はじめに
Kerasを使って画像分類プログラムを作成します。
プログラムを実行する前に大量の画像ファイル( .jpeg の形式)を用意して、画像の種類ごとにフォルダ分けしてください。後で分類テストをするので、テスト用のファイルは学習用とは別フォルダにしておいてください。
ic_module.py
インポート
Keras以外のライブラリ
import glob
import numpy as np
glob はファイル読み込みに使用します。
numpy は行列計算によく使用されるライブラリです。
Kerasのライブラリ
from keras.preprocessing.image import load_img, img_to_array, array_to_img
from keras.preprocessing.image import random_rotation, random_shift, random_zoom
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras.layers.core import Flatten
from keras.models import Sequential
from keras.models import model_from_json
from keras.callbacks import LearningRateScheduler
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
from keras.utils import np_utils
preprocessing とあるのは前処理です。
layers は学習モデルの内容の構築、その中でも convolutional は畳み込みネットワークです。
また pooling はプーリング層で、物体が画像内のどの位置にあるかを無視するために使用されます。
models は実装したモデルそのものを扱います。
callbacks は学習中に行う処理です。
optimizers は最適化のアルゴリズムです。
utils は、ここでは自然数(1, 2, 3, ...)をベクトル([1, 0, 0, ...], [0, 1, 0, ...], [0, 0, 1, ...], ...)に変換する関数のために使用しています。
処理共通のパラメータ
FileNames = ["img1.npy", "img2.npy", "img3.npy"]
ClassNames = ["うさぎ", "いぬ", "ねこ"]
hw = {"height":16, "width":16} # リストではなく辞書型 中かっこで囲む
3つに分類すると仮定しています。
FileNames は同じ種類の画像をまとめたファイル、ClassNames は画像の分類名のリストです。
ClassNames は適宜変更し、前処理ではフォルダをこの順に読み込んでください。
hw では読み込んだ画像の縮小後のサイズを指定します。
前処理
def PreProcess(dirname, filename, var_amount=3):
ここでは画像を読み込んで、サイズを16×16(height:16, width:16の場合)に統一します。
また画像を回転させたものを生成し、学習用データを増やします(var_amount=3倍にします)。
定義
num = 0
arrlist = []
画像ファイル数のカウンターと、画像ファイルをnumpy型に変換したものを入れるリストです。
ファイル読み込み
files = glob.glob(dirname + "/*.jpeg")
フォルダの中のjpegファイルのファイル名を抽出します。
画像処理
for imgfile in files:
img = load_img(imgfile, target_size=(hw["height"], hw["width"])) # 画像ファイルの読み込み
array = img_to_array(img) / 255 # 画像ファイルのnumpy化
arrlist.append(array) # numpy型データをリストに追加
for i in range(var_amount-1):
arr2 = array
arr2 = random_rotation(arr2, rg=360)
arrlist.append(arr2) # numpy型データをリストに追加
num += 1
load_img で画像ファイルを指定サイズにして読み込みます。
画像はRGB各色ごとに0~255の数値で記録されているので、255で割り0~1の数値にします。
これをarrlistに追加していきます。
さらに random_rotationで画像をランダムに回転し、これもarrlistに追加します。
保存
nplist = np.array(arrlist)
np.save(filename, nplist)
print(">> " + dirname + "から" + str(num) + "個のファイル読み込み成功")
arrlist をnumpy型にします。
numpy型のデータは save で保存できます。
モデル構築
def BuildCNN(ipshape=(32, 32, 3), num_classes=3):
ここでは学習モデルを構築します。
定義
model = Sequential()
データが分岐したり合流したりしない、単純なモデルを定義します。
層1
model.add(Conv2D(24, 3, padding='same', input_shape=ipshape))
model.add(Activation('relu'))
画像データに対し、3×3のフィルターによる畳み込み処理を24回行います。
そもそも畳み込み処理とは何か、下の画像を例に説明します。
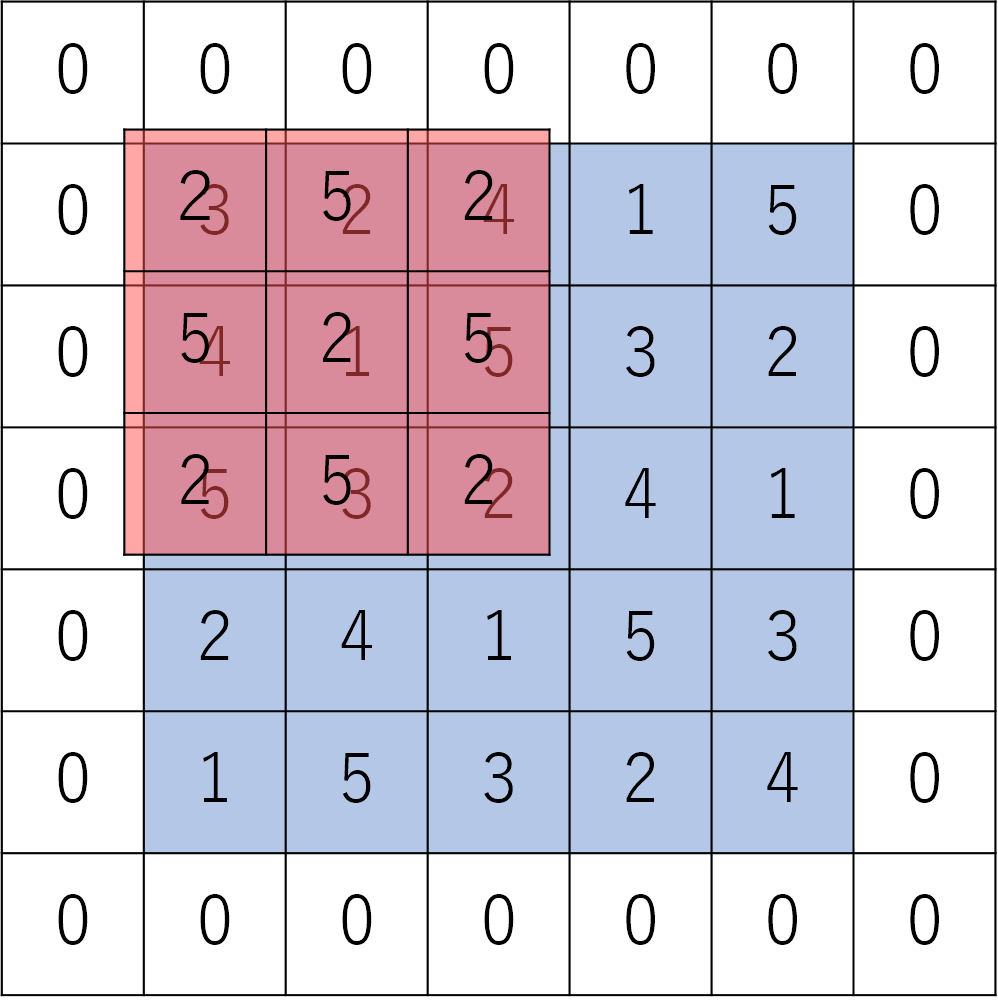
畳み込み処理ではまず赤の「フィルター」を青の「画像」に重ね合わせ、各要素ごとにかけ算をします。
2×3=6, 5×2=10, 2×4=8 といった計算ができたら、それらすべてを足し算します。
このかけ算と足し算を、フィルターを1マスずつ縦横にずらしながら行います。すると下のような結果を得ます。これが畳み込み処理です。
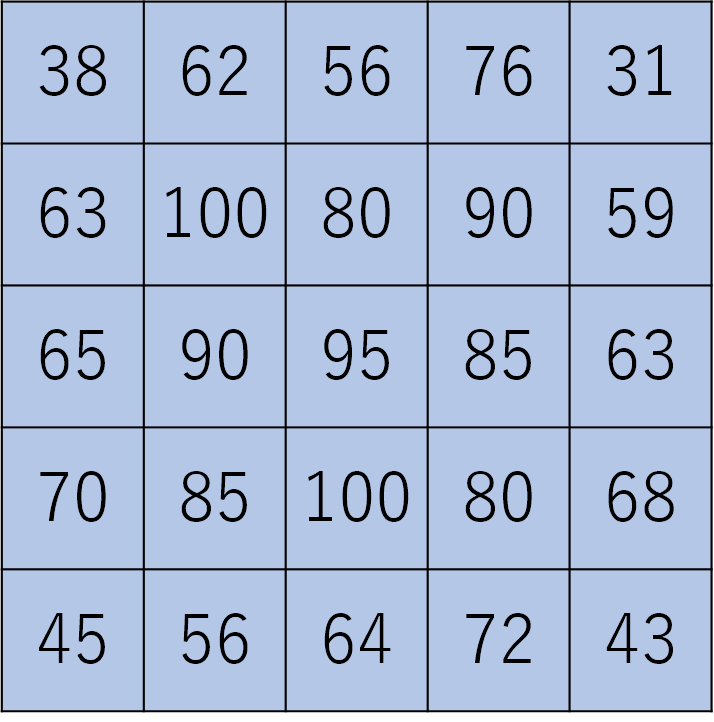
この畳み込み処理を24回行います。このことを「レイヤーが24枚」と言ったりします。
プログラムの説明に戻ると、padding='same' は画像の周りを0で埋めるという意味です。1枚目の画像が白地に「0」で囲まれているのはこれを意味していて、畳み込み処理を行った時にデータの縦横のサイズを変化させないという特徴があります。
また Activation('relu') で活性化関数にrelu関数を指定します。
層2
model.add(Conv2D(48, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
画像データに対し、3×3のフィルターによる畳み込み処理を48回行います。
MaxPooling2D はpool_size(2×2)の中の最大値を出力するものです。画像データを2×2の小領域に分割し、その中の最大値を出力します。
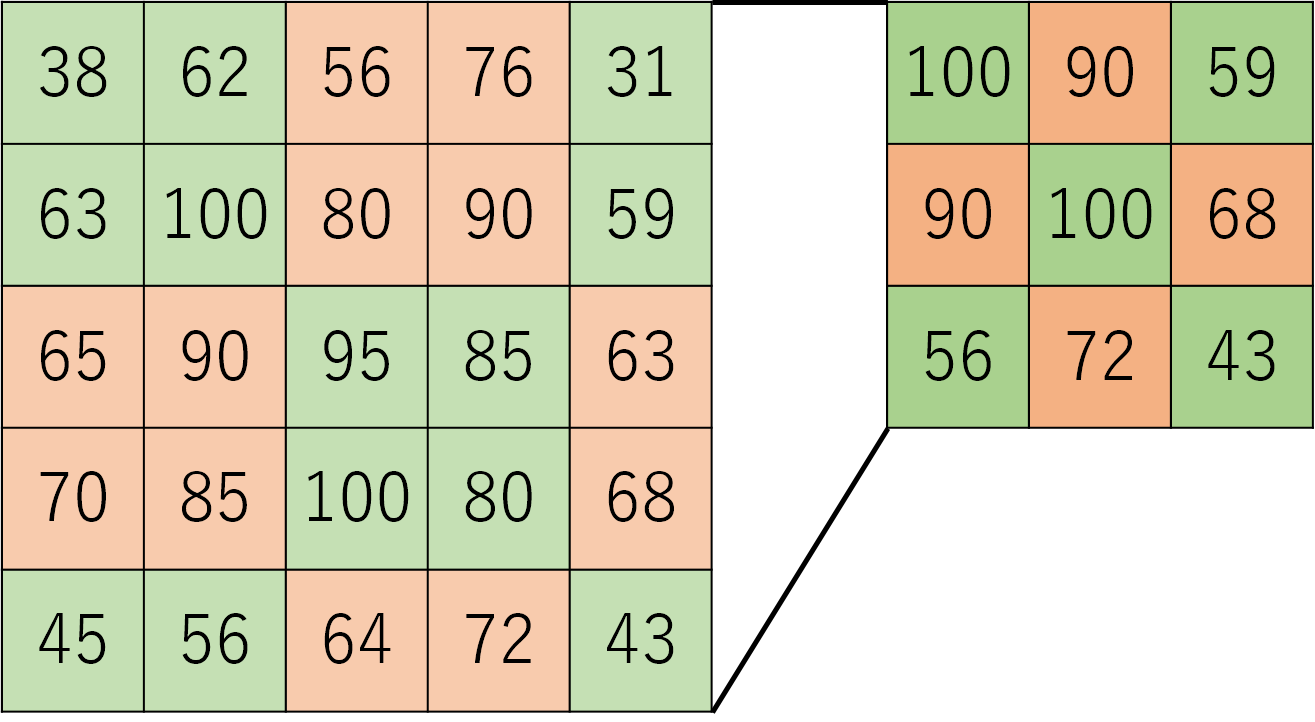
また Dropout(0.5) により入力の50%を0に置き換えます。こうすることで過学習を抑えます。
層3、層4
model.add(Conv2D(96, 3, padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(96, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
層1、層2と同様です。
違いはレイヤーが96枚(畳み込み処理が96回)になっている点です。
層5
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
今までデータを2次元配列で扱っていましたが、Flatten() と Dense(128) により要素128個の1次元配列にします。
層6
model.add(Dense(num_classes))
model.add(Activation('softmax'))
出力の個数を読み込んだフォルダの数(=画像の種類)にします。
構築
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
return model
最適化関数を Adam にして、今まで書いた構造を compile により構築します。
損失関数は分類問題でよく用いられる categorical_crossentropy です。
最後に return して、次項で各関数に構築したモデルを渡します。
学習
def Learning(tsnum=30, nb_epoch=50, batch_size=8, learn_schedule=0.9):
先ほど実装したモデルと画像データを用いて、実際に学習させます。
データの整理1
X_TRAIN_list = []; Y_TRAIN_list = []; X_TEST_list = []; Y_TEST_list = [];
target = 0
for filename in FileNames :
data = np.load(filename) # 画像のnumpyデータを読み込み
trnum = data.shape[0] - tsnum
X_TRAIN_list += [data[i] for i in range(trnum)] # 画像データ
Y_TRAIN_list += [target] * trnum # 分類番号
X_TEST_list += [data[i] for i in range(trnum, trnum+tsnum)] # 学習しない画像データ
Y_TEST_list += [target] * tsnum; # 学習しない分類番号
target += 1
学習には入力データとして画像、教師データとして分類番号を使用するので、この2つを関連付けます。
具体的には X_TRAIN_list[n] の分類番号= Y_TRAIN_list[n] とします。
また学習途中でどのくらい精度が上がっているかを見るために、tsnum 枚(画像回転で水増ししたものを含む)のデータを学習しないように分けておきます。
最後に target += 1 して、画像のnumpyデータごとに分類番号を変えています。
データの整理2
X_TRAIN = np.array(X_TRAIN_list + X_TEST_list) # 連結
Y_TRAIN = np.array(Y_TRAIN_list + Y_TEST_list) # 連結
print(">> 学習サンプル数 : ", X_TRAIN.shape)
y_train = np_utils.to_categorical(Y_TRAIN, target) # 自然数をベクトルに変換
valrate = tsnum * target * 1.0 / X_TRAIN.shape[0]
後述する関数 fit は、データの後ろの方を精度確認に使用します。
そのため X(Y)_TRAIN_list + X(Y)_TEST_list で学習しないデータを後ろに連結します。
また、現在分類番号の表記は自然数(1, 2, 3)となっていますが、このままでは学習しづらいので、ベクトル([1, 0, 0], [0, 1, 0], [0, 0, 1])に変換します。
最後の valrate はデータ全体のうちどれくらいの割合を精度確認用にするかを指定する値です。計算式により、各分類ごとに tsnum 枚を精度確認用に提供します。
学習率の変更関数
class Schedule(object):
def __init__(self, init=0.001): # 初期値定義
self.init = init
def __call__(self, epoch): # 現在値計算
lr = self.init
for i in range(1, epoch+1):
lr *= learn_schedule
return lr
def get_schedule_func(init):
return Schedule(init)
epoch数が増えるたびに、学習率を減らします。
init が最初の学習率、lr が計算後すなわち現在適用すべき学習率です。
学習が進むにつれ重みを収束しやすくします。
学習準備
lrs = LearningRateScheduler(get_schedule_func(0.001))
mcp = ModelCheckpoint(filepath='best.hdf5', monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
model = BuildCNN(ipshape=(X_TRAIN.shape[1], X_TRAIN.shape[2], X_TRAIN.shape[3]), num_classes=target)
学習に利用するパラメータを定義します。
lrs は先ほどの学習率変更関数そのものです。
mcp は学習途中で val_loss が最も小さくなるたびに、重みを保存する関数です。
model は前項で構築した学習モデルです。
学習
print(">> 学習開始")
hist = model.fit(X_TRAIN, y_train,
batch_size=batch_size,
verbose=1,
epochs=nb_epoch,
validation_split=valrate,
callbacks=[lrs, mcp])
学習は関数 fit で行います。
学習に使用するデータ X_TRAIN , y_train を指定します。
batch_size は入力データをまとめて平均化する大きさ、epochs は学習の繰り返し回数、valrate は精度確認用データの割合、callbacks は学習中に利用する関数を意味します。
保存
json_string = model.to_json()
json_string += '##########' + str(ClassNames)
open('model.json', 'w').write(json_string)
model.save_weights('last.hdf5')
学習モデルはjsonの形式で保存できます。
jsonはテキストなので、ついでに画像の分類名を付記して保存しておきます。
重みも save_weights で簡単に保存できます。
試行・実験
def TestProcess(imgname):
画像を読み込んで、学習結果をもとにそれが何の画像なのか判定します。
読み込み
modelname_text = open("model.json").read()
json_strings = modelname_text.split('##########')
textlist = json_strings[1].replace("[", "").replace("]", "").replace("\'", "").split()
model = model_from_json(json_strings[0])
model.load_weights("last.hdf5") # best.hdf5 で損失最小のパラメータを使用
img = load_img(imgname, target_size=(hw["height"], hw["width"]))
TEST = img_to_array(img) / 255
モデルのデータ、学習済みの重みデータを読み込みます。
json形式からモデルを読み込むのは model_from_json 、重みの保存ファイル読み込みは load_weights で行います。
jsonファイルには分類名が付記されているので、それを分割してからモデルを読み込んでいます。
画像を読み込むのは前処理の項でも使用した load_img です。
画像は img_to_array で数値化します。
画像分類
pred = model.predict(np.array([TEST]), batch_size=1, verbose=0)
print(">> 計算結果↓\n" + str(pred))
print(">> この画像は「" + textlist[np.argmax(pred)].replace(",", "") + "」です。")
関数 predict で学習結果を用いた計算ができます。
その計算結果は[[ 0.36011574 0.28402892 0.35585538]] のように数値が並び、各分類に分類される確率を示します。
つまり最も大きな数値で示される分類が、その画像の内容となります。
ic_module.py 全文
# ! -*- coding: utf-8 -*-
import glob
import numpy as np
from keras.preprocessing.image import load_img, img_to_array, array_to_img
from keras.preprocessing.image import random_rotation, random_shift, random_zoom
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras.layers.core import Flatten
from keras.models import Sequential
from keras.models import model_from_json
from keras.callbacks import LearningRateScheduler
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
from keras.utils import np_utils
FileNames = ["img1.npy", "img2.npy", "img3.npy"]
ClassNames = ["うさぎ", "いぬ", "ねこ"]
hw = {"height":32, "width":32} # リストではなく辞書型 中かっこで囲む
################################
###### 画像データの前処理 ######
################################
def PreProcess(dirname, filename, var_amount=3):
num = 0
arrlist = []
files = glob.glob(dirname + "/*.jpeg")
for imgfile in files:
img = load_img(imgfile, target_size=(hw["height"], hw["width"])) # 画像ファイルの読み込み
array = img_to_array(img) / 255 # 画像ファイルのnumpy化
arrlist.append(array) # numpy型データをリストに追加
for i in range(var_amount-1):
arr2 = array
arr2 = random_rotation(arr2, rg=360)
arrlist.append(arr2) # numpy型データをリストに追加
num += 1
nplist = np.array(arrlist)
np.save(filename, nplist)
print(">> " + dirname + "から" + str(num) + "個のファイル読み込み成功")
################################
######### モデルの構築 #########
################################
def BuildCNN(ipshape=(32, 32, 3), num_classes=3):
model = Sequential()
model.add(Conv2D(24, 3, padding='same', input_shape=ipshape))
model.add(Activation('relu'))
model.add(Conv2D(48, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(96, 3, padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(96, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy'])
return model
################################
############# 学習 #############
################################
def Learning(tsnum=30, nb_epoch=50, batch_size=8, learn_schedule=0.9):
X_TRAIN_list = []; Y_TRAIN_list = []; X_TEST_list = []; Y_TEST_list = [];
target = 0
for filename in FileNames :
data = np.load(filename) # 画像のnumpyデータを読み込み
trnum = data.shape[0] - tsnum
X_TRAIN_list += [data[i] for i in range(trnum)] # 画像データ
Y_TRAIN_list += [target] * trnum # 分類番号
X_TEST_list += [data[i] for i in range(trnum, trnum+tsnum)] # 学習しない画像データ
Y_TEST_list += [target] * tsnum; # 学習しない分類番号
target += 1
X_TRAIN = np.array(X_TRAIN_list + X_TEST_list) # 連結
Y_TRAIN = np.array(Y_TRAIN_list + Y_TEST_list) # 連結
print(">> 学習サンプル数 : ", X_TRAIN.shape)
y_train = np_utils.to_categorical(Y_TRAIN, target) # 自然数をベクトルに変換
valrate = tsnum * target * 1.0 / X_TRAIN.shape[0]
# 学習率の変更
class Schedule(object):
def __init__(self, init=0.001): # 初期値定義
self.init = init
def __call__(self, epoch): # 現在値計算
lr = self.init
for i in range(1, epoch+1):
lr *= learn_schedule
return lr
def get_schedule_func(init):
return Schedule(init)
lrs = LearningRateScheduler(get_schedule_func(0.001))
mcp = ModelCheckpoint(filepath='best.hdf5', monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
model = BuildCNN(ipshape=(X_TRAIN.shape[1], X_TRAIN.shape[2], X_TRAIN.shape[3]), num_classes=target)
print(">> 学習開始")
hist = model.fit(X_TRAIN, y_train,
batch_size=batch_size,
verbose=1,
epochs=nb_epoch,
validation_split=valrate,
callbacks=[lrs, mcp])
json_string = model.to_json()
json_string += '##########' + str(ClassNames)
open('model.json', 'w').write(json_string)
model.save_weights('last.hdf5')
################################
########## 試行・実験 ##########
################################
def TestProcess(imgname):
modelname_text = open("model.json").read()
json_strings = modelname_text.split('##########')
textlist = json_strings[1].replace("[", "").replace("]", "").replace("\'", "").split()
model = model_from_json(json_strings[0])
model.load_weights("last.hdf5") # best.hdf5 で損失最小のパラメータを使用
img = load_img(imgname, target_size=(hw["height"], hw["width"]))
TEST = img_to_array(img) / 255
pred = model.predict(np.array([TEST]), batch_size=1, verbose=0)
print(">> 計算結果↓\n" + str(pred))
print(">> この画像は「" + textlist[np.argmax(pred)].replace(",", "") + "」です。")
モジュールを使う
ここまでのソースは ic_module.py というファイルに書き込み保存します。
このモジュールを使用する際は処理段階ごとに、下記のようなコードを実行してください。
画像読み込み、前処理
import ic_module as ic
import os.path as op
i = 0
for filename in ic.FileNames :
# ディレクトリ名入力
while True :
dirname = input(">>「" + ic.ClassNames[i] + "」の画像のあるディレクトリ : ")
if op.isdir(dirname) :
break
print(">> そのディレクトリは存在しません!")
# 関数実行
ic.PreProcess(dirname, filename, var_amount=3)
i += 1
フォルダ(ディレクトリ)を読み込みます。
ic_module で初めの方に書いた ClassNames の順にディレクトリを指定してください。
学習
import ic_module as ic
# 関数実行
ic.Learning(tsnum=30, nb_epoch=50, batch_size=8, learn_schedule=0.9)
tsnum で各分類から何枚を精度確認用にするかを、learn_schedule で1epochごとに学習率をどれくらい減衰させるかを指定します。また nb_epoch で学習を何回繰り返すかを指定できます。
以下は実行例です。
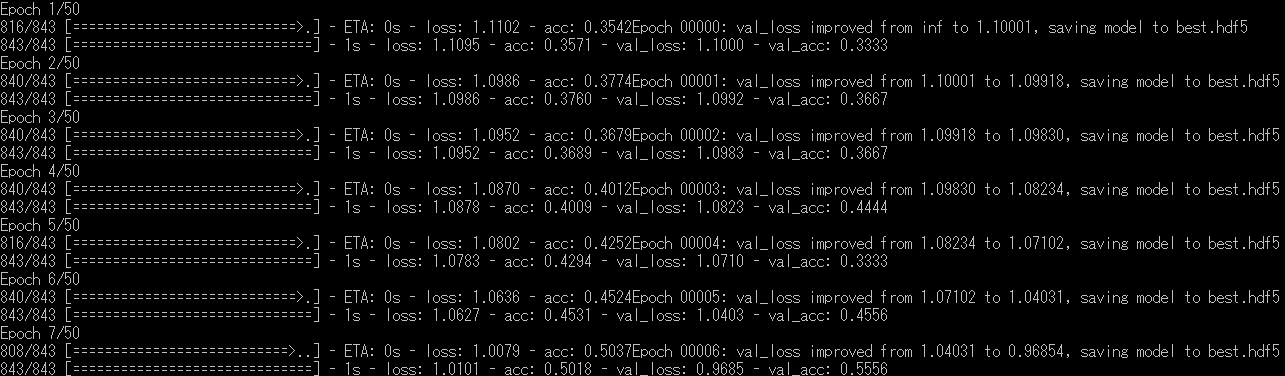
loss は計算結果と正解の値の差(損失)、acc は画像判定の精度を意味し、val_ がつくものは学習に利用していないデータを用いたときの結果です。
val_loss が小さいほど、val_acc が大きいほど学習が進んでいるといえます。
loss と val_loss や、 acc と val_acc の差が大きくなると過学習していることを意味します。これを無くすのは難しいです……
試行・実験
import ic_module as ic
import os.path as op
while True:
while True:
imgname = input("\n>> 入力したい画像ファイル(「END」で終了) : ")
if op.isfile(imgname) or imgname == "END":
break
print(">> そのファイルは存在しません!")
if imgname == "END":
break
# 関数実行
ic.TestProcess(imgname)
画像を1枚指定すると、それが何なのか判定します。
以下は実行例です。フォルダ名を忘れずに。

フォルダ内の画像一括判定
ic_moduleのTestProcessに、「return np.argmax(pred)」を追加
import glob
import ic_module as ic
import os.path as op
dirname = "dogs"#input("フォルダ名:")
files = glob.glob(dirname + "/*.jpeg")
cn1 = 0; cn2 = 0;
for imgname in files :
kind = ic.TestProcess(imgname)
if kind == 1:
cn2 += 1
cn1 += 1
print("学習・非学習含め正答率は" + str(cn2*1.0/cn1) + "です。")