2年目社員の澤山です。業務では自然言語処理に関わる内容に取り組んでいます。
昨年度は自然言語処理の前処理・単語分割に関する記事を書かせていただきました。たくさんの方に観ていただき感謝感激です。
さて,本年度5日目の記事は,Deep learningにおける日本語(と中国語)の 漢字の分割単位 について,既存の研究などを簡単にサーベイしてみましたので紹介します。
日本語言語処理における分割と漢字
近年,機械翻訳を発端として,単文の分割方法のひとつとして,単語単位の分割ではなく,サブワード(部分文字列)による分割が注目されています。
ツールとしてはsentencepieceなどが有名です。サブワード化によって,自然言語処理の各種タスクの精度が向上したという研究報告があります。
今年のACL(言語処理における最も権威ある国際学会)に固有表現抽出と品詞タグ付けにおいてどのサブワード表現・単位が適切かという論文がありました。結果を見ると,全体的にはサブワード化による恩恵があるように見えますが,日本語に注目すると,(他の言語と比較して)低い精度となったという報告がされています。
日本語でスコアが向上しなかった理由として,以下の可能性が考えられます。
- 英語などの言語とは異なり,日本語が表音文字と表意文字からなる言語であること
- 日本語のテキストをサブワード化したところで,(日本語の漢字の)多くは1文字に分割され,ほとんど文字単位と変わらないこと
- 表音文字と比較して,表意文字(の多く)の出現頻度が低いこと
- 文字種の多さ(漢字,カタカナ,ひらがな,アルファベット,記号)。
- 一つの言葉を表す方法として,表音文字と表意文字それぞれを用いた書き方が存在すること(携帯,けいたい,ケータイ)
- (多言語で事前学習したモデルを用いていることや,単純に日本語のデータがもっと必要だったなど,他の可能性もありそうです)。
機械学習のモデル側からすると,入力が文字や部分文字のid,ベクトル表現なので,文字そのものの構造や意味(例えば,漢字の部首といった構造・読み方)がわかりません。そのため,モデルに入力される漢字の意味表現は,学習データ中の出現頻度と周辺文脈に大きく依存します。つまり,エンコードする際に,多くの漢字が,それ自身の持つ意味表現を失っていることが,他のアルファベット等の表音文字列の言語と比べてスコアが低い一因なのではないかと考えられます。
漢字の部首情報の活用
日本語の漢字の分割・エンコードの観点において,モデルへ追加情報を入力する/与えることで,より分類や抽出精度を高めることができないのでしょうか。
日本人が普段何気なく使っている情報である,漢字の部首 は使えそうです。次章の例にあるように,漢字の部首からその単語が何か表すかを推測することができます。
メジャーな日本語言語処理においても,そのような文字そのものの構造情報を活用している例はそう多くはないように思います。入力された漢字を含む未知語や低頻度語をサブワード化することで減らす取り組みが一部では行われているものの,たとえば,機械翻訳のようなメジャーなタスクであってもUNK(未知語)や固有表現抽出ではMISC(その他の固有表現)と分類したまま扱っていることがほとんどです。
テキスト中の低頻度漢字でも,ぼやっと意味がわかる例
- 一般的なテキストにあまり出現しない漢字: 魴鮄
この漢字が読めなく/理解できなくても,人間は魚へんがあることから魚(もしくは魚介類)であることが推定できますよね。
このように,へん,つくりの情報を活用することで,これまで大規模なモデル上で未知語扱いになっていたものも,もう少し情報を与えることができるかもしれません。
実際に,後述する論文でも,まさに魚へんの漢字が例として紹介されていました。
ちなみに,表音文字である英語での魚の表記の例として,ナマズはcatfishと書きます。大規模なテキストを用いたサブワード化をおこなうと,catとfishの間で切られる可能性が高そうなので,精度向上が期待できそうですね。漢字にしたら「魚へん」に「猫」といったところでしょうか。
それでは,日本語(中国語)の漢字の分割とエンコードについて,どんな方法があるのかをみてみましょう.
漢字の分割/エンコード方法に関する論文
- 漢字を分割/エンコードする単位・方法として,以下のような論文が見つかりました(呼び名は各論文を参考)。
| 単位 | 内容 | 例 |
|---|---|---|
| word | 単語単位の分割 | 魴鮄 |
| character | 文字単位の分割 | 魴, 鮄 |
| subword | 部分文字列への分割 | 魴, 鮄(この単語であれば,多分characterと同じ) |
| subcharacter, radical-level | 部首単位,さらに小さい漢字単位への分割 | 魚, 方, 魚, 弗 |
| stroke | 書き順ごとの一画ごとに分割する | 論文5の図参照 |
| hiragana | すべてひらがなに変換する | ほうぼう |
| romanized | すべてローマ字に変換する | houbou |
| Visual form(image) | 漢字を画像として利用する | 論文6の図参照 |
| bytes | バイト文字列に変換する | b'\xe9\xad\xb4\xe9\xae\x84'(pythonで"魴鮄".encode()) |
| 部首/漢字の画数 | 追加情報として部首/漢字の画数を入力する | 11(魚), 4(方), 11(魚), 5(弗) |
- subcharacterに関しては,BERTやELMoといった文脈情報を扱える言語モデルでの検証はまだ少ないようで,さっと調べた感じだと見つけられませんでした。
- 論文間にまたがって分割単位が同じ部分がわかるように,分割ごとに色合いを変えた図を作成しました(見易さを優先し,作成した図の次元サイズ等は簡略化しています)。
- 論文リンクは下部の参考文献に記載しています。
1.Sub-character Neural language Modeling in Japanese (Nguyen et al.)

- 漢字の表現方法を部首(shallow)・さらに部首より小さい単位(deep)に分解。
- 言語モデルは単方向のLSTM
- 言語モデルのパープレキシティーの良さの順は,shallow > deep > baselineとなった。
- 論文内で紹介されている漢字の4つのデータセットを見ると,同じ漢字でもそれぞれ分類される部首単位が異なっていることがわかる。
- (コメント)より小さい構成単位にすればいいというわけではないみたいですね。
2.Subcharacter Information in Japanese Embeddings: When Is It Worth It? (Karpinska et al.)

-
近年,中国語で部分文字(部首)の情報が効果があることが示されており,同じ戦略が日本語でも適用できるか調査。
-
具体的には,漢字を部首のコンポーネントに分解して,各単位で扱った際の言語タスク(単語類似度・アナロジー・感情分類)での性能を調査,加えて,新しいデータセットを作った。
-
以下の複数の単位でSkip-gram(SG)
- 単語単位(SG)
- character単位(SG+kanji)
- subcharacter単位(SG+kanji+bushu)
-
結果として日本語での効果は部分的で,subcharacter単位よりも,character単位やcharacter単位のn-gramが良い精度のものが多かった。
3.Chinese–Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information(Zhang and Komachi)
- 表意文字の対訳ペア間での教師なし翻訳
- 文字単位,構成部首単位,書き順単位
- 構成部首単位,書き順単位が,ベースラインの文字単位よりもBLEUスコア(機械翻訳における参照訳と生成文の一致度)が向上
- (コメント)ふと思ったんですが,文字から画像への変換であれば部首の位置情報が入れられますが,部首分解して系列化すると,その部首が左にあるのか,上にあるのか区別できないですね(「景」と「映」の「日」が同じ系列順になる,みたいな)。
4.Which Encoding is the Best for Text Classification in Chinese, English, Japanese and Korean? (Zhang and LeCun)
- 日中韓(CJK, Chinese,Japanese,Korean)の各言語のテキストをどのエンコード単位で文書分類するといいかを網羅的に比較検証
- 文字, 単語, バイト化, ローマ字(文字), ローマ字(単語), 文字を画像化
- モデルは, CNN(OnehotNet, EmbedNet),線形モデル(ロジスティック回帰), FastTextの三つ
- CNNでは,「文字を画像化してエンコード・畳み込み」「バイト列にしてエンコード・畳み込み」「ローマ字化してエンコード・畳み込み」をしている。
- 日本語の前処理にはMeCab, python-romkanを利用
- CNNを使った分類をするときに,byte単位のone-hotエンコーディングがよかった。
- fastTextでの分類では,日中韓では文字レベルのn-gram, 英語は単語単位のn-gramが一番良かった。
- (コメント)ローマ字化するメリットとしては,漢字が表音文字化すること,加えて,音読み/訓読みの区別がされることです。一方,表意文字の持つ意味情報が失われるというデメリットもあります。直感的には,漢字とローマ字,両方使う方がいい気がします。音読みと訓読み(意味の読み方)の違いも分類に活用できたりしないでしょうか。訓読みは読みだけで意味がわかるもの(漢字でなくても意味がわかる)が多い,という特徴があったりしますし。
- (脱線)音読み・訓読みについての記事
- バイト文字に関しては,漢字が部首の順番で並んでいるものの,別の部首との境界が一文字違いだったりするので,うまく情報として活用できないのではないかと思います。
5.cw2vec: Learning Chinese Word Embeddings with Stroke n-gram Information(Cao et al.)

- 単語を文字に分解したのち,各文字を書き順ごとに一画ずつの系列に置き換え,n-gramを作って,embedding化(cw2vec, stroke n-gram)する。
- 単語類似度やアナロジー,テキスト分類,固有表現抽出などのタスクでword2vecやGloveよりも高い精度。
- 既存の手法よりも,漢字の形態と構造情報をうまく学習できた。
- 中国語に関する部分文字として,比較手法のGWEやJWEも参考になるかもしれない。
- (コメント)一画一画の書き順は初めてみましたが,分解しすぎな気が。
6.Utilizing Visual Forms of Japanese Characters for Neural Review Classification(Toyama et al.)

- 表意文字や,文字の形状(漢字を画像化して使う)を用いて,評判の分類(ドキュメント分類)を行なっている。
- 分類モデル自体は文字レベルの階層的atttention構造のRNN(HAN)を拡張する形で,文字レベルのRNNで各文字を入力する際に,文字画像化した情報もCNNで畳んで入力している。
- (コメント)画像にしちゃえというのは面白いアイディアだと思います。「へん」,「つくり」ごとのデータが不要になる点ではいいことですね。一方,漢字の構成要素の相対位置関係が取れている?ことは良いのですが,画像変換する場合は,どこまでが「へん」や「つくり」の境界なのかを区別できるのかなと気になりました。例えば,魚へんの上(クと田)と,下(点が四つの部分)が別物だと認識される可能性もありますし。
7.CNN-encoded Radical-level Representation for Japanese Processing (Ke and Hagiwara)
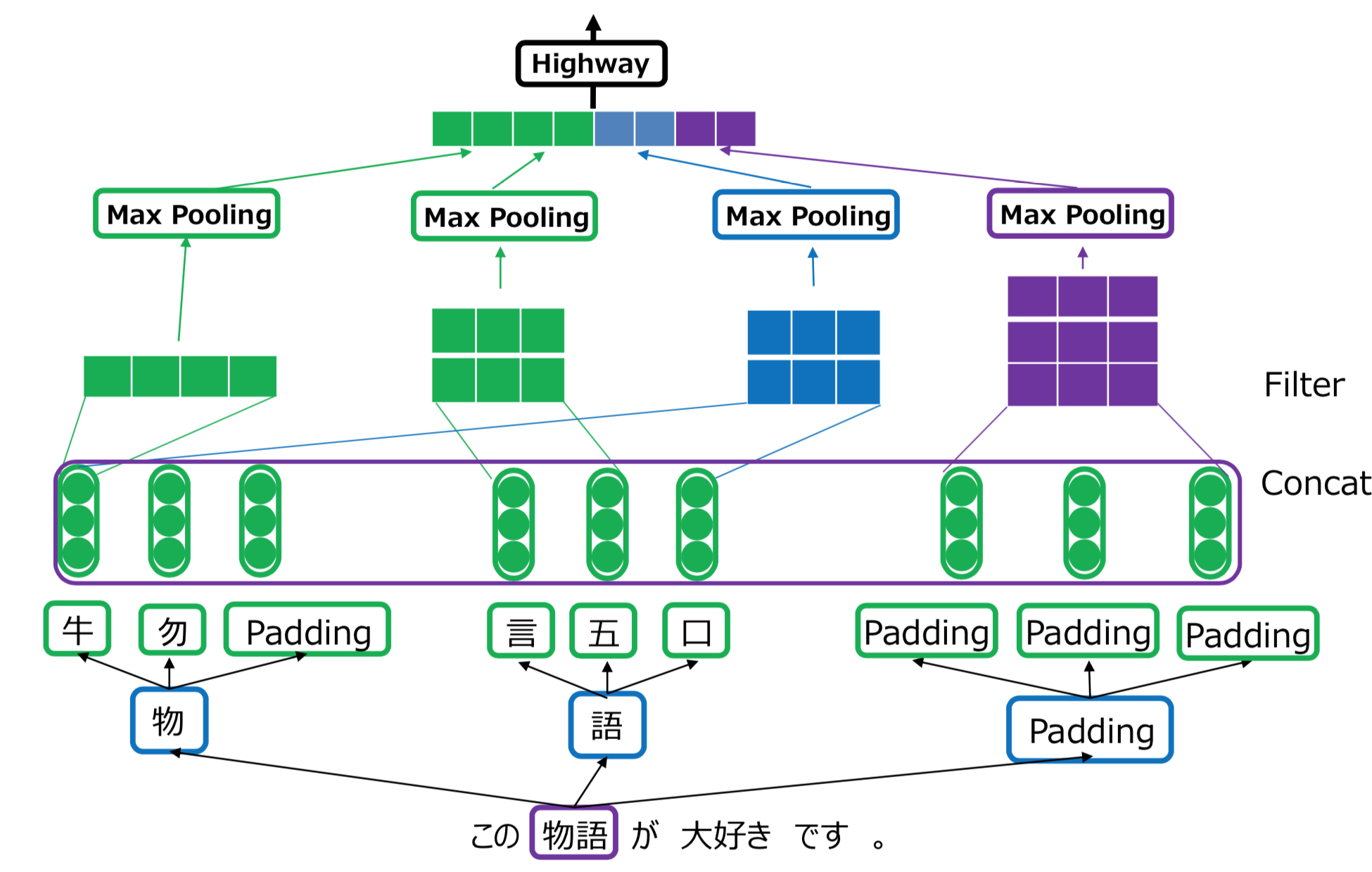
- 部首レベル(Radical-level)の埋め込み表現を作成し,極性判定。
- 単語レベルよりも学習パラメータを削減し,精度も向上。
- こちらの方の記事がわかりやすいです
- (コメント)単語や文字を固定長(3つ,4つ以上は切り捨て)に分解しているので,部首が三文字目まで同じだった場合は情報が失われていますが,やむなしな感じでしょうか。
- 一方,雲が3つに龍が3つの漢字などの画数のめちゃくちゃ大きい漢字は,どこまで細かく構造を捉えるかにもよりますが,「雲」や「龍」を部首の単位とするなら,情報としては十分かもしれませんね。
8.文字レベルの日中ニューラル機械翻訳における文字特徴情報の利用(張 and 松本)
- 文字の特徴量の1つとして「漢字の部首」,加えてその文字の表す概念の複雑さに関係する可能性のある「漢字の画数」を利用し,翻訳精度に影響があるかを調べた。
- 具体的には,日本語から中国語への文字レベルのニューラル機械翻訳において,「文字の埋め込みベクトル」に「文字の部首」,「部首の画数」,「文字全体の画数」を入力特徴情報として加え,BLEUが向上。
- (コメント)漢字の複雑性を取り入れるための追加素性として、画数を用いる手法は初めてみました。複雑性という観点では,「れっか(「熟」の下の四つの点)」と「手」が同じ画数(4)なのに,大きく構造が違うという例もあるので,やはり部首情報と一緒に用いることが必須なのではないでしょうか。
まとめ(と考察)
- 日本語や漢字を含む言語において,どんな漢字の分割・エンコード方法があるか,さくっと論文を調べてみました。
- 単語,文字,部首,ローマ字,バイト文字列,画像化,書き順,画数情報の追加等
- 近年の機械学習モデルを活用したそれぞれの研究/論文を見る限りでは,細かすぎない程度の単位で部首情報を用いることで精度改善しているため,漢字の構造や意味情報をモデル学習に活用する価値はありそうです。
- 漢字の文字構造を(部分的に)活用することで,低頻度の漢字の意味情報を拾うことができるので,小さいデータセットでは精度改善の効果が大きいかもしれません(単純にデータを集めて,整備するということも大事ですが)。例えば,機械翻訳などでは,とりあえず魚へんが含まれていれば,未知語であっても目的言語の出力時に,未知語ではなく,何らかの魚の言葉を出してくれる可能性が上がるので,多少伝達度合いは上がるのではないでしょうか。
- 加えて,このようなsubcharacterを活用することで,最近のBERTなどの巨大なモデル構造・巨大なコーパス量での殴り合いの流れから,DistilBERT, ALBERT等のモデルの蒸留・小型化の流れに進み始めているように,日本語などの表意+表音文字言語の言語モデル小型化(パラメータサイズ低減)の一助になるかもしれません。
- 日本語では,表音文字はsubword,表意文字は+αでsubcharacter情報を使うというように併用するのも一つのやり方かも。
- 近年登場した言語モデル(BERT, ELMo)では,subword単位での検証はされていますが,subcharacterでの検証はまだほとんどなさそうです。
参考文献
-
subword, subcharacter等の各種論文
- Chinese–Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information
- CNN-encoded Radical-level Representation for Japanese Processing
- Component-Enhanced Chinese Character Embeddings
- cw2vec: Learning Chinese Word Embeddings with Stroke n-gram Information
- Sequence Tagging with Contextual and Non-Contextual Subword Representations: A Multilingual Evaluation
- Subcharacter Information in Japanese Embeddings: When Is It Worth It?
- Sub-character Neural Language Modelling in Japanese
- Utilizing Visual Forms of Japanese Characters for Neural Review Classification
- Which Encoding is the Best for Text Classification in Chinese, English, Japanese and Korean?
- Workshop on Subword and Character LEvel Models in NLP(2018)
- 文字には有益な情報が詰め込まれている!?
- 文字レベルの日中・中日ニューラル機械翻訳における文字分解による低頻度文字の削減
- 文字レベルの日中ニューラル機械翻訳における文字特徴情報の利用
- 倉頡輸入法(中国語の部分漢字単位のキーボード入力)
- 魚へんの漢字(漢字ペディア)
- 英語で魚の名前 海の魚編
-
BERT/ELMo関連
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 多言語BERT README (漢字は一文字にtokenizeされるようになっているみたいですね)
- Deep contextualized word representations(ELMo)
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
- Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT
- ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
- 京大のBERT日本語pretrainedモデル(とりあえず日本語扱いたいって人は多言語BERTではなくこちらを使ってみましょう)
- 東北大のBERT日本語pretrainedモデル(MeCab利用, ライブラリtransformersで利用可能なモデル)
- Pre-trained Language modelの相関図(系譜)がありました。
-
トークナイザ
その他所感
- 入社して1年半ちょっとですが,内部で勉強会等もあり,楽しめてます。
- 時はBERT戦国時代,って感じですね。蠱毒感があります。
- こうやって調べてみると,改めて日本語は他の言語と比べて難しいし,面白い言語なんだなぁと思いました。
- 楽しんでいただけたなら幸いです。日本語言語処理にちゃんと貢献できるようになりたい。