話の概要
AWS lambdaでsh shellも実行できる。
shellが実行できれば、実行できるバイナリがなにがあるのかがわかる。
足りないバイナリはレイヤとして追加すれば、/opt/bin以下に入って、普通に動作する。
これらを足し算すると…
rec_radiko_ts.shをつかって、S3バケットに保存ができます…ともあれ技術的には
という話。
話は
とリンクしますので、そちらもどうぞ。
前提
rec_radiko_ts.shを最大限生かす。というか、いじりたくない。
というわけで、rec_radiko_ts.shは必須です。
lambdaで
経緯はnote側に記載してますので、こちらは技術的な話を。
必要なことは以下のとおり。
- 最終的に保存するバケットを作る
- 必要最低限のロールを定義する
- 必要最低限のポリシーを定義する
- つくったロールにポリシーをアタッチする
- lambda関数をつくる
- 足りないライブラリ(curlとffmpeg)をレイヤーとして登録する
- 関数本体を定義する
- 設定を変更する
- 実行
以下で順を追って説明します。
作成手順
イマドキはCodeでインフラ定義するなんてのが主流だけど、ここではそんなの無視して手順を説明します。
最終的に保存するバケットを作る
特に難しいこと考えず作ります。

名前はなんでもいいが、radi-tokyoとしてます。
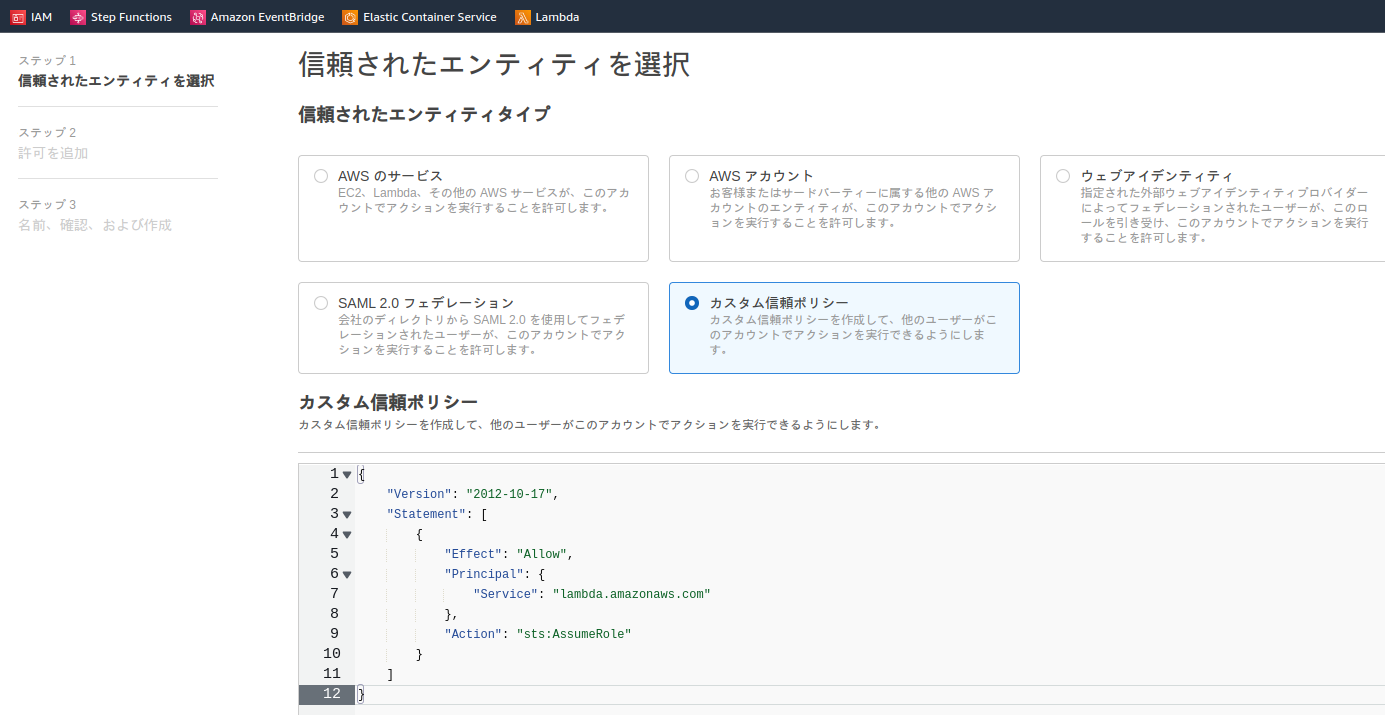
必要最低限のロールを定義する
最低限のロールを定義します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
名前はなんでもいいが、radi-tokyo-rollとしてます。
許可を追加→なにもせず次へ
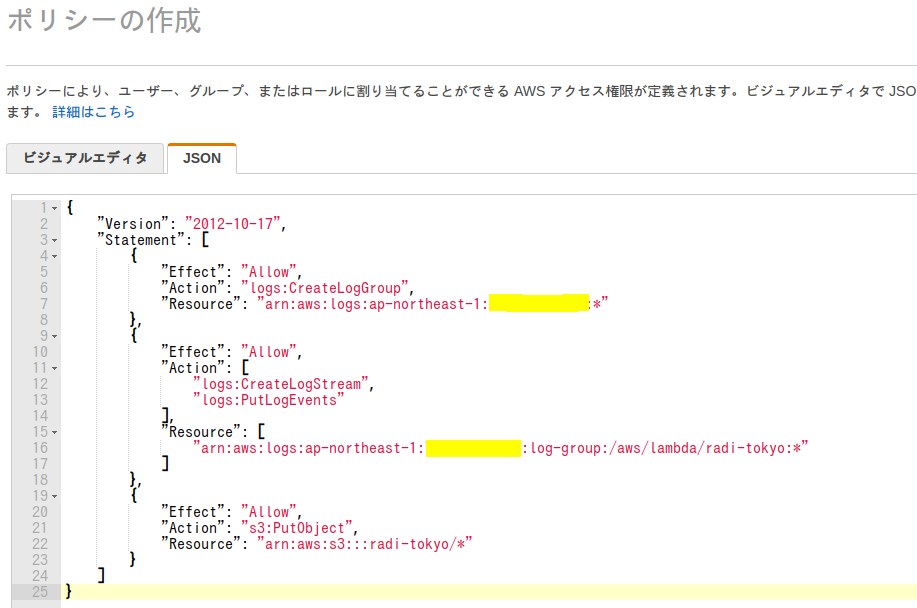
必要最低限のポリシーを定義する
最低限のポリシーを定義します。
消しているところはユーザのアカウントIDです。(ハイフンなしですよ!)
・createLogは必要らしいので追加
・s3:PutObjectは保存するバケットに許可するため。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:(アカウントID):*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:(アカウントID):log-group:/aws/lambda/radi-tokyo:*"
]
},
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::radi-tokyo/*"
}
]
}
名前はなんでもいいが、radi-tokyo-policyとしてます。
つくったロールにポリシーをアタッチする
ここでつくったロールにポリシーをアタッチする。
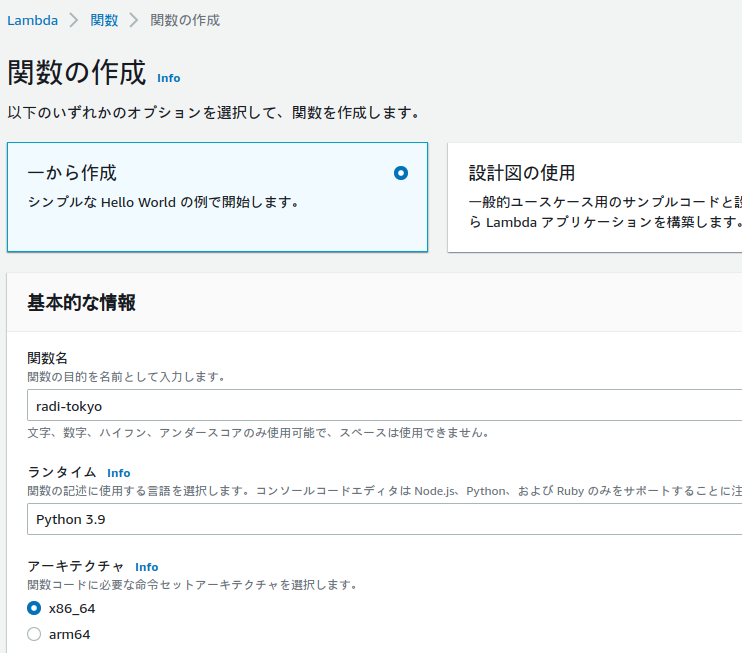
lambda関数をつくる
ここまでの準備を経て、始めて関数を作る。

ポイントは以下のとおり。
・名前はなんでもいいが、radi-tokyoとしてます。
・ランタイムは外部コマンドを呼び出せるのであれば何でもいいのですが、ここではpythonとします。
・アーキテクチャも特にこだわらなくていい…はずだが、arm64は試していない。
・デフォルトの実行ロールの変更で「基本的なlambdaアクセス権限で新しいロールを作成」を選んで作っても良い。ここまでのロールとポリシーの作成手順を飛ばすことができる。でも名前が勝手に決められちゃうので…気持ち悪い。
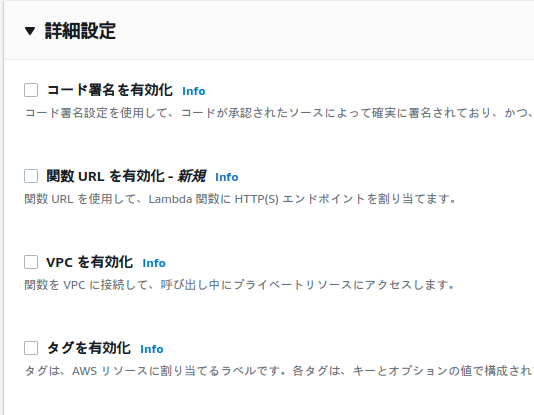
・詳細設定はチェックなし。「VPCを有効化」を選びたくなるが、結果として不要。
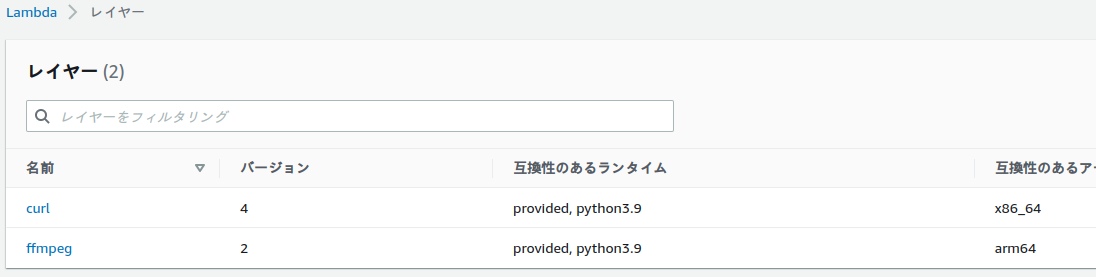
足りないライブラリ(curlとffmpeg)をレイヤーとして登録する
最終的につかうrec_radiko_tsはcurlとffmpegが必要。
レイヤーって何だ?とおもったけど、簡単に言うと
lambdaマシンの/opt/bin、/opt/lib以下に展開されるものだと思い込めばいい。
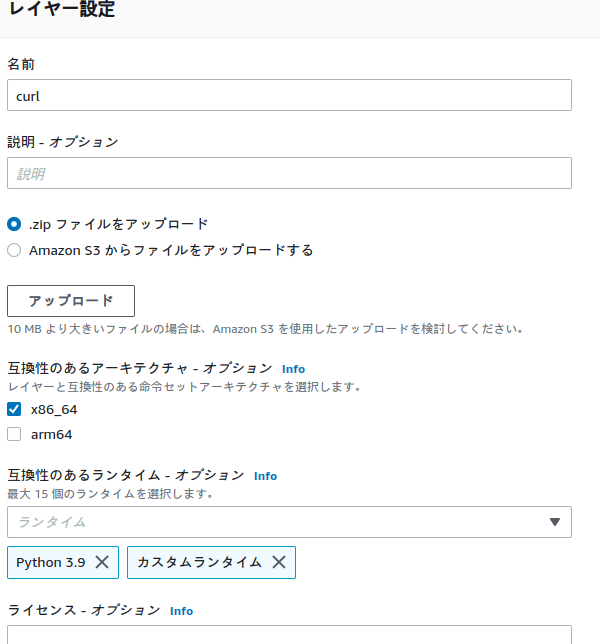
ポイントは以下のとおり。
・展開直下にbin,libのフォルダが配置されるように圧縮すること。
・互換性のあるランタイムはちゃんとコールする関数で使うランタイム(ここでいうとpython3.9)を含めないとつかえない。AWSのリンクだとpython3.6しか互換性がないので、結局自分でアップロードするしかない。
・互換性のあるアーキテクチャは、ライブラリに合わせる。とくにffmpegは公開されているバージョンの一番上のamd64なのでそっちをつかった。(これでいいんだ、なかなか自由だなぁ…)ちなみにバージョンは5.0.1です。
関数本体を定義する
関数本体はこちら
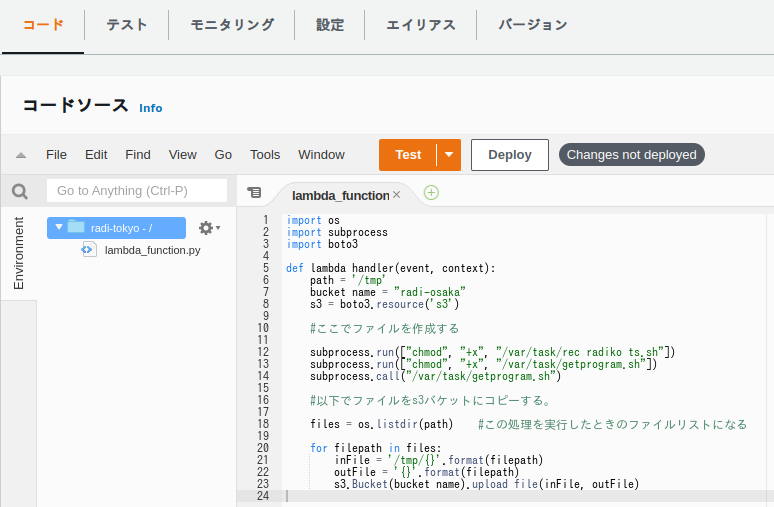
中にあるシェルファイル2つは以下のようにして作る
メニューの「file」から新しいファイルをつくる。
ひとしきり内容を書き込んだのち、保存するときにファイル名を指定する。

関数本体はこちら
import os
import subprocess
import boto3
def lambda_handler(event, context):
path = '/tmp'
bucket_name = "radi-tokyo"
s3 = boto3.resource('s3')
#ここでファイルを作成する
subprocess.run(["chmod", "+x", "/var/task/rec_radiko_ts.sh"])
subprocess.run(["chmod", "+x", "/var/task/getprogram.sh"])
subprocess.call("/var/task/getprogram.sh")
#以下でファイルをs3バケットにコピーする。
files = os.listdir(path) #この処理を実行したときのファイルリストになる
for filepath in files:
inFile = '/tmp/{}'.format(filepath)
outFile = '{}'.format(filepath)
s3.Bucket(bucket_name).upload_file(inFile, outFile)
1行め~3行めはimport。まぁPGみればどこでつかっているかわかるか。
pathは/tmpを指定しているが、lambdaマシンで唯一書き込みができるフォルダ。
ちなみにlambdaマシンはAmazon Linux 2ベースです。
その辺は↓がわかりやすい。
途中にでる
/var/task/rec_radiko_ts.sh
は割愛。ネットで取得したソースをまるっとコピペ。
/var/task/getprogram.shは/var/task/rec_radiko_ts.shを呼び出すためのシェル
#!/bin/sh
set -euo pipefail
/var/task/rec_radiko_ts.sh -s TBS -f `date -d -1week+tuesday +\%Y\%m\%d`0100 -d 120 -o "/tmp/`date -d -1week+tuesday +\%Y\%m\%d`_test.m4a"
exit 0
とかでいい。ちなみにdateもちゃんと使える。
(alpineとかだと、dateが簡易版で「-1week+tuesday」こういうのがつかえない。)
で、これらのPGはどう動くかというと
起動→py関数→getprogram.shが実行→rec_radiko_ts.shが呼び出されて実行→最後、/tmpに保存されたファイルをまるっとS3バケットへ
こんな感じ。
lambda関数とルートは、lambdaマシンの/var/task
よって、そこにファイルは保存できる。しかし、実行権はないので自力で実行権を付与する。
シェルの実行結果は/tmpに書き込まれる。
最後、その/tmpのファイルすべてをまるっとS3バケットにupload_fileする。
こんな感じ
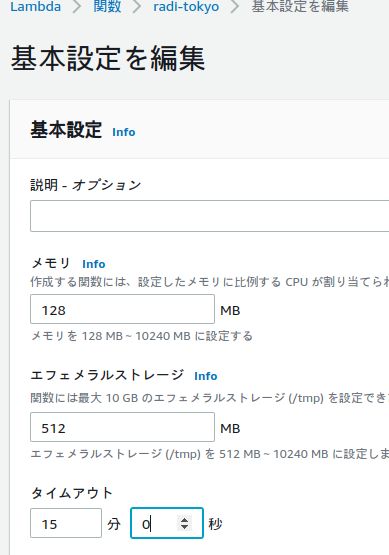
設定を変更する
lambda関数のデフォルトはタイムアウト3秒。さすがに短すぎるので修正する。
まぁmaxの15分でいいと思う。
実行
テストでもいいから実行する。
起動に引数もないのでhelloWorldをそのまま使って良い。
…これでできちゃうんですね、技術的には。
最後に
技術的にはできますが…AWSのインスタンスって東京なんですよね。
これを使えるととらえるかどうか。
でも、lambdaマシンのことやレイヤーのこととかわかって、よかったです。
役に立ったら、イイネしてね。