Adversarial Example とは
最近あちこちで応用の進んでいる深層学習ですが、内部がブラックボックスのこともあり、まだまだ謎が多いというのが現状です。そのような中、深層学習の不可解な挙動として最近話題になっているのが Adversarial Example です。呼ばれ方もいろいろで、adversarial attack や、adversarial perturbation と呼ばれることもあれば、画像関係の場合は adversarial image と呼ばれることもあります。いずれにせよ、簡単にいえば、分類器に対する脆弱性攻撃のようなものです。例えば、分類器が正しく分類できていた画像に、人の目では判別できない程度のノイズをのせることで、作為的に分類器の判断を誤らせることができるといったものです。
よく説明として使われるのが下の画像で、
 [Explaining and Harnessing Adversarial Examples](https://arxiv.org/abs/1412.6572)
57.7% の確度でパンダとして認識されていた画像(左)に、小さなノイズ(中)を加えた結果(右)は、人の目には違いがわからないが分類器には 99.3% の確度でテナガザルと認識されたというものです。
[Explaining and Harnessing Adversarial Examples](https://arxiv.org/abs/1412.6572)
57.7% の確度でパンダとして認識されていた画像(左)に、小さなノイズ(中)を加えた結果(右)は、人の目には違いがわからないが分類器には 99.3% の確度でテナガザルと認識されたというものです。
似たような現象として、人の目にはノイズや単なる幾何学パターンにしか見えなくても深層学習モデルには高い確度で「ペンギン」などとラベリングされてしまうような画像を生成できることも知られています(参考:Deep Neural Networks are Easily Fooled)。こちらは特定の呼び名がついていないようですが、合わせておさえておきたいところです。
Adversarial Example いろいろ
微小なノイズを加えるという特性上、連続値として処理できる画像関係の話題が大半です。しかし、少数ではありますが、テキスト分類、楽曲分類などでも報告が上がっています。
また、画像関係については、様々な adversarial image の生成方法が提案されています。 adversarial image からの防衛方法(誤分類を防ぐ方法)についてもいろいろなものが提案されています。ただ、一言でいってしまえば、adversarial attack を完全に防ぐ方法は現時点で存在していません。次々と新しい防衛法が提案されては、それをかいくぐる adversarial image の生成方法が考案されるといったイタチごっこが続いています。完全な防衛方法は存在していないのですが、可能な限り微小なノイズを加えた adversarial image を使って学習させることで分類器の決定境界を微調整する方法が比較的頑健だったりするようです(参考:Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples)。
Adversarial Example を作ってみる
実際に adversarial image を作ってみます。
概要
手法
adversarial image を生成する方法は様々なものがあるのですが、なるべく単純な手法で試すといことで、 Fast Gradient Sign 系統の手法を使います。これは、入力画像について損失が大きくなる方向に適当な値を加算(or 減算)するというもので、パンダの例に合わせて更新式を書くならば
x = x + \epsilon \text{sign} \: \big( \nabla_{x} J(\theta, x, y) \big) \tag{1.1}
となります。 $x$ が入力画像ベクトル、$\epsilon$ は適当に小さい値、$y$ が正解ラベルです。また、 $J$ は損失関数で $\theta$ は分類器モデルのパラメーターです。分類器を学習させるのが目的ではないため、$\theta$ は固定します。一方で、分類器を騙すように入力画像を変形させたいので、損失関数 $J$ を入力画像 $x$ で微分し損失が大きくなる方向に $\epsilon$ を加算します。$\text{sing}( )$ は値の符号を取り出す関数です。
(1.1) の場合は、正解ラベルとの損失を大きくするという発想ですが、あらかじめ指定した不正解ラベルに向けて画像を変形させるという方法もあります。このときは、ターゲットとなるラベルとの損失を小さくしていくことになるので
x = x - \epsilon \text{sign} \: \big( \nabla_{x} J(\theta, x, t) \big) \tag{1.2}
とかけます。 $t$ がターゲットとなる不正解ラベルです。
以上が基本ですが、Adversarial examples in the physical world では、(1.1) や (1.2) の更新の後にピクセルの値を適当な範囲内でclipする、さらに何回か更新を iterate するなどしているようです。
下の実験結果のところで示しているものは、(1.2) のタイプで、ターゲットラベルを最も予測確率の低かったラベルに設定し、ピクセル値のcliping と更新の iteration も行ったものです。Adversarial Examples をやってみる のページで "iterative least likely" として詳しく紹介されているので、詳細はそちらをご覧ください。
データ
画像はせっかくなので CIFAR10 などの小さい画像ではなく、ImageNetを使ってみましょう。ImageNet 画像は、研究機関などに所属していない限り一括ダウンロードできず、血涙を流しつつかき集める必要があります。ページ下部の参考文献などみつつ集めてください。ちなみに、1000カテゴリー✕10枚=10000枚もあれば、この実験のためには十分な気がします。
フレームワーク / モデル
深層学習用のフレームワークとして chainer を用います。ImageNetの画像分類モデルを自力で学習させるのはしんどいので学習済みモデルを使います。chainer link一覧によると学習済みモデルとして、VGG16, GoogLeNet, Residual Networks が用意されているようです。ちなみにこれらは、ILSVRC(ImageNetを用いた画像分類コンテスト)での2014年準優勝, 2014年優勝, 2015年優勝のモデルのようです。モデルの詳細はこちらをご覧ください。
ページ下では、VGG16とResidual Networksのうち152層versionを用いたものを載せています。Residual Networks(152層)については以下、ResNet152と略記します。
ImageNetの学習データ画像
現時点でImageNetの画像は2万クラスあるそうなのですが、学習済みモデルはそのうちの1000クラスを分類するように作成されています。そのため、どの1000クラスで学習されているのか知る必要があります。おそらく、こちらやあちらだと思うのですが確信はありません。とりあえず、このリストが正しいものとして進めます。
コード
本体
import os
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import Variable
from chainer import cuda
import numpy as np
from PIL import Image
from numpy import random
# stop drop-out
chainer.config.train = False
##################################################################
# for one adversarial image ######################################
class AdvImage(object):
"""
This object performs adversarial attack to one image.
original image : Image Net
Neural Net models : VGG16, GoogLeNet, ResNet152
Attack methods : (iterative) fast gradient sign methods
"""
uses_device = None
xp = None
model_name = None
model = None
size = None
mean = None
last_layer = None
def __init__(self, image_path, image_index, uses_device=0):
"""
Set an original image and index.
"""
self.path = image_path
self.index = image_index
self.ORG_image = Image.open(image_path).convert('RGB')
self.org_image = None # resized image
self.target = None
self.adv_image = None # adversarial image
@classmethod
def set_model(cls, model_name, uses_device=0):
"""
Set model and device.
uses_device = -1 : CPU
uses_device >= 0 : GPU (default 0)
"""
# use gpu or cpu
cls.uses_device = uses_device
if uses_device >= 0:
chainer.cuda.get_device_from_id(uses_device).use()
chainer.cuda.check_cuda_available()
import cupy as xp
else:
xp = np
cls.xp = xp
# set model
cls.model_name = model_name
if model_name == "VGG16":
cls.model = L.VGG16Layers()
cls.last_layer = 'fc8'
cls.size = (224, 224)
cls.mean = [103.939, 116.779, 123.68]
elif model_name == "GoogLeNet":
cls.model = L.GoogLeNet()
cls.last_layer = 'loss3_fc'
cls.size = (224, 224)
cls.mean = [104.0, 117.0, 123.0]
elif model_name == "ResNet152":
cls.model = L.ResNet152Layers()
cls.last_layer = 'fc6'
cls.size = (224, 224)
cls.mean = [103.063, 115.903, 123.152]
else:
raise Exception("Invalid model")
if uses_device >= 0:
cls.model.to_gpu()
#for memory saving
for param in cls.model.params():
param._requires_grad = False
def set_state(self):
"""
Set a variable which correspnds to the adversarial image.
"""
if AdvImage.model is None:
raise Exception("model is not set")
self.org_image = self.ORG_image.resize(AdvImage.size)
if self.adv_image is None:
self.target = self._prepare_variable(self.org_image)
self.adv_image = self._restore_image(self.target)
else:
self.target = self._prepare_variable(self.adv_image)
def reset_state(self):
"""
Reset the adversarial image and the corresponding variable.
"""
self.target = self._prepare_variable(self.org_image)
self.adv_image = self._restore_image(self.target)
def _prepare_variable(self, image):
"""
Convert PIL.Image to chainer.variable.
"""
# image must be resized before fed into this method
xp = AdvImage.xp
arr = xp.array(image, dtype=xp.float32) # image should be copied (to gpu)
arr = arr[:, :, ::-1]
arr -= xp.array(AdvImage.mean, dtype=xp.float32)
arr = arr.transpose((2, 0, 1))
arr = arr.reshape((1,) + arr.shape)
return Variable(arr)
def _restore_image(self, target):
"""
Convert chainer.variable to PIL.Image.
"""
arr = target.data[0].copy() # vaiable.data should be copied (to cpu)
arr = cuda.to_cpu(arr)
arr = arr.transpose((1, 2, 0))
arr += np.array(AdvImage.mean, dtype=np.float32)
arr = arr[:, :, ::-1]
return Image.fromarray(arr.astype(np.uint8), 'RGB')
def _save_image(self, image_obj, dir_path, model_name):
model_dir = os.path.join(dir_path, model_name)
if os.path.exists(model_dir) is False:
os.mkdir(model_dir)
file_name = "{0}.jpg".format(os.path.basename(self.path).split('.')[0])
file_path = os.path.join(model_dir, file_name)
image_obj.save(file_path)
def save_adv(self, dir_path):
self._save_image(self.adv_image, dir_path, AdvImage.model_name)
def save_org(self, dir_path):
self._save_image(self.org_image, dir_path, "Original")
@classmethod
def _pred(cls, image):
res = cls.model.predict([image], oversample=False).data[0]
res = cuda.to_cpu(res)
pred_index = np.argmax(res)
prob = res[pred_index]
return pred_index, prob
def pred_org(self):
return AdvImage._pred(self.org_image)
def pred_adv(self):
return AdvImage._pred(self.adv_image)
## adversarial attacks #####################
def fast_gradient(self, eps):
xp = AdvImage.xp
out_layer = AdvImage.last_layer
x = AdvImage.model(self.target, layers=[out_layer])[out_layer]
t = xp.array([self.index], dtype=xp.int32)
loss = F.softmax_cross_entropy(x, t)
self.target.cleargrad()
AdvImage.model.cleargrads()
loss.backward()
perturb = xp.sign(self.target.grad)
self.target = Variable(self.target.data + eps * perturb)
self.adv_image = self._restore_image(self.target)
def iterative_gradient(self, eps, alpha =1, n_iter = None):
xp = AdvImage.xp
if n_iter is None:
n_iter = int(min(eps + 4, 1.25 * eps))
t = xp.array([self.index], dtype=xp.int32)
out_layer = AdvImage.last_layer
target_org = self.target.data.copy()
for _ in range(n_iter):
x = AdvImage.model(self.target, layers=[out_layer])[out_layer]
loss = F.softmax_cross_entropy(x, t)
self.target.cleargrad()
AdvImage.model.cleargrads()
loss.backward()
perturb = xp.sign(self.target.grad)
updated_data = self.target.data + alpha * perturb
clipped_data = xp.clip(updated_data, target_org - eps, target_org + eps)
self.target = Variable(clipped_data)
self.adv_image = self._restore_image(self.target)
def iterative_least_likely(self, eps, alpha =1, n_iter = None, index = None):
xp = AdvImage.xp
if n_iter is None:
n_iter = int(min(eps + 4, 1.25 * eps))
if index is None:
probs = AdvImage.model.predict([self.org_image], oversample=False).data[0]
probs = cuda.to_cpu(probs)
least_index = np.argmin(probs)
t = xp.array([least_index], dtype=xp.int32)
out_layer = AdvImage.last_layer
target_org = self.target.data.copy()
for _ in range(n_iter):
x = AdvImage.model(self.target, layers=[out_layer])[out_layer]
loss = F.softmax_cross_entropy(x, t)
self.target.cleargrad()
AdvImage.model.cleargrads()
loss.backward()
perturb = xp.sign(self.target.grad)
updated_data = self.target.data - alpha * perturb
clipped_data = xp.clip(updated_data, target_org - eps, target_org + eps)
self.target = Variable(clipped_data)
self.adv_image = self._restore_image(self.target)
##################################################################
# for list of adversarial images #################################
class AdvImageList(object):
"""
This object performs adversarial attack to multiple images.
"""
def __init__(self, image_paths, image_indices, model_name, uses_device=0):
"""
Set original images and indices.
Also, set device:
uses_device = -1 : CPU
uses_device >= 0 : GPU (default 0)
"""
if len(image_paths) != len(image_indices):
raise Exception("length of paths and indices do not match")
self.image_paths = image_paths
self.image_indices = image_indices
self.length = len(image_indices)
self.uses_device = uses_device
AdvImage.set_model(model_name, uses_device)
self.adv_images = []
for i in range(len(image_indices)):
adv = AdvImage(image_paths[i], image_indices[i])
adv.set_state()
self.adv_images.append(adv)
def save_images(self, dir_name):
for x in self.adv_images:
x.save_org(dir_name)
x.save_adv(dir_name)
def pred(self):
self.org_preds = []
self.org_probs = []
self.adv_preds = []
self.adv_probs = []
for x in self.adv_images:
pred, prob = x.pred_org()
self.org_preds.append(pred)
self.org_probs.append(prob)
pred, prob = x.pred_adv()
self.adv_preds.append(pred)
self.adv_probs.append(prob)
def show(self):
for i in range(self.length):
print("{0} : ({1}, {2:.3f}) --> ({3}, {4:.3f})".format(self.image_indices[i],
self.org_preds[i], self.org_probs[i],
self.adv_preds[i], self.adv_probs[i]))
def change_model(self, model_name):
AdvImage.set_model(model_name, self.uses_device)
for x in self.adv_images:
x.set_state()
self.pred()
def reset_state(self):
for x in self.adv_images:
x.reset_state()
self.pred()
## adversarial attacks #########################
def fast_gradient(self, eps):
for x in self.adv_images:
x.fast_gradient(eps)
self.pred()
def iterative_gradient(self, eps, alpha = 1, n_iter = None):
for x in self.adv_images:
x.iterative_gradient(eps, alpha = alpha, n_iter = n_iter)
self.pred()
def iterative_least_likely(self, eps, alpha = 1, n_iter = None, index = None):
for x in self.adv_images:
x.iterative_least_likely(eps, alpha = alpha, n_iter = n_iter, index = index)
self.pred()
使い方
① 入力画像のパスのリストと、対応する正解ラベルのリストを準備
image_paths = ['/img_dir/img01jpg', '/img_dir/img02.jpg', '/img_dir/img03.jpg', '/img_dir/img04.jpg']
image_indices = [491, 70, 301, 310]
② 分類器のモデル名("VGG16" or "GoogLeNet" or "ResNet152")を指定してインスタンス作成
advlist = AdvImageList(image_paths, image_indices, "VGG16", uses_device = -1)
デフォルトでは GPU 使用(uses_device = 0)となっているので、CPUのみの場合は uses_device = -1 とする。
③ 適当にパラメータを指定して adversarial attack 開始
VGG16 モデルで、$\epsilon = 8$ としてみると
advlist.iterative_least_likely(8)
④ 結果を表示
advlist.show()
下のような表が出力される。
491 : (491, 1.000) --> (509, 0.693)
70 : (70, 0.977) --> (148, 0.989)
301 : (301, 0.916) --> (807, 0.670)
310 : (310, 0.803) --> (936, 0.488)
一番左の数値が正解ラベル、":" の後の数値は元画像に対する分類器のTOP1予測ラベルと確率、"-->" の後の数値は生成した adversarial image に対するTOP1予測ラベルと確率。
⑤ 作成した画像を保存したいときは、保存用 directory のパスを指定
save_dir = '/saved_img_dir'
advlist.save_images(save_dir)
以下の要領で画像が保存される。
/saved_img_dir/
┣ Original/ (リスケールされた元画像を保存)
┗ VGG16/ (VGG16で生成した adversarial image を保存)
⑥ 作成した adversarial image を別の分類器モデルに入力してみる
モデルを ResNet152 に変更し、VGG16 で作成した adversarial image を評価させてみる。
advlist.change_model('ResNet152')
advlist.show()
491 : (491, 1.000) --> (632, 0.219)
70 : (70, 0.999) --> (70, 0.995)
301 : (301, 0.991) --> (301, 0.971)
310 : (310, 1.000) --> (310, 0.759)
左から順に正解ラベル、元画像に対する ResNet152 の予測ラベル/確率、VGG16 で作成した adversarial image に対する ResNet152 の予測ラベル/確率。
⑦ 変更後のモデルで adversarial image を生成
モデルを変更しただけでは adversarial image の再作成は行われないので、変更後のモデルで再作成したいときは adversarial image をリセットしたのち再度 attack。
advlist.reset_state()
advlist.iterative_least_likely(8)
advlist.show()
491 : (491, 1.000) --> (509, 0.209)
70 : (70, 0.999) --> (70, 0.992)
301 : (301, 0.991) --> (125, 0.205)
310 : (310, 1.000) --> (310, 0.950)
ここで再度画像を保存すると
save_dir = '/saved_img_dir'
advlist.save_images(save_dir)
下のように保存される。
/saved_img_dir/
┣ Original/ (リスケールされた元画像を保存)
┣ VGG16/ (VGG16 で生成した adversarial image を保存)
┗ ResNet152/(ResNet152 で生成した adversarial image を保存)
結果
適当にいろいろ作ってみた中で、特徴的だったものをいくつか紹介したいと思います。
表の見方ですが、横向きに列が "Original", "VGG16", "ResNet" と並んでいてその下に画像があります。この画像は左から順に、もと画像(のスケール変換したもの)、VGG16 モデルを使って作成した adversarial image、ResNet152 モデルを使って作成した adversarial image となります。さらに画像の下には、"VGG16", "ResNet152" の行があって、各モデルに画像を放り込んだ時の TOP1 分類結果と確率を載せています。
例えば、横列が "VGG16"、縦の項目が "ResNet152" の時は、VGG16 で生成したadversarial image をResNet152 に放り込んだ結果となります。
全体にうっすら模様が浮き出る
パンダの例のように、一見すると違いがわからないけれども予測結果がおかしくなっているタイプも、やはり確認できました。
しかし、目を凝らしてじっくり見てみると、全体に薄っすらと模様が浮かび上がっているように思えました。
2つほど例を上げます。
例1) ladybug, ladybeetle, lady beetle, ladybird, ladybird_beetle (てんとう虫)
| Original | VGG16 | ResNet152 | |
|---|---|---|---|
 |
 |
 |
|
| VGG16 | てんとう虫 (91.6%) | solar dish (67.0%) | てんとう虫 (83.1%) |
| ResNet152 | てんとう虫 (99.1%) | てんとう虫 (97.1%) | ヤドカリ (20.5%) |
| *solar dish : 陽光線を一点に集める凹面鏡 |
遠くから見ると違いがわからないのですが、近づいていくと画像がぼやっとしていることに気づきます。さらに至近距離まで近づいてじっくり見てみると、波紋のような模様が浮かび上がっているのがわかります。てんとう虫自体はさほど変化しているようには思えません。
私達が上のような画像を見るとき、てんとう虫のあたりだけに注目して周辺の情報は捨てていると思います。一方で、コンボリューションなど含むディープラーニング系の分類器は、全体からもパターンを抽出しようとして引っかりやすくなるのかもしれません。
ちなみに、あるモデルで作成した adversarial image は他のモデルも騙せると言われていますが、今回実験してみたところでは、その傾向は見えにくいようでした。上のてんとう虫画像でも、VGG16 で作成した adversarial image は ResNet152 を騙せていませんし、その逆もまた然りです。それぞれのモデルの学習に使われた画像が異なる、画像をnumpy.array から PIL.Image に変換するところでつぶれている、方法がざっくりすぎるなどいろいろあるのかもしれませんが、今回は気にしないことにします。また、VGG16 に比べて、GoogLeNet や ResNet152 のほうが adversarial image を生成しにくいように思えました。
例2) harvestman, daddy_longlegs, Phalangium_opilio (ザトウムシ)
| Original | VGG16 | ResNet152 | |
|---|---|---|---|
 |
 |
 |
|
| VGG16 | ザトウムシ (97.7%) | シャチ (98.9%) | ザトウムシ (73.4%) |
| ResNet152 | ザトウムシ (99.9%) | ザトウムシ (99.5%) | ザトウムシ (99.2%) |
画像の違いが極めてわかりにくく、てんとう虫より巧妙な例です。
ResNet152 の方では adversarial image の作成に失敗していますが、VGG16 は騙せています。ザトウムシがシャチと解釈されています。どこがシャチなのかは全くわかりません。じっくり見てみると、幾何学模様というほどでないのですが、背景の凸凹感や色調が若干変化しているように思えます。ImageNetのシャチ画像をみると水面が写っているものが多いのですが、ザトウムシ画像の背景の岩肌と水面の質感との比較で判定されているとかなのでしょうか。
画像の端が壊れる
例3) bassinet(ほろ付き揺りかご)
| Original | VGG16 | ResNet152 | |
|---|---|---|---|
 |
 |
 |
|
| VGG16 | ほろ付き揺りかご (93.8%) | オオハシシギ(鳥の一種) (92.6%) | ほろ付き揺りかご (91.8%) |
| ResNet152 | ほろ付き揺りかご (98.9%) | ほろ付き揺りかご (92.3%) | ほろ付き揺りかご (95.4%) |
画像の一部が壊れるものは多かったのですが、物体の境界や何もない隅のほうが狙われることが多い印象です。上の例では、画像の左上が壊れ、ゆりかごが鳥と解釈されてしまっています。全体もぼやっとしています。
空白に幾何学模様が刻まれる
生成した adversarial image を眺めていて一番派手で目を引くのがこのタイプです。背景が単色塗りつぶしの空白の場合、そこに幾何学?模様が刻まれて分類がおかしくなります。
例4) soap dispenser(石鹸容器)
| Original | VGG16 | ResNet152 | |
|---|---|---|---|
 |
 |
 |
|
| VGG16 | 石鹸容器 (98.2%) | 枕 (52.1%) | エプロン (34.2%) |
| ResNet152 | 石鹸容器 (90.4%) | ストゥーパ(仏塔) (67.5%) | 教会 (53.7%) |
容器の表面にもうっすらと模様が浮かんでいますが、背景にサイケデリックな模様が刻まれています。VGG16、ResNet152 ともに adversarial image の作成に成功しています。ResNet152 の方はストゥーパや教会のような建築物系で石鹸容器と比較してわからなくもないような気がしますが、VGG16 では枕やエプロンと関連性が全くわかりません。
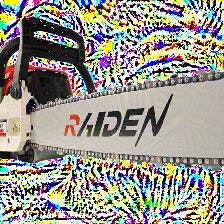
例5) chain saw, chainsaw(チェーンソー)
| Original | VGG16 | ResNet152 | |
|---|---|---|---|
 |
 |
 |
|
| VGG16 | チェーンソー (100.0%) | お菓子* (69.3%) | お菓子 (73.7%) |
| ResNet152 | チェーンソー (100.0%) | スピーカー (21.9%) | お菓子 (20.9%) |
*)ImageNetの画像を見たところ、「お菓子」というよりは「お菓子の陳列」のような感じでした。
もうひとつ、背景にサイケデリックな模様が刻まれる例です。こちらは、adversarial image の分類結果が「お菓子(の陳列)」になりやすいようです。カラフルなお菓子が並んだ様子と adversarial image の背景が似ているといわれれば、そんな気もしますが。
ざっと見て見ただけなので、今回はこのあたりでおしまいです。
参考文献
解説記事
はじめてのAdversarial Example
Adversarial Examples をやってみる。
論文まとめ
Awesome Adversarial Examples for Deep Learning
Awesome Adversarial Machine Learning