はじめに
Splunkの内部で起こっていることをログ取り込み時の処理と検索時の処理に分け、解説してみます。
Splunkは大量のログでも非常に高速かつ柔軟に検索、データ加工ができます。この魔法は2段階の処理で実現しています。
- 大量のログから欲しいキーワードを含む行(イベント)を抽出する
- 得られたイベントからデータを取り出し加工する
今回 1)について解説し、2) についても一部触れます。
.conf 2016のイベント資料(Behind the Magnifying Glass: How Search Works)に基づいて解説します。
外観
Splunkは主に3つのコンポーネントから構成されています。
サーバーやネットワーク機器からログをIndexer(インデクサー)に飛ばすforwarder(図下)。
Forwarderから飛んできたログを受け取り、検索しやすいように加工するindexer(図中)。
ユーザーへコンソールを提供し、検索指示を受け付け、検索指示をindexerに投げ、検索結果を表示するsearch head(図上)の3つです。

ログ→slice→journal.gz→バケツ
Splunkが受け付けるログはテキストのみです。バイナリはテキストに変換してやる必要があります。ログは行単位になっている必要があります。1行に一つtime stampがついているのが普通の形式ですね。
Forwarderからログがindexerに送られます。Indexerは送られてきたログに対し、複数行を一つの塊、slice(スライス)とする処理を行います。Sliceの大きさは128KBが上限です。複数のsliceをまとめてjournal.gzというファイルに圧縮します。ログの全てはjournal.gzに入っているわけです。

このjournal.gzをbucket(バケツ)に入れます。バケツはあとで説明します。
ログ→TSIDX→バケツ
ログがindexerに送られてきた時にjournal.gzを作る作業の他に、TSIDX(Time Series Index)もindexerで作ります。
下図を見てください。Raw Eventsというのがログです。ログに含まれる字句(Term)を字句解析(Lexical Analysis)で取り出します。字句(Term)とは意味のある最小単位の言葉や数字/記号のことです。英語の場合はスペース(空白)で単語は区切られるので楽ですね。
ログに含まれるTermをすべて集めたものがLexicon(辞書)です。辞書の目次を考えた時に、目次の内容は単語とそれが含まれるページ番号が羅列されています。LexiconにもTermとそれが含まれるsliceのアドレスが書かれています。
このLexiconとsliceアドレスが書かれたデータがTSIDXという形になってバケツに入ります。
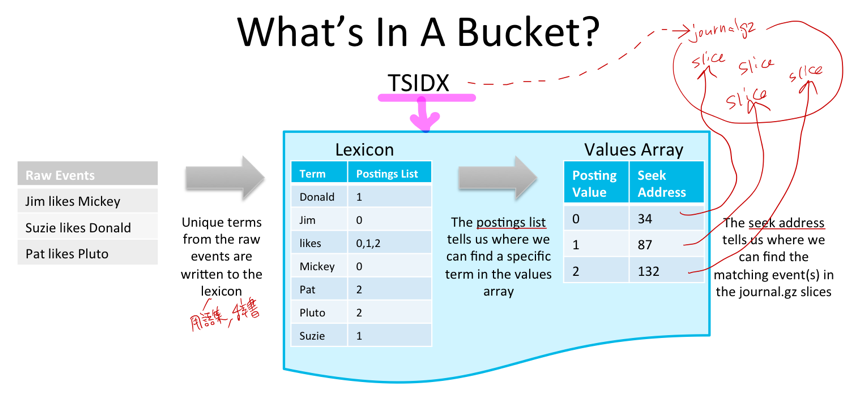
なお、LexiconにあるTermはそれぞれハッシュ値を計算し、それらハッシュ値はすべてOR演算で一つのハッシュ値を得ます(バケツのハッシュ値とでも名付けておきます)。
バケツのハッシュ値 = md5(Donald) OR md5(Jim) OR … OR md5(Suzie)
※ハッシュ計算にmd5を使っているのかは知りません。ここは単に例です。
あとで検索時に使用するbloom filterについて解説しますが、その時に使います。
バケツ
つまり、バケツにはログそのものと等価であるjournal.gzと、ログの目次となるTSIDXが入っているわけです。検索したいワードをTSIDXで探し、journal.gzから該当するイベント(行)を高速に探し出すわけです。
Splunkで検索式を書く時、index=xxx と書きますが、バケツはindexごとに用意されています。Indexの値が異なるバケツは見る必要がありません。またバケツは複数あります。(Index=xxxとindex=yyyでバケツは異なり、またindex=xxxのバケツも複数あります)
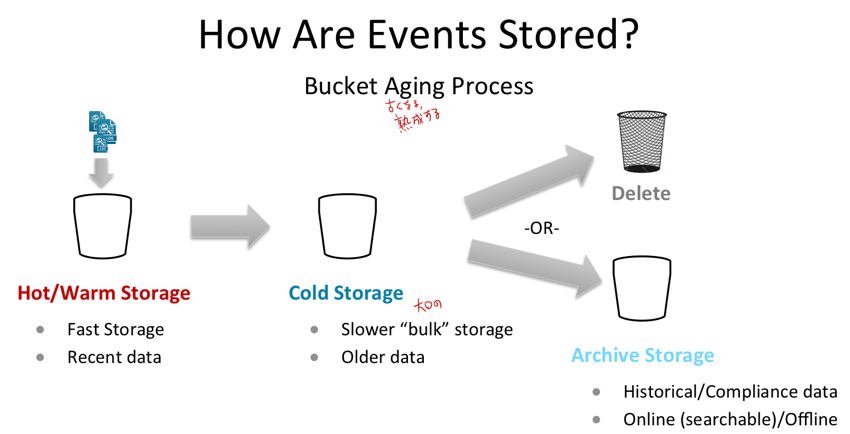
バケツにはHOT/WARMとCOLDの2種類があります。HOTバケツには新し目のデータが入っています。RAIDを使うなどしてハードウェア的に高速なストレージを使います。COLDバケツは古めのデータが入っています。ハードウェア的に安価で低速なストレージを使います(なので古いデータの検索は遅くなります)。時間が経つとHOTバケツに入っていたデータはCOLDバケツに移され、さらに月日が経つと設定に応じてCOLDバケツから消去されたり、テープにアーカイブされるなどして消されます。
検索語が含まれるイベントを見つけるまで
では検索時にどうやってバケツを選び、journal.gzに含まれるログにたどり着けるかを解説していきます。

① 検索式を入力します。Index=worldで最近4時間以内のデータからname fieldがwaldoのものを探す。
② 検索したいのはname fieldにある “waldo” です。waldoのハッシュ値を計算します。
③ Index=worldに対応するバケツを探します。バケツはたくさんありますが、その中から最近4時間以内のデータが入ったバケツを選びます。(たしかファイル名にそのバケツに含まれるログの期間が入っていたと思います)
④ waldoのハッシュ値とTSIDXにある「バケツのハッシュ値」でAND演算を行います。その結果がwaldoのハッシュ値と等しいならそのバケツにはwaldoがある。等しくないならそのバケツにはwaldoがないと判断できます。Bloom filterのところで再度解説しますが、上の図をじっくり考えればわかります。
(そのバケツにある)
md5(waldo) = md5(waldo) AND バケツのハッシュ値
(そのバケツにない)
md5(waldo) ≠ md5(waldo) AND バケツのハッシュ値
⑤ バケツのTSIDXに含まれるLexiconを調べ、検索したいTermが含まれるsliceのアドレスを得て、
⑥ Journal.gz内の指定されたsliceを取り出します。この中にはwaldoを含んだ元ログのデータが入っています。
正確には1つのsliceには複数のイベント(行)が含まれているのでwaldoを検索する処理が必要ですが、sliceは上限128KBの大きさなので検索処理は高速に実施できます。
検索語がすべて含まれるバケツを探す ー Bloom filter
先ほどの例では一つだけのTerm、“waldo”を調べました。Splunkで使用する際は、10.55.77.66 かつ waldo かつ active かつ powershell.exe など、複数単語をすべて含んだものを探すユースケースが多いです。Splunkは複数語の検索を高速に行える仕組みがあります。それがBloom filterです。

たとえば検索式、
index=world Donald Jim likes Mickey
を実行します。Splunkでは検索したいワードを空白でつなぐと、ANDの意味になります。
Bloom Filterでは、検索したいワードのハッシュ値をすべて計算し、ORを掛けます。
検索ワードのハッシュ値 = md5(Donald) OR md5(Jim) OR md5(likes) OR md5(Mickey)
この「検索ワードのハッシュ値」と「バケツのハッシュ値」でANDを掛けた結果が「検索ワードのハッシュ値」と等しければ、すべての検索したいワードを含んだバケツであることがわかります。一つだけでもワードが足りなければそのバケツは調べる必要がなくなります。
この方式はFalse Positive(偽陽性、あると思ったけど実際は無かった)になる可能性はありますが、False Negative(偽陰性、ないと思ったけど実際はあった)になることはありません(AND演算の意味をじっくり考えてみてください。検索ワードのハッシュ値のbitが1のところは完全一致しますが、bitが0のところは一致しなくてもいいことが、False Positiveは許容するがFalse Negativeは許容しないことを数学的に保証しています)。
以上のような仕組みで「1) 大量のログから欲しいキーワードを含む行(イベント)を抽出する」が実現されています。簡単にまとめると、検索したいワードが含まれるログを見つけるために、まずバケツ単位で選別し、バケツを調べる時にはTSIDXのLexiconを調べることで検索したいワードが含まれるsliceを計算量O(1)で特定することができ、結果、高速な検索が可能となっています。
以降では「2) 得られたイベントからデータを取り出し加工する」のアークテチャの側面について解説していきます。
検索式の構造
Splunkで使用する検索式はSQLに似た言語を使います。SPL(Search Processing Language)といいます。

1行目(最初の“|”まで)はBase Searchといいます。バケツから処理したいイベントを取り出しメモリに展開するとても大切な役割を担っています。
Base Searchでできるだけイベント数を絞り込むことは検索スピードに劇的に効きます。
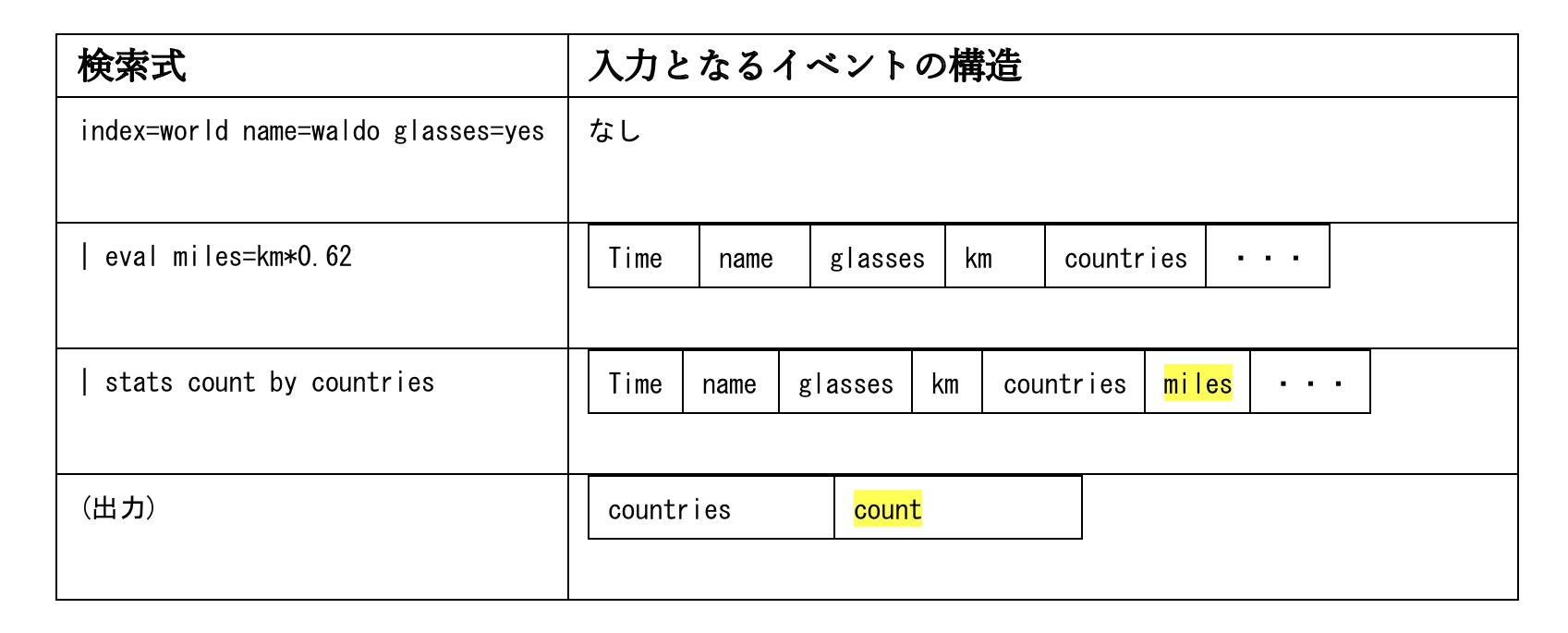
2行目以降がSPL Commandsで、Base Searchでメモリに展開したイベントに対して各種操作を行なっていきます。検索や演算の単位はイベントごとです。イベントを跨いだ処理は制約があります。
検索式はパイプ(”|”)でつないでいきます。行A | 行B とあると、行Aで演算した出力(イベントの集合)がパイプで行Bの入力となり、処理がつながっていきます。
検索時のSearch headとindexerの役割
Search Headはコンソール機能をユーザーに提供し、ユーザーは検索式を入力します。
① ② Search Headは受け取った検索式をparse(解釈)し、indexerに送ります。
③ 〜⑦ Indexerで処理を行い、結果をSearch Headに送ります。
⑧ Search Headは結果をユーザーに提示します。
以上が基本的なSearch Headとindexerの役割分担となっています(下図)。
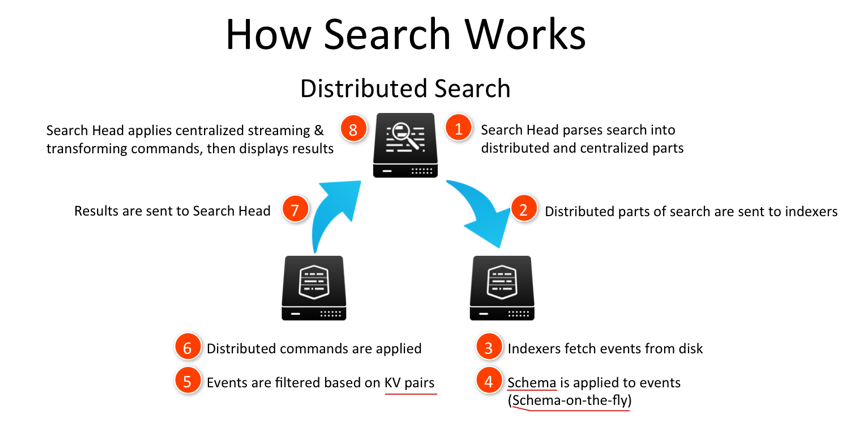
⑥ Indexerはクラスタ構成になっているため分散処理により高速検索を負荷分散しつつ行えます。
④ RDB(リレーショナルデータベース)と異なり、Splunkはフィールドの型などは特にありません。Splunkはフィールドや型をイベントから読み出し、柔軟に対応します(Schema-on-the-fly)。
⑤ KVというのはKey-Valueで、Keyとはフィールドを指します。フィールドと値の対応をとります。(KV pairs)
⑦⑧ ところでindexerはSPLのコマンドをなんでも処理できるわけではなく、コマンドの種類によってindexerで処理できるもの/Search Headでのみ処理できるものに別れます。
Splunk のマニュアルにコマンドごとに書かれています。
Streaming commands (Distributable) ・・・ indexerで動く
Streaming commands (Centralized) ・・・ Search Headで動く
Transforming commands ・・・ Search Headで動く(一部indexer)
パフォーマンスに関することとして、indexerで動いている中、Centralized コマンドやTransforming コマンドなどSearch Headで動くコマンドを処理すると、処理がSearch Headに移り、以後DistributableコマンドであってもSearch Headで処理が継続されます。分散処理ができなくなるためパフォーマンスが劣化します。
以上、Splunkのinternal architectureの解説でした。
参考