こんにちは。NTTドコモ入社1年目の九島です。
アドベントカレンダー16日目の本記事では、YouTubeで再生されやすいサムネの特徴をディープラーニングで解析する方法について詳しくご紹介します。
使用したプログラミング言語はPythonです。
はじめに
本記事は、以下の2部構成となっています。
- YouTube Data APIをPythonで利用する方法
- ディープラーニングに基づく動画サムネイルの分類
「YouTube Data APIをPythonで利用する方法」では、YouTube動画の情報を取得するために必要な準備から、実際に取得するコードの説明まで記載しています。
本記事を参考にすることで、
実際にYouTube動画の視聴回数やサムネイルの画像を取得できます。
「ディープラーニングに基づく動画サムネイルの分類」では、ディープラーニングの一種であるConvolutional Neural Network (CNN)の簡単な説明から、それに基づいて動画サムネイルを分類するコードの説明まで記載しています。
本記事を参考にすることで、
実際にCNNで分類モデルを構築し、動画サムネイルに適用できます。
YouTube Data APIを利用してYouTube動画のデータ分析をしたい方や、ディープラーニングでひとまず画像分類をしてみたい方の参考になれば幸いです。
また最終的に、画像分類の結果からどのような画像が多く視聴されるのかを考察しました。
YouTubeで再生されやすいサムネは、以下の特徴がありました。
YouTubeで再生されやすいサムネの特徴
- 色の彩度が高い
- 色の数が多い
- テロップの文字数が多い
- 人物やキャラクターの顔が写っている
※本記事では、Pythonを実行できる環境がある前提で話を進めます。
YouTube Data APIをPythonで利用する方法
YouTube Data APIとは
YouTube Data APIは、YouTubeに投稿されている動画の情報を取得可能なAPIです。
YouTube Data APIの公式ドキュメント:
https://developers.google.com/youtube/v3/getting-started?hl=ja
YouTube Data APIで取得可能な動画に関する情報の例を以下に記載します。
- タイトル
- チャンネル名
- 視聴回数
- 高評価数
- サムネイルのURL
本記事では、視聴回数とサムネイルを利用しました。
YouTube Data APIを利用するための準備
YouTube Data APIを利用するためには、以下の準備が必要です。
- Googleアカウントの作成
- 新しいプロジェクトの作成
- APIとサービスの有効化
- APIキーの取得
それぞれの準備について詳細に説明します。
※Googleアカウントの作成は省略します。
新しいプロジェクトの作成
以下にアクセスし、「プロジェクトを作成」をクリックして任意の名前の新しいプロジェクトを作成します。
http://console.developers.google.com/project
プロジェクトを作成すると、通知等からプロジェクトの管理画面にアクセスできます。
APIとサービスの有効化
プロジェクトの管理画面にアクセスできたら、「APIの概要に移動」、「APIとサービスの有効化」を順にクリックし、APIライブラリへアクセスします。
APIライブラリでは、有効にしたいAPIを検索することができます。
「YouTube Data API」等で検索し、検索結果の「YouTube Data API v3」を選択、そして「有効にする」をクリックすることで、YouTube Data APIの有効化が完了します。
APIキーの取得
プロジェクトの管理画面またはYouTube Data APIの管理画面の左側に「認証情報」というタブがあります。
それをクリックし(プロジェクトの管理画面からクリックした場合はYouTube Data APIを選択後)、「認証情報を作成」、「APIキー」を順にクリックするとAPIキーが作成されます。
※ここで作成したAPIキーは後で使用するのでコピーしておいてください。
以上でYouTube Data APIを利用するための準備は完了です。
Python側の準備
PythonでYouTube Data APIを利用するためには、以下のpipコマンドで事前にライブラリをインストールします。
pip install google-api-python-client
YouTube動画の情報を取得
YouTube動画の情報は以下のコードを実行することで取得できます。
from apiclient.discovery import build
YOUTUBE_API_KEY = '{取得したAPIキー}'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
search_response = youtube.search().list(
part='snippet',
# 検索クエリ
q='ゲーム実況',
# 視聴回数の多い順
order='viewCount',
type='video',
).execute()
取得した情報の詳細は、以下のようにsearch_responseの中身を確認することで見ることができます。
search_response['items'][0]
確認できる要素例:
-
videoId: 動画のID -
channelId: チャンネルのID -
title: 動画のタイトル -
description: 動画の説明欄 -
thumbnails: 動画のサムネイル(URL情報) -
channelTitle: チャンネル名 -
publishTime: 投稿日
また、上記のvideoIdを用いて以下のコードを実行することで、動画の視聴回数や高評価数も確認することができます。
statistics = youtube.videos().list(
# 統計情報
part = 'statistics',
id = {動画のvideoId}
).execute()['items'][0]['statistics']
確認できる要素例:
-
viewCount: 視聴回数 -
likeCount: 高評価数
取得できる情報やAPIの使い方などをより詳細に確認したい方は公式ドキュメントをご覧ください。
YouTube Data APIの公式ドキュメント:
https://developers.google.com/youtube/v3/getting-started?hl=ja
また、複数の動画の情報をデータフレームに格納し、分析したい場合は以下の方法があります。
まず、検索する条件を指定します。
以下のコードでは、検索クエリはゲーム実況、視聴回数の多い順、50件の結果を取得、2020/07/01 - 2020/12/01の期間、など様々なパラメータを用いて検索条件を指定できます。
search_response = youtube.search().list(
part='snippet',
# 検索クエリ
q='ゲーム実況',
# 視聴回数の多い順
order='viewCount',
type='video',
# 50件
maxResults=50,
# アップロード日が2020/07/01以降
publishedAfter='2020-07-01T00:00:00Z',
# アップロード日が2020/12/01以前
publishedBefore='2020-12-01T00:00:00Z'
)
output = youtube.search().list(
part='snippet',
q='ゲーム実況',
order='viewCount',
type='video',
maxResults=50,
publishedAfter='2020-07-01T00:00:00Z',
publishedBefore='2020-12-01T00:00:00Z'
).execute()
次に、for文で検索結果をリストに格納します。
ここで注意していただきたいことは、YouTube Data APIは無料で利用する場合、使用回数に制限があるという点です。
YouTube Data APIの管理画面の左側に「割り当て」というタブがありまして、そちらを確認すると、10,000 Queries / 日という表記があります。
一回のコード実行でどれだけ消費されるか未検証ですが、無料利用の場合は制限があるという点にご注意ください。
# ループ回数
num = 20
# 動画情報を格納するリスト
video_list = []
for i in range(num):
video_list = video_list + output['items']
search_response = youtube.search().list_next(search_response, output)
output = search_response.execute()
最後に、上記で作成したリストをデータフレームへ変換します。
以下では、HighViewCountという変数で視聴回数のフィルタリングをかけています。
import pandas as pd
# 統計情報を取得する関数
def get_statistics(id):
statistics = youtube.videos().list(part = 'statistics', id = id).execute()['items'][0]['statistics']
return statistics
# フィルタリングする視聴回数の値
HighViewCount = 100000
df = pd.DataFrame(video_list)
df1 = pd.DataFrame(list(df['id']))['videoId']
df2 = pd.DataFrame(list(df['snippet']))[['channelTitle','publishedAt','channelId','title','description']]
df3 = pd.DataFrame(list(pd.DataFrame(list(pd.DataFrame(list(df['snippet']))['thumbnails']))['high']))['url']
ddf = pd.concat([df1, df2, df3], axis = 1)
df_static = pd.DataFrame(list(ddf['videoId'].apply(lambda x : get_statistics(x))))
df_output = pd.concat([ddf,df_static], axis = 1)
df_output['viewCount'] = df_output['viewCount'].astype(int)
# 視聴回数で動画をフィルタリング
df_highview = df_output[df_output['viewCount']>=HighViewCount]
YouTube動画のサムネイルを取得
前項で取得できたデータフレームを利用して、動画のサムネイルそのものを取得します。
以下、サムネイルを取得するコード例です。
※下に注意点が書いてあります。
import requests
df_highview = df_highview.drop_duplicates()
df_highview = df_highview.reset_index(drop=True)
df_loop = df_highview
for i in range(len(df_loop)):
#URLを入力して画像そのものを取得
response = requests.get(df_loop.loc[i, 'url'])
image = response.content
filename = './image_' + str(i) + '.jpg'
with open(filename, "wb") as f:
f.write(image)
こちらのコードでは、前項で取得した情報の中のサムネイルURLの部分を取り出し、画像を取得しています。
ただし注意点として、上記のような画像URLへアクセスするコードを書く際には、サーバーへ負担がかからないように工夫してください。
上記のコードは例なので、アクセスする間隔を空けるなどの対処は適宜行なってください。
この点についてより詳細に調べたい方は以下の記事をご参考ください。
以上で本記事の一つ目のゴールである「実際にYouTube動画の視聴回数やサムネイルの画像を取得する」が完了しました。
ディープラーニングに基づく動画サムネイルの分類
Convolutional Neural Network (CNN)とは
ディープラーニングの一種であるCNNは、ニューラルネットワークに畳み込み処理を導入した深層学習モデルです。
画像認識・分類に適したモデル構造となっており、その分野でよく使われるモデルです。
本記事では、動画サムネイルに対して一般的な構造のCNNを適用し、分類問題を解きます。
分類問題の設定
本記事では、視聴回数とサムネイルの情報を利用することで、視聴回数の多いサムネイルと少ないサムネイルを分類する問題を解くことを考えます。
具体的に、検索クエリをゲーム実況として取得した動画に対して、視聴回数が10万回以上と1万回以下で、正例と負例を分け、それらのサムネイル画像を用いてCNNのモデルを構築します。
※「YouTube動画の情報を取得」の項で登場した変数HighViewCountを変更して検索することで、正例と負例のサムネイルを取得します。
動画サムネイルの読み込み
以下のコードでフォルダ上の画像データを読み込みます。
本記事で使用する画像枚数は、正例が749枚、負例が748枚です。
import glob
import PIL
import keras
from keras.preprocessing import image
# リサイズする画像サイズ
input_shape = (256, 256, 3)
# クラス数
num_classes = 2
# 画像データ
x = []
# ラベル(1:正例, 0:負例)
y = []
# 画像のファイル名
z = []
image_list_positive = glob.glob('{正例の画像フォルダのディレクトリ}/image_?.jpg')
for f in image_list_positive:
x.append(image.img_to_array(image.load_img(f, target_size=input_shape[:2])))
y.append(1)
z.append(f)
image_list_negative = glob.glob('{負例の画像フォルダのディレクトリ}/image_?.jpg')
for f in image_list_negative:
x.append(image.img_to_array(image.load_img(f, target_size=input_shape[:2])))
y.append(0)
z.append(f)
画像の前処理
以下のコードで画像に対して前処理を適用します。
import numpy as np
from keras.utils import plot_model, to_categorical
from sklearn.model_selection import train_test_split
x = np.asarray(x)
x /= 255
y = np.asarray(y)
# ラベルをカテゴリカル変数へ変換
y = keras.utils.to_categorical(y, num_classes)
# 画像データセットを学習用とテスト用に分割
x_train, x_test, y_train, y_test, z_train, z_test = train_test_split(x, y, z, test_size=0.33, random_state= 3)
# 学習用データセットをモデルの学習でそのまま使用する用と検証用に分割
x_train_train, x_train_val, y_train_train, y_train_val, z_train_train, z_train_val = train_test_split(x_train, y_train, z_train, test_size=0.1, random_state = 3)
上記のように分割したデータセットのそれぞれのボリュームを以下に記載します。
len(x_train), len(x_test)
1002, 495
len(x_train_train), len(x_train_val)
901, 101
モデルの構築
以下のコードでモデルの構築を行います。
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPool2D
from keras.optimizers import Adam
from keras.layers import Dense, Activation, Dropout, Flatten
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=adam,
metrics=['accuracy'])
分類精度の検証
構築したモデルに学習用データを当てはめて学習します。
# バッチサイズ
batch_size = 100
# エポック数
epochs = 100
history = model.fit(x_train_train, y_train_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_train_val, y_train_val))
学習したモデルを用いてテスト用データを分類します。
predictions = model.predict(x_test)
分類結果と真値から分類精度を確認します。
- 正解率
Accuracy: 0.76
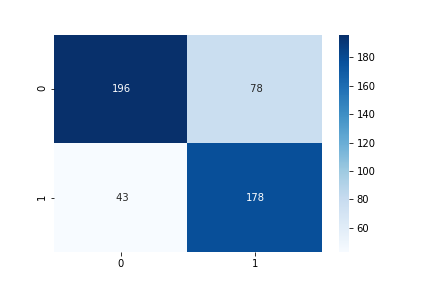
- 混同行列
True Positive: 178
True Negative: 196
False Positive: 78
False Negative: 43
- 再現率、適合率、F値
Recall: 0.81
Precision: 0.70
F-measure: 0.75
本記事では試験的なCNNの適用なので、モデルの構造やバッチサイズ、エポック数をより適切なものに変えることで高精度化が期待できると思います。
また、深層学習なので学習に使用する画像の枚数をもっと増やすべきなのですが、YouTube Data APIを無料版で利用する際の利用制限により、想定よりも画像を集められなかったという背景があります。
YouTube Data APIを利用する方はご注意ください。
以上で本記事の二つ目のゴールである「実際にCNNで分類モデルを構築し、動画サムネイルに適用できる」が完了しました。
定性評価
最後に、テスト画像の分類結果からどのような画像が多く視聴されるのかを考察します。
※画像は載せられないので、文章のみになります。
正例で正解だった画像及び負例で不正解だった画像(つまり、YouTubeで再生されやすいサムネ)の特徴を以下に挙げます。
YouTubeで再生されやすいサムネの特徴
- 色の彩度が高い
- 色の数が多い
- テロップの文字数が多い
- 人物やキャラクターの顔が写っている
あくまで主観的な評価ですが多少の傾向はあると思いました。
特徴量マップの可視化や、学習する画像の枚数の増加などを行うことで、もう少し明確な特徴が見れると思います。
まとめ
本記事では、YouTubeで再生されやすいサムネの特徴をディープラーニングで解析する方法について詳しくご紹介しました。
具体的に、以下の二つのゴールを実現するための方法を記載しました。
- 実際にYouTube動画の視聴回数やサムネイルの画像を取得できる
- 実際にCNNで分類モデルを構築し、動画サムネイルに適用できる
いかがでしたでしょうか?
本記事で少しでもみなさまのお役に立てれば幸いです。
YouTube Data APIでは、本記事で使用した情報以外にも多くの情報を取得できます。
今後は他の情報を利用してデータ分析やモデル構築をやってみたいと思います。
また、CNNの構築について、本記事では試験的な適用であったため、今後は適切なモデル構造の模索や最新手法の導入などにチャレンジしたいと思います。