はじめに
こんにちは。@dcm_yamaya です。
画像認識やエッジコンピューティングの技術領域を担当しています。
エッジ側での画像認識を実現するデバイスとして NVIDIA の Jetson シリーズがあります。
今年は Jetson Nano が新しく発売され、直近では Jetson Xavier NX
がリリースされました。
エッジ側での画像認識をリアルタイムに、精度良く実現しようとすると出てくる課題があります。潤沢なGPU環境で学習させたモデルをそのまま Jetson シリーズに
デプロイしてもGPUメモリに載り切らず実行できなかったり、載ったとしても目標とする fps が得られなかったりします。
そうした場合に、学習モデルを NVIDIA GPU に最適化することで高速化できる TensorRT というライブラリがあります。TensorRT は最新のバージョンは6であり、3D CNNやLSTMにも
対応しているようです。
https://developer.nvidia.com/tensorrt#tensorrt-whats-new
Jetson シリーズはいまのところ TensorRT 5.1.6 が Jetpack 4.2.1 or 4.2.2 により導入でき、TensorRT 5 代になり使いやすくなってきています。ですがドキュメントがそう多くなかったりデバイスやフレームワークによってまずどこから試すのがよいか結構悩んだりします。
そこで今回は、筆者が今年取り組んだ、 Jetson シリーズで TensorRT を使い高速化する方法をフレームワーク別に2019年版としてまとめたいと思います。どれかのニーズに当てはまれば幸いです。
対象とする人
- Jetson シリーズを使ってみたい
- エッジデバイスでの画像認識の推論をしてみたい
やること
- Jetson と TensorRT の紹介
- フレームワーク別 TensorRT の使い方
NVIDIA Jetson シリーズ と TensorRT
NVIDIA Jetson シリーズ
NVIDIA の Jetson シリーズはGPUを搭載した組み込みコンピュータボードで、nano, tx2, xavier の大きく3種類が現行の種類で、11月には新しく Xavier NX が仲間入りしました。

Maxwell 世代の Tegra X1 ではありますが、Jetson nano が最も安価に入手でき手軽に画像認識を試すにはもってこいのエッジコンピュータといえます。

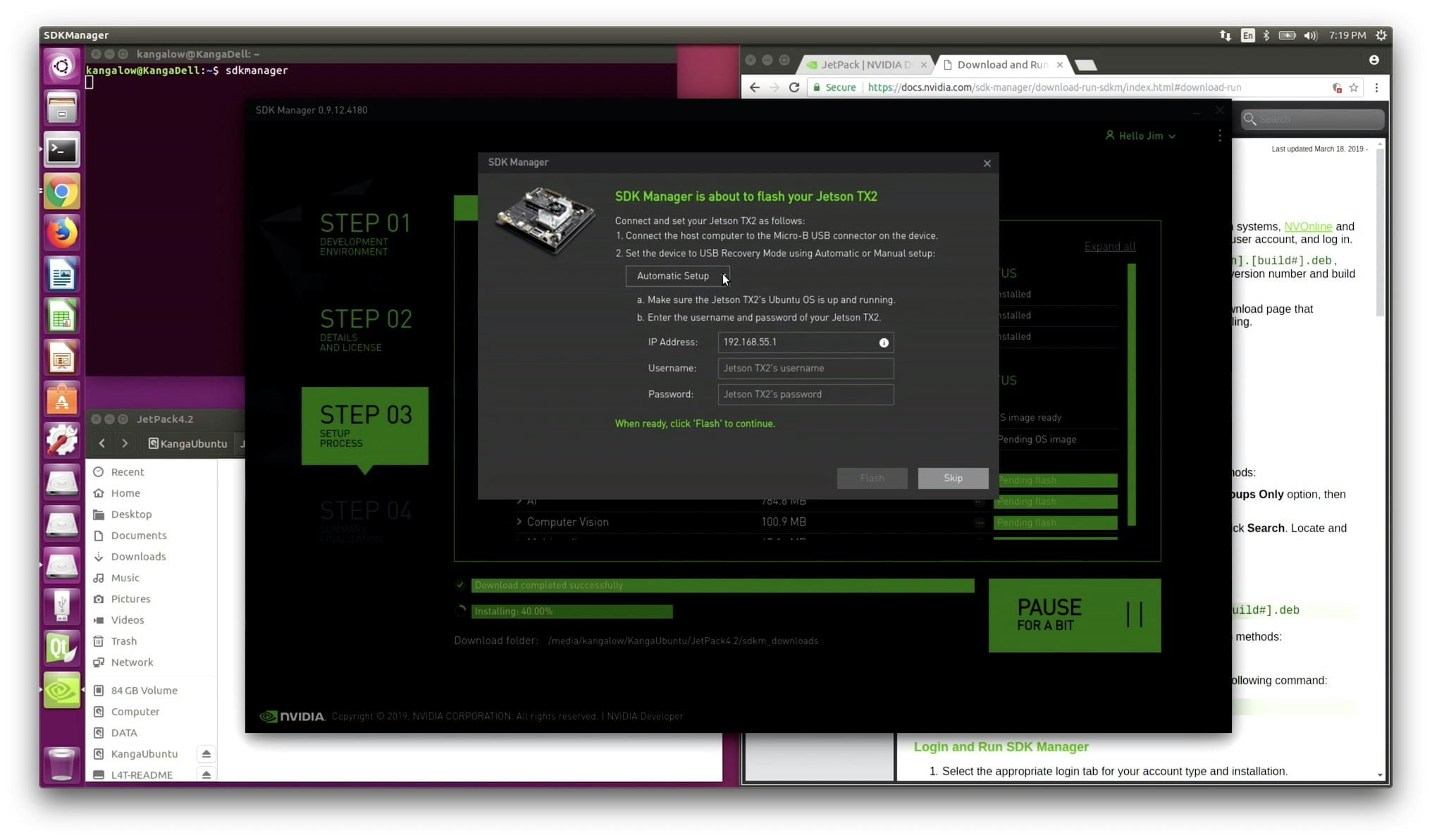
Jetson へのOSはJetPack SDKというSDKで管理され、そのフラッシュは SDK Manager と呼ばれるアプリケーションですることができ、Ubuntu が動作するPCをホストとして必要となります。最新のバージョンは JetPack 4.2.2 となります。
TensorRT とは
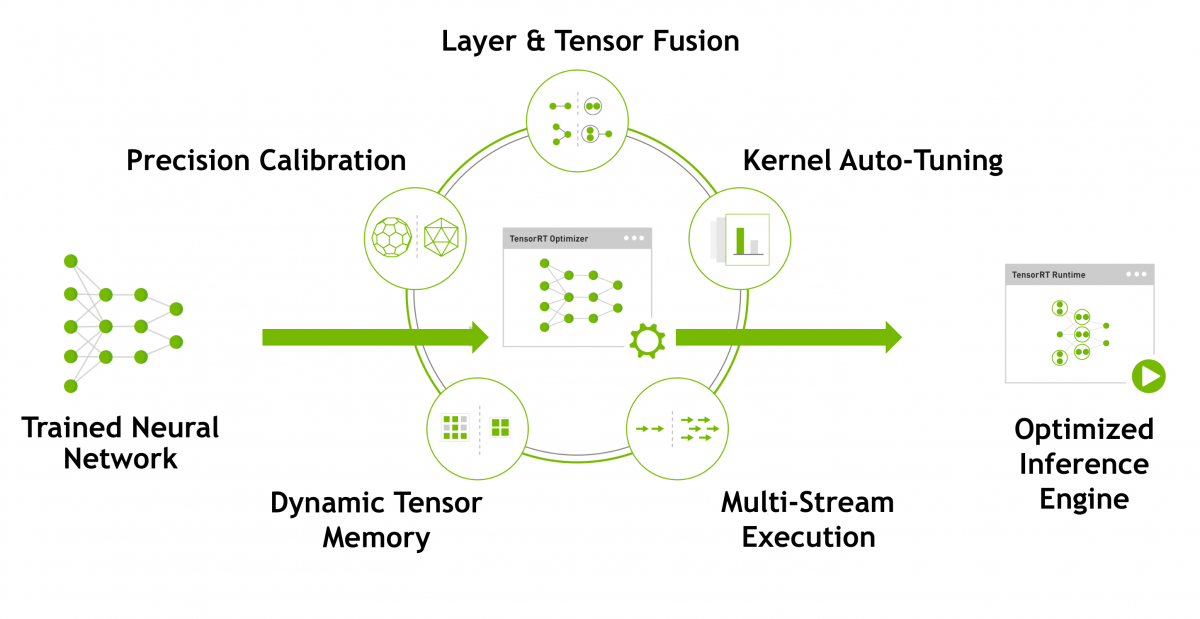
TensorRT は 推論処理を実行する NVIDIA の GPU に対して convolution の演算などを最適化することにより推論を高速化するライブラリです。32bit浮動小数点で学習させたモデルを16bit浮動小数点でビルドすることによりファイルサイズや使用メモリを1/3~1/2とすることができます。Jetson シリーズだけではなく、Tesla や Quadro などのGPUに対してももちろん利用でき、推論精度をほぼ維持したまま実行を高速化することができます。
Jetson で利用できる TensorRT の最新バージョンは現在 5.1.6 となっており、JetPack 4.2.1 or 4.2.2 をフラッシュするとインストールされています。JetPack 4.2 では TensorRT 5.0.6 がインストールされており、異なる TensorRT バージョンでビルドしたモデル(拡張子が .trt の推論エンジン)は下記のエラーで実行できなくなることに注意が必要です。
[TensorRT] ERROR: The engine plan file is not compatible with this version of TensorRT, expecting library version 5.1.6 got 5.0.6, please rebuild.
また Release Notes を見ると、Jetson 向けと 普通のGPU 向けはバージョニングが異なっています。普通のGPU向けには 5.1.5 が 5系の最新版で、次は 6 系となっています。
https://docs.nvidia.com/deeplearning/sdk/tensorrt-release-notes/index.html
このようにGPUに最適化するがゆえにバージョニングにシビアであったり、学習モデルをどのフレームワークで学習したかなどによりTensorRTの適用の仕方が変わってきたりします。そこで、次節以降では画像認識モデルを Jetson で高速化するために必要な手順を紹介します。
フレームワーク別 TensorRT の使い方
画像認識でよく用いられる次の3つのフレームワークで学習したモデルに対して TensorRT 化する方法を紹介します。
- darknet yolov3 and tiny-yolov3
- TensorFlow or Keras
- Pytorch
対象となる Jetson は nano, tx2, xavier いずれでもOKです。ただし TensorRT==5.1.6 つまり JetPack 4.2.1 or 4.2.2 がフラッシュされていることを確認してください。
darknet yolov3 and tiny-yolov3
ここ最近で物体検出のアルゴリズムとして最近よく用いられるのは yolov3 かと思います。
yolov3 の著者が学習/推論をサポートする darknet というフレームワークが有名ですが、これに
TensorRT 5.0.6 と TensorRT 5.1.6 では対応しています。
以下のドキュメントが参考になります。
https://docs.nvidia.com/deeplearning/sdk/tensorrt-sample-support-guide/index.html#yolov3_onnx
流れとしては、darknet の weight -> onnx -> trt
という2段階の変換を行います。以下にソースコードがあるのでこちらを利用します。
/usr/src/tensorrt/samples/python/yolov3_onnx
まず weight -> onnx は yolov3_to_onnx.py によって変換できます。
darknetのサイトにあるモデルや自身で学習したモデル(weightsファイル)とcfgファイルを
用意することでonnxモデルへの変換ができます。この処理はJetson上で行わなくてもよいです。
次に onnx_to_tensorrt.py によって .trt エンジンをビルドします。このとき、32bit 浮動小数点のモデルから 16bit 浮動小数点のエンジンとしてビルドしたい場合は以下のように1行加えるだけでOKです。
builder.fp16_mode = True
16bitにした場合はかなり時間がかかります。無事にビルドできると、物体検出の結果が画像として書き込まれ出力されます。
tiny-yolov3 モデルの変換
yolov3 モデルの変換はこのように付属のサンプルがそのまま使えますが、 tiny-yolov3 の場合はyolov3_to_onnx.pyについて少し修正が必要です。
まずはtinyで学習した際のcfgとweightsをもってきて、ファイルパスを更新します。
cfg_file_path = '/home/nvidia/yolov3-tiny.cfg'
weights_file_path = '/home/nvidia/yolov3-tiny.weights'
output_file_path = 'yolov3-tiny-model.onnx'
次に、cfgの中でtinyにあってyolov3では登場しない [maxpool] レイヤーを処理できるように、supported_layersに追加してあげます。
supported_layers = ['net', 'convolutional', 'shortcut',
'route', 'upsample', 'maxpool']
この [maxpool] レイヤーを処理するメソッドを加えます。
def _make_maxpool_node(self, layer_name, layer_dict):
stride=layer_dict['stride']
kernel_size = layer_dict['size']
previous_node_specs = self._get_previous_node_specs()
inputs = [previous_node_specs.name]
channels = previous_node_specs.channels
kernel_shape = [kernel_size, kernel_size]
strides = [stride, stride]
assert channels > 0
maxpool_node = helper.make_node(
'MaxPool',
inputs=inputs,
outputs=[layer_name],
kernel_shape=kernel_shape,
strides=strides,
auto_pad='SAME_UPPER',
name=layer_name,
)
self._nodes.append(maxpool_node)
return layer_name, channels
そして yolov3 では [yolo] レイヤーが3つありますが tiny では2つになるので、この点も修正してあげます。画像の入力サイズを608として学習した場合の例です。
yolo_wh = 608
output_tensor_dims = OrderedDict()
kernel_size_1 = yolo_wh / 32
kernel_size_2 = yolo_wh / 16
output_tensor_dims['016_convolutional'] = [18, kernel_size_1, kernel_size_1]
output_tensor_dims['023_convolutional'] = [18, kernel_size_2, kernel_size_2]
そして最後に地味にはまるのが、onnx==1.4.1でなければいけないこと(最新版を入れるとエラーが起こる。。)と、cfgファイルに最後改行を入れないとうまくパースされないという点です。\n\nと2回の改行が前提で書かれている部分があるため、ご自身のcfgファイルの最後に改行を加えてください。
layer_param_block, remainder = remainder.split('\n\n', 1)
こうすることで、onnx への変換ができ、onnx_to_tensorrt.py でtrtエンジンを生成します。postprocessor_args で yolo_masks と yolo_anchors をtiny版に修正すればOKです。
postprocessor_args = {"yolo_masks": [(3, 4, 5), (0, 1, 2)],
"yolo_anchors": #学習時のcfgの値を記載,
...
TensorFlow or Keras
TensorFlow や Keras で学習したモデルは以下の手順で変換していきます。最終的にuff(universal file format)形式のモデルになればTensorRTで使えるようになります。
.h5 -> frozen graph -> .uff
hdf5からpbへの変換
現在この例で参考になるのは donkey-car プロジェクトです。用意してくれているスクリプトを参考にします。
https://github.com/autorope/donkeycar/blob/dev/scripts/freeze_model.py
hdf5 形式の学習モデルを、frozen graph 化(.pb)します。
freeze_model.py --model="mymodel.h5" --output="frozen_model.pb"
pbからuffへの変換
続いて、frozen graph から uff形式へ変換します。uff 変換するための convert-to-uff はワークステーションなどのマシンを使用する場合には以下の TensorRT インストール手順に導入方法があります。
https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html?ncid=afm-chs-44270&ranMID=44270&ranEAID=a1LgFw09t88&ranSiteID=a1LgFw09t88-QLrg.XlEHbnD3ysmVgDR7w#installing-tar
ので、convert-to-uff が使える場合は、以下で変換します。
convert-to-uff frozen_model.pb -o model.uff
Jetson 上で変換する場合には、以下のような変換スクリプトを組んであげるのがよいです。uff.from_tensorflow_frozen_model()というメソッドがあるのでこれで変換ができます。 output_nodesにはfreezeしたときの .metadata ファイルを参考にすればよいです。
import uff
uff.from_tensorflow_frozen_model('fronzen_model.pb', output_nodes=output_names, output_filename='model.uff')
uff でJetson上で推論させようとすると起こる問題
これで TensorRT から読み込めるようなったので、推論してみます。 donkeycar で用意してくれているスクリプトを参考になります。
https://github.com/autorope/donkeycar/blob/dev/donkeycar/parts/tensorrt.py
これがuffモデルをloadするスクリプトになっているので、変換したuffモデルを読ませてあげればよいです。
しかし筆者の Jetson TX2 で試した場合には以下のようなエラーがでました。
Cudnn Error in configure: 7 (CUDNN_STATUS_MAPPING_ERROR)
これは infer メソッドの中で、入力画像をCPUからGPUに転送するときに起こっているっぽい。
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device_memory, inp.host_memory, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host_memory, out.device_memory, stream) for out in outputs]
cudaのmemcpyには async でなく sync するメソッドがあるので、試しに非同期処理から同期処理に変えたところ、エラーは出なくなりきちんと推論できるようになりました。(がしかしせっかく複数ストリーム流せるよさは失われそう…)
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
[cuda.memcpy_htod(inp.device, inp.host) for inp in inputs]
context.execute(batch_size=batch_size, bindings=bindings)
[cuda.memcpy_dtoh(out.host, out.device) for out in outputs]
return [out.host for out in outputs]
Pytorch
Pytorch モデル(.pth)を TensorRT にかけるには、torch2trt というライブラリを使うのが便利です。NVIDIA-AI-IOT リポジトリにあるのでクローンしてきます。
使い方などは丁寧に Jupyter でも記されているので、 TensorRT の環境さえあれば試しやすいのもよいです。抜粋すると以下のような形で .pth モデルの読み込みと推論ができてしまいます。(いままで見てきた手順に比べるとかなり楽ですね。。)
from torch2trt import torch2trt
# モデルの読み込みと推論
model_trt = torch2trt(model, [data], fp16_mode=True)
output_trt = model_trt(data)
おわりに
Jetson 上での TensorRT を使った画像認識の推論の高速化方法 @ 2019年版 についてまとめてみました。いずれかの方法が Jetson シリーズを触り始めた方のとっかかりになれば幸いです。