BigQueryで遊び初めて、早5ヶ月。色んな単語と出会いました。
スロット, 分散ストレージ, シャッフル, 分割テーブル, クラスタ化テーブル・・・
特に分割テーブル, クラスタ化テーブルはBigQueryのベストプラクティスとして紹介されます。
でも、BQ初心者には何がいいんだかさっぱりわからんのです。
ドキュメントを読んでもあまりピンとこないのです。
だったら!!実際に検証して、
分割テーブルやクラスタ化テーブルがどんだけ意味があるのか?どんだけすげーのか?
確かめたいと思い、今回記事にしようと思いました。
はじめに
この記事は,NTTドコモサービスイノベーション部AdventCalendar2019の12日目の記事になります。
12日目のこの記事では,GoogleCloudPlatformのDWHサービスであるBigQueryの分割テーブル(partitioned table),クラスタ化テーブル(clustered table)について紹介するとともにどの程度性能に影響してくるかを検証してみたいと思います。
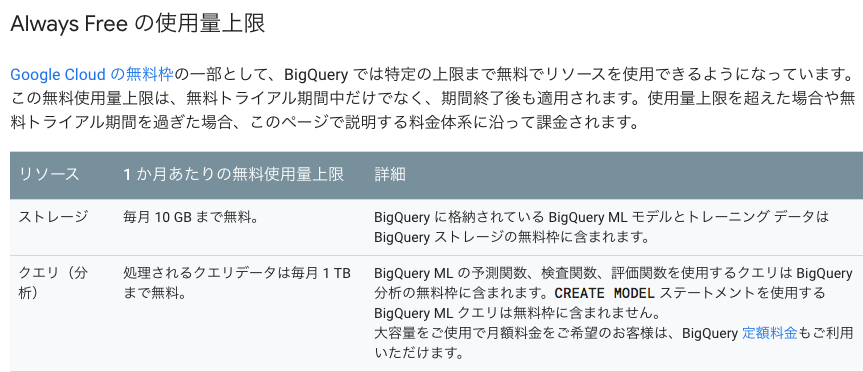
ちなみに今回の検証にかかった料金は0円です。下記の無料枠や初回登録クレジットを合わせるとある程度無料でBigQueryが楽しめます!!
BigQueryにおける分割テーブル, クラスタ化テーブルとは?
BigQueryではテーブルを作成する際に分割テーブル(公式ドキュメントの英語ではpartitioned table), クラスタ化テーブル(clustered table)を非常に簡単に設定できます。公式ドキュメントを参考に分割テーブルおよびクラスタ化テーブルについて簡単にまとめます。
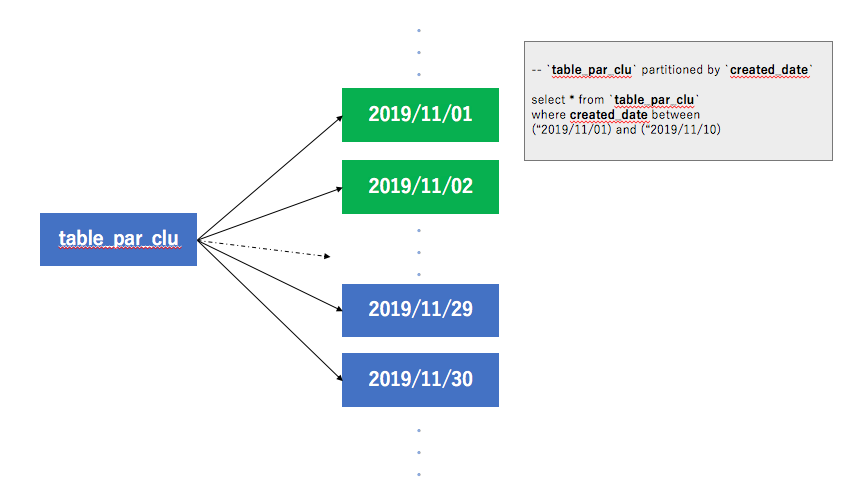
分割テーブル(partitioned table)
分割テーブルはパーティションと呼ばれるセグメントに分割された特殊なテーブルで,データの管理や照会をより簡単に行うことができます。大きいテーブルを小さいパーティションに分割することでクエリのパフォーマンスを向上させることができ,クエリで読み取られるバイト数を減らすことによってコストを管理できます。
公式ドキュメントから引用:https://cloud.google.com/bigquery/docs/partitioned-tables?hl=ja
分割テーブルを適用するだけでもクエリのパフォーマンス向上やコスト削減を実現できるようですね。分割テーブルを適用したテーブル作成も比較的容易に作成することができるのでやらない手はないですね。
クラスタ化テーブル(clustered table)
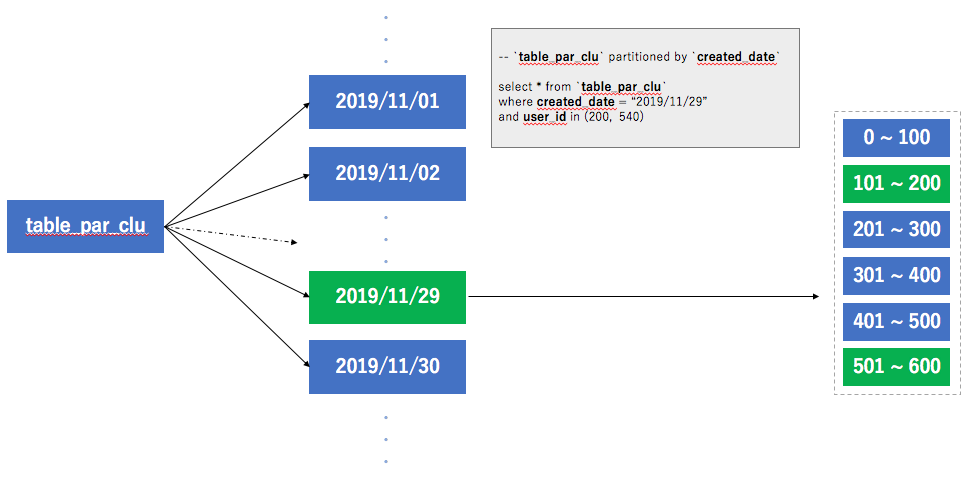
BigQuery でクラスタ化テーブルを作成すると,テーブルのスキーマ内の 1 つ以上の列の内容に基づいてテーブルのデータが自動的に編成されます。指定した列は,関連するデータを同じ場所に配置するために使用されます。複数の列を使用してテーブルをクラスタ化する場合は,指定する列の順序が重要です。指定した列の順序によって,データの並べ替え順序が決まります。クラスタリングは,フィルタ句を使用するクエリやデータを集計するクエリなど,特定のタイプのクエリのパフォーマンスを向上させることができます。
公式ドキュメントから引用:https://cloud.google.com/bigquery/docs/clustered-tables?hl=ja
指定したカラムでソートした状態でテーブルを構築してくれるのはいいですね,分割テーブルで指定した時系列カラム以外でも範囲指定した抽出が効率がよくなるだろうし,groupbyやdistinctにも影響してきそうです。
機能検証
では実際に上記の機能がどの程度性能に影響してくれるかを検証してみようと思います。
検証設定
データ
下記スクリプトを利用して検証テーブルを作成します。
吐き出したファイルをCloud Storageに格納し,BigQueryへロードします。
□ データ量:100MB(圧縮状態)
□ データ行:2,000,000行
import random
import math
import datetime
import sys
def zipf(max):
return math.e ** (random.random() * math.log(max + 1.0)) - 1.0
def nullgen(st, num):
if random.random() < num:
return ''
else:
return st
def generator(num,offset):
r = int(zipf(num)) + offset
txt = hashlib.sha512(str(r)).hexdigest()
txt = txt+txt+txt+txt+txt+txt+txt+txt
txt = txt[0:txt.find('a')+txt.find('b')+10]
return txt
def log_gen(num):
for i in range(0,num):
created_date = datetime.datetime.strftime(datetime.datetime.strptime('2019-11-'+str(random.randint(1,30))+' 00:00:00','%Y-%m-%d %H:%M:%S') + datetime.timedelta(seconds=random.random()*3600*24),'%Y-%m-%d %H:%M:%S')
user_id = str(int(zipf(6000000)))
col_001 = str(int(random.randint(10, 50)))
col_002 = str(random.randint(0,5))
col_003 = nullgen('http:',0.3)
col_004 = str(int(random.random()*253+1)) + '.' + str(int(random.random()*253+1)) + '.' + str(int(random.random()*253+1)) + '.' + str(int(random.random()*253+1))
record = [time_x,key_id,col_001,col_002,col_003,col_004]
print(','.join(record))
if __name__ == '__main__':
log_gen(2000000)
上記のスクリプトで生成されるデータはユーザーのアクション履歴を模しています。
- created_date:ユーザーのアクション時間およびレコード生成時間
- user_id:ユーザーid
- col_001:年齢
- col_002:特徴
- col_003:アクセスURL
- col_004:アクセス元IP
webサービスで生成されるよくあるレコードの簡易版と思っていただければと思います。
BigQuery
環境
- 2000 slot
- オンデマンド
- 東京リージョン
- キャッシュなし
□ Tips
通常のBigQueryを使用するとオンデマンドで上限2000slotの利用になります。
オンデマンドでの使用はslotなどの計算リソースが同一リージョンの他のユーザーと共有されている状態のため混み具合によっては速度に振れ幅があるようです。
参考:https://cloud.google.com/bigquery/pricing?hl=ja#flat_rate_pricing
テーブル
テーブルは下記2種類を用意しました。
| 分割テーブル | クラスタ化テーブル | |
|---|---|---|
| table_no | なし | なし |
| table_par_clu | あり | あり |
分割テーブルにはcreated_dateカラムを指定し,クラスタ化テーブルにはuser_idを指定しています
下記,各テーブルのプレビューになります。
table_par_cluは同様のcreated_dateで固まっているように見えますね。さらにuser_idも同様な値で固まっていそうなので分割されたテーブル内でも指定したカラムがソートされていることもわかります。
- table_no

- table_par_clu

それぞれに同一の検証クエリを投げて検証します。
検証項目
検証項目は下記の項目で実施します。
それぞれがテーブルオプションによってどの程度変化するのかを計測します。
□ 処理時間
□ slot消費
□ 処理量
□ シャッフル量
検証結果
A. ユニークユーザー数のカウント
distinctを使ったユーザー数のカウントクエリになります。
# standardSQL
select count(distinct user_id) as count from `qiita_test.table_no`;
| 1回目 | 2回目 | |
|---|---|---|
| table_no | 0.39sec | 0.35sec |
| table_par_clu | 0.7sec | 0.7sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 15.2MB | 16MB | 0.75 | 1.44MB |
| table_par_clu | 15.2MB | 16MB | 12 | 6.32MB |
B. 日付を絞ったユニークユーザー数のカウント
distinctを使ったユーザー数のカウントクエリにwhere句で日付を絞ります。
# standardSQL
select count(distinct user_id) as count from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24";
| 1回目 | 2回目 | |
|---|---|---|
| table_no | 0.9sec | 0.4sec |
| table_par_clu | 1.2sec | 0.8sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 30.5MB | 31MB | 1 | 945.8KB |
| table_par_clu | 10.2MB | 11MB | 1 | 945.8KB |
C. 特定のカラムでgroupbyを使用したcount
countやgroupbyなど分析でよく利用されるクエリとなっています。
# standardSQL
select col_001, count(distinct user_id) as count from `qiita_test.table_no` group by 1;
| | 1回目 | 2回目 |
|:--|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 0.8sec | 0.7sec |
| table_par_clu | 0.4sec | 1.0sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 30.5MB | 31MB | 1.1 | 13.4MB |
| table_par_clu | 30.5MB | 31MB | 20.4 | 24MB |
D. 日付を絞った特定のカラムでgroupbyを使用したcount
pattern_Cクエリを日付で絞ります。
# standardSQL
select col_001, count(distinct user_id) as count from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24" group by 1;
| | 1回目 | 2回目 |
|:--|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 0.8sec | 0.9sec |
| table_par_clu | 1.1sec | 1.0sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 45.7MB | 46MB | 0.9 | 5.61MB |
| table_par_clu | 15.2MB | 16MB | 12 | 8.02MB |
E. 別テーブルの特定のユーザーを用いた抽出
クラスタ化テーブルの影響を確かめるために特定のuser_idを利用したクエリを試してみます。
別のサービスのuser_idを模したservice_idとの紐付けテーブルを下記のように作成しました。

下記クエリでtable_henkanからサンプリングしたuser_idをtable_no,table_par_cluから抽出しようと思います。
# standardSQL
select * from `qiita_test.table_no` where user_id in ( select user_id from `qiita_test.table_henkan` where MOD(service_id, 100)<=50 )
| | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 4sec | 3.7sec |
| table_par_clu | 3.7sec | 3.3sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 100.1MB | 101MB | 1.1 | 10.7MB |
| table_par_clu | 100.1MB | 101MB | 5.7 | 10.7MB |
F. 日付を絞った別テーブルの特定のユーザーを用いた抽出
上記のクエリをさらに日付で絞ってみます。
# standardSQL
select * from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24" and user_id in ( select user_id from `qiita_test.table_henkan` where MOD(service_id, 100)<=50 )
| | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 1.8sec | 1.7sec |
| table_par_clu | 1.6sec | 1.7sec |
| 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 | |
|---|---|---|---|---|
| table_no | 100.1MB | 101MB | 0.6 | 3.6MB |
| table_par_clu | 33.7MB | 34MB | 2.1 | 3.6MB |
考察
分割テーブルおよびクラスタ化テーブルを適用したテーブルに対して検証結果からわかることは下記3点かと思います。
□ 日付を絞ることで課金されたバイト数が減少する
日付を絞った検証の課金されたバイト数を下図にまとめる。
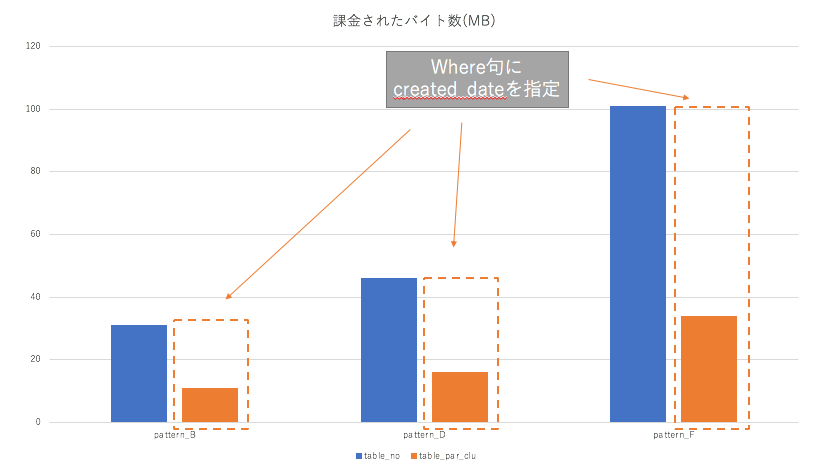
- 分割したテーブルから日付を絞った分のみ読み取りが行われている(1/3の読み取り量)
- 課金されたバイト数が減少していることからコスト管理しやすくなる
□ クラスタ化テーブルで指定したカラムで絞ったクエリはパフォーマンスが向上する
- 今回の検証ではデータ量が小さく差がわかりにくかったため,20GBのデータ量でpattern_E', pattern_E, pattern_Fを検証してみた
- 差分をわかりやすくするためcreated_dateのみで絞ったpattern_E'も計測する
# standardSQL
select * from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24"
| pattern_E' | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 14sec | 14sec |
| table_par_clu | 14sec | 13sec |
| pattern_E' | 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 |
|---|---|---|---|---|
| table_no | 19.4GB | 19.4GB | 60 | 13.1GB |
| table_par_clu | 6.5GB | 6.5GB | 71 | 12.9GB |
# standardSQL
select * from `qiita_test.table_no` where user_id in ( select user_id from `qiita_test.table_henkan` where MOD(service_id, 100)<=50 )
| pattern_E | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 18sec | 20sec |
| table_par_clu | 13sec | 14sec |
| pattern_E | 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 |
|---|---|---|---|---|
| table_no | 19.4GB | 19.4GB | 111 | 17.26 GB |
| table_par_clu | 19.4GB | 19.4GB | 157 | 16.7GB |
# standardSQL
select * from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24" and user_id in ( select user_id from `qiita_test.table_henkan` where MOD(service_id, 100)<=50 )
| pattern_F | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 35sec | 31sec |
| table_par_clu | 19sec | 16sec |
| pattern_F | 処理バイト数 | 課金バイト数 | 消費スロット数 | シャッフルバイト数 |
|---|---|---|---|---|
| table_no | 19.4GB | 19.4GB | 17 | 4.68 GB |
| table_par_clu | 6.4GB | 6.4GB | 29 | 4.13 GB |
上記それぞれの処理速度の結果を下図にまとめる。

- 追加検証の結果からクラスタ化テーブルで指定したカラムで絞るとパフォーマンスが向上する
- 今回は比較的均等にデータが生成されているが,実際のデータは偏りが大きかったりするためその点の影響も受けそうである
□ 分割テーブルおよびクラスタ化テーブルを適用したテーブルは多くのスロット数を消費する
検証結果それぞれの消費されたスロット数の結果を下図にまとめる。

- スロットはBigQueryの計算リソースであることから分割テーブルおよびクラスタ化テーブルを適用したテーブルには多くの計算リソースを消費する
→ オンデマンドでは上限が2000スロットのためデータ量の大きいテーブルに対してオプションを適用するとスロット数の上限に当たりやすくなり,コストを抑えられるが処理速度は落ちる可能性がある
おわりに
今回はBigQueryの分割テーブル,クラスタ化テーブルについて検証を実施しました。
結論としては,分割テーブルもクラスタ化テーブルどちらも意味がありました。(当然ですが(笑))
分割テーブルは日付で絞ると課金対象となる処理データ量が削減することがわかりました。テーブル作成時にUIでボタンをクリックするだけで設定可能なため,労力が少なくコスト管理を実現できるため有用そうです。
クラスタ化テーブルは指定カラムで絞ると処理性能の向上が期待できます。user_idなど頻繁に条件に指定するカラムを設定することや複数設定する時の順序など考慮すべきポイントはありますが,これも分割テーブル同様,労力が少なく処理性能の向上が実現できるため有用だと思います。
ただ,両方を適用するとスロットの消費は通常のテーブルに比べて多くなる傾向があるようです。スロットが上限に当たると性能面でのボトルネックになる可能性もあるので大きいデータを扱う時はflat rateも選択肢の1つかと思います。
やはりドキュメントに書かれているだけではピンとこない部分も実際に検証して数値で確認することで影響を実感できたのはよかったです。
BigQueryを利用している方々の役にたてれば幸いです。
以上でNTTドコモサービスイノベーション部AdventCalendar2019の12日目になります。
参考:検証結果
上記以外にもいくつか検証したのでのせておきます。
G. 特定のカラムのサンプリング
特定カラムに計算処理をして抽出する,こちらもよくクエリかと思います。
# standardSQL
select * from `bq_test.table_no` where MOD(user_id, 100)<=10;
| 単一性能 | 1回目 | 2回目 |
|:--|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 2.5sec | 2.5sec |
| table_par_clu | 2.1sec | 2.0sec |
| 単一性能 | 処理されたバイト数 | 課金されたバイト数 | 消費されたスロット | シャッフルされたバイト数 |
|---|---|---|---|---|
| table_no | 99.5MB | 100MB | 0.8 | 32.1MB |
| table_par_clu | 99.5MB | 100MB | 3 | 32.1MB |
H. 日付を絞った特定のカラムのサンプリング
# standardSQL
select * from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24" and MOD(user_id, 100)<=10 ;
| 単一性能 | 1回目 | 2回目 |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 1.4sec | 1.7sec |
| table_par_clu | 1.4sec | 1.5sec |
| 単一性能 | 処理されたバイト数 | 課金されたバイト数 | 消費されたスロット | シャッフルされたバイト数 |
|---|---|---|---|---|
| table_no | 99.5MB | 100MB | 0.8 | 10.7MB |
| table_par_clu | 33.4MB | 34MB | 1.5 | 10.7MB |
I. 分析で利用される関数の使用
timestamp_diff関数やlag関数など分析で利用される関数を使用したクエリです。上記2つに比べて計算量が多いクエリとして検証してみます。
# standardSQL
select time_diff, count(*) as cnt
from(
select
TIMESTAMP_DIFF(created_date, lag(created_date) over (partition by user_id order by created_date), SECOND) as time_diff
from `qiita_test.table_no`
) as tbl_a
group by 1;
| 単一性能 | 1回目 | 2回目 |
|:--|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 1.4sec | 1.6sec |
| table_par_clu | 1.3sec | 1.0sec |
| 単一性能 | 処理されたバイト数 | 課金されたバイト数 | 消費されたスロット | シャッフルされたバイト数 |
|---|---|---|---|---|
| table_no | 30.5MB | 31MB | 1.3 | 40.2MB |
| table_par_clu | 30.5MB | 31MB | 7.1 | 42.2MB |
J. 分析で利用される関数の使用
timestamp_diff関数やlag関数など分析で利用される関数を使用したクエリです。上記2つに比べて計算量が多いクエリとして検証してみます。
# standardSQL
select time_diff, count(*) as cnt
from(
select
TIMESTAMP_DIFF(created_date, lag(created_date) over (partition by user_id order by created_date), SECOND) as time_diff
from `qiita_test.table_no` where created_date between "2019-11-14" and "2019-11-24"
) as tbl_a
group by 1;
| 単一性能 | 1回目 | 2回目 |
|:--|:--:|:--:|:--:|:--:|:--:|:--:|
| table_no | 1.1sec | 1.2sec |
| table_par_clu | 2.1sec | 1.4sec |
| 単一性能 | 処理されたバイト数 | 課金されたバイト数 | 消費されたスロット | シャッフルされたバイト数 |
|---|---|---|---|---|
| table_no | 30.5MB | 31MB | 1 | 13.5MB |
| table_par_clu | 10.1MB | 11MB | 5 | 14MB |