1. 行指向データベースと列指向データベースの違いについて
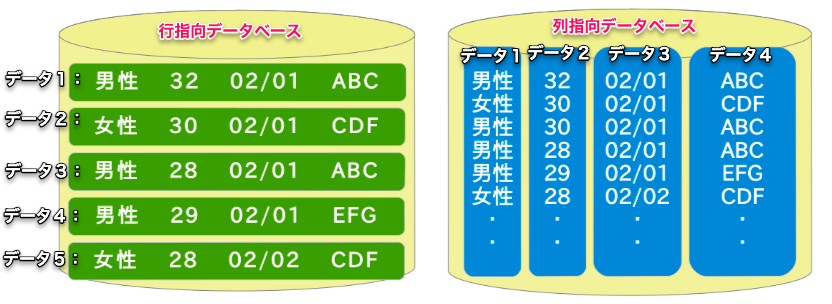
行指向データベース(行ベースのデータベース)
- 通常のリレーショナルデータベース、例えばMySQLやPostgreSQLやOracleやSQL ServerやDB2などは「行指向」のデータベースです(一般的なデータベースは行指向であるため、普段、明示的に「これは行指向のデータベースです」という言い方をすることはほとんどありません。)。
- Alibaba CloudのRDSと普通のPolarDBも行指向データベースです。
- OLTP(Online Transaction Processing)シナリオ、つまり一般のwebシステムにおけるCRUD(追加、読み取り、更新、削除)のようなオンライントランザクション処理が得意です。
- データは「行単位」で保存(すべての列の値を行として、物理的に一緒に格納)。
-
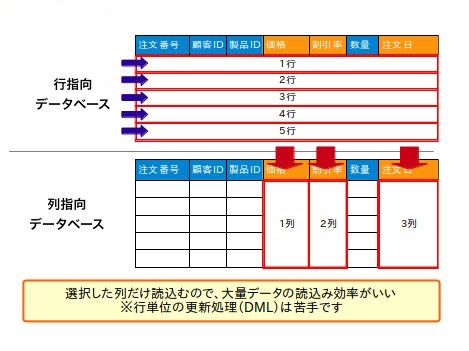
select A,B from table_name where ...のようなクエリで、特定の列を指定したとしても、マッチするレコードのすべての列の内容が返される。- 選択されたAとB列しか表示されないのですが、 データベースからは確実にマッチするレコードのすべての列の内容が返される。
- 原因: データは、一定数の物理ディスクブロック/ページで格納されていて、読み取る時にはブロックごと読み取り、不要な列も返される(ディスクアクセスの仕組み)。
列指向データベース(別名:カラム型データベース)
- 主にデータ分析のために最適化されたデータベースで、大規模なデータに対する集計処理(つまりOLAP, Online Analytical Processing)を高速に行います。
- 列単位でデータを取得,取り出しを行います。データは一連の列ファイル、各列ファイルは、特定の数の物理ディスクブロックで構成、特定の列は、単一の列ファイルに保存
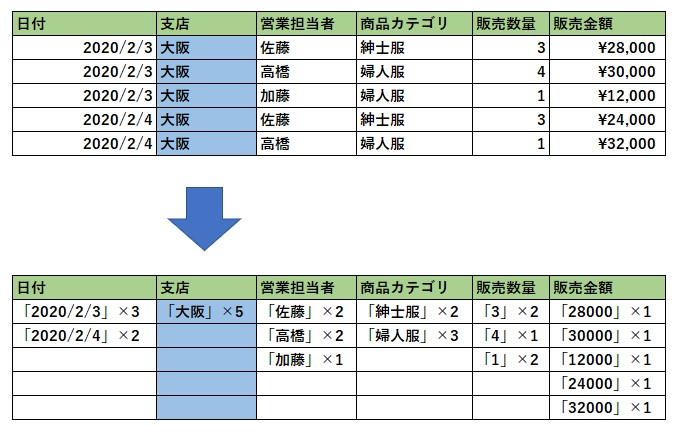
- データの圧縮効率がよくなる。つまり、データを列方向に保持しているとデータの定義情報や、値が同一のデータを格納しているので圧縮効率をあげやすいです。
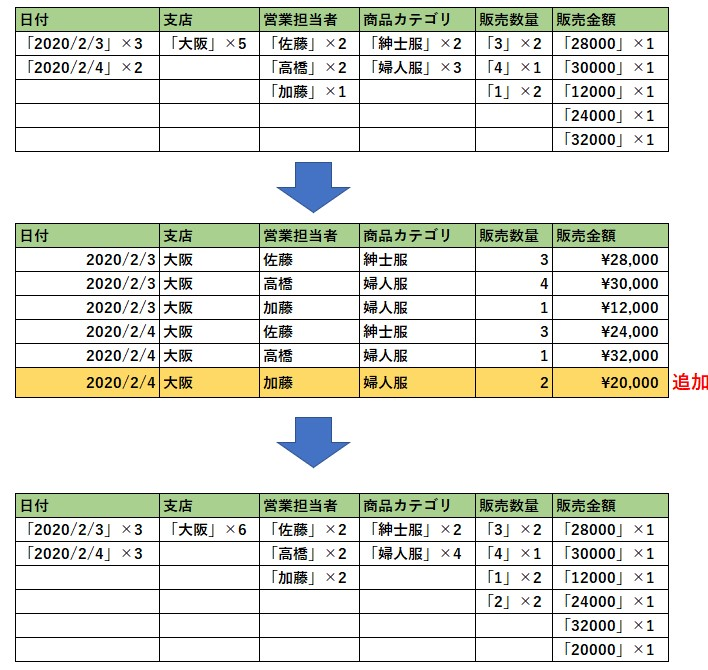
列データの値を見てみると、「支店」は全て大阪の値、「商品カテゴリ」は紳士服と婦人服であったりと重複が見られます。
データを圧縮するときに「大阪5」などで表せば 効率的にデータを圧縮 できる気が直感的にするのではないでしょうか。(実際の圧縮はそのように単純にはおこなっていませんが、今回は分かりやすくするために、そのような表現をしました)
- OLTPのシーンには向いていない。データの圧縮、展開で オーバーヘッドが発生するので、データの新規追加、更新、削除などのトランザクション処理は苦手です。
例えば、先ほどの表データに1行データを追加したいとします。
行方向のデータベースでは、行データをまとめて追加すればよいですが、列方向の場合は、圧縮したデータを一度展開して、各列項目を読み込んで追加したうえで、再度圧縮してあげるという処理が発生します。
| 比較項目 | 行指向データベース | 列指向データベース |
|---|---|---|
| 格納&取りたし単位 | 行単位(すべての列の値を行として)で物理的に一緒に格納&取り出し | 列単位(特定の列は、単一の列ファイルに保存) |
| レコードへのアクセス方法 | 常に各行の全ての列のデータが返される | 指定した列のデータしか返さない |
| 少数の行に対する多くの列の取得と更新 | 効率的 | 非効率 |
| 大量の行に対する少数の列の集約と更新 | 非効率 | 効率的 |
| 圧縮効果 | 低い | 高い |
| 得意分野 | 少量データのCRUDなどのトランザクション処理処理/OLTP(普通のwebシステム) | データ分析workload(大規模なデータに対する集計処理) /OLAP |
2. PolarDBの列指向機能(IMCI)について
- PolarDB MySQLには列指向(In-Memory Column Index、略称IMCI)としてデータの扱いもできます。OLAPシナリオの大量データ複雑クエリを対象としています。列指向インデックスを通じて、PolarDBはリアルタイムのトランザクション処理とリアルタイムのデータ分析の能力を一体化し、一元的なHTAPデータベースプロダクトソリューションとなりました。一つのデータベースで、OLTPおよびOLAPの両方の要求を同時に満たすことができます。
- IMCIの構造:
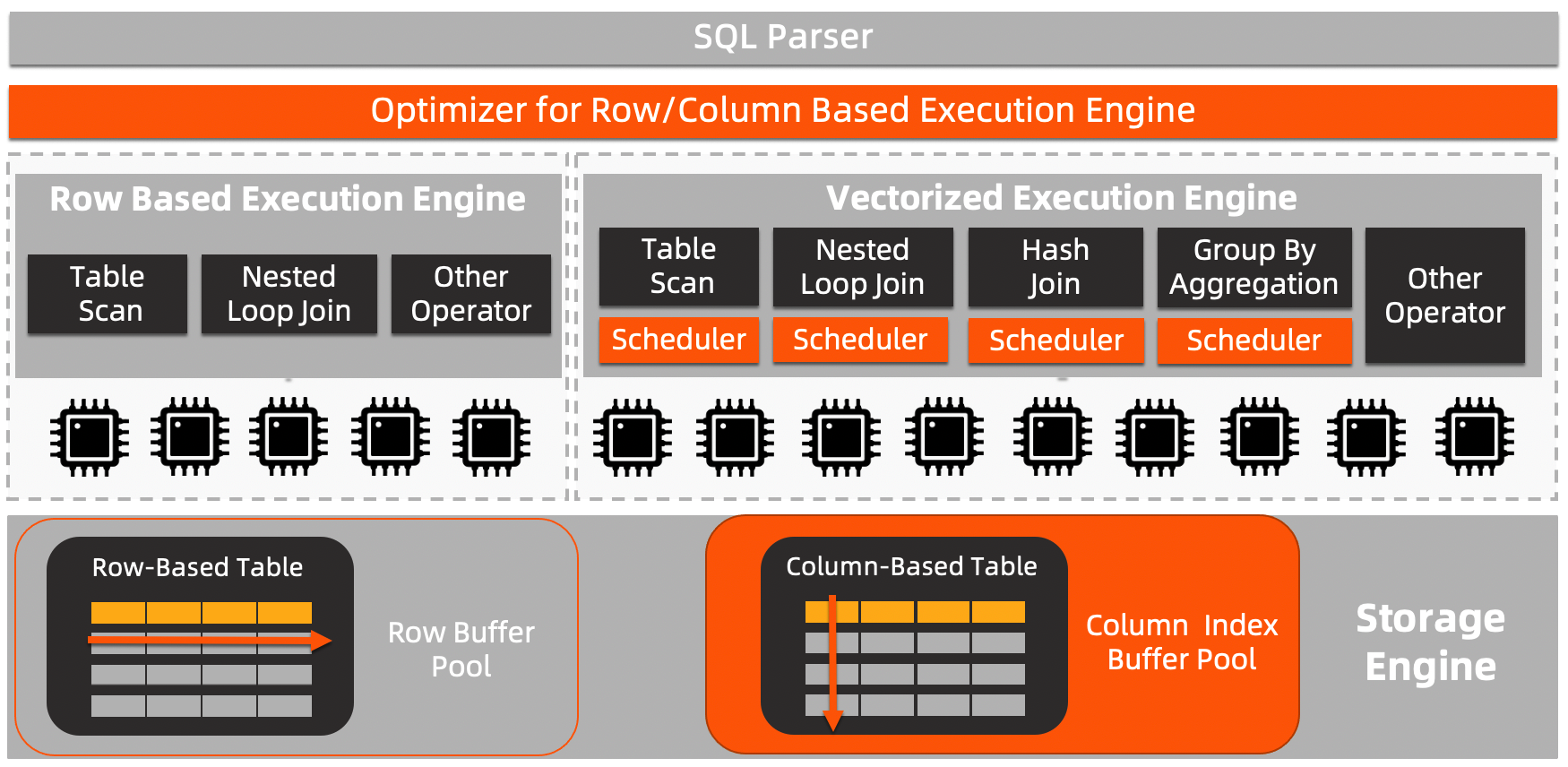
- IMCI機能は必要に応じて有効にされ、同じクラスタ内でOLTPとOLAPの計算リソースが隔離されています。
- IMCI機能を利用するための流れ:
- 読み取り専用の
column storenode(列指向ノード)を新規作成 (費用発生) - 新規作成されたノードアクセスするためのエンドポイントの作成
- 既存のテーブルに対して手動でカラム型インデックスを追加 (カラム型インデックス保存に必要なストレージは料金発生)
※ データそのもの、そしてもともと使われているインデックス(行指向インデックス)は変わらず、あくまでもデータ分析workloadも対応できるために、カラム型インデックスを追加しただけです。
- 読み取り専用の
3. IMCIの機能を使ってみる
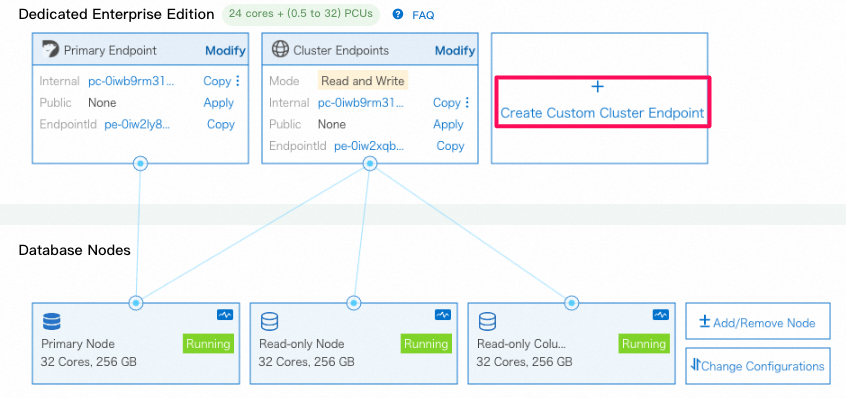
3.1 読み取り専用のcolumn storeノード(列指向node)を追加
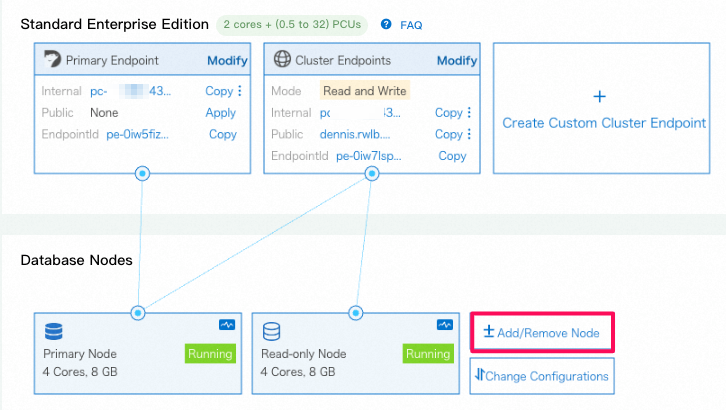
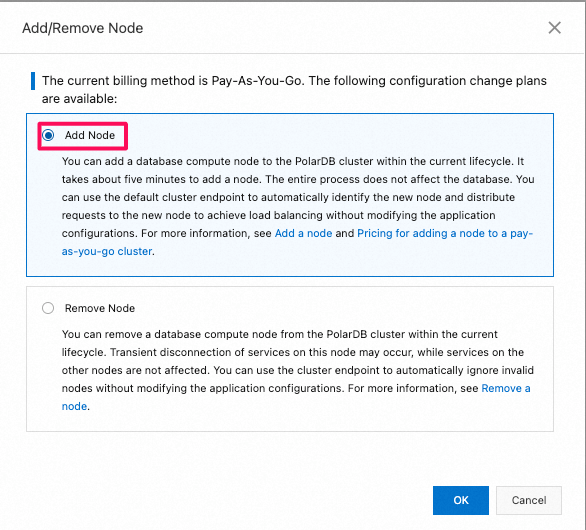
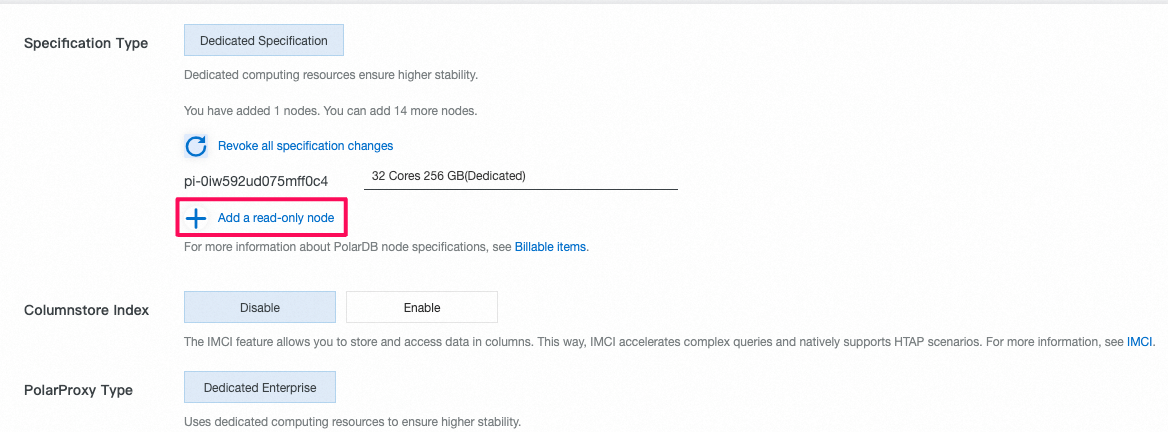
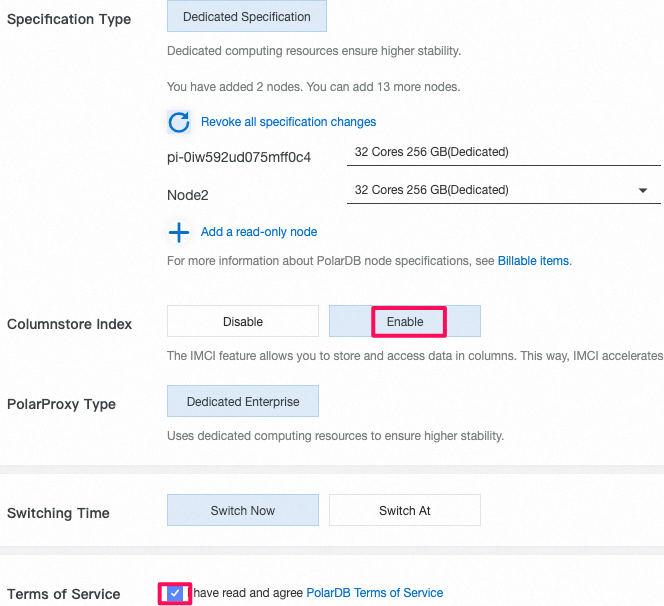
- 新規追加されたread-only 列指向のnode
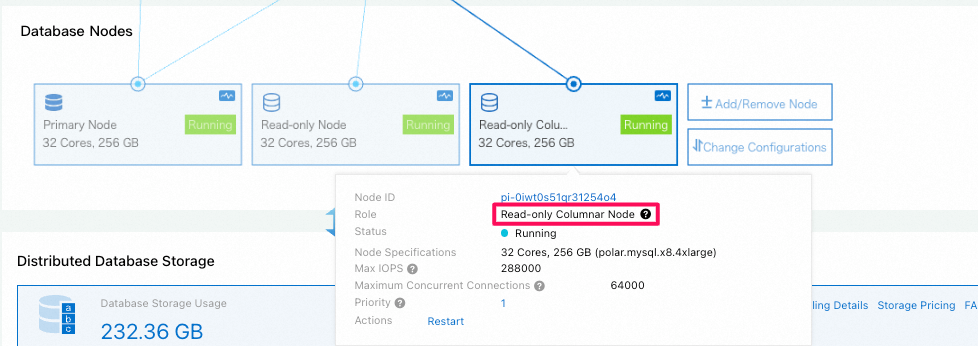
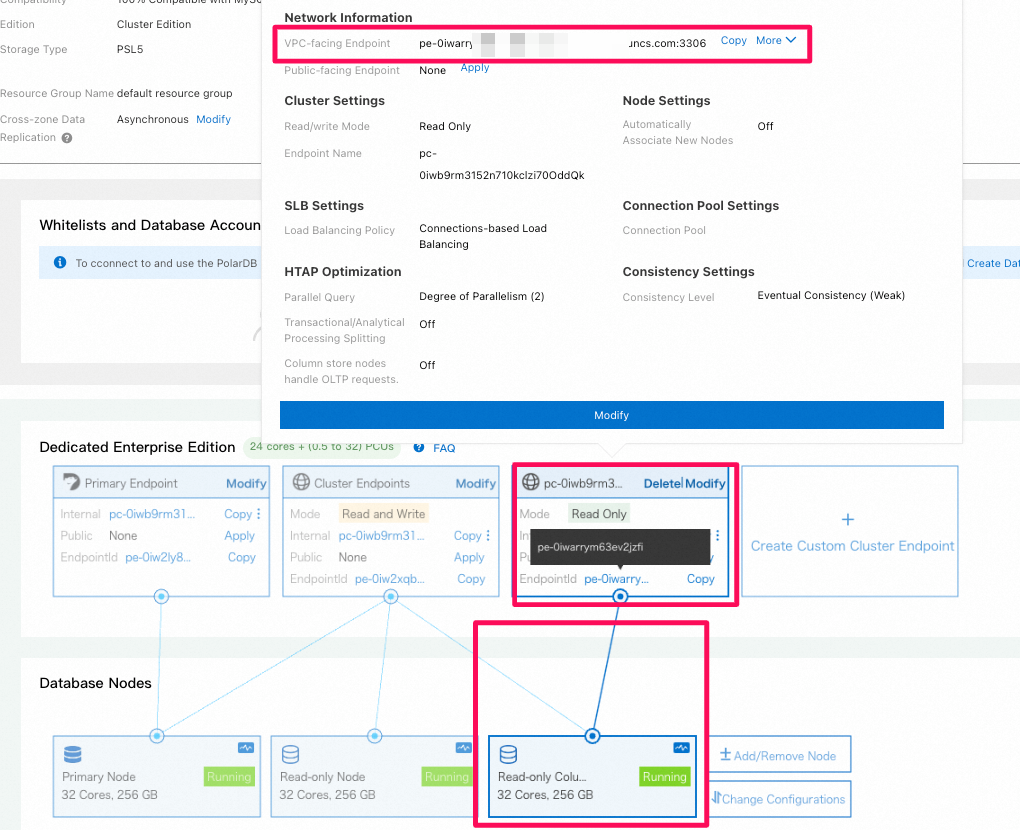
3.2 読み取り専用のcolumn storeノード(列指向node)へアクセスするためのエンドポイントを作成
方法1: 分析専用のcustom endpoint(read only)を作成して、利用する
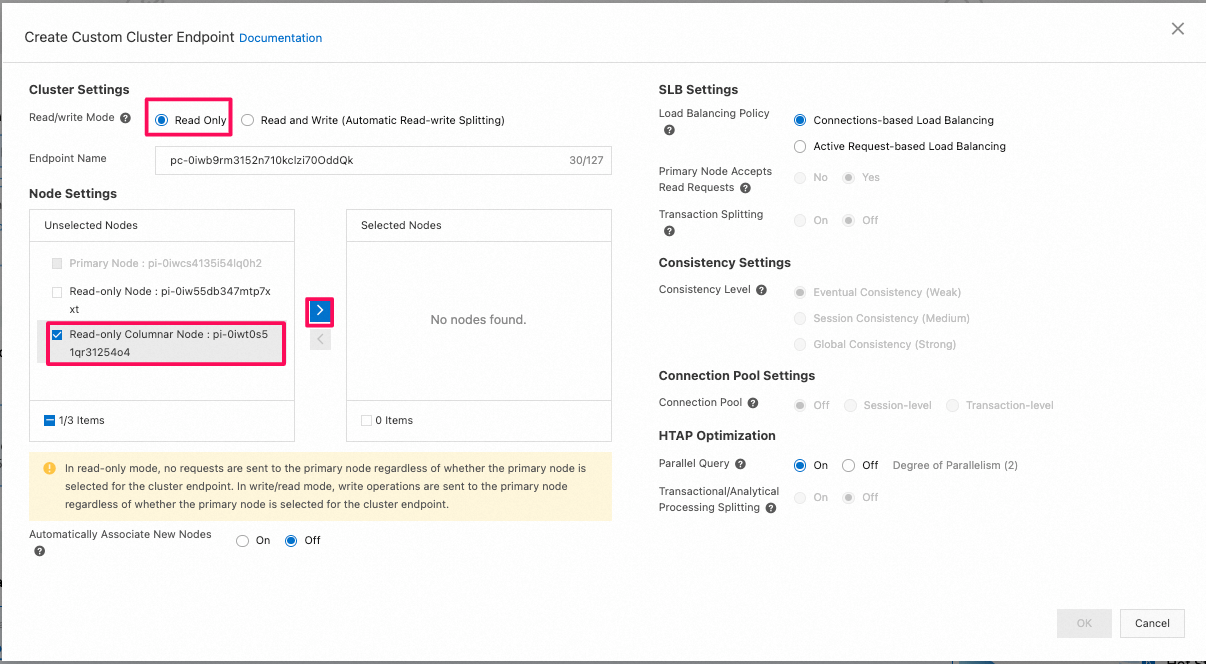
- 新しいread-only 列指向のnodeに接続しているcustom endpointの作成
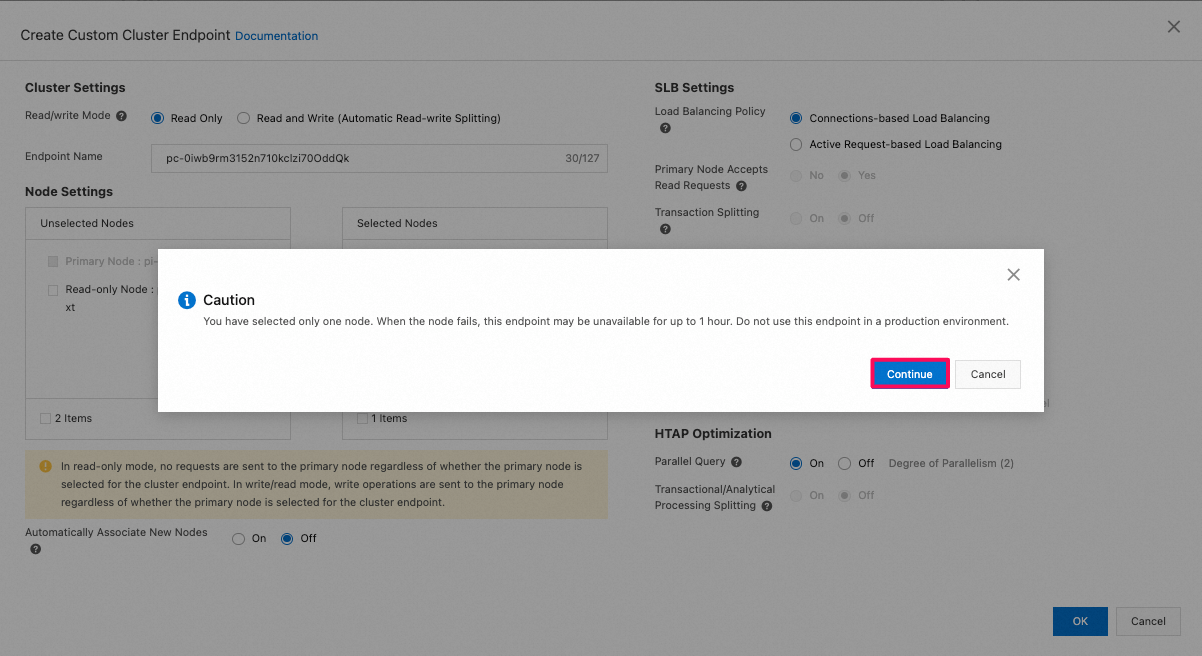
- [Read/write Mode]を[Read Only]に設定し、Read-onlyの列指向nodeを追加してください。本番環境では一つの列指向node利用すると、可用性が低いですよという警告メッセージが表示されますが、無視してかまいません。
該当の方法はread onlyのカスタムエンドポイントとなりますので、selectなどの読み取り専用のクエリしか実行できません。
IMCIを利用するためには、既存のテーブルに対して以下のようにカラム方インデックスを追加する必要があります。読み取り専用のカスタムエンドポイントに接続しても、カラムインデックスは追加できないため、以下の方法2で実際に実施します。
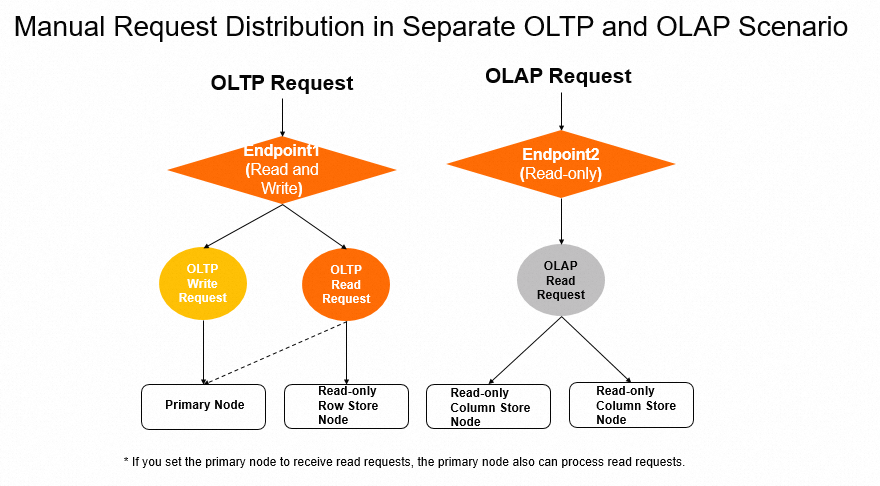
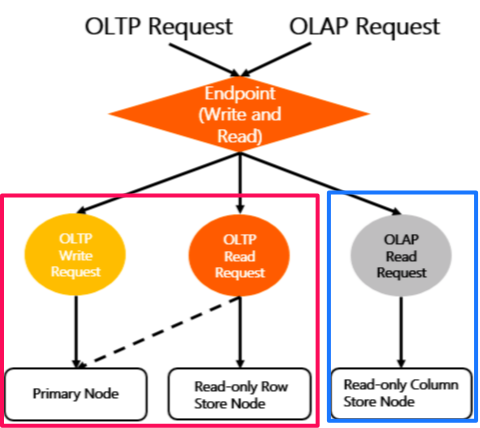
方法2: OLTP用とOLAP(分析用)は一つの共通のendpointを利用
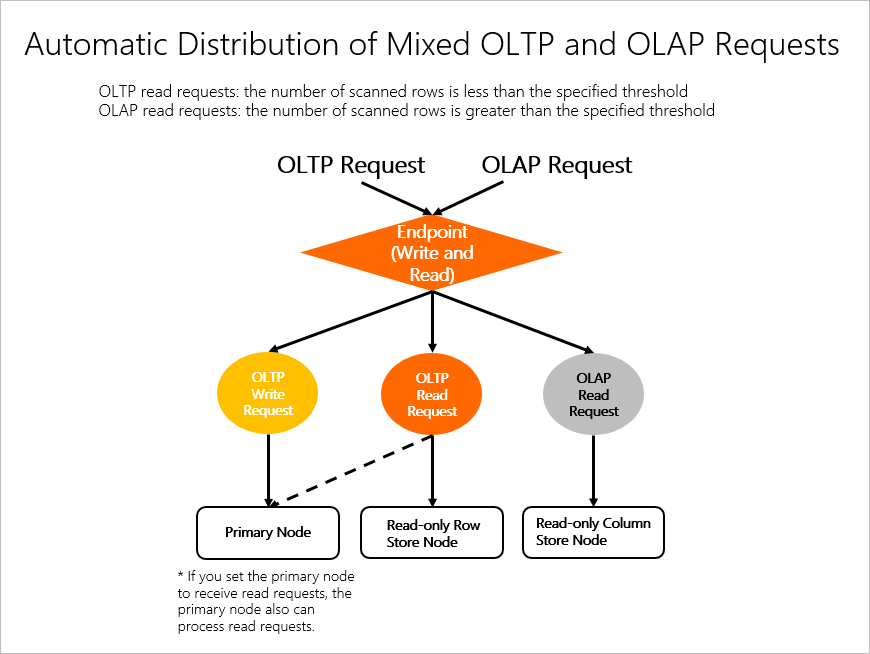
selectなどの読み取りクエリ実行する時には、内部でクエリの実行計画の結果によってOLTP用(単に普通のトランザクションクエリ)かOLAP用(時間かかる複雑の分析クエリ文)を自動的に識別し、自動的に正しいnodeに振り分けてくれます。
- OLTP用(単に普通のトランザクションクエリ)クエリであれば、右の赤枠の部分に振り分けてくれます。
- OLAP(時間かかる複雑の分析クエリ文)の場合は、自動的に左の青枠の部分に振り分けてくれます。
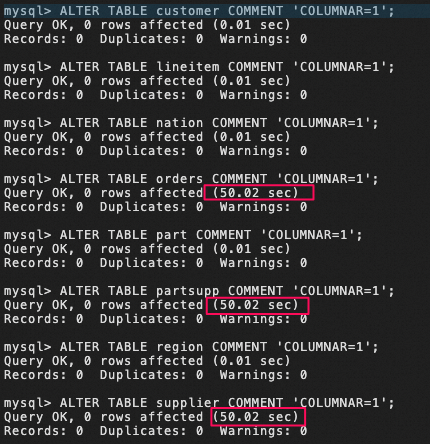
3.3 既存のテーブルに対して手動でカラム型インデックスを追加
mysql> use tpch100g;
mysql> show tables;
+--------------------+
| Tables_in_tpch100g |
+--------------------+
| customer |
| lineitem |
| nation |
| orders |
| part |
| partsupp |
| region |
| supplier |
+--------------------+
mysql> ALTER TABLE customer COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE lineitem COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE nation COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE orders COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE part COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE partsupp COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE region COMMENT 'COLUMNAR=1';
mysql> ALTER TABLE supplier COMMENT 'COLUMNAR=1';
-
カラム型インデックス追加でかかった時間
多くても50秒程度、それ以外は0.1秒完了した。
-
カラム型インデックスは有効になっているかどうかの確認
- 各クエリは以下で格納されています。
- クエリ文に対して以下のように実行計画を確認して、
IMCI Execution Planのようなメッセージが表示されましたら、カラム型インデックスが有効であることが分かります。
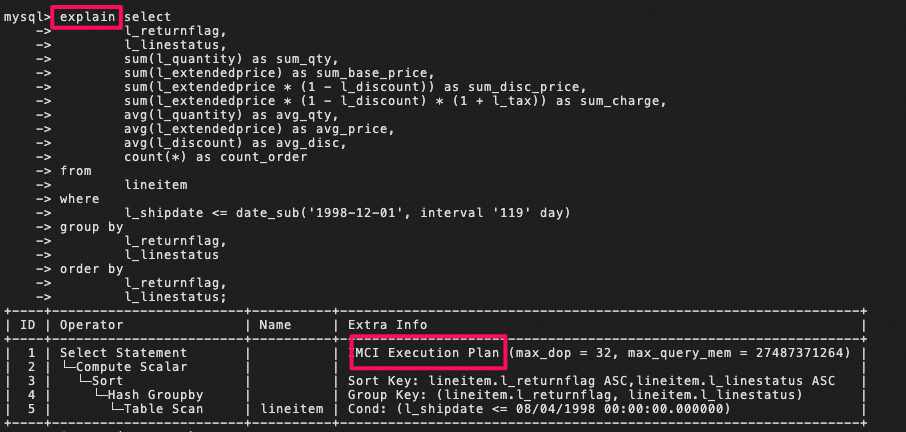
- 各クエリは以下で格納されています。
3.4 query実行し、性能確認
-
クエリ一括実行できるシェルスクリプトの用意:
[~/workspace/benchtpch/queries]# vim sql.sh #!/usr/bin/env bash host=** port=** user=** password=** database=** resfile=resfile echo "start test run at "`date "+%Y-%m-%d %H:%M:%S"`|tee -a ${resfile}.out for (( i=1; i<=22;i=i+1 )) do queryfile="Q"${i}".sql" start_time=`date "+%s.%N"` echo "run query ${i}"|tee -a ${resfile}.out mysql -h ${host} -P${port} -u${user} -p${password} $database -e" source $queryfile;" |tee -a ${resfile}.out end_time=`date "+%s.%N"` start_s=${start_time%.*} start_nanos=${start_time#*.} end_s=${end_time%.*} end_nanos=${end_time#*.} if [ "$end_nanos" -lt "$start_nanos" ];then end_s=$(( 10#$end_s -1 )) end_nanos=$(( 10#$end_nanos + 10 ** 9)) fi time=$(( 10#$end_s - 10#$start_s )).`printf "%03d\n" $(( (10#$end_nanos - 10#$start_nanos)/10**6 ))` echo ${queryfile} "the "${j}" run cost "${time}" second start at "`date -d @$start_time "+%Y-%m-%d %H:%M:%S"`" stop at "`date -d @$end_time "+%Y-%m-%d %H:%M:%S"` >> ${resfile}.time done -
クエリ一括実行できるシェルスクリプトの実行:
[~/workspace/benchtpch/queries]# bash sql.sh start test run at 2023-09-01 18:31:41 run query 1 -
以下の2つのファイルが生成されます。
- resfile.out: クエリ実行の結果
- resfile.time: 各クエリ実行でかかった時間
[~/workspace/benchtpch/queries]# ls -al resfile* -rw-r--r-- 1 root root 18574 Oct 17 10:42 resfile.out -rw-r--r-- 1 root root 649 Oct 17 10:42 resfile.time -
時間確認:
cat resfile.time Q1.sql the run cost 16.535 second start at 2023-10-17 14:51:02 stop at 2023-10-17 14:51:19 Q2.sql the run cost 1.706 second start at 2023-10-17 14:51:19 stop at 2023-10-17 14:51:21 Q3.sql the run cost 6.080 second start at 2023-10-17 14:51:21 stop at 2023-10-17 14:51:27 Q4.sql the run cost 4.589 second start at 2023-10-17 14:51:27 stop at 2023-10-17 14:51:31 Q5.sql the run cost 5.587 second start at 2023-10-17 14:51:31 stop at 2023-10-17 14:51:37 Q6.sql the run cost 2.511 second start at 2023-10-17 14:51:37 stop at 2023-10-17 14:51:39 Q7.sql the run cost 2.961 second start at 2023-10-17 14:51:39 stop at 2023-10-17 14:51:42 Q8.sql the run cost 5.230 second start at 2023-10-17 14:51:42 stop at 2023-10-17 14:51:48 Q9.sql the run cost 17.084 second start at 2023-10-17 14:51:48 stop at 2023-10-17 14:52:05 Q10.sql the run cost 8.711 second start at 2023-10-17 14:52:05 stop at 2023-10-17 14:52:13 Q11.sql the run cost 1.655 second start at 2023-10-17 14:52:13 stop at 2023-10-17 14:52:15 Q12.sql the run cost 8.092 second start at 2023-10-17 14:52:15 stop at 2023-10-17 14:52:23 Q13.sql the run cost 10.391 second start at 2023-10-17 14:52:23 stop at 2023-10-17 14:52:33 Q14.sql the run cost 6.157 second start at 2023-10-17 14:52:33 stop at 2023-10-17 14:52:40 Q15.sql the run cost 4.800 second start at 2023-10-17 14:52:40 stop at 2023-10-17 14:52:44 Q16.sql the run cost 3.264 second start at 2023-10-17 14:52:44 stop at 2023-10-17 14:52:48 Q17.sql the run cost 5.232 second start at 2023-10-17 14:52:48 stop at 2023-10-17 14:52:53 Q18.sql the run cost 19.113 second start at 2023-10-17 14:52:53 stop at 2023-10-17 14:53:12 Q19.sql the run cost 11.765 second start at 2023-10-17 14:53:12 stop at 2023-10-17 14:53:24 Q20.sql the run cost 5.729 second start at 2023-10-17 14:53:24 stop at 2023-10-17 14:53:30 Q21.sql the run cost 12.681 second start at 2023-10-17 14:53:30 stop at 2023-10-17 14:53:42 Q22.sql the run cost 2.228 second start at 2023-10-17 14:53:42 stop at 2023-10-17 14:53:44
5. test結果
| Query number | row based(秒) | IMCI有効/column based(秒) |
|---|---|---|
| Q1 | 1359.181 | 16.535 |
| Q2 | 36.620 | 1.706 |
| Q3 | 289.391 | 6.080 |
| Q4 | 63.78 | 4.589 |
| Q5 | 251.48 | 5.587 |
| Q6 | 16.4 | 2.511 |
| Q7 | 174.91 | 2.961 |
| Q8 | 560.82 | 5.230 |
| Q9 | 450.68 | 17.084 |
| Q10 | 895.75 | 8.711 |
| Q11 | 30.03 | 1.655 |
| Q12 | 266.14 | 8.092 |
| Q13 | 780.74 | 10.391 |
| Q14 | 72.04 | 6.157 |
| Q15 | 261.77 | 4.800 |
| Q16 | 40.69 | 3.264 |
| Q17 | 57.75 | 5.232 |
| Q18 | 257.66 | 19.113 |
| Q19 | 19.17 | 11.765 |
| Q20 | 143.97 | 5.729 |
| Q21 | 293.99 | 12.681 |
| Q22 | 18.81 | 2.228 |
6. 結論
- 普通のPolarDBは複雑なシーンのOLAPデータ分析はなかなか厳しいだろう。
- PolarDBのIMCIを利用すると、
- 既存のnodeに影響を与えず(既存のOLTPのworkloadに影響せず)に簡単に複雑なOLAPデータ分析が可能になる。
- 料金としては追加したread-onlyのnode(カラムベースのnode)の料金だけを払えばよい。
- OLAP workloadの可用性や性能を高めるには、さらに複数のカラムベースのnodeを追加すればよいでしょう。
- わざわざ複雑な専用なデータウェアハウスを使って、OLTPのデータベースからデータを同期する仕組みも不要になる。