はじめに
Splunkはデータの規模に応じてスケールアップすることができます。
ログやデータをインデックスしている Indexer がダウンした場合でもサーチを続けられるように冗長構成を組むこともできます。
この冗長構成を クラスター と呼びますが、今回はクラスター環境の簡単な構築方法を記載します。
予備知識
まずはSplunkのクラスター環境についての基礎知識を少々。
知ってるよ、って方は読み飛ばしてください。
Splunkコンポーネント
-
Indexer : ログやデータをインデックスするところ。クラスター環境の場合、 Search Peer もしくは Peer Node という。Elastic Stackでいうと、Elasticsearch。
-
Search Head : 主にユーザーがログインしてサーチするところ。他にもAPI Callやスケジュールサーチ、アラートもここで担う。Elastic Stackでいうと、Kibana。
-
Forwarder : データ転送元。ログサーバーやその他ログを保管しているサーバーにインストールするもの。Elastic Stackでいうと、Beats。
(LogstashはForwarderとIndexerに跨ってる感じかな) -
Cluster Master : クラスターを管理する管理系コンポーネント。データのレプリケーションをどのIndexerに作るとか、サーチをした際にデータがどのIndexerにあるとか、Indexerがダウンしたらレプリケーション作るとか、けっこう忙しい。
-
License Master : Splunkのライセンスを管理する管理系コンポーネント。どれくらいデータをインデックスしたか、サーチしながらチェックしてやがる。
-
Deployment Server : ForwarderにAppを展開する管理系コンポーネント。どのディレクトリのどのファイルをインデックスするかとか、どのIndexerに送るか、というのもAppとして管理するんだぜ。
ポート
Splunkの各コンポーネントが通信する際のポートは下図参照
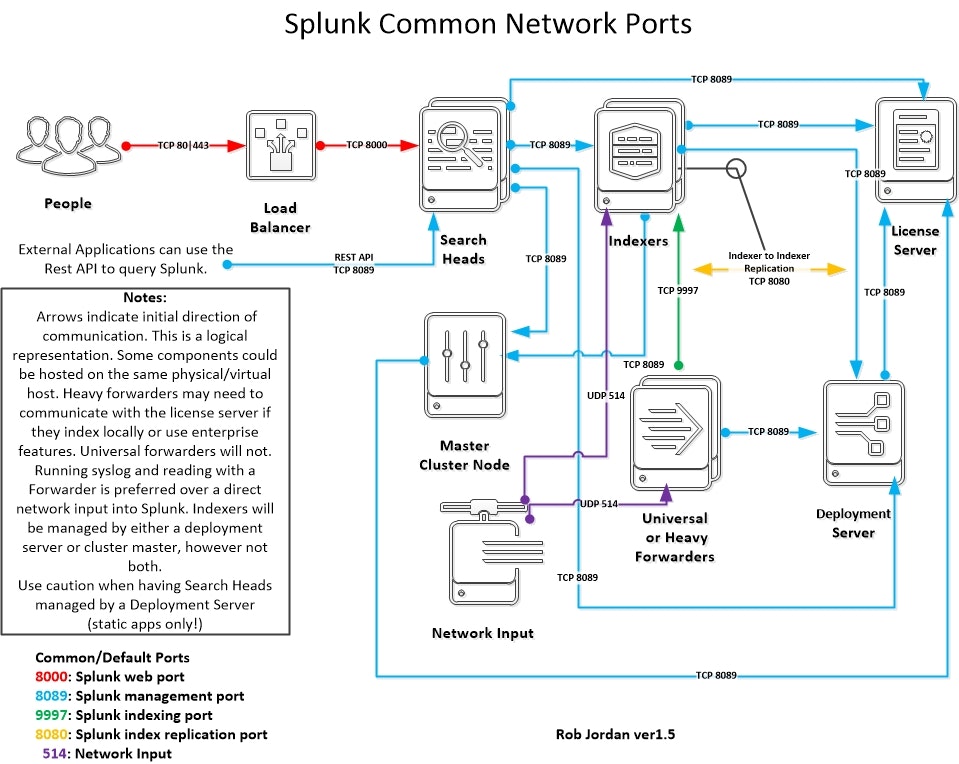
-
8089全てのSplunkインスタンス(ForwarderではInbound不要)で必須 -
8000Search Headのみ -
9997Indexerのみ -
8080Indexerのみ
インデックスのレプリケーション
インデックスしたデータをIndexerでレプリケーションする場合、2つの要素があります。
Search Factor (以下、SF) と Replication Factor (以下、RF) です。
そもそもSplunkにインデックスされたデータは、主に 圧縮された生データ(journal.gz) と インデックス(tsidx) の2つでSplunk内に保管されます。
この2つが揃って(実際は他のメタデータもありますが)初めてサーチできることになります。
話を戻して、レプリケーションするとき、
- SF で指定した数字は生データとインデックスをクラスター内でいくつ保有するか
- RF で指定した数字は生データのみをクラスター内でいくつ保有するか
この2つを指定してやります。
「どうやって決めればいいの?」 という疑問が出てくると思いますが、基本的には 「何台のIndexerダウンを許容するか」 です。
そのうえで、
- SFは 「サーチを途切れさせないようにするため、何台までのIndexerダウンを許容するか」
- RFは 「データの欠損が出ないようにするには何台までのIndexerダウンを許容するか」
ということで決めます。
RFで指定した生データのみのコピーの場合、Indexerがダウンしたら生データからインデックスを作成するので、(データ量にもよりますが)サーチ可能になるまで数時間要します。
SF=2, RF=3という構成が一般的(デフォルト?)ですが、この数字はお好みで。
この場合、インデックスはオリジナル含めて2個、生データはオリジナル含めて3個が複数のIndexerに渡って保有されている状態になりますので、最低3台のIndexerが必要になります。
やってみよう
ということで、これからCLIやシェルを駆使して10分でクラスター環境構築してやるよ。
(今までの予備知識は10分にカウントしないでね)
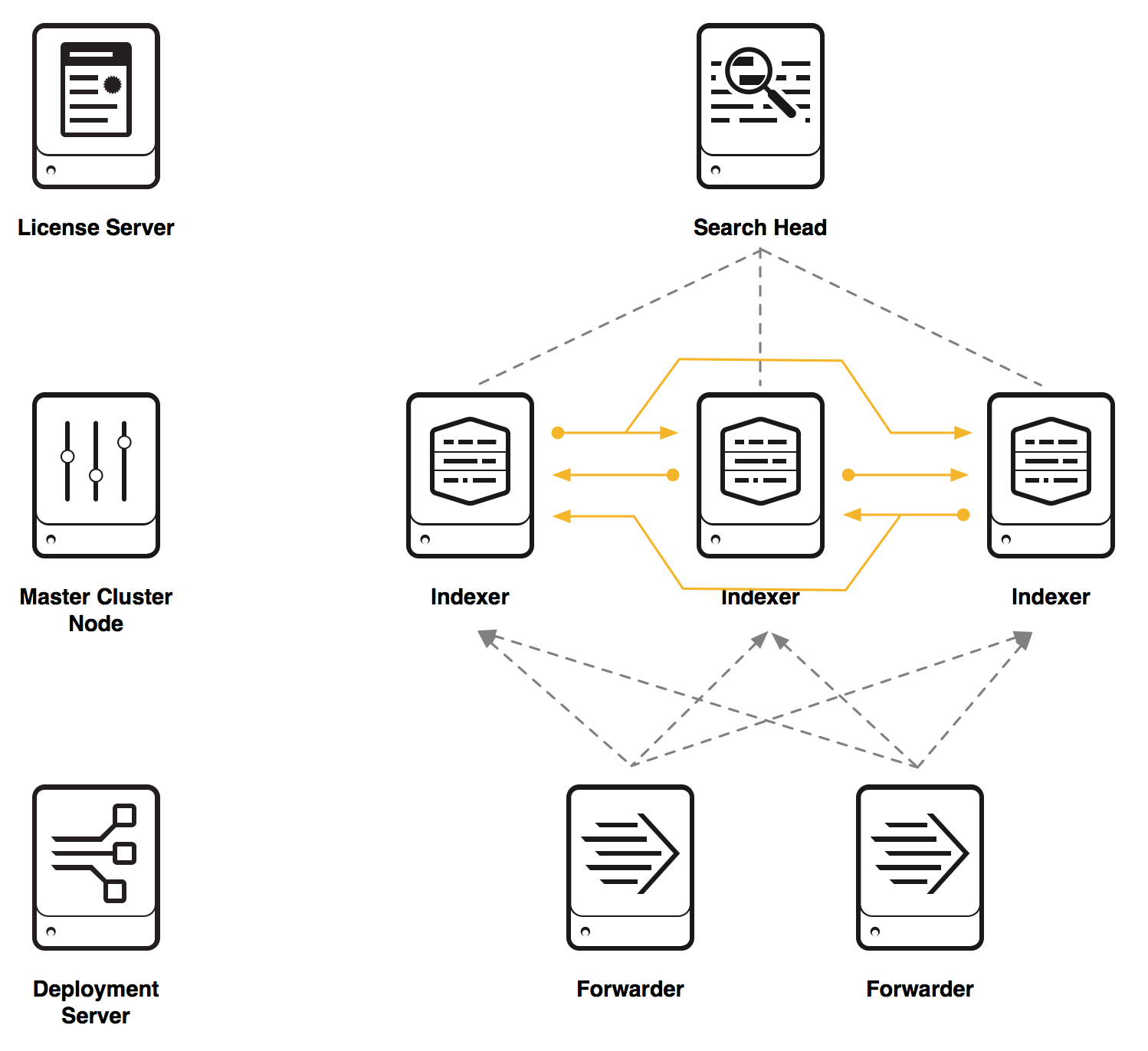
今回は検証環境ということで、9台のEC2を使って構築します。
OSは Amazon Linux
完成イメージ
こんな感じ(逆にわかりづらいか)
Splunkインストール
Splunkはこのシェル実行しちゃってサクッとインストール
# !/bin/bash
ENT_FILE="splunk-7.0.3-fa31da744b51-Linux-x86_64.tgz"
FWD_FILE="splunkforwarder-7.0.3-fa31da744b51-Linux-x86_64.tgz"
ENT_VERSION=`echo $ENT_FILE | sed 's/-/ /g' | awk '{print $2}'`
FWD_VERSION=`echo $FWD_FILE | sed 's/-/ /g' | awk '{print $2}'`
ENT_URL="https://www.splunk.com/bin/splunk/DownloadActivityServlet?architecture=x86_64&platform=linux&version=$ENT_VERSION&product=splunk&filename=$ENT_FILE&wget=true"
FWD_URL="https://www.splunk.com/bin/splunk/DownloadActivityServlet?architecture=x86_64&platform=linux&version=$FWD_VERSION&product=universalforwarder&filename=$FWD_FILE&wget=true"
while read line
# for line in `cat servers.list`
do
ip=`echo $line | awk '{print $1}'`
package=`echo $line | awk '{print $2}'`
name=`echo $line | awk '{print $3}'`
INSTALL_FILE=`eval echo \\"\\${${package}_FILE}\\"`
WGET_URL=`eval echo \\"\\${${package}_URL}\\"`
if [ $package = "ENT" ]; then
DIRECTORY="splunk"
elif [ $package = "FWD" ]; then
DIRECTORY="splunkforwarder"
fi
REMOTE_SCRIPT="
echo '# Add User and Group'
sudo groupadd -g 501 splunk
sudo adduser -u 501 -g 501 splunk
echo '# Wget Package File'
wget -nv -O $INSTALL_FILE '$WGET_URL'
echo '# Install Splunk'
sudo tar zxf /home/ec2-user/$INSTALL_FILE -C /opt/
echo '# Change Owner to splunk'
sudo chown -R splunk:splunk /opt/$DIRECTORY
echo '# Start Splunk'
sudo -u splunk /opt/$DIRECTORY/bin/splunk start --accept-license --answer-yes --no-prompt
echo '# Set Hostname'
sudo -u splunk /opt/$DIRECTORY/bin/splunk set default-hostname $name -auth admin:changeme
echo '# Set Server Name'
sudo -u splunk /opt/$DIRECTORY/bin/splunk set servername $name -auth admin:changeme
echo '# Enable Boot-Start'
sudo /opt/$DIRECTORY/bin/splunk enable boot-start -user splunk
echo '# Restart Splunk'
sudo -u splunk /opt/$DIRECTORY/bin/splunk restart
"
echo "Connecting... $ip"
ssh -n ${ip} "${REMOTE_SCRIPT}"
echo "---------------------------"
# done
done < servers.list
echo "Done"
-- 2018/04/25 追記 ココカラ --
Splunkのバージョン 7.1.0 (2018年4月24日リリース)以降を使う場合は、 --no-prompt 使ってはいけないみたいです。
どうやら初回起動で admin ユーザーのパスワードを設定するみたいなので、 --no-prompt を指定するとパスワード設定の処理をスキップしてしまい、ユーザーが作成されていない状態のままログインできなくなるみたいです。(対処法あるにはあるのですが...)
なので、 7.1.0 以降を使う場合は初回起動を以下のように書き換えましょう。
sudo -u splunk /opt/$DIRECTORY/bin/splunk start --accept-license --answer-yes --seed-passwd changeme
この --seed-passwd は7.1.0の新しいオプションのようです。
-- 2018/04/25 追記 ココマデ --
シェルと同じディレクトリにサーバーのIPとSplunホスト名・サーバー名をリストにします。
※ 第2項目は、Splunk Enterpriseなら ENT 、Universal Forwarderなら FWD
10.0.0.101 ENT cm # Cluster Master
10.0.0.102 ENT lm # License Master
10.0.0.103 ENT ds # Deployment Server
10.0.0.111 ENT sh # Search Head
10.0.0.121 ENT idx-1 # Indexer Cluster #1
10.0.0.122 ENT idx-2 # Indexer Cluster #2
10.0.0.123 ENT idx-3 # Indexer Cluster #3
10.0.0.131 FWD fwd-1 # Forwarder #1
10.0.0.132 FWD fwd-2 # Forwarder #2
各サーバーに splunk というユーザーを作成してSplunk起動しているので、以降CLI実行するときには sudo -u splunk をつけています。
ライセンス関連
ライセンスはLicense Masterで一括管理します。
まずはLicense Masterにライセンスを追加
## Add License @License Master
ssh 10.0.0.102
sudo -u splunk /opt/splunk/bin/splunk add licenses <license_file_path> -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
License Slave設定
Cluster Master、Deployment Server、Search Head、IndexerをLicense Slaveにする。
つまり、Splunk Enterpriseを入れたコンポーネントのライセンスは全てLicense Masterに集約するということ。
## Switch to License Slave
## @Cluster Master
ssh 10.0.0.101
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
## @Deployment Server
ssh 10.0.0.103
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
## @Search Head
ssh 10.0.0.111
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
## @Indexer #1
ssh 10.0.0.121
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
## @Indexer #2
ssh 10.0.0.122
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
## @Indexer #3
ssh 10.0.0.123
sudo -u splunk /opt/splunk/bin/splunk edit licenser-localslave -master_uri https://10.0.0.102:8089 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
確認してみよう
ちゃんとLicense設定できたかな?
## Check License Slaves
ssh 10.0.0.102
sudo -u splunk /opt/splunk/bin/splunk list licenser-slaves -auth admin:changeme
License SlaveになっているSplunkインスタンスのGUIDが表示されます。
32C8226F-E30E-4E18-82CD-04040F569025
active_pool_ids:
auto_generated_pool_enterprise
label:lm
pool_ids:
auto_generated_pool_enterprise
auto_generated_pool_forwarder
auto_generated_pool_free
stack_ids:
enterprise
forwarder
free
warning_count:0
5F6F26AE-ADF3-4E94-BE51-12219BFAB1CF
active_pool_ids:
auto_generated_pool_enterprise
label:idx-1
pool_ids:
auto_generated_pool_enterprise
auto_generated_pool_forwarder
auto_generated_pool_free
stack_ids:
enterprise
forwarder
free
warning_count:0
...
各SplunkインスタンスのGUIDを確認するには下記コマンドで
sudo -u splunk grep guid /opt/splunk/etc/instance.cfg
クラスター関連
Cluster Master設定
SFは2、RFは3でCluster Masterを作成する。
## Add Cluster Master
ssh 10.0.0.101
sudo -u splunk /opt/splunk/bin/splunk edit cluster-config -mode master -replication_factor 3 -search_factor 2 -secret idxcluster -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
-secret の引数で指定する値は何でもいいけど、以降のステップで指定するものと同じにしないといけないよ。
IndexerをクラスターのSearch Peerにする
レプリケーションで使うポートは 8080 として、ついでにForwarderからのデータ受信をポート 9997 で設定しておく。
## Add Cluster Peer
ssh 10.0.0.121
sudo -u splunk /opt/splunk/bin/splunk edit cluster-config -mode slave -master_uri https://10.0.0.101:8089 -replication_port 8080 -secret idxcluster -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk enable listen 9997 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
ssh 10.0.0.122
sudo -u splunk /opt/splunk/bin/splunk edit cluster-config -mode slave -master_uri https://10.0.0.101:8089 -replication_port 8080 -secret idxcluster -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk enable listen 9997 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
ssh 10.0.0.123
sudo -u splunk /opt/splunk/bin/splunk edit cluster-config -mode slave -master_uri https://10.0.0.101:8089 -replication_port 8080 -secret idxcluster -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk enable listen 9997 -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
Search HeadでサーチできるようにCluster Masterと紐付ける
## Add Search Head to Cluster
ssh 10.0.0.111
sudo -u splunk /opt/splunk/bin/splunk edit cluster-config -mode searchhead -master_uri https://10.0.0.101:8089 -secret idxcluster -auth admin:changeme
sudo -u splunk /opt/splunk/bin/splunk restart
AppをIndexerに配布する場合
前提として、SplunkのAppは $SPLUNK_HOME/etc/apps/ に格納されます。
ただし、クラスターのSearch PeerにAppをインストールする場合は、直接上記ディレクトリに入れるのではなく、 Cluster Master の $SPLUNK_HOME/etc/master-apps/ にAppを置いて、Bundle として各Search Peerに配布することになります。
インデックスしたデータのレプリケーションしているからには、設定を含むAppもちゃんとCluster Masterで管理しなさいよ、ということです。
## Deploy Apps to Peer Nodes
ssh 10.0.0.101
sudo -u splunk cp -p -r <APP_DIR> /opt/splunk/etc/master-apps/
## Validate Cluster Bundle
sudo -u splunk /opt/splunk/bin/splunk validate cluster-bundle -auth admin:changeme
## Commit Cluster Bundle
sudo -u splunk /opt/splunk/bin/splunk apply cluster-bundle
## Check Cluster Bundle Status
sudo -u splunk /opt/splunk/bin/splunk show cluster-bundle-status
## Rolling Restart
sudo -u splunk /opt/splunk/bin/splunk rolling-restart cluster-peers -auth admin:changeme
Forwarderセットアップ
Deployment Server の $SPLUNK_HOME/etc/deployment-apps/ にAppを置いてForwarderに配布します。
今回の検証環境のようにForwarderが2台だけなら 「そんなめんどくせーもん要らねえよ ( ゚д゚)、ペッ」 となりそうですが、規模が大きくなると数百台、数千台のForwarderを扱うことになり、それぞれで扱うデータも異なるので、Deployment Server使わないと管理が難しくなってしまうのです。
Indexer Discoveryを有効にする
ナニソレ美味しいの? ってなりますよね。
例えば、Forwarderでデータ転送先Indexerをホスト名やIPアドレスでベタ書きすると、Indexerを拡張していったとき、毎回その設定を書き換えなきゃいけなくなります。
Forwarderからの転送先Indexerをクラスター内のSearch Peerにしたい。
だったら、ForwarderからCluster Masterに対象のIndexerが何かを問い合わせればいいや、ってことになります。
ということで、Cluster Masterで設定します。
## Edit server.conf @Cluster Master
ssh 10.0.0.101
sudo -u splunk vi /opt/splunk/etc/system/local/server.conf
server.conf に以下の2行を追加
[indexer_discovery]
pass4SymmKey = idxforwarders
で、Cluster MasterのSplunk再起動
sudo -u splunk /opt/splunk/bin/splunk restart
Deployment ServerでApp作成
ということで、Indexerへのデータ転送をAppという形でForwarderに展開します。
データ転送は outputs.conf で設定します。
まずはAppディレクトリと outputs.conf を作成
## Create App Directory and outputs.conf
ssh 10.0.0.103
sudo -u splunk mkdir -p /opt/splunk/etc/deployment-apps/uf_base/local
sudo -u splunk vi /opt/splunk/etc/deployment-apps/uf_base/local/outputs.conf
outputs.conf で以下を設定
ここでIndexer Discoveryを指定するわけですね。
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
indexerDiscovery = idxc1
useACK = true
[indexer_discovery:idxc1]
master_uri = https://10.0.0.101:8089
pass4SymmKey = idxforwarders
ForwarderをDeployment Serverに通信させる
Deployment ServerがForwarderにAppを展開するといっても、どこにForwarderがあるのか把握してなければ無理だよね。
ということで、ForwarderからDeployment Serverに疎通させて、自分の居場所を教えてあげましょう。
Forwarderで下記CLIを実行
## Set Deploy Poll @Forwarder
ssh 10.0.0.131
sudo -u splunk /opt/splunkforwarder/bin/splunk set deploy-poll 10.0.0.103:8089 -auth admin:changeme
sudo -u splunk /opt/splunkforwarder/bin/splunk restart
ssh 10.0.0.132
sudo -u splunk /opt/splunkforwarder/bin/splunk set deploy-poll 10.0.0.103:8089 -auth admin:changeme
sudo -u splunk /opt/splunkforwarder/bin/splunk restart
Deployment ServerからForwarderにAppを配布
さて、いよいよ配布です。
Deployment Serverで、どのAppをどのForwarderに配布するか serverclass.conf で指定
ssh 10.0.0.103
sudo -u splunk vi /opt/splunk/etc/system/local/serverclass.conf
serverclass.conf に以下を追加
[serverClass:uf_base:app:uf_base]
restartSplunkWeb = 0
restartSplunkd = 1
stateOnClient = enabled
[serverClass:uf_base]
whitelist.0 = ip-10-0-0-13*
Deployment ServerのSplunk再起動
sudo -u splunk /opt/splunk/bin/splunk restart
しばらくするとForwarderにAppディレクトリ uf_base が展開されていることが確認できます。
ssh 10.0.0.131
sudo -u splunk ls -l /opt/splunkforwarder/etc/apps
ssh 10.0.0.132
sudo -u splunk ls -l /opt/splunkforwarder/etc/apps
全SplunkインスタンスのデータをSearch Peerに集約
これを忘れちゃいけないよ。
Cluster環境を組むとユーザーはSearch HeadにログインしてSearch Peerにインデックスされたデータをサーチすることになります。
License MasterやCluster Master、Deployment Serverといった管理系コンポーネントや、Search HeadでもSplunkそのもののインターナルログが _internal や _audit といった、アンダースコアで始まるインデックス名で勝手にインデックスされます。
なので、これらのコンポーネントでも outputs.conf でSearch Peerにデータ転送するよう設定しましょう。
## Edit outputs.conf @Cluster Master
ssh 10.0.0.101
sudo -u splunk mkdir -p /opt/splunk/etc/apps/outputs/local
sudo -u splunk vi /opt/splunk/etc/apps/outputs/local/outputs.conf
## Edit outputs.conf @License Master
ssh 10.0.0.102
sudo -u splunk mkdir -p /opt/splunk/etc/apps/outputs/local
sudo -u splunk vi /opt/splunk/etc/apps/outputs/local/outputs.conf
## Edit outputs.conf @Deployment Server
ssh 10.0.0.103
sudo -u splunk mkdir -p /opt/splunk/etc/apps/outputs/local
sudo -u splunk vi /opt/splunk/etc/apps/outputs/local/outputs.conf
## Edit outputs.conf @Search Head
ssh 10.0.0.111
sudo -u splunk mkdir -p /opt/splunk/etc/apps/outputs/local
sudo -u splunk vi /opt/splunk/etc/apps/outputs/local/outputs.conf
[indexAndForward]
index = false
[tcpout]
defaultGroup = default-autolb-group
forwardedindex.filter.disable = true
indexAndForward = false
[tcpout:default-autolb-group]
indexerDiscovery = idxc1
useACK = true
[indexer_discovery:idxc1]
master_uri = https://10.0.0.101:8089
pass4SymmKey = idxforwarders
で、Splunk再起動
sudo -u splunk /opt/splunk/bin/splunk restart
これも Deployment Server で管理してもいいかもですね。
Splunkにログインして確認
ブラウザからSearch Headにログインして確認してみましょう。
サーチ画面に進んで下記サーチ文を実行
| tstats count where index=_internal by host splunk_server
tstats はインデックスのみを検索してメタデータの統計を出すコマンド。
通常のサーチよりちょっぱやで結果が帰ってきます。
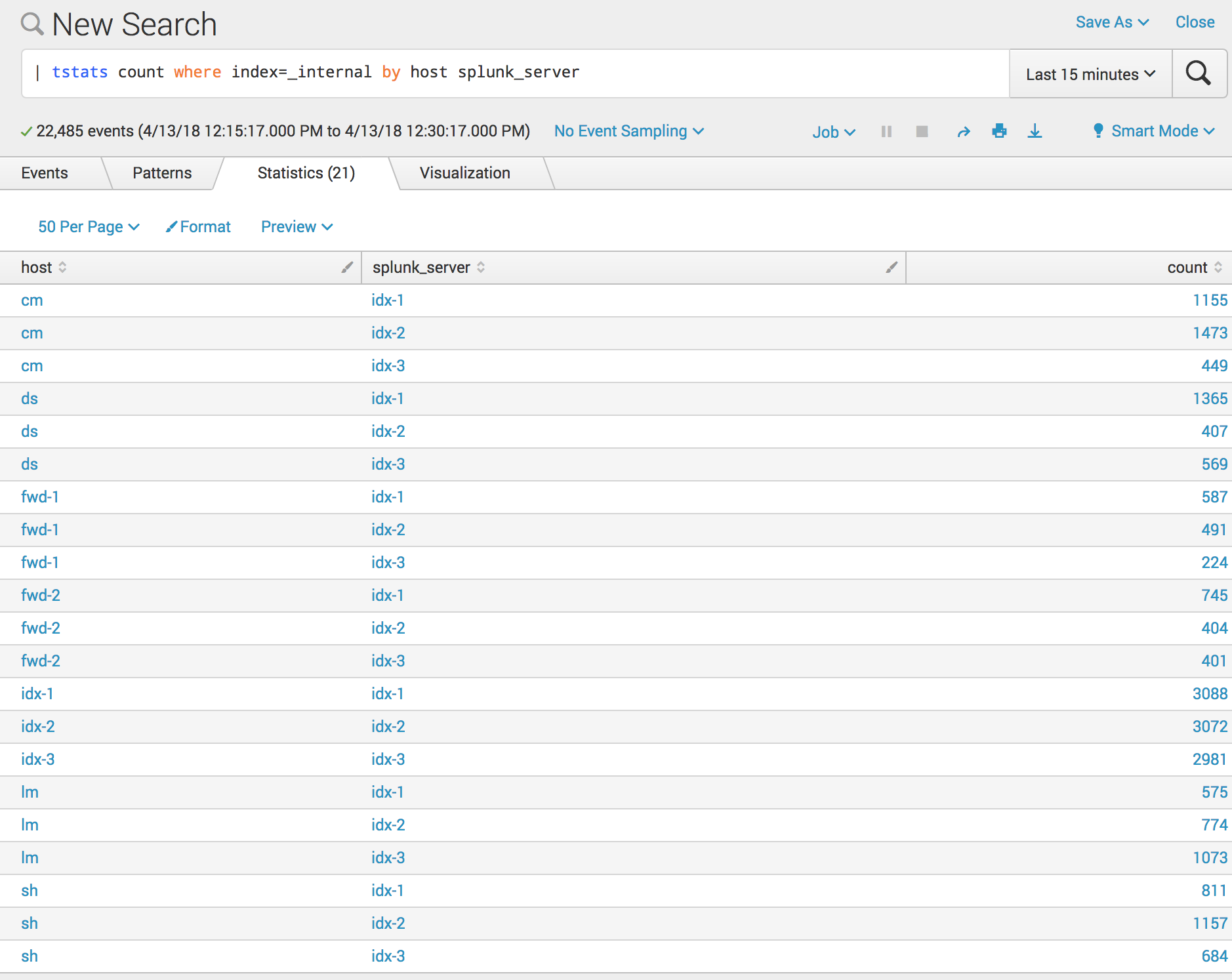
ここで、 host はログ発生元のホスト名、 splunk_server はインデックスされているSplunkサーバー名です。
-
hostはCLI$SPLUNK_HOME/bin/splunk set default-hostnameで設定 -
splunk_serverはCLI$SPLUNK_HOME/bin/splunk set servernameで設定
各Splunkインスタンスのインターナルログが idx-1 idx-2 idx-3 に分散されてインデックスされていることがわかります。
最後に
ね、簡単でしょ?
ユーザーが増えたときに負荷分散するためにSearch Headを冗長化する Search Head Cluster や、DRのために複数拠点でレプリケーションする Multisite Cluster というのもありますが、それはまた別の機会に。
反省
10分というのは盛りすぎましたね。
ちょこちょこ再起動してるので、もうちょい時間かかるかもです。