10回クイズとは
「『シャンデリア』って10回言って?」
「シャンデリアシャンデリアシャンデリア……」
「毒リンゴを食べたのは?」
「シンデレラ」
「白雪姫でしたー」
「……」
準備
とりあえず動かしてみたい人は実装まで読み飛ばしてください。
構造の分析
10回クイズをよく見てみると,登場する主な語は3つだけであることが分かります:
- 10回言わせる語(例: シャンデリア)
- 誤答(例: シンデレラ)
- 正答(例: 白雪姫)
さらに,この3つの語の間には,「シャンデリア」に対して,「シンデレラ」は少なくとも音韻的に類似,「白雪姫」は少なくとも意味的に類似しているという関係がありそうです(下図)。

音韻的な類似度と意味的な類似度に基づいて語の組合せを選択できるということは,以下の手順を踏めば,計算機にも10回クイズっぽいものは作れそうです。
- 10回言わせたい語をユーザに入力させる
- 10回言わせたい語に**音が近い語(誤答)**を選択する
- 誤答に**意味が近い語(正答)**を選択する
- (10回言わせたい語, 誤答, 正答) のトリプルを出力する
なお,誤答を導く質問文は人間ががんばって考えるものとします。
音韻の類似度
本来はIPA1などをどうにかこうにか比較することで音韻の類似度とするべきだとは思いますが,本項では便宜的に,或る語のローマ字表記間の編集距離を音韻的類似度と仮定します。
編集距離(或いはレーベンシュタイン距離)は,或る文字列を別の文字列に変形する際に必要な手順(置換・挿入・削除)の最小回数のことで,2つの文字列間の類似度を示します。例えば,"kitten"-"sitting"間の編集距離は3です。
- kitten → sitten("k"を"s"に置換)
- sitten → sittin("e"を"i"に置換)
- sittin → sitting("g"を挿入)
意味の類似度
単語ベクトルのコサイン類似度を意味の類似度とします。単語ベクトルは,例えばword2vecという手法を使えば作成できます。
word2vecの解説はQiita上を問わず有形無形に存在するため,ここでは説明を省略しますが,簡単にいえば単語のベクトル表現(≒ 単語の意味)を獲得する手法のひとつです。
(そもそも)なぜ我々は10回クイズにひっかかってしまうのか
例えば,「オレンジ」や「バナナ」という語を見せられた後に「リ◯◯」と見せられると,多くの人が「リンゴ」を思い浮かべるでしょう。一方で,「音符」や「テンポ」という語を見せられた後に「リ◯◯」と見せられたら,「リズム」を思い浮かべるかも知れません。「リ◯◯」という実験刺激は同じなのに,事前に提示された刺激によって想起する語が異なる現象のことをプライミング効果といいます2。
10回クイズも同様に,「シャンデリア」(先行刺激)によって「シンデレラ」が比較的想起されやすい状態になっているところへ,「毒リンゴを食べたのは?」と質問されると,本来「白雪姫」と答えるべきなのに,意味の類似している語「シンデレラ」と誤って回答してしまいます。
なぜ先行刺激が後続する反応に影響を与えるのでしょうか。これは,人間の脳内において,言葉がランダムに格納されているのではなく,何らかの形で結びつき合っている(しかも意味や音韻の似た語同士は近くに固まっている)ためだと考えられています。人間の言語知識構造の表現は様々提案されていますが,代表的なものとして,Collins & Quillian (1969) によって提案された「意味ネットワークモデル」が挙げられます。
意味ネットワークは一般的に,下図のように表現されます(図はWikipediaから引用3,一部改変)。破線は音韻的な関係を表し,実線は意味的な関係を表します。
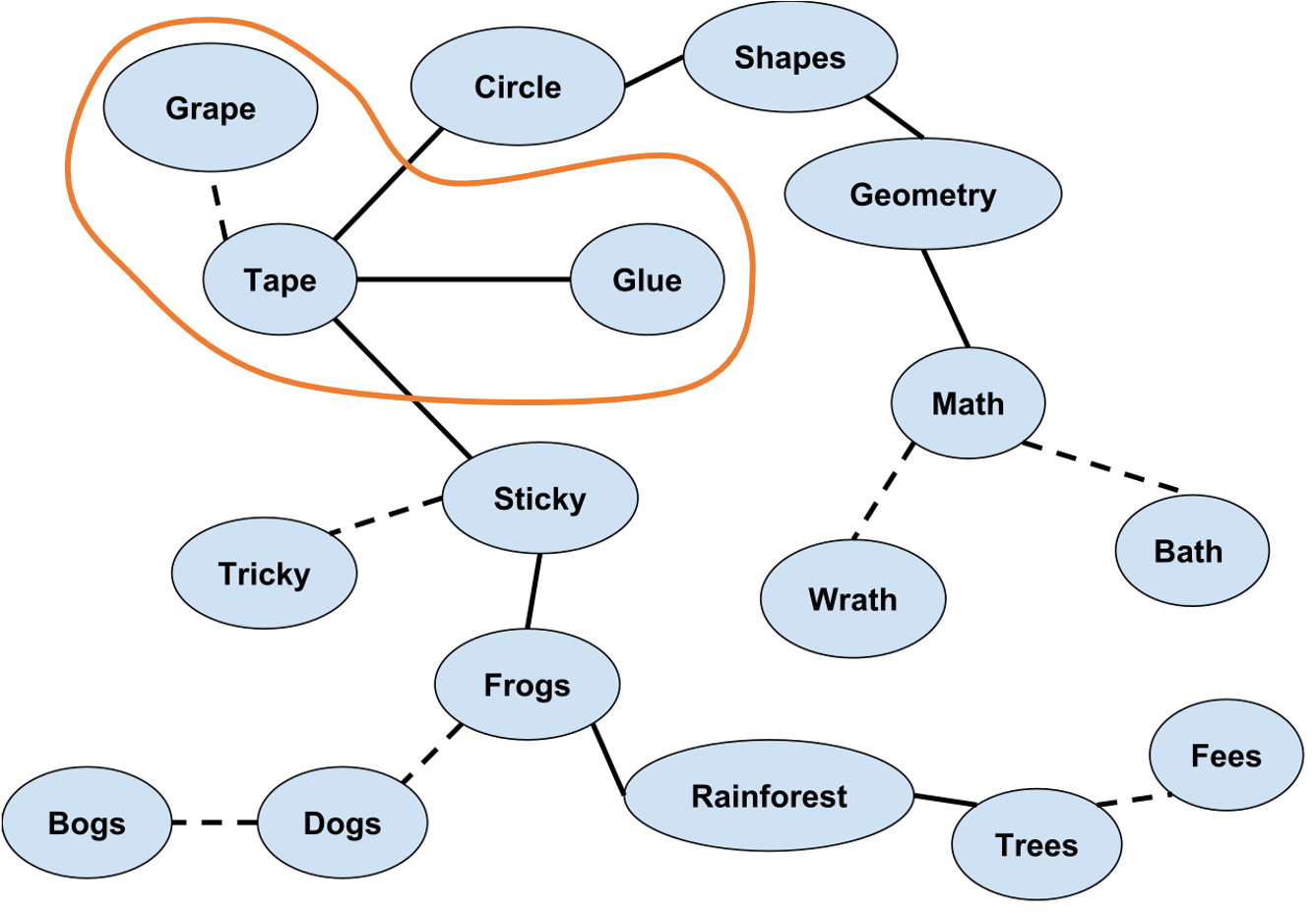
橙色で囲んだ部分に注目してみましょう。GrapeとTapeは発音が似ているので破線でつながっており,TapeとGlueは意味が近いので実線でつながっています。先ほどの「シャンデリア」「シンデレラ」「白雪姫」の関係と似ていますね。もし英語で10回クイズを作るなら,”Grape”と10回言わせて,"Glue"が正答,"Tape"が誤答となるような質問をしてあげるとうまく引っかかってくれそうです(あまり良い質問例は思いつきませんが)。
実装
それでは,先行刺激語$A$から,誤答$B$・正答$C$の候補を生成するプログラムを実装してみます。
Pythonのバージョンは3.7.3です。
入力の変換
まず,10回言わせたい語(入力)をローマ字に変換します。ローマ字への変換にはpykakasiを利用します。いつの間にかメジャーバージョンが上がっていたので,以下に示す書き方は古いAPIでの書き方です。
from pykakasi import kakasi
kks = kakasi()
kks.setMode('H', 'a')
kks.setMode('K', 'a')
kks.setMode('J', 'a')
kks.setMode('r', 'Hepburn')
conv = kks.getConverter()
print(conv.do('シャンデリア'))
# => 'shanderia'
誤答の選択
誤答となる語の候補を,入力された語との音韻的類似度に基づいて選択します。音韻の比較には,先述した通り,編集距離を利用します。このとき,編集距離を最長の文字数で割ることで正規化します。また,「距離」なので(数字が小さいほど類似していることになるので)1から減算して類似度とします。
実際に「シャンデリア」に対する類似度を計算してみると,「白雪姫」よりも「シンデレラ」の方が「シャンデリア」に音韻的に近いことが分かります。
import Levenshtein
def calc_normalized_edit_distance(yomi, yomi_candidate):
dist = 1. * Levenshtein.distance(yomi, yomi_candidate)
dist /= max(len(yomi), len(yomi_candidate))
return 1 - dist
print(calc_normalized_edit_distance('shanderia', 'shinderera'))
# => 0.7
print(calc_normalized_edit_distance('shanderia', 'shirayukihime'))
# => 0.3076923076923077
正答の選択
正答となる語の候補を,誤答との意味的類似度に基づいて選択します。意味の比較には,先述した通り,word2vecなどで作成した単語ベクトルを利用します。ベクトル表現は自分でWikipediaなどのコーパスから学習してもいいですし,公開されている言語資源を利用してもいいです。日本語のベクトル表現は,例えば東北大学が公開しています。
実際に「シンデレラ」との意味的類似度を計算してみましょう。「白雪姫」の方が「シャンデリア」よりも「シンデレラ」との意味的類似度が高いことを確認できます。
from gensim.models import KeyedVectors
word2vec = KeyedVectors.load_word2vec_format(
'jawiki.all_vectors.300d.txt',
unicode_errors='ignore'
)
print(word2vec.similarity('シンデレラ', 'シャンデリア'))
# => 0.53577656
print(word2vec.similarity('シンデレラ', '白雪姫'))
# => 0.79137415
結果の出力
入力された語から誤答と正答を選択できるようになったので,これらをまとめて出力します。だいたい下記のような雰囲気のプログラムになると思います。各誤答候補に対し,正答をひとつ出力するので,誤答候補個数分出力されます(とても遅いです。例えば,$B$/$C$の語彙を絞る,読みはあらかじめ辞書などに格納しておくなどすればもう少し早くなります)。
また,音韻的・意味的類似度にバイアスとしてそれぞれ$α$,$β$を乗算しています。本例だと両方とも$1.0$としていますが,結果を見ながら,或いは何かしらの指標に基づいてバイアスを調整すると,結果がよくなるかもしれません。
from pykakasi import kakasi
import Levenshtein
from gensim.models import KeyedVectors
class TenTimesQuiz(object):
def __init__(self):
self.alpha = 1.0 # 音韻的類似度に対するバイアス
self.beta = 1.0 # 意味的類似度に対するバイアス
kks = kakasi()
kks.setMode('H', 'a')
kks.setMode('K', 'a')
kks.setMode('J', 'a')
kks.setMode('r', 'Hepburn')
self.conv = kks.getConverter()
self.word2vec = KeyedVectors.load_word2vec_format(
'jawiki.all_vectors.300d.txt',
unicode_errors='ignore'
)
self.words = set(self.word2vec.vocab)
def get_yomi(self, word):
return self.conv.do(word)
def calc_normalized_edit_distance(self, yomi, yomi_candidate):
dist = 1. * Levenshtein.distance(yomi, yomi_candidate)
dist /= max(len(yomi), len(yomi_candidate))
return 1 - dist
def get_B(self, A):
# 10回言わせたい語Aから誤答候補Bを作成する
scores = []
A_yomi = self.get_yomi(A)
for B in self.words:
B_score = self.calc_normalized_edit_distance(A_yomi, B_yomi)
B_yomi = self.get_yomi(B)
scores.append((B_score, B, B_yomi))
return sorted(scores, key=lambda x: x[0], reverse=True)[:10]
def get_C(self, B):
# 誤答候補Bから正答候補Cを作成する
scores = []
for C in (self.words - set([B])):
C_score = self.word2vec.similarity(B, C)
C_yomi = self.get_yomi(C)
scores.append((C_score, C, C_yomi))
return sorted(scores, key=lambda x: x[0], reverse=True)[:10]
def calc(self, A):
if A not in self.word2vec:
print('not in word2vec')
return []
self.words -= set([A])
scores = []
f = lambda x, y: self.alpha * x + self.beta * y
B_scores = self.get_B(A) # 誤答候補の作成(10個)
for B_score, B, B_yomi in B_scores:
tmp_score = None
for C_scores in self.get_C(B): # 各誤答候補に対して正答候補をひとつ選択
C_score, C, C_yomi = C_scores
if tmp_score is None:
score = round(f(B_score, C_score), 3)
tmp_score = (B_score, C_score, B, C, score)
else:
if f(*tmp_score[:2]) < f(B_score, C_score):
# 正答候補を更新
score = round(f(B_score, C_score), 3)
tmp_score = (B_score, C_score, B, C, score)
scores.append(tmp_score)
return sorted(scores, key=lambda x: x[-1], reverse=True)
if __name__ == '__main__':
ten_times_quiz = TenTimesQuiz()
scores = ten_times_quiz.calc('シャンデリア')
このプログラムを使って,10回言わせたい語を「シャンデリア」としたときの結果を見てみましょう。最終スコアの上位10個を出力してみたのが以下の結果です。
| 音韻的類似度 | 意味的類似度 | 誤答 | 正答 | 最終スコア | |
|---|---|---|---|---|---|
| 1 | 0.7777777777777778 | 0.9309064 | シャンペリ | モンテイ | 1.709 |
| 2 | 0.7777777777777778 | 0.9103219 | ファンデリア | ラインデリア | 1.688 |
| 3 | 0.7777777777777778 | 0.8847987 | サンドリア | アレク | 1.663 |
| 4 | 0.7777777777777778 | 0.8408523 | シャンディア | カルガラ | 1.619 |
| 5 | 0.7 | 0.89138585 | シャンドリス | レイグル | 1.591 |
| 6 | 0.7777777777777778 | 0.8040835 | シャンベリ | Chambéry | 1.582 |
| 7 | 0.7777777777777778 | 0.78028136 | シャンドラ | コホリント | 1.558 |
| 8 | 0.7777777777777778 | 0.7781659 | サンテリア | 新古典主義建築 | 1.556 |
| 9 | 0.7 | 0.81578547 | シンデレラ | 人魚姫 | 1.516 |
| 10 | 0.7 | 0.81439954 | しゃんぐりら | ランプオブシュガー | 1.514 |
「シンデレラ」「人魚姫」の組合せの最終スコアは,トップではないものの,比較的高い結果になりました。これは人間の感覚とも一致していると言えるでしょう。
ちなみに,最高スコアである「シャンペリ」「モンテイ」は共に,スイス南部ヴァレー州モンテイ郡にある自治体です。
10回クイズとは
「『シャンデリア』って10回言って?」
「シャンデリアシャンデリアシャンデリア……」
「スイス南部ヴァレー州モンテイ郡の首都にあたる基礎自治体は?」
「……」
「モンテイでしたー」
「……」
-
情報処理推進機構ではなく国際音声記号 (International Phonetic Alphabet) のことです ↩
-
https://bsd.neuroinf.jp/wiki/%E3%83%97%E3%83%A9%E3%82%A4%E3%83%9F%E3%83%B3%E3%82%B0%E5%8A%B9%E6%9E%9C ↩