NTTドコモの久保田です。2度目の登場です。
みなさんItem2Vecという技術をご存じでしょうか。
Item2Vecとは、文章から単語の分散表現を獲得するWord2Vecを推薦システムに適用した技術です。具体的にECサイトでの推薦を考えたときに、Word2Vecの単語を商品に、文章をユーザが評価したアイテム集合として、アイテムの分散表現を獲得し、アイテム間の類似度などをもとに推薦していく感じです。
簡単に実装できるので、割とやってみた系の記事が多いですが、実際に推薦システムへの適用を考えたときに気を付けるところがあります。
Item2Vecの実装方針
gensimというトピック分析のライブラリがあり、このライブラリを使えば簡単にItem2Vecを実装できます。
1行をユーザが評価しているアイテム集合、各アイテムはスペースで区切られたテキストファイル(今回は、item_buskets.txtとします)を入力として、以下の例の通りにすると、モデルを学習できます。パラメータに関しては、後段で説明します。めちゃくちゃ簡単ですね!
from gensim.models import word2vec
sentences = word2vec.LineSentence('item_buskets.txt')
model = word2vec.Word2Vec(sentences)
推薦システムへの適用を考えたときに気を付けること
トピック分析のライブラリであるgensimを使うと、簡単にItem2Vecを実装できます。しかしながら、gensimはもともと自然言語処理への適用を考えて作成されているので、問題設定が異なる推薦システムへ適用するときには問題設定に沿った変更をする必要があります。
Word2VecとItem2Vecの違い
-
データセットの違い
Word2Vecで扱うコーパスは、文章なので文法などの文章としての制約を受けたデータ構造であるのに対して、Item2Vecで扱うEコマースの購買履歴等のアイテム集合はユーザの行動やアイテムの性質によって規定されたデータ構造です。したがって、データセットの性質が異なる可能性があります。 -
適用分野の違い
Word2Vecの適用分野である自然言語処理とItem2Vecの適用分野である推薦システムでは、そもそも違います。自然言語処理において、様々な文章に登場する頻出語の正確な分散表現を獲得することが間接的には精度に影響する可能性がありますが決定的ではないはずです。一方、推薦システムにおいて、様々なユーザが購買している商品の正確な分散表現を獲得することは推薦システムが達成したいコンバージョン率のアップなどに決定的に効いてきます。
これらの違いから、Word2VecとItem2Vecのハイパーパラメータが違うだろうというのが、仮説として成り立ちます。
その仮説を検証した論文がrecsys2018で報告されたWord2vec applied to Recommendation: Hyperparameters Matterです。以下の実験設定や評価結果などはこの論文から引用しています。
実験設定
- データセット
30Music dataset、Deezer dataset、E-commerce dataset、Click-Stream datasetの4つです。それぞれのアイテムの登場回数の$ \log $をとったものが下の図です。
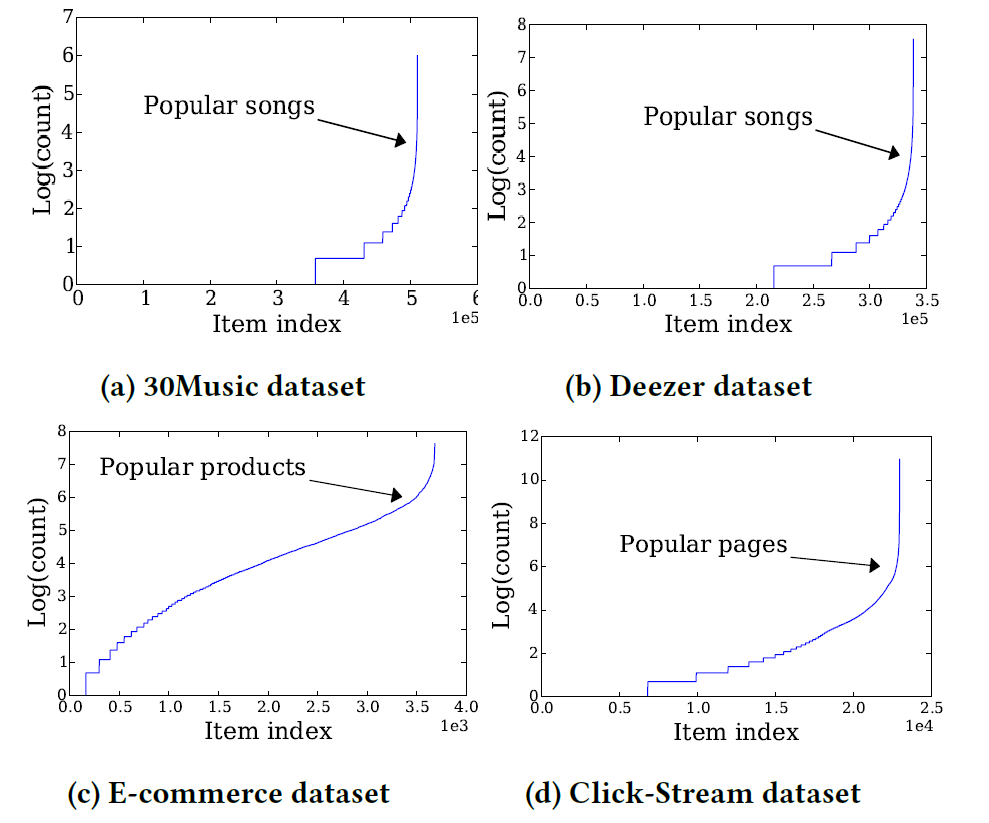
結構データセットによって分布に特徴がありますねー。last.fmのデータである30Music datasetやDeezerのデータであるDeezer datasetは音楽ストリーミング系で、人気の曲と不人気曲の間に結構差がありますね。Click-Streamデータセットに関しても同様に人気・不人気に差がありますね。一方、E-commerce datasetは先ほどの二つよりはなだらかな曲線になってます。
-
アーキテクチャ
Skip-gram with negative sampling(SGNS)を使用しています。 -
問題設定
過去の行動履歴から次のアクションを予測するという問題設定にしています。
実際にモデルを学習する際には、$ (n-1) $番目まででSGNSのモデルを学習させ、$ n $番目を予測して評価しています。 -
評価指標(Hit Ratio@K(HR@K))
ユーザ一人当たりK個のアイテムリストを作成し、$ n $番目のアイテムが入っていれば1、入っていなければ0として、それらの和をユーザ数で割った指標です。Kを大きくすればHRは大きくなります。 -
評価指標(Normalized Discounted Cumulative Gain@K(NDCG@K))
NDCGはランキングの評価指標になっていて、提示したK個で実際に$ n $番目のアイテムの予測が当たったとして、どの順番でそれを予想したのかを評価する指標になります。値が大きいほどランキングとしてよいランキングであることを示しています。
NDCG@K = \left\{
\begin{array}{ll}
\frac{1}{\log_{2} (j+1)} & (\text{if} \ j^{th} \ \text{predicted item is correct}) \\
0 & (\text{otherwise})
\end{array}
\right.
探索パラメータ
上で示した論文では、以下のパラメータの探索をして評価を行っています。
| パラメータ | gensimのWord2Vecにおいて対応するオプション |
|---|---|
| window size $ L $ | window |
| epochs $ n $ | iter |
| sub-sampling parameter $ t $ | sample |
| negative sampling distribution parameter $ \alpha $ | ns_exponent |
| embedding size | size |
| the number of negative samples | negative |
| learning rate | alpha, min_alpha |
おそらくあまり見慣れないので、$ t $と$ \alpha $ではないかなと思います。
sub-samplingのパラメータである$ t $は高頻出語のダウンサンプリングに関係するパラメータです。自然言語処理では、高頻出語である"a"や"the"には低頻出語と比較して、あまり情報量がないのでダウンサンプリングしています。推薦システムの問題設定では、高頻出語にあたる人気アイテムは推薦システムの精度にかなり効いてくるはずなので、パラメータの影響度が高そうなのはなんとなくわかります。
次に、negative sampling distribution parameterである$ \alpha $は、negative samplingする分布の形状を変更するパラメータです。gensimのデフォルトでは0.75に設定されています。$ \alpha = 1$だと、単語の頻度に基づくサンプリング、$ \alpha = 0$だとランダムサンプリングになり、負の値になると頻度が低いものをよりサンプリングしやすくなります。
論文では、表に示したパラメータの調査をしたようですが、太字の4つのパラメータ以外はパフォーマンスにあまり影響しなかったようで、4つのパラメータに関して詳細な評価を行っています。
以下の図に論文での評価結果を載せます。
gensimのデフォルトのパラメータで実装したItem2Vec(表中のOut-of-the-box SGNS)と4つのパラメータを最適なパラメータにしたItem2Vec(表中のFully optimised SGNS)だけ見ればとりあえず大丈夫かと思います。

特に人気のアイテムと不人気アイテムの差が大きかった音楽系のデータセット(30Music datasetとDeezer dataset)でデフォルトの2倍ぐらいの性能が出ていますね!Click-Stream datasetでは、約10倍の精度向上していてすごい。
論文では、30Music datasetでnegative sampling distributionのパラメータである$ \alpha $(gensimだとns_exponent)の分布と精度の関係を示しています。
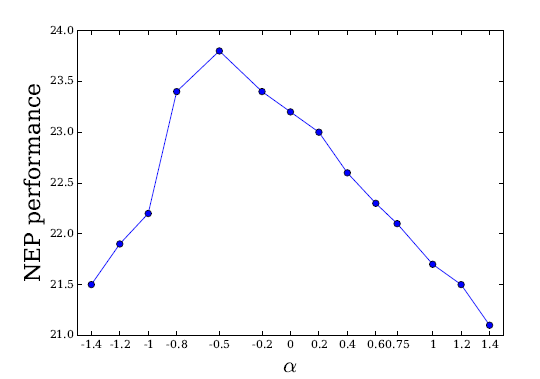
gensimのデフォルトパラメータの0.75は最適なパラメータでないことがわかりますね。ちなみに、この論文の結果を受けて、gensimのオプションで$ \alpha $に当たるns_exponentが追加されています。
まとめ
問題設定に合わせてハイパーパラメータを設定しようという論文の紹介でした。結構○○Vecが流行っているので、どういったパラメータが最適化を探索してみると面白いかもしれません。