初版:
Ver1.1:次の解説を追記→OpenCVカスケード型分類器、データーの水増しについて、CNNについて、過学習について、予測結果について

オス猫の「ソラ」とメスネコの「ミミ」2匹の猫を飼っているのですが、
「ソラ」の食欲が旺盛でミミ」の余った餌を食べてしまい、日に日に巨大化して困っています
ずっとつきっきりではいられないので
どちらがどれだけ餌を食べたかを把握するために
将来的にラズベリーパイとカメラを活用して動画で2匹の猫を判別させて、
それぞれの猫がどのくらいの餌を食べているかを記録するシステムをつくりたいと思っています
まずは前段として、オリジナルの猫の画像により、ディープラーニングのライブラリのTensorflow(Keras)を使用して
深層学習で「ソラ」と「ミミ」の判別させてみたと思います
作成にあたり、こちらのサイトを参考にさせていだきました
ありがとうございました
目次
1-実行環境
実行環境はColaboratory(Colab)を利用しました。
2-実装
最初にolaboratory上に猫の画像をアップし、
Googleドライブをpythonで使用できるようにします。
from google.colab import drive
drive.mount('/content/drive')
次に今回使用するモジュールをインポートします。
import matplotlib.pyplot as plt
import os
import cv2
from google.colab.patches import cv2_imshow
import glob
import re
import random
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D, BatchNormalization
import copy
from IPython import display
from sklearn.model_selection import train_test_split
2-1データの作成
まず我が家の猫の写真を下記のディレクトリに12枚ずつ保存
/content/drive/MyDrive/cat_picture/org/sora
/content/drive/MyDrive/cat_picture/org/mimi
猫の顔を認識してくれるOpenCVのカスケード型分類器を使用して
元の画像より猫の顔を切り出しました
※OpenCVのカスケード型分類器とはOpenCV が提供している画像の中から特定のものを検出する機能を持つ
XMLファイルです。
その中で、「猫の正面の顔」を検出してくれる「haarcascade_frontalcatface.xml」を今回使用します
猫がなかなかじっとしてくれないので、うまく顔認識できる写真を撮って集めるのに苦労しました
#ソラ用写真リサイズ
#カスケード型分類器に使用する分類器のデータ(xmlファイル)を読み込み
HAAR_FILE = "/content/drive/MyDrive/haarcascade/haarcascade_frontalcatface.xml"
cascade = cv2.CascadeClassifier(HAAR_FILE)
num=0
#ファイルリストの取得
#並び替え"
def atoi(text):
return int(text) if text.isdigit() else text
def natural_keys(text):
return [ atoi(c) for c in re.split(r'(\d+)', text) ]
files = sorted(glob.glob("/content/drive/MyDrive/cat_picture/org/sora/*.jpg"), key=natural_keys)
print(files)
for file in files:
num=num+1
#取得したファイル名の表示
print(file)
#画像ファイルの読み込み
img = cv2.imread(file)
#cv2_imshow(img)
#グレースケールに変換
img2 = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
#img2 = cv2.cvtColor(img,cv2.COLOR_RGB2BGR)
#cv2_imshow(img2)
#カスケード型分類器を使用して画像ファイルから顔部分を検出する
#face = cascade.detectMultiScale(img2,scaleFactor=1.07,minNeighbors=7,minSize=(100,100))
face = cascade.detectMultiScale(img2,minSize=(50,50))
#cv2_imshow(face)
#print(face)
#print(face.shape)
#顔部分を切り取り、リサイズする。
for x,y,w,h in face:
# 検出した顔部分を切り出す
#for(x, y, w, h) in face:
face_cut = img2[y:y+h,x:x+w] # 範囲
#横幅のエリアを1.6倍にし、縦幅のエリアを2.23倍にすることで、4:3の比率でカット
#face_cut = img2[y-int(h*0.6):y+int(h*1.53), x-int(w*0.3):x+int(w*1.3)]
#print(face_cut)
#cv2_imshow(face_cut)
#カットした画像を450*600のサイズにする。
#print(face_cut.shape)
resize_img = cv2.resize(face_cut , dsize=(450, 600))
#resize_img = cv2.resize(face_cut , dsize=(100, 200))
cv2_imshow(resize_img)
#画像の出力
wright_file="/content/drive/MyDrive/cat_picture/resize/sora/sora"+ str(num) + ".jpg"
print(wright_file)
cv2.imwrite(wright_file,resize_img)
出力結果(抜粋)です
こんな感じで切り取ってくれました


ミミも同様に(コード略)顔を切り出します


次に写真を水増ししていきます
1枚の写真につき48枚、合計576枚を用意しました
※画像認識では、画像データとそのラベル(教師データ)の組み合わせが大量に必要となりますが、
十分な数の画像とラベルの組み合わせを用意する事は、結構大変です(猫の場合は特に)
そこで、データの個数を十分量に増やすために画像の水増しをしてあげます
画像の水増しといっても、ただ単にデータをコピーして量を増やすだけでは意味がないため、
・焦点をずらす
・コントラスト変化させる
・ノイズを付与する
・輝度変化させる
等を行い、データーを増やしています
#ソラ用データー水増し
#画像変換条件
filter1 = np.array([[0, 1, 0],
[1, 0, 1],
[0, 1, 0]], np.uint8)
filter2 = np.ones((3, 3))
list_resize = [2, 3, 5, 7]
list_mosaic = [3, 5, 7, 10]
list_rotation = [45, 135, 225, 315]
list_flip = [0, 1, -1]
list_cvt1 = [0]
list_cvt2 = [0]
list_THRESH_BINARY = [50, 100, 150, 200]
list_THRESH_BINARY_INV = [50, 100, 150, 200]
list_THRESH_TRUNC = [50, 100, 150, 200]
list_THRESH_TOZERO = [50, 100, 150, 200]
list_THRESH_TOZERO_INV = [50, 100, 150, 200]
list_gauss = [11, 31, 51, 71]
list_gray = [0]
list_nois_gray = [0]
list_nois_color = [0]
list_dilate = [filter1, filter2]
list_erode = [filter1, filter2]
parameters = [list_resize, list_mosaic, list_rotation, list_flip, list_cvt1, list_cvt2, list_THRESH_BINARY, \
list_THRESH_BINARY_INV, list_THRESH_TRUNC, list_THRESH_TOZERO, list_THRESH_TOZERO_INV, list_gauss, \
list_gray, list_nois_gray, list_nois_color, list_dilate, list_erode]
#水増し画像の合計
list_sum =len(list_resize) + len(list_mosaic) + len(list_rotation) + len(list_flip) + len(list_cvt1) + len(list_cvt2) + \
len(list_THRESH_BINARY) + len(list_THRESH_BINARY_INV) + len(list_THRESH_TRUNC) + len(list_THRESH_TOZERO) + \
len(list_THRESH_TOZERO_INV) + len(list_gauss) + len(list_gray) + len(list_nois_gray) + len(list_nois_color) + \
len(list_dilate) + len(list_erode)
print("合計:{}枚".format(list_sum))
#実行する関数のリスト
methods = np.array([lambda i: cv2.resize(img, (img.shape[1] // i, img.shape[0] // i)),
lambda i: cv2.resize(cv2.resize(img, (img.shape[1] // i, img.shape[0] // i)), (img.shape[1],img.shape[0])),
lambda i: cv2.warpAffine(img, cv2.getRotationMatrix2D(tuple(np.array([img.shape[1] / 2, img.shape[0] /2])), i, 1), (img.shape[1], img.shape[0])),
lambda i: cv2.flip(img, i),
lambda i: cv2.cvtColor(img, cv2.COLOR_BGR2LAB),
lambda i: cv2.bitwise_not(img),
lambda i: cv2.threshold(img, i, 255, cv2.THRESH_BINARY)[1],
lambda i: cv2.threshold(img, i, 255, cv2.THRESH_BINARY_INV)[1],
lambda i: cv2.threshold(img, i, 255, cv2.THRESH_TRUNC)[1],
lambda i: cv2.threshold(img, i, 255, cv2.THRESH_TOZERO)[1],
lambda i: cv2.threshold(img, i, 255, cv2.THRESH_TOZERO_INV)[1],
lambda i: cv2.GaussianBlur(img, (i, i), 0),
#lambda i: cv2.imread("/content/drive/MyDrive/cat_picture/resize/cat1.jpg", i),
lambda i: cv2.imread(file, i),
#lambda i: cv2.fastNlMeansDenoising(cv2.imread("/content/drive/MyDrive/cat_picture/resize/cat1.jpg", i)),
lambda i: cv2.fastNlMeansDenoising(cv2.imread(file, i)),
lambda i: cv2.fastNlMeansDenoisingColored(img),
lambda i: cv2.dilate(img, i),
lambda i: cv2.erode(img, i)
])
#水増し画僧の保存用関数
def save(cnv_img):
cv2.imwrite("/content/drive/MyDrive/cat_picture/data/sora/sora_data" + str(num) + ".jpg", cnv_img)
#画像タイトル用ナンバーの初期化
num = 0
#並び替え"
def atoi(text):
return int(text) if text.isdigit() else text
def natural_keys(text):
return [ atoi(c) for c in re.split(r'(\d+)', text) ]
#元画像の読み込み
files = sorted(glob.glob("/content/drive/MyDrive/cat_picture/resize/sora/*.jpg"), key=natural_keys)
print(files)
for file in files:
#num=num+1
#取得したファイル名の表示
print(file)
#画像ファイルの読み込み
img = cv2.imread(file)
#img = cv2.imread("/content/drive/MyDrive/cat_picture/resize/cat1.jpg")
#cv2_imshow(img)
#画像の水増しと保存
for ind, method in enumerate(methods):
for parameter in parameters[ind]:
num += 1
cnv_img = method(parameter)
save(cnv_img)
ミミも同様に水増しをして、こちらも合計576枚を用意
(コード略)
そして X_trainを画像、 y_trainに学習ラベルとして、numpy配列に変換
学習ラベル0をsora、1をmimiとして学習データーを作成しました
DATADIR = "/content/drive/MyDrive/cat_picture/data/"
CATEGORIES = ["sora", "mimi"]
IMG_SIZE = 32
training_data = []
def create_training_data():
for class_num, category in enumerate(CATEGORIES):
path = os.path.join(DATADIR, category)
for image_name in os.listdir(path):
try:
img_array = cv2.imread(os.path.join(path, image_name), cv2.IMREAD_GRAYSCALE) # 画像読み込み
img_resize_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # 画像のリサイズ
training_data.append([img_resize_array, class_num]) # 画像データ、ラベル情報を追加
except Exception as e:
pass
create_training_data()
random.shuffle(training_data) # データをシャッフル
X_train = [] # 画像データ
y_train = [] # ラベル情報
# データセット作成
for feature, label in training_data:
X_train.append(feature)
y_train.append(label)
# numpy配列に変換
X_train = np.array(X_train)
y_train = np.array(y_train)
# データセットの確認
for i in range(0, 4):
print("学習データのラベル:", y_train[i])
plt.subplot(2, 2, i+1)
plt.axis('off')
plt.title(label = 'Sora' if y_train[i] == 0 else 'Mimi')
plt.imshow(X_train[i], cmap='gray')
plt.show()
学習データのラベル: 1
学習データのラベル: 1
学習データのラベル: 0
学習データのラベル: 1

訓練用と検証用データーに分割
X_train, X_test, y_train, y_test = train_test_split(X_train,y_train,test_size=0.33, random_state=42)
これで、データづくりが終わりました
いよいよ次は学習モデルを作成します!
(ここまでが長かった)
2-2モデルの作成
ソラ・ミミを分類するモデルを作り、CNN(畳込みニューラルネットワーク)を実装していきます
CNN(Convolutional Neural Network)とは、「畳み込み」という操作を加えたニューラルネットワーク構造のことを言います。CNN最大の特徴は、「局所的に特徴量を抽出する」ことです。
・畳み込み層で、フィルタを用いて画像の特徴を抽出
・プーリングは、ダウンサンプリングやサブサンプリングとも呼ばれ、特徴マップのサイズを決められた演算を行って小さくしていきます
・全結合層は、通常のニューラルネットワークにおける隠れ層と出力層に相当します
modelのaddメソッドによって層を追加
まずは畳み込み層(CNN)を、次にPooling層を加えて、それを数回か繰り返した後に、
最後に全結合の層を付けて、0か1を出力するようにしています
あとはmodelのcompile関数で最適化関数・誤差関数を定義します
※モデルの学習を始める前に,compileメソッドを用いどのような学習処理を行なうかを設定する必要があります
model = Sequential([
Conv2D(16, 3, padding='same', activation='relu', input_shape=(32, 32,1)),
MaxPooling2D(),
Conv2D(32, 3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(64, 3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
2-3学習
history = model.fit(X_train, y_train, epochs=20, batch_size=32,validation_data=(X_test, y_test))
Epoch 1/20
25/25 [==============================] - 11s 23ms/step - loss: 12.7079 - accuracy: 0.6394 - val_loss: 0.5936 - val_accuracy: 0.6430
Epoch 2/20
25/25 [==============================] - 0s 6ms/step - loss: 0.3943 - accuracy: 0.8158 - val_loss: 0.2868 - val_accuracy: 0.8609
Epoch 3/20
25/25 [==============================] - 0s 6ms/step - loss: 0.2476 - accuracy: 0.8975 - val_loss: 0.2651 - val_accuracy: 0.8950
Epoch 4/20
25/25 [==============================] - 0s 6ms/step - loss: 0.1878 - accuracy: 0.9131 - val_loss: 0.2130 - val_accuracy: 0.9003
Epoch 5/20
25/25 [==============================] - 0s 6ms/step - loss: 0.1409 - accuracy: 0.9313 - val_loss: 0.1879 - val_accuracy: 0.9134
Epoch 6/20
25/25 [==============================] - 0s 6ms/step - loss: 0.1160 - accuracy: 0.9494 - val_loss: 0.2072 - val_accuracy: 0.9239
Epoch 7/20
25/25 [==============================] - 0s 8ms/step - loss: 0.1011 - accuracy: 0.9533 - val_loss: 0.1748 - val_accuracy: 0.9396
Epoch 8/20
25/25 [==============================] - 0s 7ms/step - loss: 0.1026 - accuracy: 0.9585 - val_loss: 0.2875 - val_accuracy: 0.8924
Epoch 9/20
25/25 [==============================] - 0s 7ms/step - loss: 0.1132 - accuracy: 0.9520 - val_loss: 0.2574 - val_accuracy: 0.9186
Epoch 10/20
25/25 [==============================] - 0s 7ms/step - loss: 0.0946 - accuracy: 0.9676 - val_loss: 0.2244 - val_accuracy: 0.9029
Epoch 11/20
25/25 [==============================] - 0s 7ms/step - loss: 0.1133 - accuracy: 0.9507 - val_loss: 0.2404 - val_accuracy: 0.9134
Epoch 12/20
25/25 [==============================] - 0s 8ms/step - loss: 0.1020 - accuracy: 0.9533 - val_loss: 0.1955 - val_accuracy: 0.9344
Epoch 13/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0622 - accuracy: 0.9792 - val_loss: 0.1745 - val_accuracy: 0.9213
Epoch 14/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0548 - accuracy: 0.9792 - val_loss: 0.1892 - val_accuracy: 0.9396
Epoch 15/20
25/25 [==============================] - 0s 7ms/step - loss: 0.0420 - accuracy: 0.9818 - val_loss: 0.2158 - val_accuracy: 0.9396
Epoch 16/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0429 - accuracy: 0.9844 - val_loss: 0.2414 - val_accuracy: 0.9213
Epoch 17/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0407 - accuracy: 0.9844 - val_loss: 0.1944 - val_accuracy: 0.9318
Epoch 18/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0366 - accuracy: 0.9883 - val_loss: 0.1919 - val_accuracy: 0.9318
Epoch 19/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0448 - accuracy: 0.9805 - val_loss: 0.1850 - val_accuracy: 0.9475
Epoch 20/20
25/25 [==============================] - 0s 6ms/step - loss: 0.0310 - accuracy: 0.9870 - val_loss: 0.2040 - val_accuracy: 0.9423
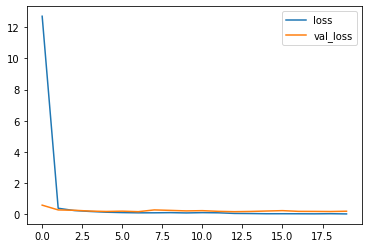
2-4評価
学習モデルを評価します。 出来上がった学習モデルに検証用データ (X_test と y_test )を与えて
誤差率と正解率を算出して評価します
score = model.evaluate(X_test, y_test, verbose=1)
print()
print('Test loss:', score[0])
print('Test accuracy:', score[1])
12/12 [==============================] - 0s 3ms/step - loss: 0.2040 - accuracy: 0.9423
Test loss: 0.20397047698497772
Test accuracy: 0.9422572255134583
誤差率:0.20
正解率:0.94
という成績になりました
さらに、loss(誤差)と
history = history.history
plt.plot(np.arange(len(history["loss"])),history["loss"], label="loss")
plt.plot(np.arange(len(history["val_loss"])),history["val_loss"], label="val_loss")
plt.legend()
accuracy(正解率)のグラフをプロットします
plt.plot(np.arange(len(history["accuracy"])), history["accuracy"], label="accuracy")
plt.plot(np.arange(len(history["val_accuracy"])), history["val_accuracy"], label="val_accuracy")
plt.legend()
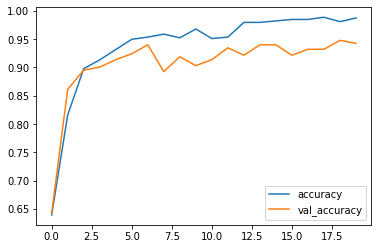
※過学習のご指摘をいただいたので、いろいろ調べてみると、
過学習とは、「コンピューターが手元にあるデータから学習しすぎた結果、予測がうまくできなくなってしまった」という状態で、
正解率のグラフを見るとEpoch6のあたりからaccuracyとval_accuracyに開きがあり、どうやら過学習になっているようです
このあたりの話は下記を参考にさせていただきました
もう少し、学習を深めてモデルを適正化していきたいと思います
2-5予測
学習したモデルに新たにソラミミの画像を読み込ませ、予測してもらいます
こちらを参考にさせていただきました
import numpy as np
from keras.preprocessing import image
#予測したい画像のパス
TESTPATH = "/content/drive/MyDrive/cat_picture/uploads/cat_org13.jpg"
#予測モデルに入力できるように画像を配列に落とし込む
img = image.load_img(TESTPATH,color_mode = "grayscale",target_size=(32, 32))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = x / 255.0
#予測
result_predict = model.predict(x)
print(result_predict)
model.predictでモデルに入力サンプルを与え、出力予測データを出力させています
今回の出力層はsimoid関数を使用していますので、結果は0.0~1.0の範囲の数値になります
結果:
[[0.5325012]]
結果が0に近いほどがソラ、1に近いほどミミということなのですが
画像をミミに変えて試しても、0.5付近の値に変化はありません
学習データーの成績はそこそこよかったので不思議です
今のところ原因がサンプル数が少ないこと、過学習によるものと思われるのですが
さらに調査を継続していきます
猫の写真をたくさん撮って、学習モデルも強化していきたいと思います
終わりに
Aidemyでpython、機械学習、ディープラーニングを3ヵ月学んで、今回、データーの作成、モデルの作成、学習、予想まで
初めて実行してみました
朝、4時半に起きて、会社から帰って毎日遅くまで、Aidemyの講習を頑張った3ヵ月間
この経験は将来必ず役に立つと思っています。
残念ながら予測がうまくいきませんでしたが、
次は、このモデルを改良して、ラズベリーパイを使って、今度は動画での猫の判別にチャレンジします!
ありがとうございました
“No. Try not. Do. Or do not. There is no try.” by ヨーダ