3年目社員の澤山です。業務では自然言語処理に関わる内容に取り組んでいます。
昨年度は Deep learning における日本語(と中国語)の 漢字の分割単位に関する記事を書かせていただきました。毎年たくさんの方に観ていただき感謝感激です。
さて,本年度15日目の記事では,GPT-2 をファインチューニングして遊んでみようと思います。
※ 記事は 2020/11 時点の内容です。ライブラリなどのアップデート等で処理に変更があるかもしれません。それぞれの動作環境等をご確認のうえ参考になさってください。
GPT-2 とは?
GPT-2 は, 最近ではすっかり有名になった, Transformer のデコーダをベースとした学習済みの大規模な言語モデルです。一方, エンコーダ側は BERT としても有名です。
GPT-2 は, RNN などと同様に自己回帰型のモデルで, トークン系列(プロンプト)を GPT-2 に入力すると, 次のトークンを順番に予測・出力していきます。最近では, 日本語の学習済みモデル も公開されていたりもします。今年はその後継モデルである GPT-3 も話題になりました。
ファインチューニングであそんでみよう!
GPT-2 や BERT といった大規模な事前学習済みの言語モデルの特徴として, QAタスクや文書要約, 分類といった他の言語処理タスクが解けるようにモデルをファインチューニングできるということが挙げられます。
今回はチュートリアルっぽく, 公開されている既存のデータを加工し, 実際にモデルのファインチューニングをしてみようと思います。
つくってみるもの
今回つくってみるものは, クローズドクエッション( Yes/No で解答できる質問)に対して, Yes/No を指定して解答させるようなシンプルなモデルです。
イメージ
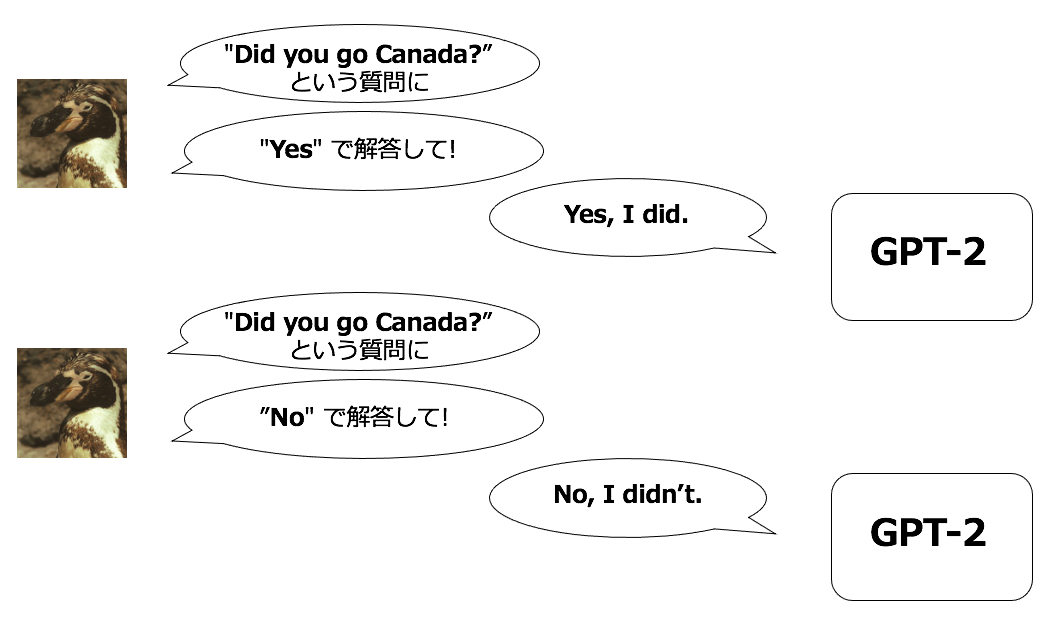
全体の流れは以下です。
- ファインチューニング用データ作成
- 作成したデータを用いたモデルのファインチューニング
- ファインチューニングしたモデルを用いた解答生成
環境
Python は 3.7.0 です。
今回利用する GPT-2 のソースコード, ならびに事前学習モデルは Hugging face の ライブラリである Transformers を利用しています。ライブラリのインストールと gitリポジトリのクローンをしました。
使った GPU は Tesla K80 でした。
ファインチューニング用データの作成
質問応答のデータが必要なので, 今回は, cornell movie dialog corpus をデータとして利用しました。こちらは, 映画の字幕から収集された会話のコーパスになります。
このデータは, pytorchのチャットボットチュートリアルでのデータ加工 でも利用されており, こちらのデータ処理を参考にデータの前処理をおこないました(先頭文字の小文字化などもおこなわれています)。
映画コーパスの前処理
ファインチューニング用データの前処理として, 上記チュートリアル内の Load and trim data の項目の, 低頻度語を取り除く処理の一つ手前までデータを前処理しました(ソースコードはほぼ同じなので割愛)。
低頻度語を取り除く処理を行わない理由として, 後続処理のtokenizerとして利用する GPT2 tokenizer がサブワードベースの分割器であり, 低頻度語をサブワードに分割してくれるためです。
前処理の結果, 以下のような形式のデータが得られます(チュートリアル内の出力結果と同じ)。1行ごとに, セリフ → セリフ となるようになっています。
['there .', 'where ?']
['you have my word . as a gentleman', 'you re sweet .']
['hi .', 'looks like things worked out tonight huh ?']
['you know chastity ?', 'i believe we share an art instructor']
['have fun tonight ?', 'tons']
['well no . . .', 'then that s all you had to say .']
['then that s all you had to say .', 'but']
['but', 'you always been this selfish ?']
['do you listen to this crap ?', 'what crap ?']
['what good stuff ?', 'the real you .']
テキストの前処理についてもう少し詳しく知りたい方は, 以前, テキストの前処理についての記事を書いているのでよかったら参考にしてください。日本語について書いていますが, 英語テキストにも応用できる部分があると思います。
追加処理: ファインチューニング用学習データへの加工
続いて, 前処理したデータをファインチューニング用学習データに加工します。加工内容は以下の通りです。
- 最初のセリフ と 後ろのセリフ の文区切り(split) や 文末(end of sentence) を識別するための特殊トークンの付与
-
<SPL>や<EOS>と言ったトークンです。
-
- 最初のセリフが質問でかつ, 後ろのセリフの先頭が yes/no である行をデータから抽出し, Yes/No トークンを付与
- 今回は上記の特殊トークンの形式に合わせて
<Yes><No>というトークン形式としました。入力と区切られてさえいれば,Yes |No |のような別の形式でも問題ないです。 - また, Yes, No 程度であれば, GPT-2へ入力する解答の先頭トークンを Yes/No に固定(指定)すれば, 出力させることももちろん可能です。今回は, ファインチューニング用データの特徴(解答内容や解答文長)を学ばせることを目的として, Yes/No トークンを付与するデータを作成しています。
- 今回は上記の特殊トークンの形式に合わせて
# ~ pytorchのチャットボットチュートリアルと同様の処理のため, 最終行以外は省略 ~
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# <--- ここからファインチューニング用データのための追加処理 ---->
# 先頭のセリフを question, 後ろのセリフを answer としています。
processed_questions = []
processed_answers = []
processed_qa = []
num_of_yn_questions = 0 # yes/no の質問の数
question_set = {"do", "does", "did", "have", "are", "am", "are", "is", "was", "were"} # クローズドクエスションの疑問詞
for pair in pairs:
processed_question = []
processed_answer = []
question, answer = pair[0], pair[1]
q_tokens = question.split(" ")
a_tokens = answer.split(" ")
if q_tokens[-1] == "?" and q_tokens[0] in question_set: # question の文末が "?" でかつ,先頭トークンが question_set に含まれている
if a_tokens[0] == "yes" or a_tokens[0] == "no": # answer の先頭トークンが yes/no
# answer側の処理
head_token_a = a_tokens[0][0].upper() + a_tokens[0][1:] # "Yes" or "No" 先頭文字を大文字にしておく
tail_tokens_a = a_tokens[1:]
processed_answer.append(head_token_a)
processed_answer += tail_tokens_a
#print("{}".format(processed_answer))
# question側の処理
head_token_q = q_tokens[0][0].upper() + q_tokens[0][1:] # "Yes/No 疑問詞"先頭文字を大文字にしておく。
tail_tokens_q = q_tokens[1:]
processed_question.append("<{}>".format(head_token_a))# questionの先頭に<yes>, <no>トークンをつける。
processed_question.append(head_token_q)
processed_question += tail_tokens_q
pair = [" ".join(processed_question), " ".join(processed_answer)]
print("{}".format(pair))
num_of_yn_questions += 1
processed_qa.append(pair)
print("number of y/n questions {}/{}".format(num_of_yn_questions, len(pairs)))
# number of y/n questions 731/64271
# 条件を満たす質問文は731文
# 映画コーパスなので, クローズドクエッションに正直に Yes/No で返さない文もある。Yes/No で答えている文は意外と少ない。
## 'do you listen to this crap ?'に対して 'what crap ?' と答えているなど。
# 学習,開発データに分割・保存
sample_size = 5000 # 今回は精度面を考慮しないので,ランダムサンプルしていません。
train = processed_qa[:-int(sample_size)]
valid = processed_qa[-int(sample_size):]
## cornell_movie_dialogs_corpus_for_gpt2 のフォルダを作成しておく(各自で名前決めてください)。
train_out_path = "./cornell_movie_dialogs_corpus_for_gpt2/train.txt"
valid_out_path = "./cornell_movie_dialogs_corpus_for_gpt2/valid.txt"
## 文の前後に付与するトークン
split_token = "<SPL>" # 文区切りの特殊トークン
eos_token = "<EOS>" # 文末特殊トークン
with open(train_out_path, "w") as f_train:
for qa in train:
q, a = qa[0], qa[1]
new_line = "{} {} {} {}\n".format(q, split_token, a, eos_token)
f_train.write(new_line)
with open(valid_out_path, "w") as f_valid:
for qa in train:
q, a = qa[0], qa[1]
new_line = "{} {} {} {}\n".format(q, split_token, a, eos_token)
f_valid.write(new_line)
上記処理の結果、以下の形式でデータが作成されました。
# 最初のセリフが質問(?を含む, 上記で定義したクローズドクエッション), かつ, 後ろのセリフの先頭が yes/no である行
<Yes> Are you quite sure ? <SPL> Yes really thank you very much . <EOS>
<No> Did you change your hair ? <SPL> No . <EOS>
# その他の行
there . <SPL> where ? <EOS>
you have my word . as a gentleman <SPL> you re sweet . <EOS>
hi . <SPL> looks like things worked out tonight huh ? <EOS>
you know chastity ? <SPL> i believe we share an art instructor <EOS>
have fun tonight ? <SPL> tons <EOS>
well no . . . <SPL> then that s all you had to say . <EOS>
then that s all you had to say . <SPL> but <EOS>
but <SPL> you always been this selfish ? <EOS>
do you listen to this crap ? <SPL> what crap ? <EOS>
what good stuff ? <SPL> the real you . <EOS>
ファインチューニング
では, 作成したデータをもとに, GPT-2 のファインチューニングをやってみます。
手順は, GPT-2 tokenizer を用いて文のトークナイズをしたのち, トークナイズした文でモデルをファインチューニングする感じです。
特殊トークンの分割処理の確認
入力文が GPT-2 tokenizer によってどのように分割されているか確認してみました。
GPT-2 tokenizer による分割後のトークンのid列みたところ, 先頭の Yes/No トークンが以下のように分割されました。
# "<Yes> Are you quite sure ? <SPL>" の分割
prompt_text: <Yes> Are you quite sure ? <SPL>
encoded_prompt: tensor([[ 27, 5297, 29, 4231, 345, 2407, 1654, 5633, 50260]])
# 先頭の "<Yes>" が "<", "Yes", ">" に分割されている
# "<No> Did you change your hair ? <SPL>" の分割
prompt_text: <No> Did you change your hair ? <SPL>
encoded_prompt: tensor([[ 27, 2949, 29, 7731, 345, 1487, 534, 4190, 5633, 50260]])
# 先頭の "<No>" が "<", "No", ">" に分割されている
学習
- Transformers のコード(
transformers/examples/language-modeling/run_language_modeling.py) を利用します。- トークナイズも含めてやってくれます。
- 特殊トークンを追加する処理はソースコードに追記する必要があります。
- あらかじめ用意されている特殊トークンの追加はこちらを参考にしました。
- Transformers のソースだと
tokenization_utils_base.pyの881行目に書いてありました。
- 利用する GPT-2 の事前学習済みモデルは, 用意されている中で一番小さい
gpt2です。この他にも,gpt2-medium,gpt2-large,gpt2-xlが利用できます。
python transformers/examples/language-modeling/run_language_modeling.py
--output_dir ./data/model_from_cornell_corpus/ # モデルの出力先, 各自で作っておいてください
--model_type=gpt2 # 利用する学習済みモデル
--model_name_or_path=gpt2
--do_train # 学習する設定
--train_data_file ./data/cornell_movie_dialogs_corpus_for_gpt2/train.txt # 学習データのパス
--do_eval # 評価する設定
--eval_data_file=./data/cornell_movie_dialogs_corpus_for_gpt2/valid.txt # 評価(開発)データのパス
--per_device_train_batch_size=2 # バッチサイズ
--per_device_eval_batch_size=2 # バッチサイズ
--num_train_epochs=10 # 学習エポック数
--save_steps=5000 # モデルを保存する頻度
--save_total_limit=3 # 保存するモデル数
# GPUの利用設定は各自の環境を確認してみてください。
ファインチューニング結果の確認
それでは, 学習されたモデルを用いて, 生成してみます。Transformers のサンプルコードの中にある run_generation.py を利用しました。こちらは最新版の Transformers を pip install した際には含まれていないので, Transformers の git リポジトリ から直接ダウンロードしてきました。
# 特殊トークンを付与しない
python transformers/examples/text-generation/run_generation.py --model_type=gpt2 --model_name_or_path="./data/model_from_cornell_corpus/" --prompt "Did you go to Canada ? <SPL>" --seed=${RANDOM} --stop_token="<EOS>"
=== GENERATED SEQUENCE 1 ===
Did you go to Canada ? <SPL> yes.
# 特殊トークンを付与する(Yes)
python transformers/examples/text-generation/run_generation.py --model_type=gpt2 --model_name_or_path="./data/model_from_cornell_corpus/" --prompt "<Yes> Did you go to Canada ? <SPL>" --seed=${RANDOM} --stop_token="<EOS>"
=== GENERATED SEQUENCE 1 ===
<Yes> Did you go to Canada ? <SPL> Yes i did. # Yesが出た。指定なしの時は小文字yのyesなので <Yes> トークンの指定が効いていることがわかる。
# 特殊トークンを付与する(No)
python transformers/examples/text-generation/run_generation.py --model_type=gpt2 --model_name_or_path="./data/model_from_cornell_corpus/" --prompt "<No> Did you go to Canada ? <SPL>" --seed=${RANDOM} --stop_token="<EOS>"
=== GENERATED SEQUENCE 1 ===
<No> Did you go to Canada ? <SPL> No! # Noが出た。
ファインチューニングの結果, Yes/No を識別して返答してくれるようになりました。
まとめ
- GPT-2 であそんでみた。
- 映画コーパスを加工してファインチューニング用データを作成
- 作成したデータで GPT-2 をファインチューニング
- ファインチューニングした GPT-2 で質問に対して Yes/No の解答文を生成
参考文献・サイト
-
今回利用したデータセット・前処理関連
-
GPT-2 関連
-
GPT-3 関連
その他所感
- 入社して2年半ちょっとですが, 社内勉強会等もあり,楽しめています。
- 大規模言語モデルの研究はいろんな方向に進み始めてますね。莫大な計算機パワーで一般人が作れないような巨大なモデルを構築し, モデルの分類精度を向上させる研究や, モデルの分類精度よりもタスクの課題が本当に解けているか,といったモデルの理解力をきちんと測定する論文が出てくるようになりました。
- 一方で,誰でも(ある程度)高精度な言語モデルを(手軽に)利用できるようになってきています。最近では, 日本語版の学習済みモデルも公開され始めていて, 日本語も色々できるようになってきたなぁと感じたりします。
- 大規模言語モデルを活用した便利なサービスが日本語でも増えていくといいですね。