はじめに
こんにちは。 @dcm_yamaya です。
ことしハマったキーボードは HHKB Professional HYBRID (not type-s) です。
この記事は、NTTドコモ R&D Advent Calendar 2020 7日目の記事です。
普段の業務では、画像認識やエッジコンピューティングの技術領域を担当しています。
昨年の記事 ではJetson上で画像認識モデルをTensorRT化する方法を紹介しました。
ことしはTensorRTに関連して興味があった、GTC2020で発表された NVIDIA Triton Inference Server を使って画像認識モデルの推論を試したいと思います。
「あれ、このフレームワーク前もなかったっけ?TensorRT Inference Server じゃなかったっけ?」
と思ったら、名前が変わっていました。
https://twitter.com/_ksasaki/status/1243708356419710976?s=20
対象とする人
- GPUサーバで
- Triton Inference Server を使ってみたい
やること
- Triton Inference Server とは
- 分類モデルの推論
- 物体検出モデル(yolov3)の推論
Triton Inference Server で推論してみよう
Triton Inference Server とは
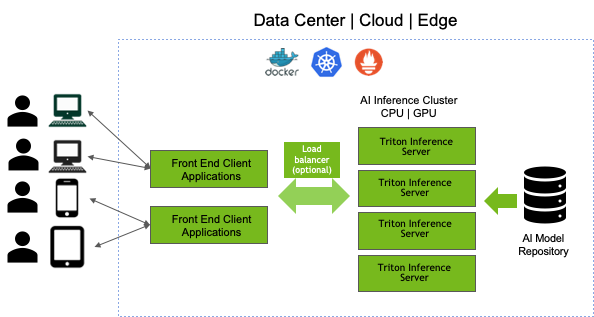
NVIDIA がリリースしている、GPUを使用して機械学習モデルを高速に推論させるサーバを構築するためのフレームワークです。
単に推論させるだけであれば、わざわざをサーバを立てなくても…という気もしますが、TISによって複数の学習環境の異なるモデルを高速に
動作させることができるといったメリットがあります。
Inference Server に載せたモデルを推論するには、クライアントからHTTP/RESTまたはGRPCプロトコルでリクエストを投げることで、
推論結果を得ることができます。
TensorFlowはTensorFlow Serving, Pytorch は TorchServe と フレームワークごとに Serving が用意されていますが、それらとは異なりTensorRTが使えるなどより実行を高速にできる(可能性がある)のがこれらとのちがいかなと思います。
※[2]
特徴
- 様々なフレームワークで学習されたモデルを扱うことができる
- TensorRT
- TensorFlow GraphDef
- TensorFlow SavedModel
- ONNX
- Pytorch TorchScript
- 複数のモデルを同時に、1つのGPU内または複数のGPU上で実行できる(Concurent Execution)
- GPUごとに使用率やメモリ、レイテンシーの状況など各種メトリクスの監視ができる

分類モデルの推論
では早速 Triton Inference Server を使って推論してみたいと思います。
こちらにチュートリアルがあるのでこれを参考に画像分類モデルの推論を試してみます。
特にTensorRTがUbuntuやCUDAのバージョンにシビアなため、それにあったTISのバージョンを選択する必要があることが注意点です。
(筆者は最初にはまりました。。)
https://github.com/triton-inference-server/server/blob/master/docs/quickstart.md
筆者の動作環境
- Docker version 19.03.13
- Ubuntu 18.04
- CUDA 10.2
- TensorRT 6.0.1.8
Docker Image のインストール
下記コマンドでngcから docker image を pull してきます。
docker pull nvcr.io/nvidia/tritonserver:<xx.yy>-py3
<xx.yy> の部分はバージョンとなっていて、Ubuntu、CUDA、TensorRTのバージョンに合わせて選択します。
リリースノートを参照しながら、筆者環境では20.03を選択しました。
$ docker pull nvcr.io/nvidia/tritonserver:20.03-py3
model repositoryの作成
サンプルとしていくつかモデルがダウンロードできるようになっているので、githubのコードから./fetch_models.shを実行します。これにより複数個のモデルが配置されます。
git clone https://github.com/NVIDIA/triton-inference-server
cd triton-inference-server
git checkout r20.03
cd docs/examples
./fetch_models.sh
Triton Server で推論したいモデルは model repository に置きますが、その位置は docs/example/model_repository になります。
サーバの実行
まずはサーバを立ち上げます。以下のコマンドで /models に model_repository をマウントできるようにします。
cd triton-inference-server
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $PWD/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:20.03-py3 trtserver --model-repository=/models
注意するのは、20.03までは trtserver という名前で、以降は tritonserver な点です。これでGPUの認識及び model_repository 以下にあるモデルがGPU上に展開されるログが表示されていると思います。最後にhttpserviceなど3つのサーバがスタートしていることが表示されればOKです。
=============================
== Triton Inference Server ==
=============================
NVIDIA Release 20.03 (build 11042949)
Copyright (c) 2018-2019, NVIDIA CORPORATION. All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION. All rights reserved.
NVIDIA modifications are covered by the license terms that apply to the underlying
project or file.
2020-11-29 11:05:38.961638: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.2
I1129 11:05:39.008650 1 metrics.cc:164] found 1 GPUs supporting NVML metrics
I1129 11:05:39.014088 1 metrics.cc:173] GPU 0: Quadro P6000
I1129 11:05:39.014403 1 server.cc:120] Initializing Triton Inference Server
I1129 11:05:39.334589 1 server_status.cc:55] New status tracking for model 'densenet_onnx'
I1129 11:05:39.334616 1 server_status.cc:55] New status tracking for model 'inception_graphdef'
I1129 11:05:39.334640 1 server_status.cc:55] New status tracking for model 'simple'
...
Starting endpoints, 'inference:0' listening on
I1129 11:05:42.585518 1 grpc_server.cc:1939] Started GRPCService at 0.0.0.0:8001
I1129 11:05:42.585571 1 http_server.cc:1411] Starting HTTPService at 0.0.0.0:8000
I1129 11:05:42.629039 1 http_server.cc:1426] Starting Metrics Service at 0.0.0.0:8002
これでAPIの状態などをチェックすることができます。
curl localhost:8000/api/status
id: "inference:0"
version: "1.12.0"
uptime_ns: 6718051588331
model_status {
key: "densenet_onnx"
value {
config {
name: "densenet_onnx"
platform: "onnxruntime_onnx"
version_policy {
latest {
num_versions: 1
}
}
input {
name: "data_0"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: 3
dims: 224
dims: 224
reshape {
...
クライアントの実行
次にクライアント側を実行します。
docker pull nvcr.io/nvidia/tritonserver:20.03-py3-sdk
docker run --rm --net=host -it nvcr.io/nvidia/tritonserver:20.03-py3-clientsdk
コンテナに入ることができたら、pythonコードを実行し、画像の分類モデルのリクエストを投げて結果を表示してみます。
python /workspace/install/python/image_client.py -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
Request 0, batch size 1
Image ‘/workspace/images/mug.jpg’:
504 (COFFEE MUG) = 13.901954650878906
968 (CUP) = 12.000585556030273
967 (ESPRESSO) = 9.819758415222168
これでdensenetによる画像分類ができ、/workspace/images/mug.jpgに対しCOFFEE MUGの画像と推論ができました。
image_client.pyでは、引数でモデルを指定しています。-mでdensenetモデルを選択肢、-cで上位3つの結果を返すように設定しています。
これで、サーバ側とクライアント側の動きを試すことができました。
モデルの配置の仕方
新しいモデルを配置してサーバで読むにはどうするのか?というとmodel_repositoryに設定されたルールやパスを記述して読み込ませることができます。docs/example/model_repositoryがそのまま参考になりますが、こういった構成で配置することになります。
models/
+-- densenet_onnx # モデルの名前
| +-- config.pbtxt # 設定ファイル
| +-- output_labels_file.txt # クラス名のファイル
| +-- 1/ # バージョン
| +-- saved_model.pb
...
モデル名のフォルダの下に、設定ファイルとバージョンを示すフォルダがあり、そのフォルダの下にバイナリファイル(重みパラメータであるモデルファイル)を配置します。設定ファイルは、例えばdensenet_onnxの場合はこのように記述されています。
name: "densenet_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 0
input [
{
name: "data_0"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 224, 224 ]
reshape { shape: [ 1, 3, 224, 224 ] }
}
]
output [
{
name: "fc6_1"
data_type: TYPE_FP32
dims: [ 1000 ]
reshape { shape: [ 1, 1000, 1, 1 ] }
label_filename: "densenet_labels.txt"
}
]
入力と出力の形式を記述するのはもちろん、platformでモデル自体の形式を指定します。TensorRT化されたモデルであればtensorrt_plan、TFのsaved_modelであればtensorflow_savedmodelと記載します。
このようにしてモデルを配置したらもう一度サーバ側のdockerコンテナを立ち上げることで、新しく配置したモデルが読み込まれリクエストを投げて推論することができます。
物体検出モデルの推論
次に、分類モデル以外の例として、みんな大好き物体検出アルゴリズムyolov3をTISに載せて推論してみます。
学習のフレームワークとしてdarknetで学習したモデルをTensorFlowのsavedmodelとしてpbで読み込む方法と、TensorRT化した上でデプロイする2つ方法がありますが、今回は前者でやってみようと思います。
モデルの設定
今回のモデルはTensorFlowの savedmodel を使うこととします。この場合はdarknetの重みからpbへ変換して上げる必要がありますが、その部分は下記レポジトリが参考になります。
https://github.com/zzh8829/yolov3-tf2
TensorFlow Serving の例でexportできる部分があるので、これをもとにpb化してきます。
python export_tfserving.py --output serving/yolov3/1/
続いて、yolov3のモデルを配置するにあたり、設定ファイルを書く必要があります。yolov3.pbtxtはこんな感じで書くことができます。モデル名(フォルダ名)はyolov3_tfとしています。
name: "yolov3_tf"
platform: "tensorflow_savedmodel"
max_batch_size: 64
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: -1
dims: -1
dims: 3
}
]
output [
{
name: "yolo_nms_0"
data_type: TYPE_FP32
dims: -1
dims: 1
dims: 4
},
{
name: "yolo_nms_1"
data_type: TYPE_FP32
dims: -1
dims: -1
},
{
name: "yolo_nms_2"
data_type: TYPE_FP32
dims: -1
dims: -1
}
]
instance_group [
{
kind: KIND_GPU
count: 1
gpus: [0] # 使用するGPUの指定
}
]
最後のinstance_groupではCPU/GPUどちらで実行するのか、GPUの場合どのGPUで何並列で実行するのかを設定できます。
ここまでできたら、サーバ側でyolov3モデルを読み込むよう再度立ち上げます。
docker run --gpus=1 --rm -p 8000:8000 -p 8001:8001 -p 8002:8002 -v $PWD/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:20.03-py3 trtserver --model-repository=/models
クライアント側の設定
続いてクライアント側です。
yolov3のクライアント例を作っている先人のdocker image[3]を参考にしながら画像描画部分を修正しgRPC経由でリクエストを投げ推論する、ことをやってみたいと思います。
docker pull srijithss/tensorrtserver_client:latest
docker run -it -v $PWD/:/opt/code srijithss/tensorrtserver_client:latest bash
コンテナに入ったらpython trtserver_test.pyが実行できますが、そのままだと表示が見づらいので、inference.pyとして少し修正します。
def draw_outputs(self, img, outputs):
boxes, objectness, classes, nums = outputs
boxes, objectness, classes, nums = boxes[0], objectness[0], classes[0], nums[0]
for i in range(nums):
x1y1 = tuple((np.array(boxes[i][0:2]) * self.wh).astype(np.int32))
x2y2 = tuple((np.array(boxes[i][2:4]) * self.wh).astype(np.int32))
label = self.class_names[int(classes[i])]
class_num = 0
for name in self.class_names:
if label == name:
class_num = self.class_names.index(name)
break
cv2.rectangle(img, x1y1, x2y2, self.class_colors[class_num], 2)
text = label + " " + ('%.2f' % objectness[i])
tlx = x1y1[0]
tly = x1y1[1]
cv2.rectangle(img, (tlx, tly - 20), (tlx + 110, tly), self.class_colors[class_num], -1)
cv2.putText(img, text, (tlx, tly-5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,0), 1)
return img
def process(self):
img = cv2.imread(self.args.img)
if self.wh is None:
self.wh = np.flip(img.shape[0:2],0)
frame_rgb = self.bgr_to_rgb(img, self.args.yolo_size)
frames = []
frames.append(frame_rgb)
responses = []
yolo_generator = partial(request_generator, self.yolo_request, frames)
responses = self.grpc_stub.StreamInfer(yolo_generator())
for response in responses:
boxes, scores, classes, nums = process_yolo_response(response)
img_out = self.draw_outputs(img, (boxes, scores, classes, nums))
cv2.imwrite('result.jpg', img_out)
これでdarknetでおなじみの画像に推論してみると以下のようになります。
python inference.py --img ./dog.jpg

このように、TISにモデルを載せるためにはどのフレームワークで学習しTISがサポートするフレームワークに変換できるかどうか、設定ファイルを正しく記述しているかが重要となります。一回載せてさえしまえば、httpまたはgRPC経由でAPIとして機械学習モデルを利用することができるのは便利だなと思います。
ただし設定ファイルの書き方やクライアント側の書き方もgRPCに慣れていないと難しかったです。src/clients/python/examplesにいくつかサンプルがあるのでこの辺が参考になります。(C++, go もある)
おわりに
Triton Inference Server を使って画像認識モデルの推論を試してみました。
ほかのタスク(音声認識など)をデプロイしたり、torchscript 形式での実行やonnxでの実行など検証したいことはほかにもあるので、それらが今後の課題です。
Jetsonシリーズではあまりなさそうですが、GPUクラスタでの実行において今後もServingのフレームワークは重要なポイントになりそうです。