こんにちは、NTTドコモ サービスイノベーション部 ビッグデータ担当の小笠原です。
この記事は Advent Calendar 2021 NTTドコモ R&D、20日目の記事になっております。
最近、機械学習モデルを組み込んだアプリケーションを作成する機会があり、今後はその高度化の一つとして推論部分の API 化に挑戦していきたいと思っています。
個人的な見解ですが、モデルを API 化するメリットは商用環境にデプロイするまでの時間を短縮できることだと思っています。
一般的に、新しいモデルを導入したり、更新したりする際には、データサイエンティストが作ったモデルをエンジニアが受け取り、エンジニアがそのモデルに対応したコードに修正する必要があると思います(この作業が意外と大変だと思っています・・)。
これはエンジニアに負担がかかるとともに、データサイエンティストにとってもすぐに QA 環境でのテストができないことを意味し、効率的な開発ができていない状態になっていると思います。
そこで、推論部分を API 化し(分離し)、サービスを分けることでデータサイエンティストとエンジニアとの役割を明確化でき、エンジニアのコード修正頻度を下げることができます。
また、エンジニアも空いた分の稼働を使って CI/CD 化を進めれば、全体としてモデルをデプロイするまでの時間をどんどん短縮できると思っています。
今回は、そんな理想に夢を膨らませながら機械学習モデルの推論部分を API 化し、そのついでにオートスケール(スケールイン/アウト)させてみたという内容の記事になってます。
オートスケールさせてみた理由は、なんかカッコいいから 1日の中でも時間帯によってリクエストにばらつきがあるワークロードが多いと思い、需要があると思ったからです。
忙しい人向け
「新しく機械学習モデルを作成し、API としてスケールイン/アウトする形でデプロイする。ついでにベンチマーククライアントを走らせてスケールイン/アウトを体感する。」といったシナリオを順番に説明していく記事となっています。
そのため、忙しい人向けには取り組みの中で得た学びを共有できればと思います。
- インフラ部分の構築が思ったよりも大変(2.)
- モデルをデプロイするまでに必要な知識/技術が芋づる式に出てきた
- 柔軟性との兼ね合いになりそうだが、マネージドに寄せるのも手段の一つだと感じた
- API 化するための推論クラスは思ったよりも簡単に作れる(3.1.)
- モデルの読み込みと推論の関数だけあれば動かせる
- データサイエンティストにとっても負担が大きくなりすぎることはないと思う
- ワークロードを想定してどの指標をもとにスケールイン/アウトさせるかを明確化させておく(3.3.)
- スケールイン/アウト自体は K8s HorizontalPodAutoscaler 機能を使えばすぐにできる
- ベンチマークを実行する際は取得したい指標を事前に決め、計測できるようにしておく(4.)
1. 概要
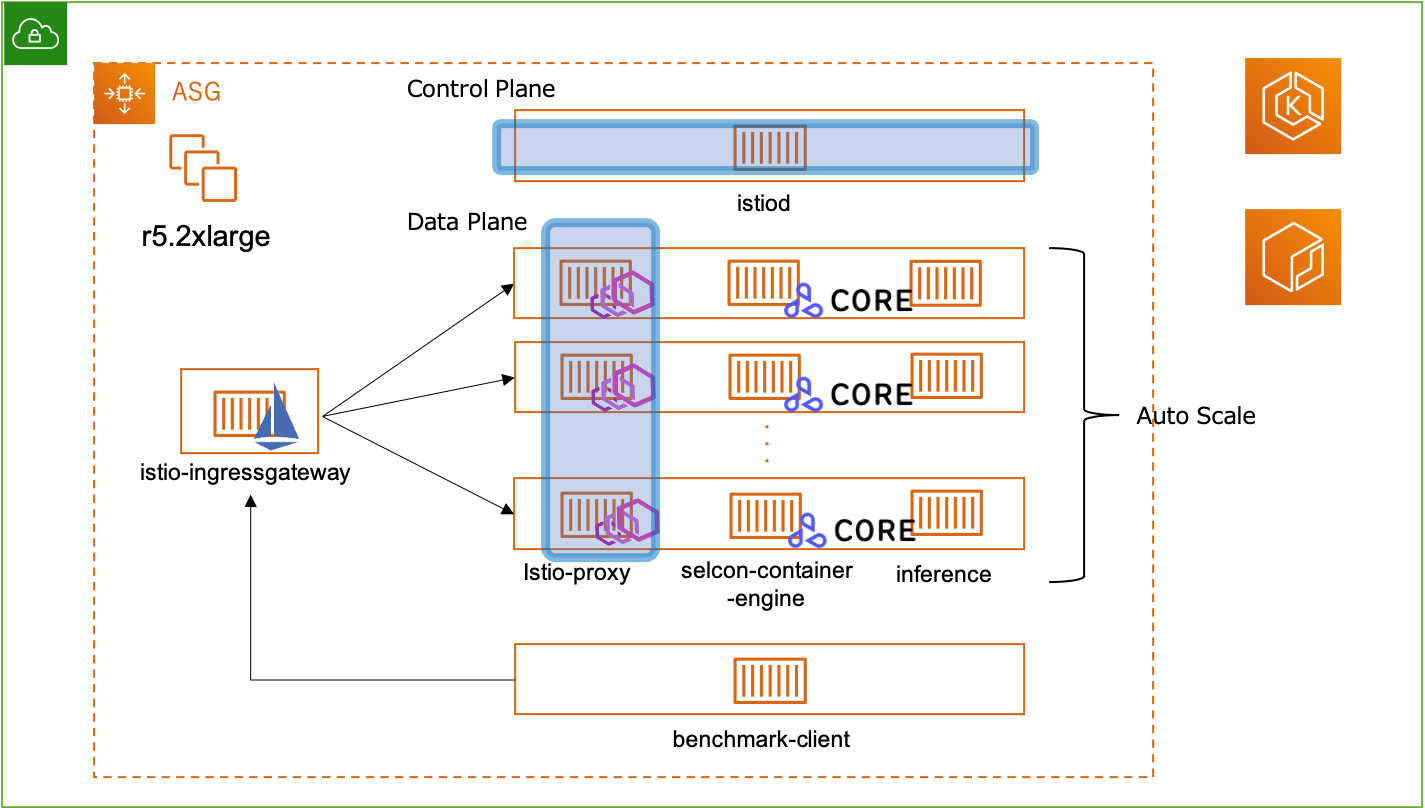
AWS EKSクラスターを展開して、その上に Seldon Core を用いてモデルを API 化することにします。
Seldon Core は機械学習モデルを REST/gRPC マイクロサービスとして K8s 上にデプロイするための Open-source platform です。
公式リポジトリに Istio と組み合わせた方法が記載されていたため、その方法に則って行います。
Istio は モデルを API 化した際の ingress gateway の機能を提供します。
1.1. 環境
- EKS
- 1.20
- Auto Scaling Group(Worker Node)
- r5.2xlarge
- 8 vCPU
- 64 GiB
- r5.2xlarge
- Istio
- 1.12.0
- Seldon Core
- 1.11.2
2. 準備
今回、 EKS クラスターの作成はメインではないため省略させていただき、パッケージのインストールから説明していきます。
2.1. Istio
公式サイトから istio をダウンロードし、 istioctl から demo プロファイル(チュートリアル実行用のプロファイル)を指定してインストールします。
demo プロファイルでは、 istio-egressgateway, istio-ingressgateway, istiod が istio-system 名前空間で起動します。(istio-egressgateway もデプロイされますが、今回は使用しません)
$ curl -L https://istio.io/downloadIstio | sh -
$ cp ./istio-1.12.1/bin/istioctl /usr/bin
$ istioctl install --set profile=demo -y
以下のコマンドを実行してインストールされていることを確認できます。
$ kubectl get service -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-egressgateway ClusterIP 10.100.94.113 <none> 80/TCP,443/TCP 12d
istio-ingressgateway LoadBalancer 10.100.80.19 <pending> 15021:30311/TCP,80:31360/TCP,443:30016/TCP,31400:30035/TCP,15443:31515/TCP 12d
istiod ClusterIP 10.100.92.147 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 12d
続いて Gateway の設定をします。
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: seldon-gateway
namespace: istio-system
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
$ kubectl apply -f seldon-gateway.yml
2.2. Helm
EKS クラスターに Helm をインストールします。
Helm は K8s 用のパッケージマネージャで Seldon Core をインストールするのに使います。
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 > get_helm.sh
$ chmod 700 get_helm.sh
$ ./get_helm.sh
次のコマンドを使用してインストールされているか確認できます。
$ helm help
2.3. Seldon Core
以下のリンクに従って Helm を使ってインストールしていきます。
$ kubectl create namespace seldon-system
$ helm install seldon-core seldon-core-operator \
--repo https://storage.googleapis.com/seldon-charts \
--set usageMetrics.enabled=true \
--set istio.enabled=true \
--namespace seldon-system
モデルをデプロイするための名前空間も予め作成しておきます。
$ kubectl create namespace model
# Pod がデプロイされた時に Sidecar Proxy が自動追加されるように設定する
$ kubectl label namespace model istio-injection=enabled
2.4. metrics-server
オートスケールさせるために必要なメトリクスを収集するサービスをデプロイします。
これにより、 CPU/Memory ベースでのスケールイン/アウトが可能となります。
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
2.5. モデル
ここでは iris データセットを使って xgboost のモデルを作成します。
import joblib
from sklearn import datasets
import xgboost as xgb
iris = datasets.load_iris()
dtrain = xgb.DMatrix(iris.data, label=iris.target)
xgb_params = {
'objective': 'multi:softprob',
'num_class': 3,
'eval_metric': 'mlogloss'
}
bst = xgb.train(xgb_params,dtrain,num_boost_round=100)
joblib.dump(bst, 'model.joblib')
このコードを実行すると model.joblib という名前のモデルが作成されます。
3. モデルのデプロイ
モデルのデプロイは以下の手順で行います。
- 推論用のクラスを作成する
- イメージを作成しレジストリにプッシュする
- APIとしてモデルをデプロイする
3.1. 推論用のクラスを作成する
今回は Python を使用して推論用のクラスを作成していきます。
この際、クラス名とそのファイル名は一致させておくようにします(ビルドの際にそういった指定があります)。
他にも Go, Java, Nodejs, C++, R などのラッパーがあります。
import joblib
import logging
import numpy as np
from typing import Iterable, List, Union
import xgboost as xgb
logger = logging.getLogger(__name__)
JOBLIB_FILE = "model.joblib"
class MyModel(object):
def __init__(self) -> None:
logger.info("Initializing")
self.load()
def load(self) -> None:
logger.info("Load Model")
try:
self._model = joblib.load(JOBLIB_FILE)
except Exception as e:
logging.exception("Exception during load model")
logging.error(e)
def predict(
self, X: np.ndarray, features_names: Iterable[str] = None
) -> Union[np.ndarray, List, str, bytes]:
try:
X = xgb.DMatrix(X)
predictions = self._model.predict(X)
except Exception as e:
logging.exception("Exception during predict")
logging.error(e)
return predictions
3.2. イメージを作成しレジストリにプッシュする
Dockerfile をビルドしてイメージを作成し、ECR にプッシュします。
フォルダ構成は以下のようになっており、 model.joblib は 2.4 で作成したモデルです。
iris-model-server/
├ Dockerfile
├ requirements.txt
├ model.joblib
└ MyModel.py
コンテナ内には以下のライブラリをインストールします。
joblib==1.1.0
numpy==1.21.4
seldon-core==1.12.0
xgboost==1.5.1
Dockerfile は 公式 を参考にし、 MODEL_NAME にはファイル名(=クラス名)を指定し、 SERVICE_TYPE には MODEL を指定します。
FROM python:3.8.7-buster
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
# Port for GRPC
EXPOSE 5000
# Port for REST
EXPOSE 9000
# Define environment variable
ENV MODEL_NAME MyModel
ENV SERVICE_TYPE MODEL
CMD exec seldon-core-microservice $MODEL_NAME --service-type $SERVICE_TYPE
イメージをビルドします。
$ docker build . -t mymodel:1.0
ECR にプッシュします。
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com
$ docker tag mymodel:1.0 XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/mymodel:1.0
$ docker push XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/mymodel:1.0
XXXXXXXXXXXX には、ご自身の AWS アカウントの ID を入力して下さい。
3.3. APIとしてモデルをデプロイする
作成したイメージを 2.3 で作っておいた model 名前空間に SeldonDeployment としてデプロイします。
ここでは、自動スケーリング(スケールイン/アウト)するために HorizontalPodAutoscaler の仕様も定義します。
はじめに レプリカ数=1 としてレプリカセットをデプロイし、最大 20 までレプリカ数をスケールアウトできるように設定しました。
今回は手始めということもありスケーリングの基準に CPU 使用率を利用します。
平均で 40% を超えたらスケールアウトさせるようにします(スケーリングを体感したかったため、少し低めに設定しました)。
正確には、以下の計算式に基づき自動スケーリングされます。
(必要なレプリカ数) = ceil(sum( Pod の現在の CPU 使用率)/ targetAverageUtilization )
デプロイのための yml ファイルです。
CPUに基づいたオートスケーリングをするためには CPU リソース の request は必須なので、きちんと記述するようにしましょう。
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model-autoscale
namespace: model
spec:
name: iris-model-autoscale
predictors:
- componentSpecs:
- hpaSpec:
maxReplicas: 20
metrics:
- resource:
name: cpu
targetAverageUtilization: 40
type: Resource
minReplicas: 1
spec:
containers:
- image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/mymodel:1.0
imagePullPolicy: Always
name: classifier
resources:
requests:
cpu: '0.5'
graph:
children: []
name: classifier
type: MODEL
name: autoscale
replicas: 1
デプロイをします。
$ kubectl apply -f iris-model-autoscaling.yml
きちんとデプロイされたかは以下のコマンドで確認することができます。
$ kubectl get sdep -n model
NAME AGE
iris-model-autoscale 19m
なお、以下のコマンドでも確認できます。(ポッド単位)
$ kubectl get po -n model
NAME READY STATUS RESTARTS AGE
iris-model-autoscale-autoscale-0-classifier-6b47479775-t5q86 3/3 Running 0 19m
ここで、1つのポッドに3つのコンテナが動いていることが分かると思いますが、classifier, seldon-container-engine, istio-proxy が動いています。
それぞれ以下の役割をもっています。
-
classifier: 推論用のコンテナ -
seldon-container-engine: サービスオーケストレータで、複数のモデルを使った複雑な推論を実現してくれるコンテナ- 今回のような一つのモデルしか扱わない場合は実質不要で
seldon.io/no-engine: "true"をアノテーションとして追加して立ち上がらなくすることもできる
- 今回のような一つのモデルしか扱わない場合は実質不要で
-
istio-proxy: istio のデータプレーンがサイドカーとして動いているコンテナ
4. ベンチマーク
ここからはポッドのスケーリングを体感していきます。
リクエストに波があるようなワークロードを想定し、徐々に負荷を上げていき、一定時間経ったら負荷を下げていくようなことをやってみたいと思います。
この際、ベンチマークのためのスクリプトも書きましたが、作成するのはこれが初めてなので、イケていなくてもご容赦下さい。。
4.1. ベンチマークの設計
一回のベンチマークで複数のタスクを実行するようにします。
タスクはデータの大きさ(data_size)、量(data_amount)、クライアントの数(client_num)のパラメータから構成されます。
- data_size : 一回のリクエストで送るデータの大きさ(特徴量の数 × データの個数)
- data_amount : 一回のタスクで送る data_size の数
- client_num : リクエストをするクライアントの数(スレッドの数)
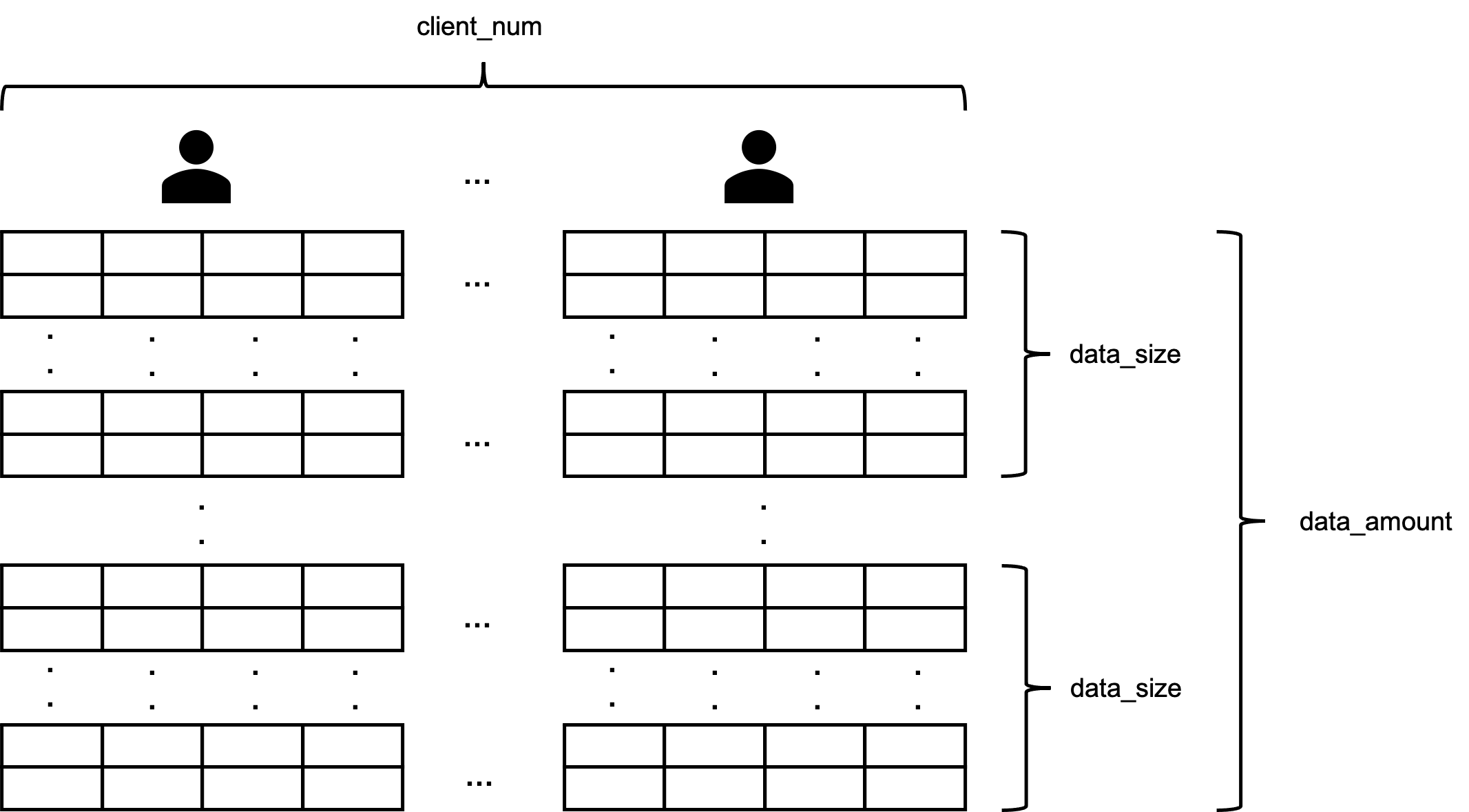
一回のベンチマークで複数のタスクを定義し、パラメータを変化させながら負荷の上げ下げをおこなっていきたいと思います。
以下はベンチマーク用のスクリプトとなっています。
はじめにリクエストのためのデータを生成し、それをスレッドによって非同期でリクエストを送るように実装しました。
リクエストにかかった時間も計測するようにしました。
from concurrent.futures import ThreadPoolExecutor
import dataclasses
from functools import wraps
import logging
import random
import sys
import time
from typing import Callable, Dict
import numpy as np
from seldon_core.seldon_client import SeldonClient
# Config
NAMESPACE = "model"
GATEWAY_ENDPOINT = "10.100.80.19"
GATEWAY = "istio"
FEATURE_NUM = 4
# ログの出力設定
logger = logging.getLogger('benchmark')
logger.setLevel(logging.INFO)
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d:%(name)s:[%(levelname)s]:%(funcName)s():%(message)s' \
, datefmt='%Y/%m/%d %H:%M:%S')
ch.setFormatter(formatter)
logger.addHandler(ch)
logger_calc = logging.getLogger('benchmark-calc')
logger_calc.setLevel(logging.INFO)
fh = logging.FileHandler('calc_log.csv')
formatter_calc = logging.Formatter('%(asctime)s.%(msecs)03d,%(message)s' \
, datefmt='%Y/%m/%d %H:%M:%S')
fh.setFormatter(formatter_calc)
logger_calc.addHandler(fh)
@dataclasses.dataclass
class Task:
data_size: int
data_amount: int
client_num: int
def __post_init__(self) -> None:
self.data = [self._create_dataset(self.data_size) for _ in range(self.data_amount)]
def _create_dataset(self, n: int) -> np.ndarray:
data = []
for _ in range(n):
tmp = [random.randrange(1,5) for _ in range(FEATURE_NUM)]
data.append(tmp)
return np.array(data)
def stop_watch(func: Callable) -> Callable:
@wraps(func)
def wrapper(*args, **kargs) :
start = time.time()
result = func(*args,**kargs)
elapsed_time = time.time() - start
logger_calc.info(f"{elapsed_time}")
return result
return wrapper
@stop_watch
def predict(sc: SeldonClient, data: np.ndarray) -> Dict:
return sc.predict(transport="rest", data=data, client_return_type="dict")
def task(data: np.ndarray) -> Dict:
deployment_name = sys.argv[1]
sc = SeldonClient(deployment_name=deployment_name
, namespace=NAMESPACE
, gateway_endpoint=GATEWAY_ENDPOINT
, gateway=GATEWAY
)
return predict(sc, data)
def main() -> None:
# 第一引数にはデプロイした SeldonDeployment 名が入る
if len(sys.argv) != 2:
logger.error("Wrong number of arguments")
exit()
# prepare benchmark for data_size
logger.info("start preparing data")
task1 = Task(data_size=500, data_amount=1500, client_num=4)
logger.info("finish preparing data: 1st task")
task2 = Task(data_size=1000, data_amount=1500, client_num=4)
logger.info("finish preparing data: 2nd task")
task3 = Task(data_size=5000, data_amount=1500, client_num=4)
logger.info("finish preparing data: 3rd task")
task4 = Task(data_size=10000, data_amount=1500, client_num=4)
logger.info("finish preparing data: 4th task")
# start benchmark
logger.info("1st task")
with ThreadPoolExecutor(max_workers=task1.client_num) as executor:
for d in task1.data:
executor.submit(task, d)
logger.info("2nd task")
with ThreadPoolExecutor(max_workers=task2.client_num) as executor:
for d in task2.data:
executor.submit(task, d)
logger.info("3rd task")
with ThreadPoolExecutor(max_workers=task3.client_num) as executor:
for d in task3.data:
executor.submit(task, d)
logger.info("4th task")
with ThreadPoolExecutor(max_workers=task4.client_num) as executor:
for d in task4.data:
executor.submit(task, d)
logger.info("5th task")
with ThreadPoolExecutor(max_workers=task3.client_num) as executor:
for d in task3.data:
executor.submit(task, d)
logger.info("6th task")
with ThreadPoolExecutor(max_workers=task2.client_num) as executor:
for d in task2.data:
executor.submit(task, d)
logger.info("7th task")
with ThreadPoolExecutor(max_workers=task1.client_num) as executor:
for d in task1.data:
executor.submit(task, d)
if __name__ == "__main__":
main()
リクエスト先は istio の ingressgateway であり、 clusterIP を指定してデータを送ります。
clusterIP の確認は以下のコマンドでできます。
$ kubectl get svc istio-ingressgateway -n istio-system -o jsonpath='{.spec.clusterIP}'
10.100.80.19
ここから、data_size を変えることで負荷状況を変化させ、オートスケールするかどうかを観測していきたいと思います。
data_amount は負荷を与え続ける時間を調整できるようにパラメータ化しましたが、今回は固定値を与えることにします。
また、cluster_num も用意しましたが、リクエスト数に応じてスケールするようにはなっていないため、こちらも固定値を設定したいと思います。(色々と柔軟に設定できるように頑張りましたが、それぞれのパラメータを変えての検証まではできませんでした。。今後機会があれば活用していきたいと思います!)
4.2. データの大きさを変化させてみる
データの大きさ(data_size) のみを変化させてベンチマークを走らせてみます。
タスクを次のように定義して、 data_size を徐々に大きくしていき、その後徐々に小さくしていくといったことを行います。
| No. | data_size | data_amount | client_num |
|---|---|---|---|
| 1st | 500 | 1500 | 4 |
| 2nd | 1000 | 1500 | 4 |
| 3rd | 5000 | 1500 | 4 |
| 4th | 10000 | 1500 | 4 |
| 5th | 5000 | 1500 | 4 |
| 6th | 1000 | 1500 | 4 |
| 7th | 500 | 1500 | 4 |
下図のような結果になりました。
青線は推論にかかった時間(リクエストを投げてからレスポンスが返ってくるまでの時間)を表し、黄線はポッドのレプリカ数を表しています。
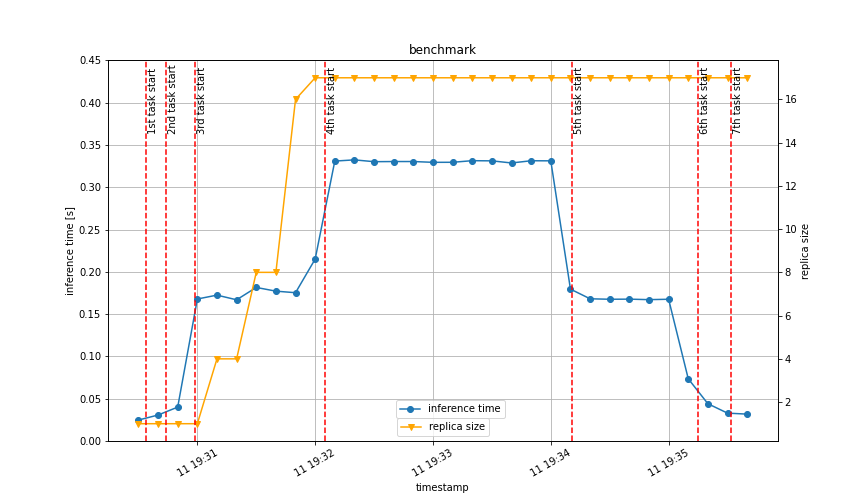
黄線を見て分かる通り data_size が大きくなったことでレプリカ数が増えていることが分かります。
正確には、 3rd タスクを行っている時に一気に増えてており、一番 data_size の大きい 4th タスクでは増えませんでした。
詳しく検証できておらず申し訳ないのですが、データが大きすぎることによる分割損みたいなことが発生しているのではないか、と推測しています(現在、 1pod/1node のような設定を特にしていないため、この部分を設定すれば変化はあるかもしれません)。
5th タスク以降の data_size を小さくしていった場合は、すぐにはスケールインされませんでした(図にはベンチマーク終了までしか載せていませんが、終了してから約5分後くらいにスケールインされました)。
K8s 1.18 からはスケールイン/アウトに対して「10秒間にレプリカ数を2倍にする」といった設定もできるみたいなので、こちらの設定をすればすぐにスケールインすることもできるかもしれません。興味がある方は試してみて下さい。
5. さいごに
モチベーションが「機械学習モデルを API 化してオートスケールさせてみたい」だったので、それは達成することができました。
しかし、今回実施したオートスケールは CPU 使用率をもとにしたもののみで、リクエスト数に応じたスケーリングなどは試せませんでした。
また、ベンチマークスクリプトも柔軟に設定できるようにした割には色々と検証できていないのが心残りです。
そのため、今後機会があればこれらのことを試していきたいと思っています。
最後まで見てくださりありがとうございました!
6. 参考
- SeldonIO/seldon-core: An MLOps framework to package, deploy, monitor and manage thousands of production machine learning models
- Istio / Getting Started
- Istio / Install with Istioctl
- Istioのインストール、サイドカープロキシ(Envoy)の挿入、マイクロサービスの可視化:Cloud Nativeチートシート(10) - @IT
- Amazon EKS での Helm の使用 - Amazon EKS
- Install Seldon-Core — seldon-core documentation
- kubernetes-sigs/metrics-server: Scalable and efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines.
- Seldon Python Component — seldon-core documentation
- Packaging a Python model for Seldon Core using Docker — seldon-core documentation
- Pythonで処理の時間を計測する冴えた方法 - Qiita
- Kubernetes完全ガイド 第2版 impress top gear