はじめまして。NTTドコモのサービスデザイン部の奥原と申します。NTTドコモ R&D Advent Calendar 2021の16日目を担当いたします。
本記事ではログの統合分析ソフトウェアであるSplunkを利用したログ検索において、筆者がハマったポイントやSplunkの理解に有用だと思ったドキュメントを紹介します。(筆者の体力的に)今回紹介するトピックはSplunkのほんの一部のアーキテクチャや機能に限りますが、どなた様かのお役に立てれば幸いです🥰
1. はじめに 「Splunkとは?」
Splunkアーキテクチャ
ざっくりとしたイメージは下記の通りです。
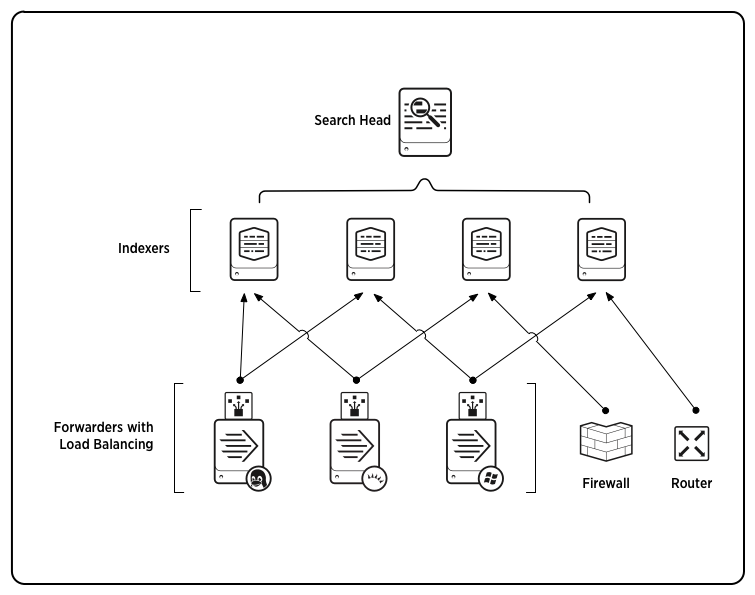
(画像引用)https://docs.splunk.com/File:Horizontal_scaling_new2_60.png
- Search Head(SH):Indexer(後述)に格納されたログを検索するためのコンポーネント。ユーザはSHのWeb UIにSPL(後述)と呼ばれるSplunk独自の検索処理言語(Splunk版のSQLのようなもの)を記述しログの検索が可能。資材配布のためのコンポーネントであるDeployer を用意し、クラスタ構成(SHC: Search Head Cluster)を組むことで可用性が向上する。
- Indexer(IDX):ログを格納(インデックス)するためのコンポーネント。クラスタ構成(IDXC:Indexer Cluster)を組む場合はクラスタ管理コンポーネントである**Cluster Master(CM)**が必要となる。
- Forwarder(FWD):ログ転送用のコンポーネント。Universal Forwarder(UF) と Heavy Forwarder(HF) の二種がある。詳細な説明は割愛するが、UFはほとんど無加工で転送し、HFはログのパースも可能という理解で良い。
その他管理系コンポーネント
- Licence Master(LM):ライセンス管理コンポーネント。
- Deployment Server:FWD, IDX(非クラスタ構成), SH(非クラスタ構成)への資材配布用コンポーネント。
全体の流れとしては、FWD→IDX→SHというフローでデータが転送され、ユーザはSHのGUIでSPLを記述し必要な情報を抽出するというイメージです。
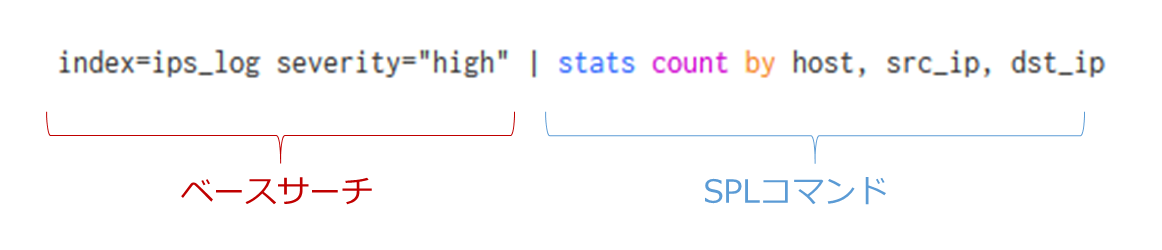
Search Processing Language (SPL)
Splunkのログ検索で用いる検索処理言語(SPL)に関してはSearch TutorialやSearch Referenceに概要がまとまっています。
簡潔に説明すると、index(SQLで言うtable)のデータに対し、SPLコマンドによって必要なフィールド(SQLで言うカラム)の値を統計処理等を実行し抽出します。
Let's start Splunk!
初学者は実際にSplunkに触れ、分からないところは公式ドキュメントやQiita等の技術記事をググって学ぶということをすれば、難なく基本を抑えることは可能だと思います。Splunkは無料でトライアル利用も可能ですし、ドキュメントも豊富です。
本章で触れた内容に関しては、下記の公式ドキュメント・Qiitaの記事を読めばさらに理解が深まるかと思います。
(参考)これを読むべし!
- Splunk Quick Reference Guide
- Components of a Splunk Enterprise deployment
- The basics of indexer cluster architecture
- Splunkのクラスター環境を10分で構築してやるよ
以降はSplunkの基礎が理解できていることが前提の内容になります。少しニッチな内容も含みますが、Splunk利用者は理解しておくと良いでしょう。
2. ログ検索高速化
ログの検索にかかる時間は短ければ短い程幸せになれます。本章ではログ検索の高速化に関して、いくつか知っておくべきことを紹介します。
コマンドが実行されるのはIDX?SH?
(参考)これを読むべし!
上記のドキュメントに記載されている内容から、サーチを高速化する上で重要なポイントをかいつまんで説明すると以下の通りです。
- SPLのサーチコマンドは6種類に大別される。
- Distributable streamingコマンドはIDXで実行されるが、当該コマンドがその他の種類のコマンドの後段で呼ばれた場合は、SHで実行される。
- Centralized streamingコマンドはIDXからSHにログを持ってきながらログの各イベントに対して作用する。
- その他の種類のコマンドはSHにイベントが揃ってから実行される。
この4点を踏まえ、IDX側で可能な限りログの絞り込みや分散処理によるログ加工は済ませたうえで、SH側で最終的な統計処理を行うというイメージでSPLを構成しましょう。
遅いSPL
index=ips_log
| table host, severity
| stats count by host, severity
| search severity = "high"
速いSPL
index=ips_log severity="high"
| fields host, severity
| stats count by host, severity
“かゆい所に手が届く”ポイント ☝️
- ログのフィルタはできるだけベースサーチで行う。
- 分析に必要なフィールドが限定されている場合はfieldsコマンドでフィルタし、tableコマンドのようなnon streamingコマンドはstreamingコマンドよりも後方で使う。
tstatsの活用
IDXに格納されるログデータはバケツ(バケット)という単位でまとめられています。このバケツの中にデータそのものや索引データ(tsidx)やデータそのものを含む圧縮データ(journal.gz)が入っています。このデータそのものを検索するのではなく、tsidxに対して統計処理を行うtstatsコマンドというものがあります。index時にフィールド抽出される設定(index-time field extractions)になっているフィールドを対象とした統計処理であれば、statsではなくtstatsコマンドを利用すると良いでしょう。
stats
index=ips_log severity = "high"
| stats count by host, severity
tstats(高速統計処理)
|tstats count where index=ips_log severity="high" by host, severity
“かゆい所に手が届く”ポイント ☝️
- 統計処理を行いたい場合、statsではなくtstatsに置き換えられないか考えてみる。
- tstatsが使えるのはindex-time field extractionsが設定されているフィールドを対象とした統計処理のみ。
(参考)これを読むべし!
3. Lookupテーブルの活用
SplunkではIDXに格納されているログだけでなく、自前のデータをLookupテーブルとしてSHにアップロードしIDXのログデータとの紐づけを行うことが可能です。
ユースケースとして、「アクセスログのステータスコードに自前で用意したステータスコード詳細のテーブルを紐づけるケース」を紹介します。
アクセスログ
index=access_log
| table browser, status
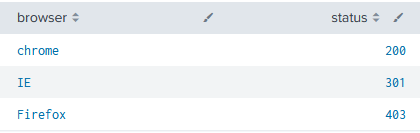
自前のLookupテーブル(status_code.csv)
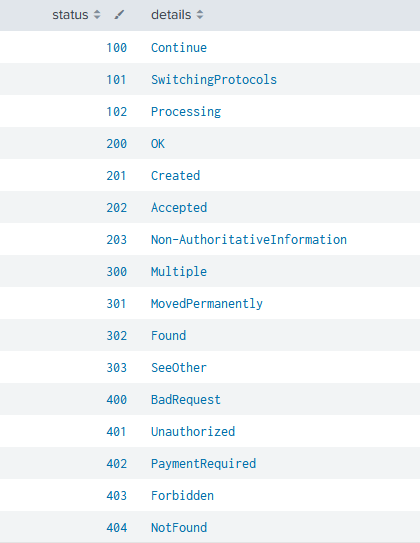
アクセスログとLookupテーブルの突合
index=access_log
| lookup status_code status OUTPUT details
| table browser,status,details
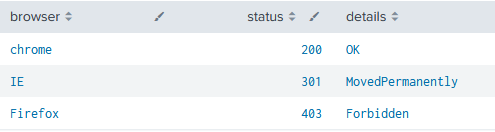
上記のようにLookupコマンドを使うことによって、Lookupテーブルの指定したフィールドに対応する別のフィールドを検索結果に付与することが可能です。
Lookupテーブルの設定方法等は公式ドキュメントにも記載があるためここでは省略します。
(参考)これを読むべし!
“かゆい所に手が届く”ポイント ☝️
筆者がハマったポイントとして、「超巨大なCSVファイルをLookupテーブルとして利用する方法」を紹介します。
※ “数GBのLookupテーブルが使いたい”という極めて稀なケースです。
LookupファイルはSHにアップロードして利用します。
SHへのファイルアップロード制限はweb.confで定義されます。
web.conf
max_upload_size = <integer>
* The hard maximum limit, in megabytes, of uploaded files.
* Default: 500
超巨大なCSVファイルをアップロードするためには、この500MB制限を緩和してあげる必要があります。
ファイルがアップロード出来たら、実際にLookupコマンドで当該ファイルを扱うために注意すべき事があります。Lookupファイルは Knowledge bundleに含まれるかたちでIDXに配布され、Lookupコマンド(Distributable streamingコマンドに分類される)によってIDX側でログの紐づけ処理が実行されます。
このKnowledge bundleにはサイズ制限があり、設定変更による制限緩和は可能ですがKnowledge bundleが肥大化すればその分だけNW帯域を圧迫することになります。
そこで、特定のオブジェクトをIDXに配布しない設定をdistsearch.confに記述することで、SHにアップロードされた超巨大LookupファイルがIDXに配布される事を防ぎます。
distsearch.conf
[replicationBlacklist]
<name> = <string>
ここまでの手順でSH上で超巨大Lookupファイルを扱う準備が出来ました。ただし、limits.confの下記アトリビュートの値(デフォルト25MB)を超えるLookupファイルはメモリ上には乗らず、ディスク上にindexされるためtsidxファイルが生成されます。当該Lookupファイルに対するLookupコマンドの初回実行時には、このtsidxの生成が行われるため数分間待つ必要があります。
limits.conf
max_memtable_bytes = <integer>
* Maximum size, in bytes, of static lookup file to use an in-memory index for.
* Lookup files with size above max_memtable_bytes will be indexed on disk
* NOTE: This setting also applies to lookup files loaded through the lookup()
eval function *which runs at search time*. The same function if called through
the ingest-eval functionality, uses ingest_max_memtable_bytes instead.
* CAUTION: Setting this to a large value results in loading large lookup
files in memory. This leads to a bigger process memory footprint.
* Default: 26214400 (25MB)
これでOK…と思ってもまだハマりポイントはありました。スタンドアローンなSHであれば問題無いのですが、SHCにおいて毎分実行されるスナップショットの取得の際に、超巨大Lookupファイルがスナップショットに含まれる事が原因でスナップショット作成に失敗する事象が発生しました。
この事象を解決するためにはSHCのserver.confに対し、当該ファイルをスナップショットに含めない設定を追加する必要がありました。
server.conf
[shclustering]
conf_replication_summary.blacklist.<name> = <blacklist_pattern>
* Files to be excluded from configuration replication summaries.
以上まとめると下記手順となります。
- Lookupファイルアップロード制限の緩和(web.conf)
- IDXへLookupファイルを配布しない設定の追加(distsearch.conf)
- メモリ上に乗らないサイズのLookupは初回lookup実行時にtsidxが生成される
- SHがクラスタ構成である場合はスナップショットに含めない設定が必要(server.conf)
ここまで書いておいてなんですが、大きなLookupファイルを使わないといけない状況は芳しくないです。
「手動更新が大変」、「初回実行時には待ち時間が発生する」、「検索にかかる時間が長い」…等々問題があるからです。
可能な限りSplunkに転送される前の世界において、必要なフィールドをログ自体に付与することが望ましいでしょう。
4. カスタムサーチコマンドの活用
Splunkでは任意のpythonスクリプトを動作させるコマンドを作成することができます。
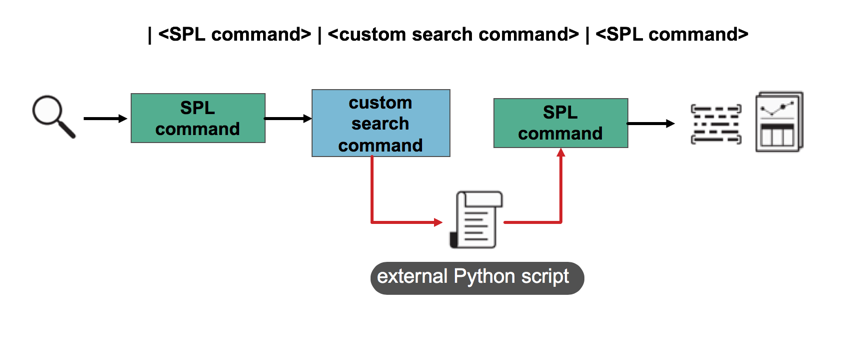
(画像引用)Create custom search commands for apps in Splunk Cloud Platform or Splunk Enterprise
入力としてログ検索結果を使うこともできますし、SPL内で任意の引数を渡すこともできます。pythonスクリプトでできることであれば何でもできるので、ログ検索の幅が格段に広がります。
“かゆい所に手が届く”ポイント ☝️
筆者がハマったポイントとして、「カスタムサーチコマンドに動的なパラメータを引数として渡す方法」を紹介します。
結論としては、下記のようにサブサーチによって引数となる文字列を作成することで実現しました。時刻情報に限った話ではなく、evalの関数でできる範囲の処理であれば動的なパラメータを引数として渡すことが可能です。
(例)コマンド実行時の時刻情報を含む文字列を引数として渡すケース
index=…
|(省略)
| mycommand [|makeresults |eval filename=strftime(now(), "output_%y%m%d%H%M.csv")|return $filename]
(参考)これを読むべし!
おわりに
本記事では下記トピックを紹介させていただきました。
- Splunkアーキテクチャ基礎
- ログ検索高速化
- Lookupテーブルの活用(+ 超巨大Lookupファイルの利用方法)
- カスタムサーチコマンドの活用(+ 動的なパラメータを引数として渡す方法)
まだまだ書きたかったトピックはありますが、それはまた別の機会に…(ここで力尽きる)