これは MIERUNE Advent Calendar 2025 の9日目の記事です。
昨日は @Yfuruchin さんによる VHFテレメトリーデータの前処理と可視化 でした。
はじめに
先々週、FOSS4G SHINSHU 2025に行ってきた。
FOSS4G SHINSHU 2025の模様は👇👇👇
https://note.com/takamune555/n/nd70cb0dc106d?sub_rt=share_pw
そこで、石川県立大学 大丸教授による『オープンデータを活用した能登半島の災害リスク評価』というポスターがあった。
ポスター内容
- 概要
- 2024年能登半島地震において発生した、地形の原形を保ったまま移動する「並進型地すべり」や「スプレッド型地すべり」を対象とした解析事例
- 発災前後の航空レーザー測量データ(DEM)といったオープンデータを活用し、地表面の移動ベクトルを算出・可視化している
- 手法
- 従来、こうした地殻変動解析は高額な専用ソフトウェアやクローズドな環境で行われることが多く、一般への技術普及が課題となっていた
- OSSの画像処理ライブラリOpenCV(テンプレートマッチング機能)を用いることで、無償かつ再現性の高い解析フローを構築している
- 技術的アプローチ
- 2時期のDEMを陰影起伏画像(グレースケール)に変換
- 発災前の画像から切り出したテンプレート(50m四方など)が、発災後の画像のどこに移動したかを探索することで、地盤のズレ(変位ベクトル)を定量的に算出
所感として、国土地理院などが公開する広域的な電子基準点の成果とは別に、ローカルなPC環境で、しかもOSSだけで詳細な変動解析ができる点は非常に興味深い。また災害時の状況把握手段として、専門家だけでなく市民エンジニアレベルでも活用できる可能性を示した実践的な内容だった。
面白そうなので、2時期のDEMから変位ベクトルを算出するQGISプラグインを作ってみた。
使用データ
作成したプラグインの動作確認には、以下のDEMデータを使用している。
- 発災前:
- 令和6年能登半島地震(能登東部発災前DEM)【朝日航洋株式会社】
- https://www.geospatial.jp/ckan/dataset/aac-disaster-20240101-dem
- 発災後の図角「07GD2」に絞り込んで1枚のtifにマージ
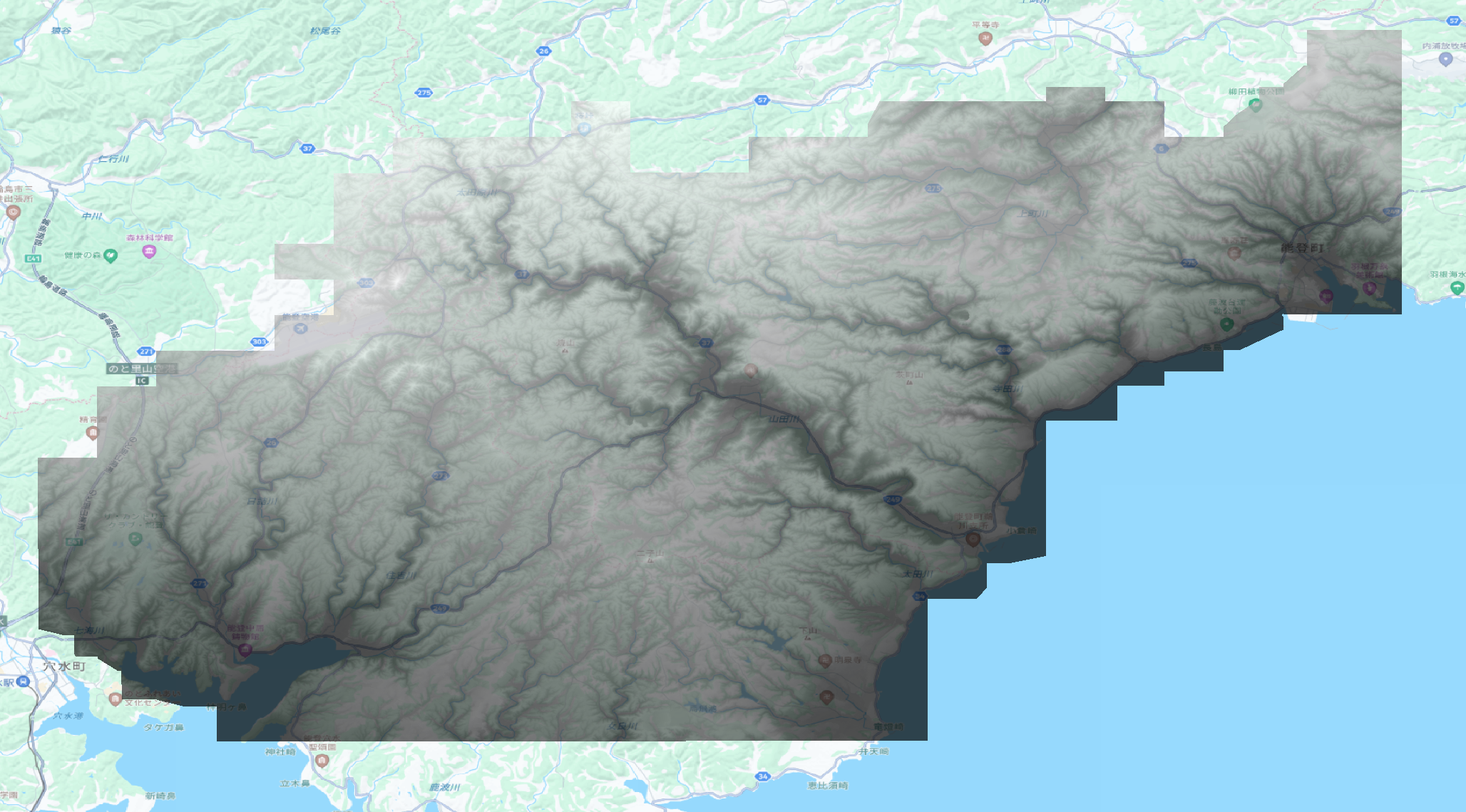
出典: HERE Technologies, 朝日航洋株式会社提供データを加工して作成
- 発災後:
- 林野庁・数値標高モデルDEM0.5m(能登地域2024)
- https://www.geospatial.jp/ckan/dataset/rinya-noto-portal/resource/319321e7-4521-4fd2-b531-be1eb29412b2
- 図角は「07GD2」
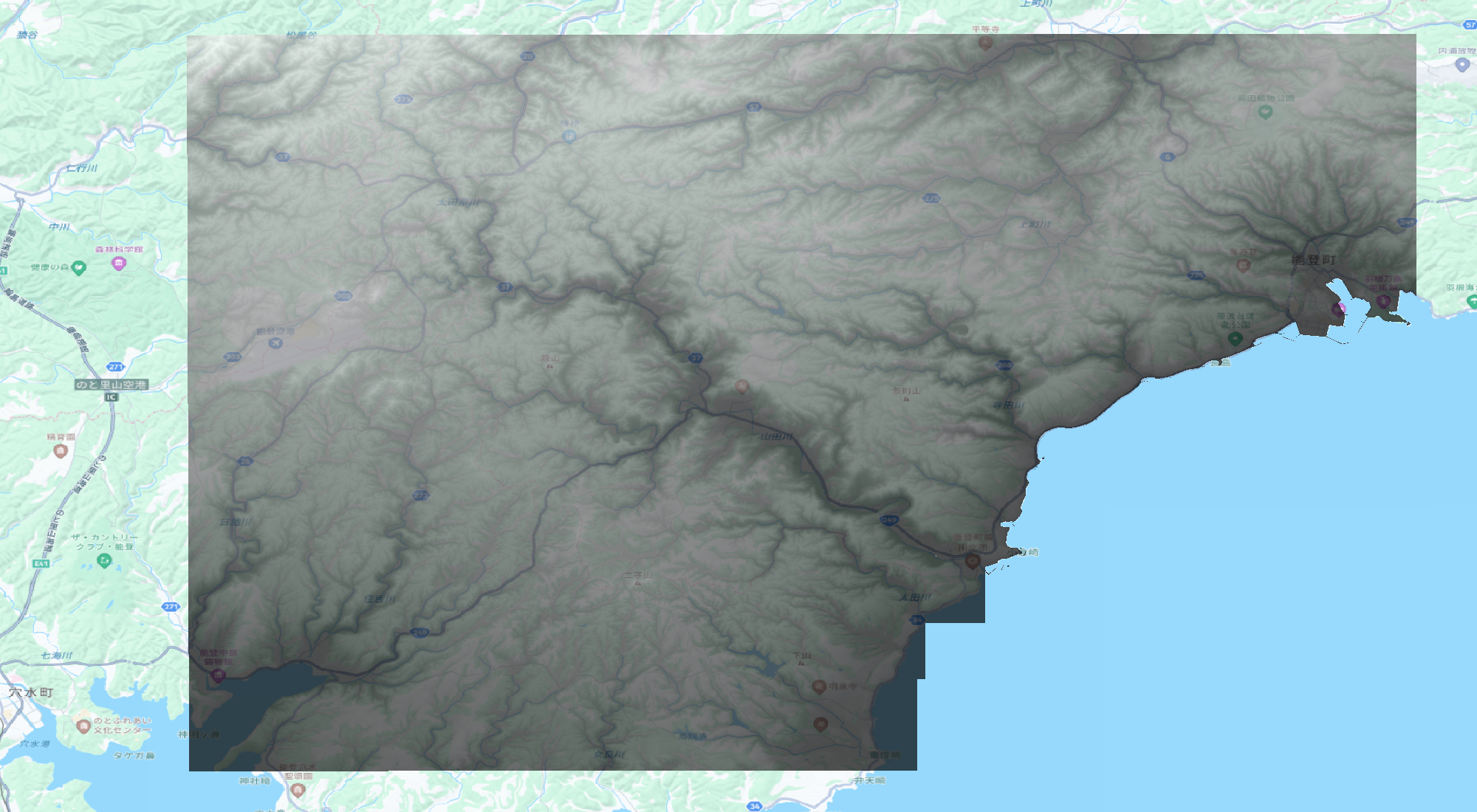
出典: HERE Technologies, 林野庁
ただし、広域であるため一部分を矩形で切り取り検証した。
BBOX([137.02061 37.28818][137.02915 37.30152])
-
発災前:
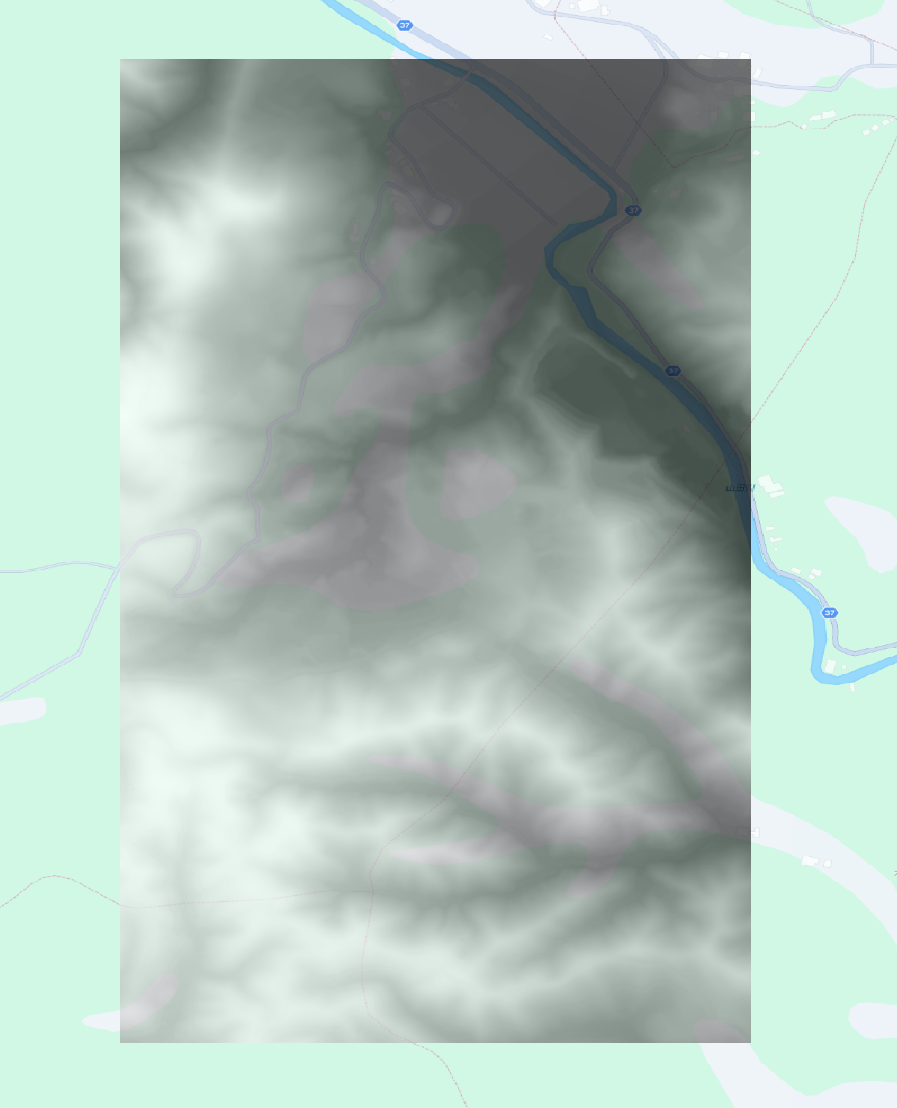
出典: HERE Technologies, 朝日航洋株式会社提供データを加工して作成 -
発災後:
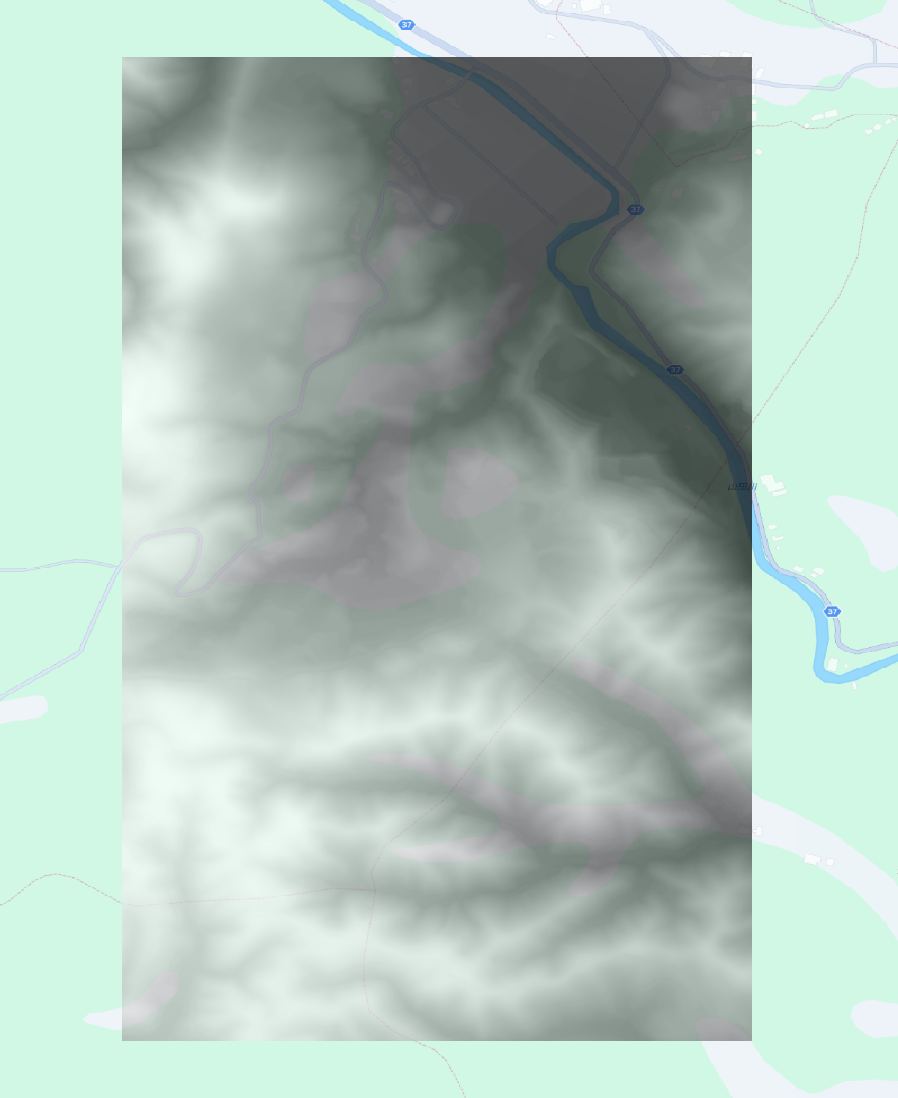
出典: HERE Technologies, 林野庁提供データを加工して作成
QGISプラグイン概要
流れ
Phase 1: パラメータ入力
↓
Phase 2: 前処理(リサンプリング・範囲統一・NoData除外)
↓
Phase 3: 画像強調(Sobelフィルタ・正規化)
↓
Phase 4: テンプレートマッチング(グリッド全体で変位計算)
↓
Phase 5: 後処理(フィルタリング・スムージング)
↓
Phase 6: ベクトル化(座標変換・属性計算)
↓
Phase 7: 出力(レイヤー作成・矢印スタイル適用)
フェーズと使用ライブラリ
| Phase | 処理内容 | 使用ライブラリ |
|---|---|---|
| 1 | パラメータ入力 | QGIS Processing |
| 2 | リサンプリング・範囲統一 | GDAL |
| 3 | Sobel フィルタ・正規化 | OpenCV |
| 4 | テンプレートマッチング | OpenCV |
| 5 | フィルタリング・スムージング | NumPy, SciPy |
| 6 | 座標変換・属性計算 | NumPy |
| 7 | レイヤー出力・スタイル適用 | QGIS Core |
パラメータと用語
- グリッド間隔(Grid Step)
- 変位ベクトルを計算するグリッドポイントの間隔(ピクセル単位)
- 小さければ密な解析、大きければ荒い解析
- 詳細な解析を行う場合は処理時間が増加
- テンプレートサイズ(Template Size)
- 変位前DEM(以下、Before DEM)から切り出すテンプレート(画像)の大きさ(ピクセル単位)
- 小さければ局所的な変異を検出しやすく、大きければ広範囲の地形特徴を捉えやすい
- ただし小さくした場合、地形の特徴がない領域ではマッチング精度が落ちる
- 探索範囲(Search Window Size)
- 変位後DEM(以下、After DEM)でテンプレートを探索する範囲の半径(ピクセル単位)
- どこまで地形が変位したかの範囲の絞り込みを行う
- 小さいほど高速になるが、大きな変位を検知できない場合がある
- スコア閾値(Score Threshold)
- マッチングスコアの最低値(0.0〜1.0)
- この値未満のマッチング結果は除外される
- 最大変位距離(Max Distance)
- 許容する最大変位距離(メートル単位)
- これを超える変位はノイズとして除外される
- ピクセルサイズ(Pixel Size)
- DEMの解像度を統一する際のピクセルサイズ(メートル単位)
- 0または未指定: Before DEMの元の解像度を使用
- 明示的に指定すると、両DEMを指定した解像度にリサンプリングし、解像度が異なるDEMを比較する場合や、処理速度を優先する場合に有効となる
- スムージングカーネルサイズ
- メディアンフィルタで近傍点を探索する範囲の半径(ピクセル単位)
- 小さくすると局所的な平滑化ができ、急激な変化を保持できる
実装詳細
Phase 2: 前処理(リサンプリング・範囲統一・NoData除外)
目的
2つのDEMは解像度や範囲が異なる場合があるため、テンプレートマッチングを行う前に以下を統一する必要がある。
- 解像度の統一: ピクセルサイズを揃える(デフォルトはBefore DEMの解像度)
- 範囲の統一: 重複範囲を計算する
- NoData領域の除外: 両DEMで有効なデータがある範囲のみを切り出す
流れ
- GDALでラスターを開く:
gdal.Open()で2つのDEMを読み込み - 地理的範囲を取得: GeoTransformから各DEMのbounding boxを計算
- 共通範囲を計算: 2つのbounding boxの交差部分(Intersection)を算出
- リサンプリング:
gdal.Warp()で共通範囲・同一解像度に変換 - NoData値をNaNに変換:
np.nanとして扱うことで、後続フェーズでの処理を統一 - 有効データ領域を抽出: NaN以外のピクセルが存在する最小矩形を計算
- 最終的な配列を切り出し: 両DEMで有効なデータがある領域のみを返す
def preprocess_rasters(raster1_path, raster2_path, pixel_size=None):
"""2つのラスターを前処理"""
# GDALでラスターを開く
ds1 = gdal.Open(raster1_path)
ds2 = gdal.Open(raster2_path)
# 地理的範囲を取得
extent1 = _get_extent(ds1)
extent2 = _get_extent(ds2)
# 共通範囲を計算
intersection = get_intersection_extent(extent1, extent2)
# 両方のラスターを同じサイズでリサンプリング
array1 = resample_raster_to_array(raster1_path, intersection, pixel_size)
array2 = resample_raster_to_array(raster2_path, intersection, pixel_size)
# NoDataを考慮した有効データ領域を計算
valid_extent1 = get_valid_data_extent(array1, initial_transform)
valid_extent2 = get_valid_data_extent(array2, initial_transform)
valid_intersection = get_intersection_extent(valid_extent1, valid_extent2)
# 有効データ領域に配列を切り出し
array1, transform = crop_array_to_extent(array1, initial_transform, valid_intersection)
array2, _ = crop_array_to_extent(array2, initial_transform, valid_intersection)
return array1, array2, transform
リサンプリングはgdal.Warp() で指定した範囲・解像度にバイリニア補間している。
処理結果
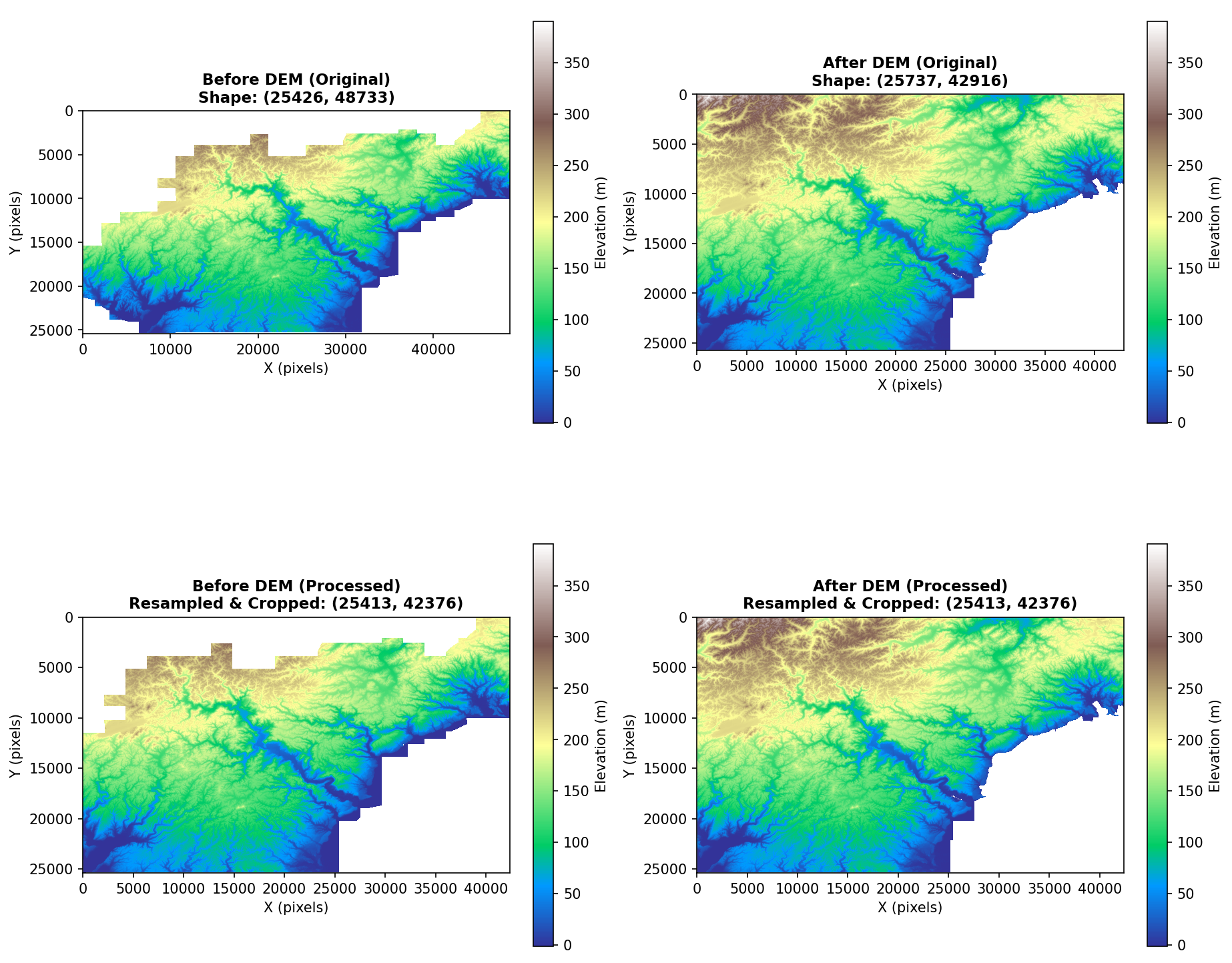
共通するBBOXにクロップし、同じ解像度(配列長)にリサンプリングされている。
Phase 3: 画像強調(Sobelフィルタ・正規化)
目的
DEMの標高値そのままでは絶対標高の違いがマッチングの精度に影響してしまう。Sobelフィルタで地形の勾配・形状を抽出して正規化することで、標高値に依存しない特徴量を得る。
Sobel(ソーベル)フィルタについてはこちら
流れ
- NaN領域のマスクを保存:
np.isnan()でNoData領域を記憶 - NaNを0に置き換え: Sobelフィルタ適用のため一時的に埋める
- Sobelフィルタ適用: X方向・Y方向の勾配を計算し、勾配の大きさを算出
- 元のNaN領域を復元: マスクを使ってNoData領域を
np.nanに戻す - 2つの配列を正規化: グローバルmin/maxで0-255にスケーリング(float32型でNaNを保持)
Sobelフィルタ
def apply_sobel_filter(array):
"""Sobelフィルタを適用して地形の勾配を抽出"""
nan_mask = np.isnan(array)
array_filled = np.nan_to_num(array, nan=0.0)
# Sobelフィルタ (X方向・Y方向の勾配)
sobel_x = cv2.Sobel(array_filled, cv2.CV_32F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(array_filled, cv2.CV_32F, 0, 1, ksize=3)
# 勾配の大きさ
magnitude = np.sqrt(sobel_x**2 + sobel_y**2)
# NaN領域を復元
magnitude[nan_mask] = np.nan
return magnitude
正規化
2つの配列から最大値最小値を取得し、両方を0-255の範囲に正規化する。またuint8型ではなくfloat32型で保持することで、NaN領域を維持する。
(uint8型はNaNを表現できない)
処理結果
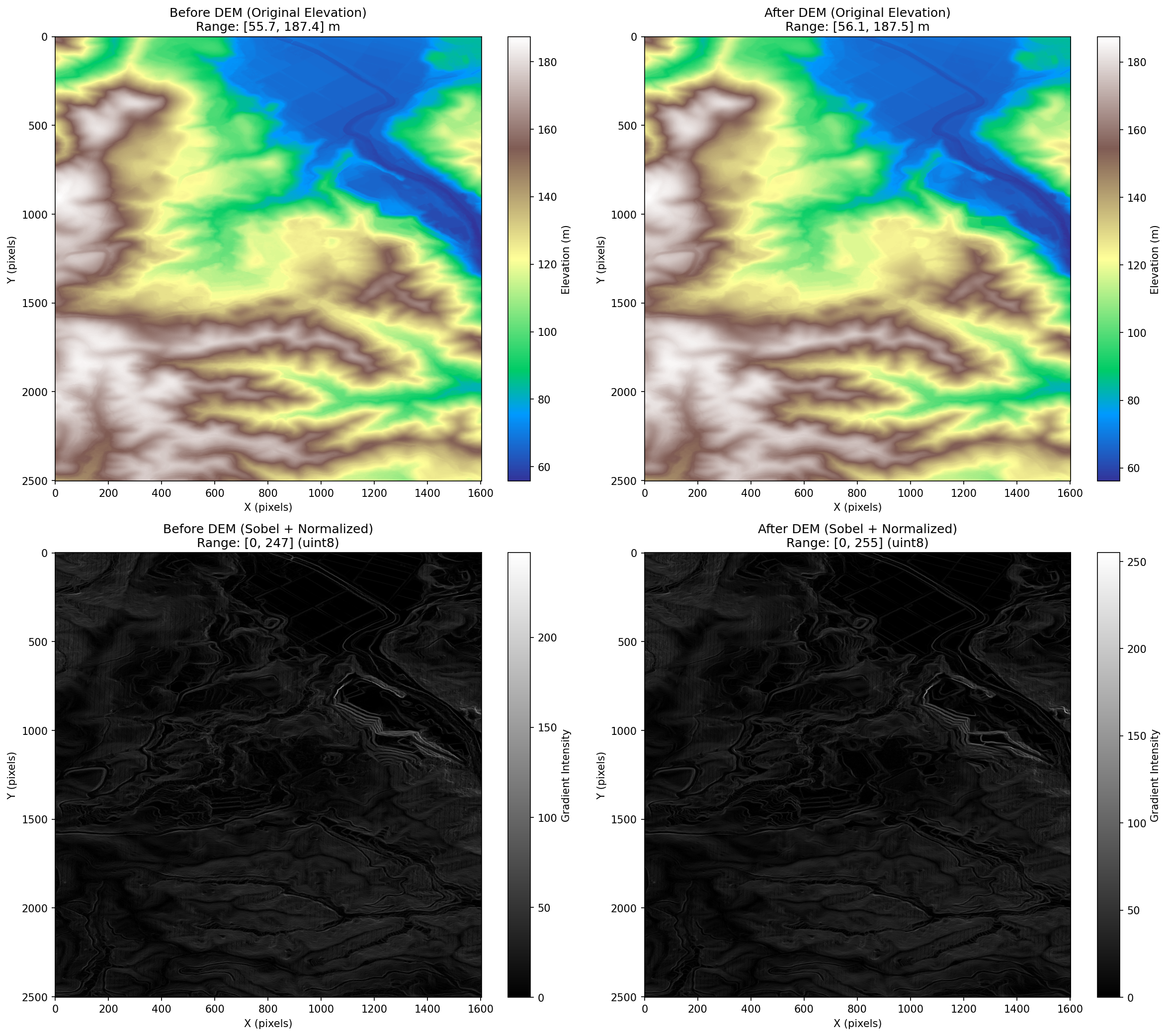
沢・尾根といった地形の特徴が強調されていることがわかる。
Phase 4: テンプレートマッチング
目的
このプラグインの確認部分となる。変位前DEMから切り出したテンプレートが、変位後DEMのどこに移動したかを検索し、変位ベクトルとマッチングスコアを計算する。
テンプレートマッチングとは
テンプレートマッチングは、画像処理におけるパターン認識手法のこと。小さな画像(テンプレート)を大きな画像の中から探索し、最も類似する位置を特定する。
このプラグインでは、指定したBefore DEMから切り出した地形テンプレートを、After DEMの対応する周辺領域(テンプレート位置)から、正規化相関係数法で探索を行い、最も近似する位置座標とスコアを取得する。
参考: https://qiita.com/pachi-dragon/items/394b26b1621de92bfd98
流れ
- グリッドポイントを生成: 画像全体を一定間隔(step)でサンプリング
- 各グリッドポイントでテンプレート抽出: Before DEMから指定サイズ(64×64pxなど)を切り出し
- 探索領域を抽出: After DEMから探索範囲を含む大きめの領域を切り出し
- テンプレートマッチング: OpenCVの
cv2.matchTemplate()で最も類似する位置を探索 - 変位ベクトル計算: マッチ位置と元の位置の差分から変位量を算出
- スコア計算: 正規化相関係数(TM_CCOEFF_NORMED)を0-1の範囲に変換
def match_template(template, search_area):
"""テンプレートマッチングを実行"""
# OpenCV TM_CCOEFF_NORMED(正規化相関係数法: -1.0 ~ 1.0)
result = cv2.matchTemplate(search_area, template, cv2.TM_CCOEFF_NORMED)
# 最大値の位置 = 最もマッチした位置
_, max_val, _, max_loc = cv2.minMaxLoc(result)
# 変位ベクトルを計算(探索領域中心からのオフセット)
dx = (max_loc[0] + template_half_x) - search_center_x
dy = (max_loc[1] + template_half_y) - search_center_y
# スコアを0-1に正規化
score = (max_val + 1.0) / 2.0
return dx, dy, score
search_areaはあらかじめクリップしておく
NoData・フラット領域の除外
テンプレート抽出時に以下の条件でスキップする
- NaNを含む場合:
np.isnan(template).any()がTrueならスキップ - フラット領域(最大値=最小値): 特徴量がないためマッチング不可能
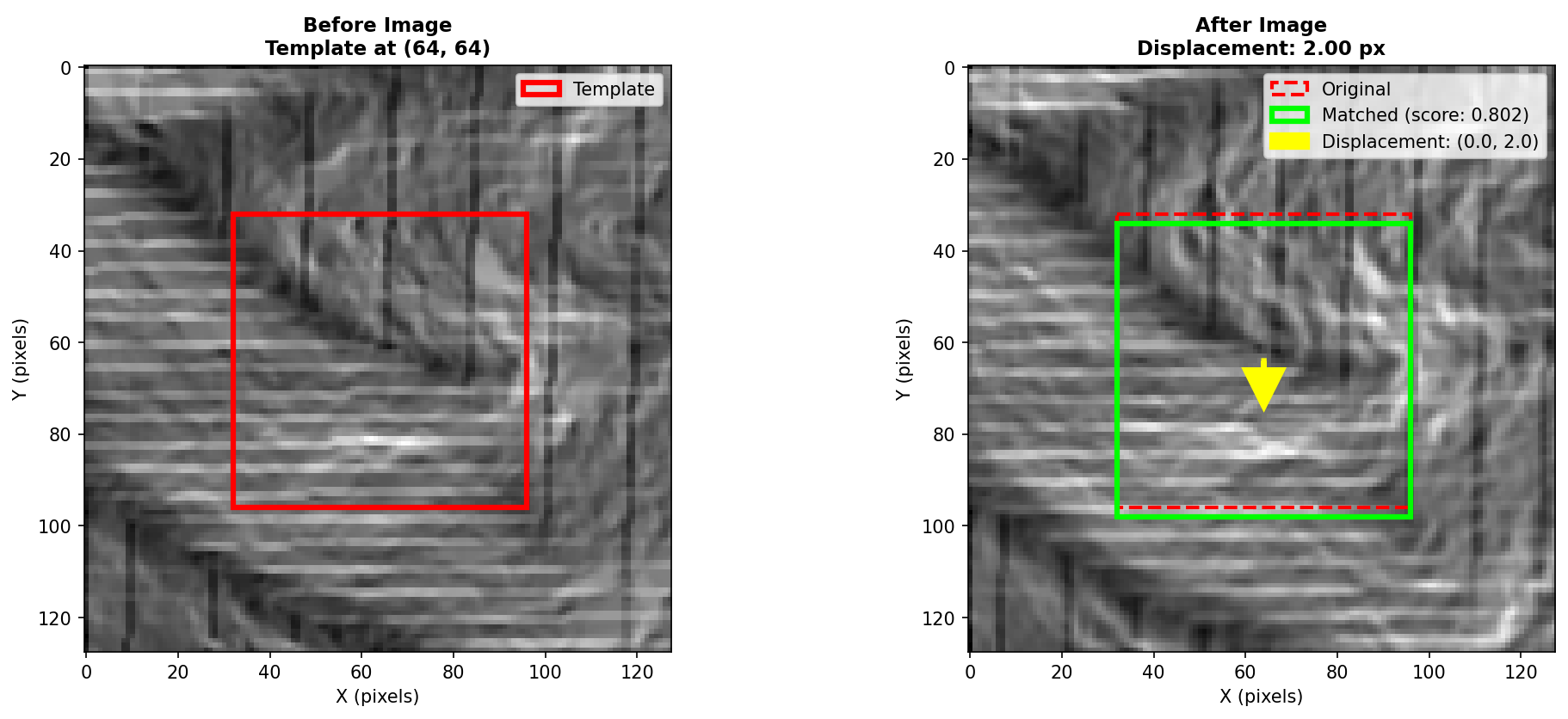
ごく僅かに下に動いていることがわかる。
Phase 5: フィルタリング・スムージング
目的
テンプレートマッチングの結果からノイズを除去し、信頼性の高い変位ベクトルのみを残す。
流れ
- スコアフィルタリング: マッチングスコアが閾値(例: 0.5)以上の点のみを残す
- 距離フィルタリング: 変位距離が最大値(例: 100px)以下の点のみを残す
- メディアンフィルタ: KDTreeで近傍点を高速検索し、メディアン値でスムージング
スコアフィルタリング
filtered = [
(p, d, s) for p, d, s in zip(grid_points, displacements, scores)
if s >= threshold
]
地形の特徴が少ない領域など、マッチングスコアが低い点を除外する。
距離フィルタリング
filtered = [
(p, d, s) for p, d, s in zip(grid_points, displacements, scores)
if np.sqrt(d[0]**2 + d[1]**2) <= max_distance
]
異常に大きな変位を除外する。
メディアンフィルタによるスムージング
KDTree(k次元木構造)を使用し、各点の近傍点を検索し、カーネルサイズ以内の近傍点の変位ベクトルから中央値を計算し、外れ値の影響を抑える。
tree = KDTree(points_array) # 一度だけ構築
for i, point in enumerate(points):
neighbor_indices = tree.query_ball_point(point, kernel_size)
neighbor_disps = displacements_array[neighbor_indices]
# 中央値を計算
median_dx = np.median(neighbor_disps[:, 0])
median_dy = np.median(neighbor_disps[:, 1])
smoothed.append((median_dx, median_dy))
処理結果
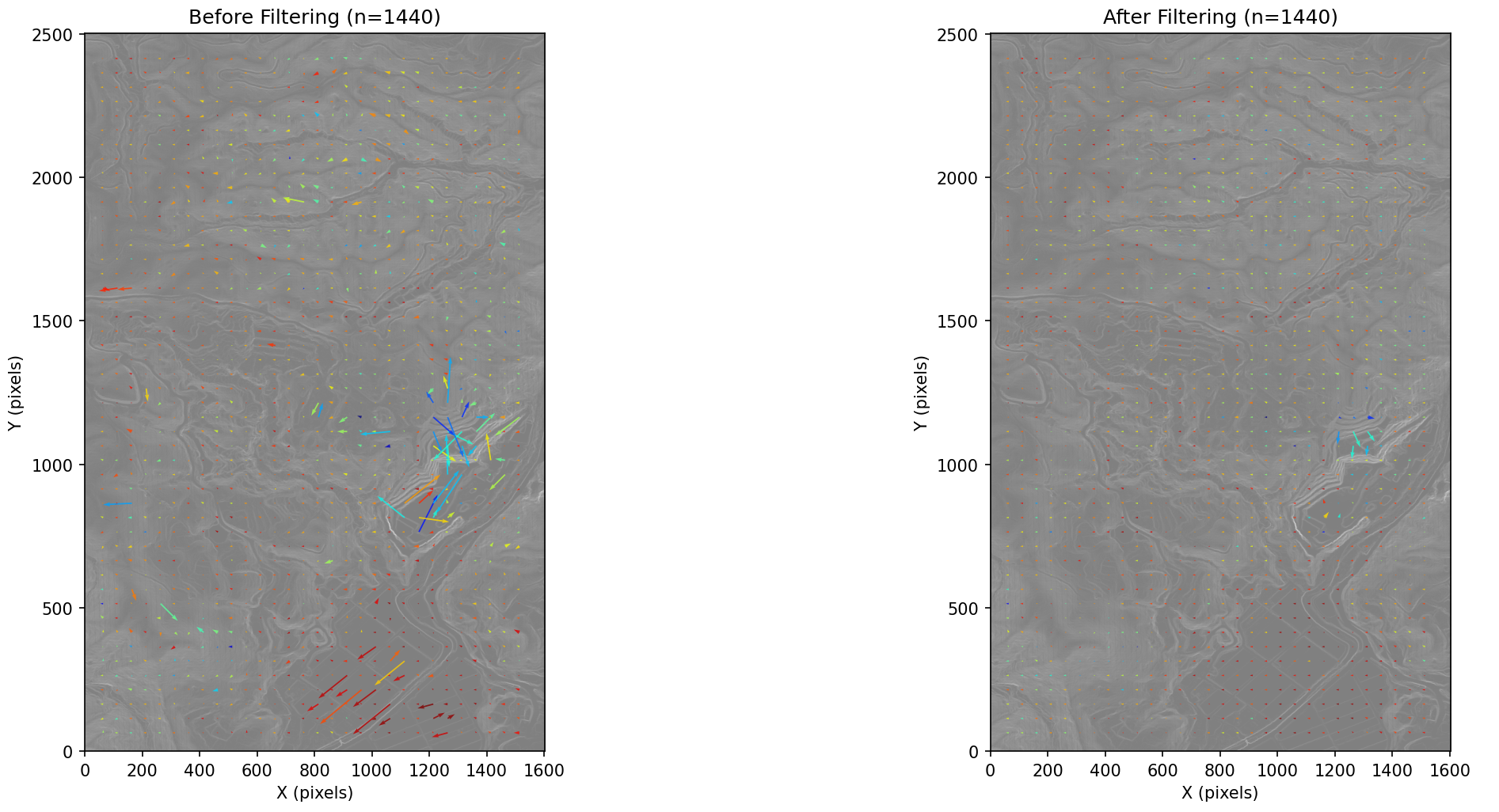
Phase 6: ベクトル化(座標変換・属性計算)
ピクセル座標系の変位ベクトルを地理座標系に変換するだけ。あと使用する属性値を格納する。
- ピクセル座標 → 地理座標:
geo_x = origin_x + px * pixel_size - 変位量(ピクセル → メートル):
shift_x_m = dx * pixel_size - 変位距離:
distance = sqrt(shift_x_m² + shift_y_m²) - 変位角度:
angle = arctan2(shift_y_m, shift_x_m) * 180 / π(0度=東、90度=北)
出力属性
| 属性名 | 説明 | 単位 |
|---|---|---|
| shift_x | X方向の変位量 | メートル |
| shift_y | Y方向の変位量 | メートル |
| distance | 変位距離 | メートル |
| angle | 変位角度(0度=東、90度=北) | 度 |
| score | マッチングスコア(信頼度) | 0.0-1.0 |
Phase 7: 出力(レイヤー作成・矢印スタイル適用)
あとはレイヤー出力して、変位ベクトルを始点/終点を繋げる線分(矢印)で書き、distancecで色分けしてあげると良い。

出典: HERE Technologies, 朝日航洋株式会社提供データを加工して作成, 林野庁提供データを加工して作成
当該箇所
-
発災前

出典: HERE Technologies, 朝日航洋株式会社提供データを加工して作成 -
発災後

出典: HERE Technologies, 林野庁提供データを加工して作成
地理院が公開している能登半島輪島中地区の斜面崩壊・堆積分布データ及び斜面崩壊・堆積分布図と比較すると、確かに崩壊している箇所に差分が出ていることがわかる。
ただし、すべての斜面崩壊が並進型地すべりではない上に同時に地殻変動のケースもあるため、全てが検出されるわけではない。
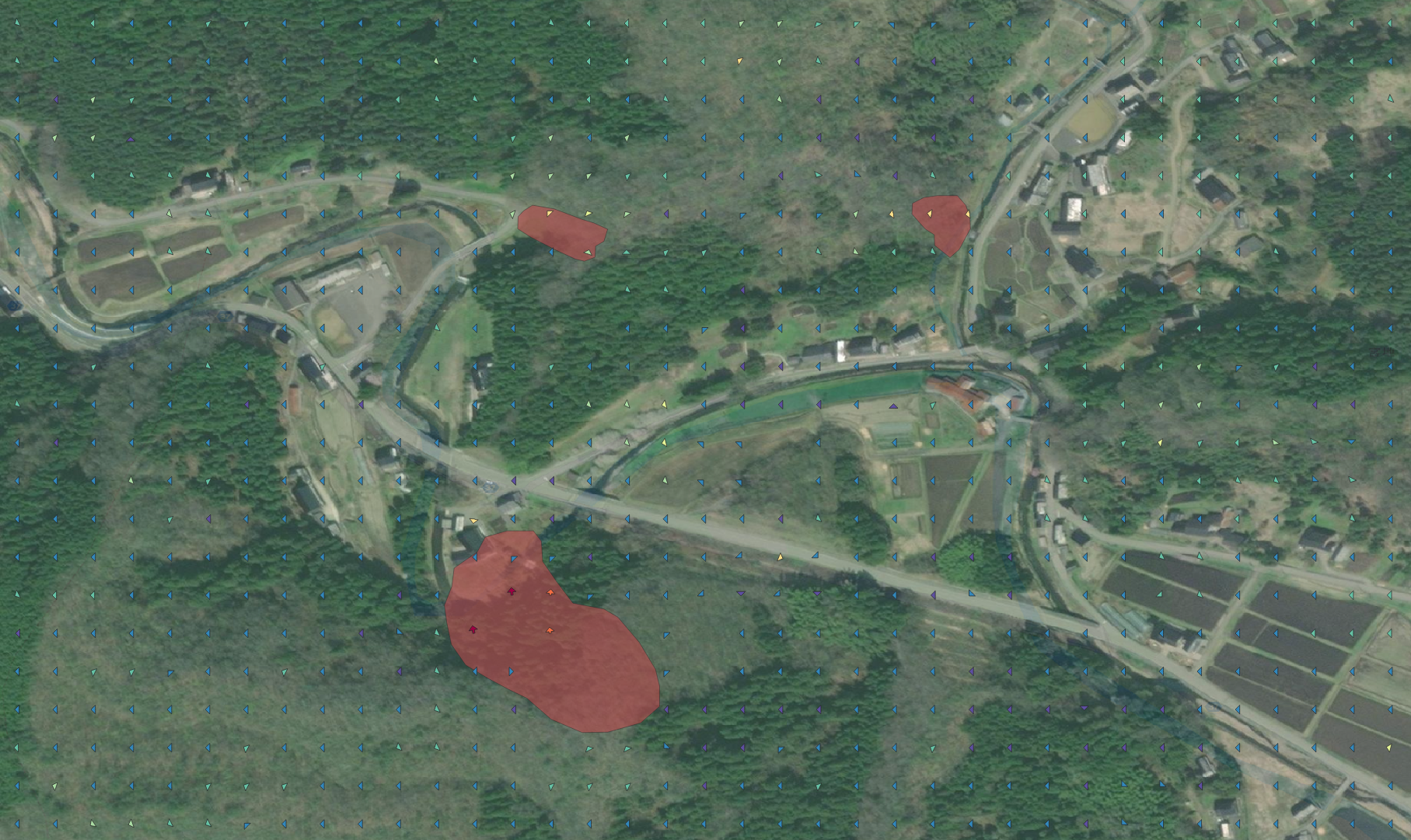
出典: HERE Technologies, tomtom, 国土地理院
作成したプラグイン
最新のリリースから『terrashift.zip』で使えるようになる。
-> ライブラリ/QGISのバージョンによりインストールできない可能性があり、調査中です。
今後としてDEMから土量を算出し3次元的な解析をできると面白い。
関連特許について
本プラグインで採用している「多時期のDEMを画像化し、テンプレートマッチングにより地形変化を検出する手法」に関連して、国際航業株式会社による以下の特許が存在します。
特許名: 地形画像を用いた地形変化の解析方法及びそのプログラム
出願番号: 特願2009-120428
公開番号: 特開2010-266419
出願日: 2009年5月18日
特許権者: 国際航業株式会社
参考: https://jglobal.jst.go.jp/detail?JGLOBAL_ID=201003048172036189
この特許の請求項は「点群データからDEMを作成し、メッシュごとに地形量を演算して画像を作成し、画像同士を照合することで地形変化を判断する」というものです。本プラグインは既存のDEMを入力とし、テンプレートマッチングで変位ベクトルを算出するという手法であるため、必ずしも該当するとは限りません。
商用・業務目的で利用を検討される場合は、特許権者への確認や専門家への相談を推奨します。