SENetsとは
- 元の論文: Squeeze-and-Excitation Networks, arXiv:1709.01507 [cs.CV]
“SENet"というネットワークがあるわけではなく、”SE”をResNetやInceptionと組み合わせて作り出せるネットワークの総称です。
既存のネットワーク、例えばResNetやInceptionに適用して、より性能の高いモデルを実現します。
下記の説明が簡潔ですが、元の論文の説明を交えて解釈したほうが良かったので、この記事にまとめました。
更新 (2020.6.6)
数年たった投稿ですが、意外にご参考にしていただく方が多く、一言追記しておく必要があると思いました。
2020年の今となっては、Transformerの登場に見られるような、データ全体からの情報を使うという考え方、SENetsは画像のグローバルな情報を利用しているので有効だという見方が一般的になっています。
概要
通常CNNの畳み込み層では、入力チャンネルが畳み込まれたあと、全て均等にチャンネルに出力されます。
これに対してSENetsは畳み込み層の各チャンネルを均等に出力せず、適応的に重みをかけることがポイントです。
SE(”Squeeze-and-Excitation"ブロックの実装例を見てみましょう。
def se_block(in_block, ch, ratio=16):
z = GlobalAveragePooling2D()(in_block) # 1
x = Dense(ch//ratio, activation='relu')(z) # 2
x = Dense(ch, activation='sigmoid')(x) # 3
return multiply()([in_block, x]) # 4
-
Global Average Poolingで、チャンネルごとの代表値として画素値平均
zを取る。(ぎゅっと_Squeeze_する部分) -
zは、更にch//ratio個に減らしてチャンネル間の非線形の関係を取る。わざとボトルネックを作って次元削減している。 - 再び
chに次元を戻す。(チャンネル間の相関を強調する、と書いてあることに相当するのか)。 - ここまで計算された値で各チャンネルを重み付ける。(2からここまでが_Excitation_)
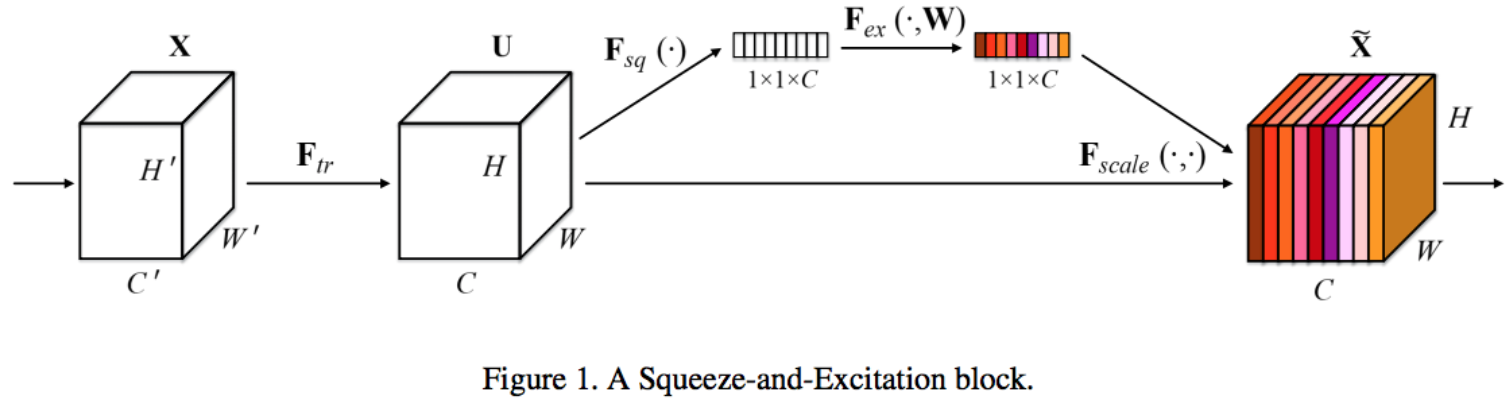
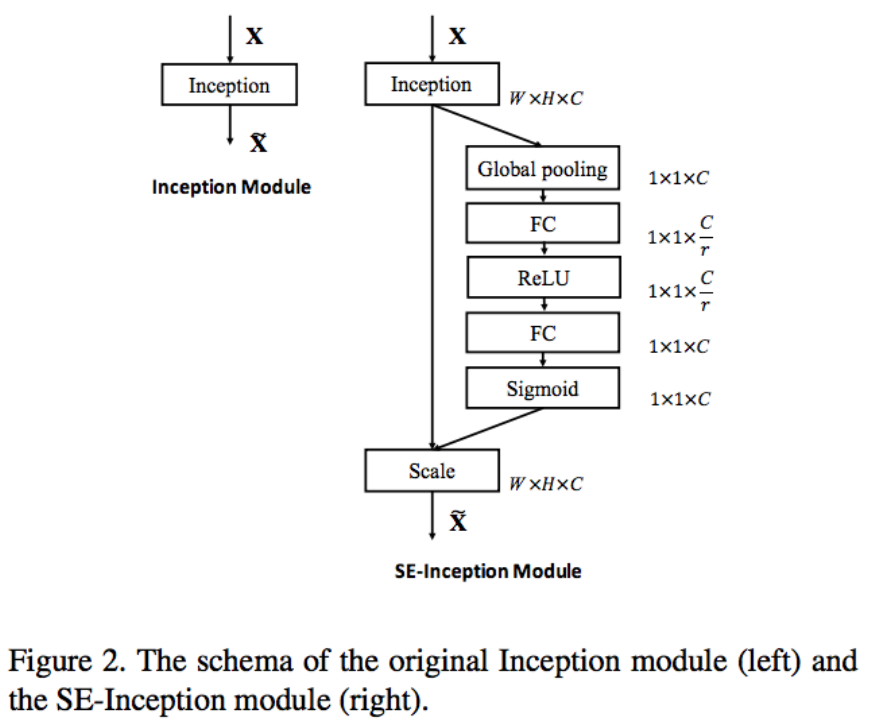
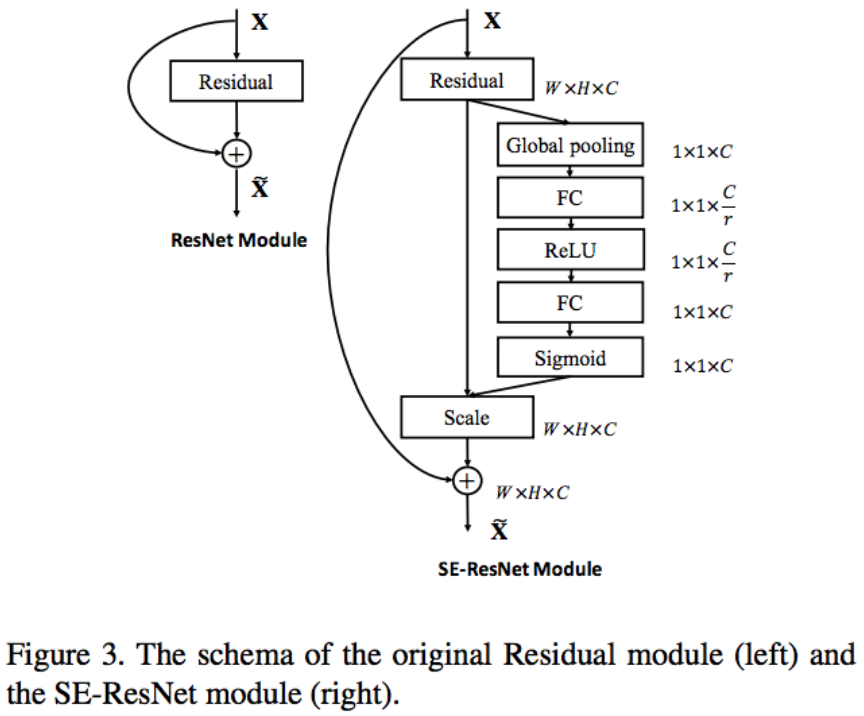
図: SEブロック (Squeeze-and-Excitation Networks, arXiv:1709.01507 [cs.CV] より)
利点
このSEブロックが、入力が条件付けるダイナミクスを本質的にもたらして特徴を識別する能力を高める、と論文で述べています。
補足(2020.6.6) 画像全体の情報を利用するTransformerのSelf-Attentionのような効果があるという見方が強くなっています。
またこのブロックを追加したとしても、計算量は1%以下しか増加せず、様々な既存モデルに適用できることが特徴ということです。例えばResNet-50に適用することで、ResNet-101相当の性能になり、ResNet-101に比べて半分の計算量になることが利点となります。