レコード間の名寄せ(Entity Recognition/Deduplication)を省力化・自動化できるかもしれない入門~
Introduction
皆様、"Enitity Matching""Deduplication"したことありますか?
おそらく多くのエンジニアの方は、
なんじゃいって感じになるかと思います。
しかし簡単に言えば、テーブル内・テーブル間のレコードの名寄せです。
多くの人が経験したことがあるでしょう。
一言に言うと、表記ゆれとかあっても"fuzzyにjoin/distinct"する事です。
SQLのJOINで扱えるレベルなら、簡単です。
しかし表記ゆれや誤りを考慮に入れた途端、厄介になります。
今回はそんな名寄せについて自動化・省力化するために、
まずその概要をまとめました。
Notice
- 概要です。各論は個別記事を追加
していく予定ですするかもしれません。 - 拙著関連記事へのリンクがあります
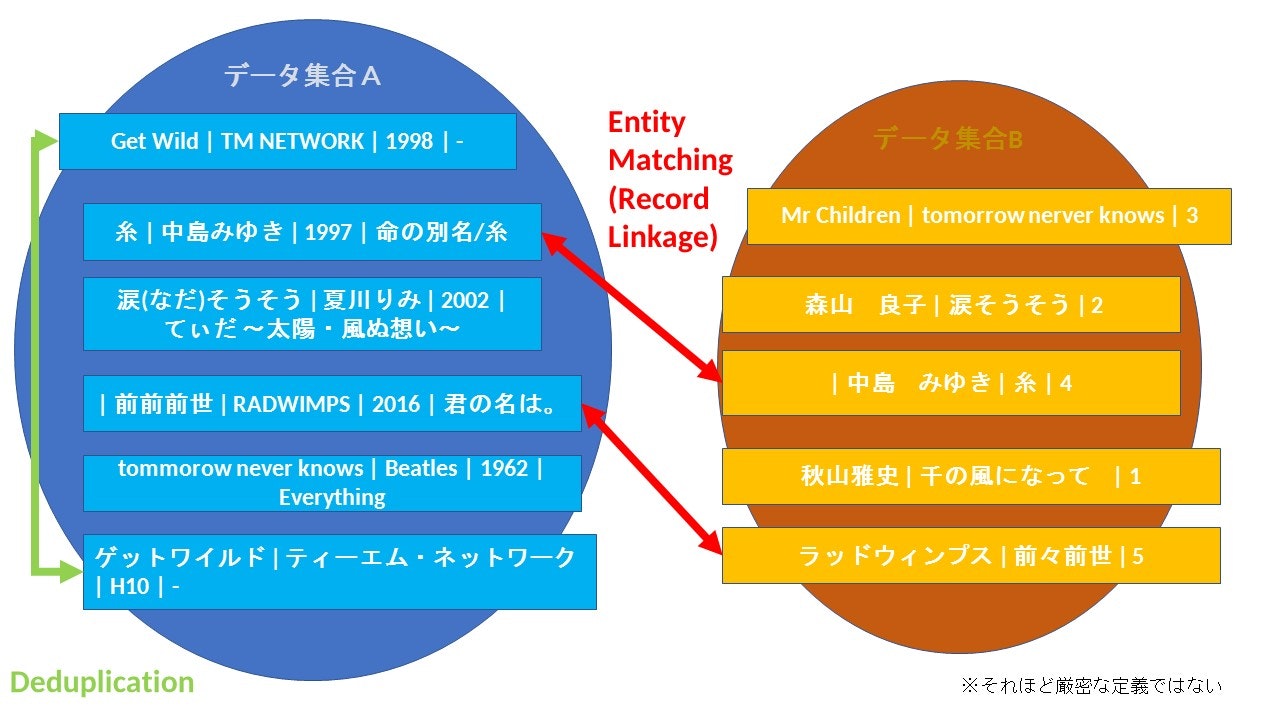
名寄せ(Entity Matching/Deduplication)とは
名寄せ(Entity Matching/Deduplication)の再定義
なんとなく"名寄せ"という言葉を使っているかと思いますが、
改めて定義すると、
- 同じEntityを指すレコードをリンクまたは統合すること
- レコードが同じデータ集合にあるか違うデータ集合にあるかで、Entity Matching/Deduplictionと使い分けることがある (ただしそれほど厳密ではない)
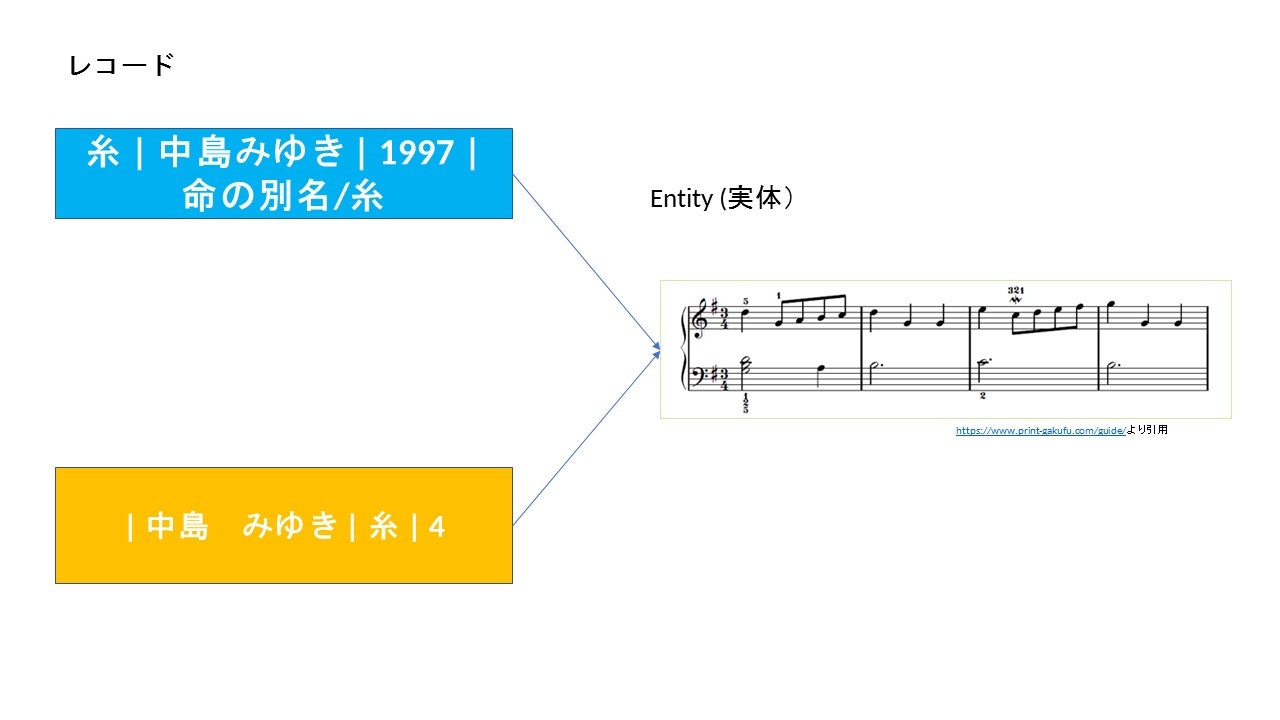
Entityとレコード
-
Entity
ここでは実体を指します。現実世界の一つの存在に対応します。基本的に同じものは複数存在しません。 -
レコード
実体の記録です。記録なので複数記録されることがあります。
そのためEntityとレコードは必ずしも1対1に対応しません。
例えばこの図の場合実体は一つですが、
レコードとしては2つ記録されています。
名寄せの呼び名
ちなみにタスクの呼び名が多岐に渡り、情報を検索するのが結構大変です。
先行論文でも呼び名が違うと、同じようなことをやっていてもお互いに参照していない!
ケースはよくありました。
まずこれを名寄せして!
- record linkage
- data linkage
- entity resolution
- name disambiguation
- author disambiguation
- object identification
- co-reference resolution
- object identification
- data reconciliation
- citation matching
- reference matching
- field matching
- identity uncertainty
- duplicate detection
- deduplication
- authority control
- approximate string join
- similarity search
- merge/purge
- list washing
- data cleansing
- field scrubbing
もちろんそれぞれ微妙に範囲に違いがあったり、違う意味でも使われるものもありますが・・・
名寄せの問題
名寄せの必要性が発生するのは、共通の信頼できるidが存在しないケースです。
そのため、不確実な属性(フィールド)の値から実体の同一性を推測しなければなりません
不確実性の原因
不確実性の原因には様々なものがありますがたとえば以下のようなものがあげられます。
※分類は独自の判断に基づきます
-
入力エラー(誤字脱字)
- Typo
- 欠損
-
データ体系の差異
- コーディングの方法の差異
例:性別の欄
男・女・その他 - 0, 1, 2
(JIS規格があるそうですが、なかなか普及せず)
- フォーマット方法の差異
- 例
日付の表記
2018年10月17日 - 17/10/2018
- 例
- フィールドの単位の差異
-
例1
住所東京都千代田区永田町2丁目3−1
|東京都 | 千代田区 | 永田町| 2丁目| 3 | 1 (分割済み) -
例2
製品名
Kingston 133x high-speed 4GB compact flash card ts4gcf133, 21.5 MB per sec data transfer rate, dual-channelsupport, multi-platform compatibility. (分かれるべきフィールドがわかれていない)
-
- カテゴライズの差異
- 例
製品カテゴリ
電子部品 - USB記憶装置
- 例
- コーディングの方法の差異
-
別表記
- 別名・省略・簡略化
- 例
NHK - 日本放送協会
株式会社 - (株)
- 例
- 違う文字種 (英語・漢字・ひらがな・カタカナ)
- 例
NTT - エヌ・ティー・ティー
- 例
- 別名・省略・簡略化
-
情報の鮮度の差異
レコードがout of dateになっているかup to dateになっているか- 結婚などで姓または名が変わった。
桂小五郎 <=> 木戸孝義 - 市区町村が合併した。
中巨摩郡櫛形町 <=> 南アルプス市
- 結婚などで姓または名が変わった。
解決にデータに対するメタ知識・ドメイン知識が求められることもあり、
人間でも正解がすべて分かるとは限りません。
どこまで名寄せが可能かはデータの状態に著しく依存します。
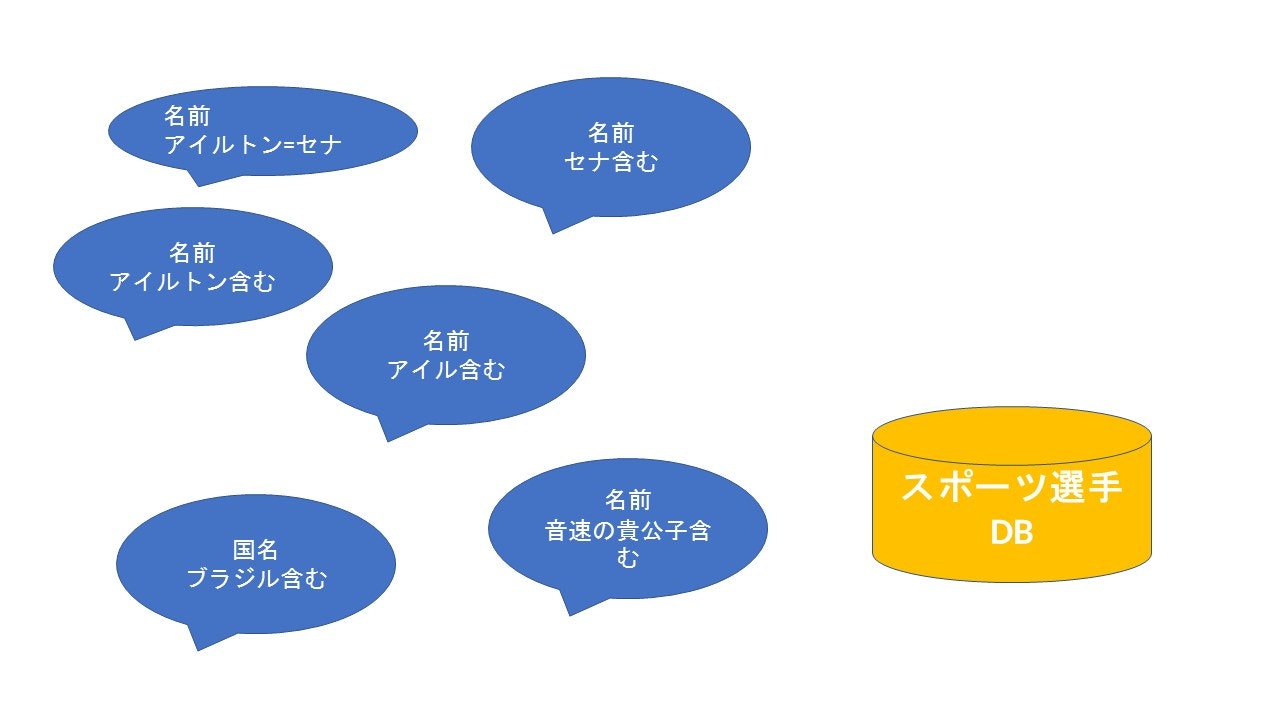
人力でDBやExcelの標準機能を使って名寄せを頑張ってみる
エラーや表記ゆれがあることを前程とすると、完全一致だけで検索しても漏れが出ます。
そのためあるレコードから思いつく限りのクエリで
もう一方のデータ集合を検索を行い、その存在の有無を確認する必要があります。
そしてデータ集合に無いことを確認するのが厄介で、
悪魔の証明ほどではありませんがきりがありません。
- 例
アイルトン=セナがスポーツ選手DBに無いことを確認するには・・・
なんとか自動化したい・・・せめて範囲を絞りたいですよね?
特徴量抽出
自動化/省力化の手法進む前に、特徴量抽出について触れなくてはなりません。
特徴量を使う手法が多いためです。
が、長くなってしまったので別記事にいたしました。以下の拙著記事を参考ください。
名寄せ(entity recognition, deduplication) で使える特徴量 - Qiita
自動化・省力化するための主な手法
- ルールベース
- スコアベース
- クラスタリング/kNN(最近傍探索)/Range Search
- Pair-wise 2値分類
- グラフベース
1. ルールベース
クエリと検索対象のが一致するように
一番よさそうな変換ルールの組み合わせを探します。

もっともよいルールの組み合わせを探すのは
考えられる限りのルールのリストと正解データがあれば、
最適化アルゴリズムである程度自動化できます。
参考
ブロッキングの手法ですが、考え方は参考になるかと思います。
特徴量を得るための前処理として行うこともあります。
2. スコアベース
なんらかの基準で、類似度や関連度を算出します。
自分工夫して作ることもできます。
閾値を設けたりランクすることで、値が小さい(または大きい)ものを取り除き、適合率を上げます。
種類としては以下のようなものがあります。
- 距離・疑似距離
- 検索スコア
- ベクトル空間モデル
これらを他の方法への特徴量として用いることもできます。
さらにメトリックをベースにして、検索用のデータ構造を作ることもできます。
1. 距離・疑似距離
2つのレコードの間の距離を定義します。
クラスタリングなどに使うのでなければ、正確に三角不等式が成り立たなくもよいので、
擬似距離でも構いません。
例
編集距離(レーベンシュタイン距離)
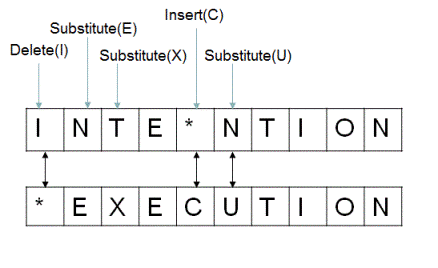
https://raw.githubusercontent.com/sumitc91/data/master/askgif-blogより引用
最少の回数で2つの文字列を同じにする編集の組み合わせを探します。
この場合距離は5です。
欠点(特に編集距離の場合)
- 基本的にはスペルミスなどわずかな違いがあるものしか検知できない
- インデックスを用意するなどの事前計算ができない
- 複数フィールドを比較する場合、重みづけなど定義が難しい
2. 検索スコア
Luceneなど検索エンジンでも使われる指標です。(正しい呼称は不明)
そのままだと、得られる候補が多く何らかの方法でフィルターをかける必要があります。
例
- TF-IDF
- Okapi BM25
(TF-IDFをドキュメントの長さを
考慮するなどして改良したもの)
3. ベクトル空間モデル
ngramなどの特徴量からなるベクトル空間内で定義できる指標です。
例
- cosine類似度

※ Statistics for Machine Learning by Pratap Dangeti より引用
4. kNN(最近傍探索)/クラスタリング
kNN
距離によるメトリック空間または特徴量ベクトル空間内の
ある点から一番近くにある点を探します。
最近傍にある点に対応するレコードが同一Entity候補となります。
-
厳密なkNN
kd-tree, vp-tree, ball-tree, bk-tree, lsd など- メトリックベースの場合メトリックの表現力に性能が大きく左右される
- 次元が高い場合次元の呪いに苦しむ
-
ANN
近似的だが高速なNN
faissなど- 画像やドキュメントの名寄せにもよく使われる。
- 次元の呪いをある程度回避できる(要出典)
関連記事
クラスタリング
同じクラスターにあるレコードを同一エンティティー候補とみなす
名寄せではhierarchical clusteringなどがよく用いられます。
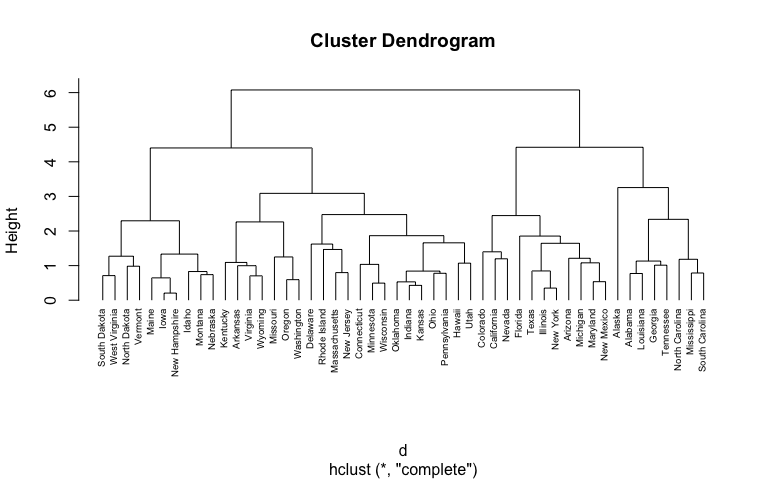
のようなクラスターが得られるので都合のいいクラスターサイズになる距離(この場合高さ)で切ります。
名寄せの場合候補を絞りたいので、小さいクラスターサイズになるよう小さめの距離が使われることが多いです。
※図は https://uc-r.github.io/public/images/analytics/clustering/hierarchical より引用。名寄せの例ではありません。
研究例: Efficient record linkage algorithms using complete linkage clustering, Mamun A Aseltine R Rajasekaran S, PLoS ONE, 2016 vol: 11 (4) pp: 1-21
欠点
- やはり次元の呪いに苦しむ
- 短いフィールドの名寄せに使うとしばしばクラスターが連結してしまい、クラスターサイズが膨らむ
- 都合のいいクラスター数・サイズのチューニングが難しい
- クラスターサイズが膨らんだり、余計な候補が含まれるのを以下のような方法で意図的に防ぐことがある。
- centroidの設定
- canopy
Pair-wise 2値分類
2つのレコードのペアをMatch/Un-match(1, 0)で分類します。
みんな大好きNaive Bayes/SVM/Boostingなどおなじみの分類アルゴリズムが使えます。
教師ありまたは半教師ありで行います。
- 教師ありだけあって、性能は他のものより良いと思われる。 (そもそも教師なしとの比較論文がなかったため正確にはわかりません。)
- 後述のブロッキングを検索ととらえると、Learning to RankのPair-wise approachの関連度を1, 0に限定したものととらえられる
- 疫学などでよく使われるFellegi-Sunter framework (probabilistic record linkage)もNaive Bayesの亜種
(参考: Extending naive Bayes classifier with hierarchy feature level information for record linkage Zhou Y Howroyd J Danicic S Bishop J)
分類器を学習させるうえで3つの大きな問題
名寄せには分類器を学習させる上で厄介な問題があります。
- ペア生成によるサンプル数の指数的増加
- “very-imbalanced”なデータ
- ラベル付けのコストの重さ
1. レコードのペア生成によるサンプル数の指数的増加
例えばN件のレコードを持つデータ集合A, M件のレコードを持つデータ集合Bから
生成されるレコードのペア数は
$$NM個$$
になります。
仮にN=1万, M=1万なら
$$1億個$$
となり当然すべてのペアを使って学習させると、膨大なリソースと時間を食います。
2. “very-imbalanced”なデータ
レコードペアの中で一致している(=ラベルが1)なのは一部です。
例えば先ほどの1億個のペアのうち、最大でも1万個のペア(たったの0.01%)しかありません。
(それぞれのデータ集合内では重複がないと仮定。)
一般的にラベルの割合が10:1以下だと分類器の学習が進みにくい(要出典)ので、何か対策が必要です。
3. ラベル付けのコストの重さ
- 先述のように1件の正解ラベルを付けるのも大変
- 検索を繰り返す
- 候補が多い- メタ知識・ドメイン知識が求められる
ラベル付けもできるだけ減らしたいですよね。
対策
- Blocking
- Clustering/kNNによるunder-sampling
1.ブロッキング
- データ集合を何らかの基準に基づいてブロックに分割します。この時マッチしているペアがなるべく含まれるように分割します。
- ブロックの中で、学習に使うペアを生成します
- ブロックを小さくできればできるほど、ペアの生成数を減らすことができます。
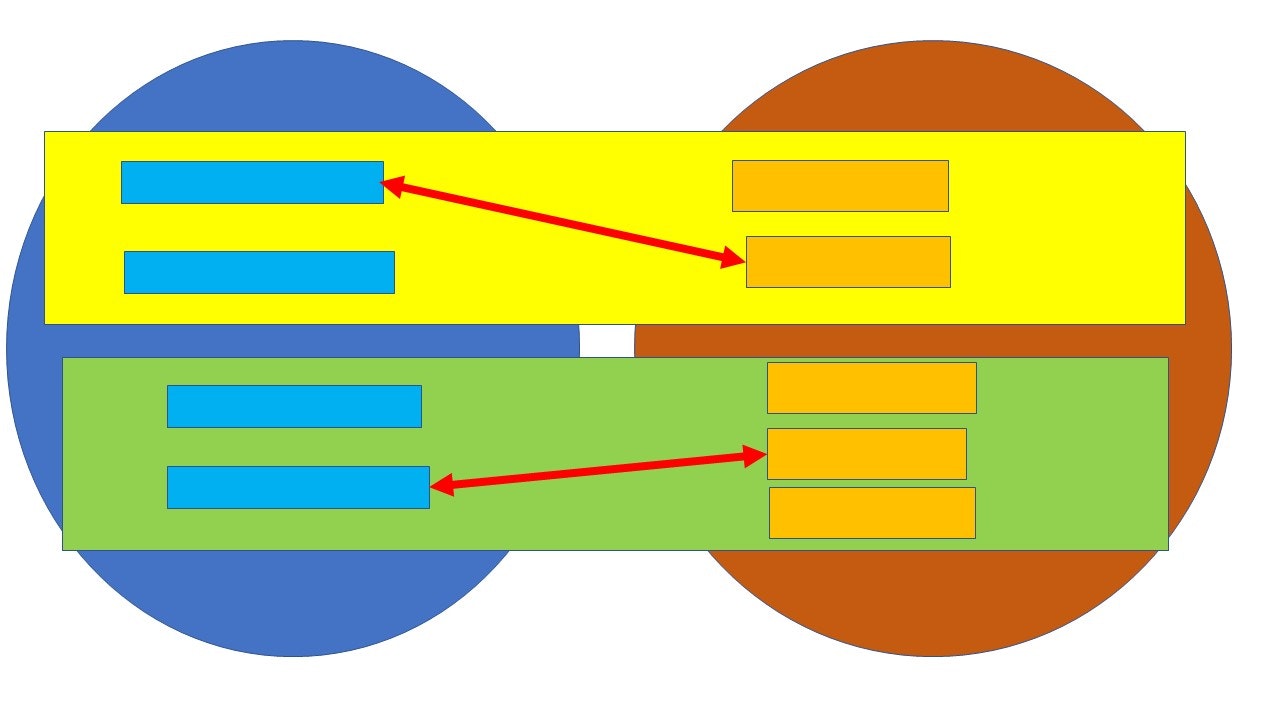
代表的なblocking
-
教師なし
- ミスや揺れがないフィールドや特徴量の値に基づく分割
- k-mer
-
教師有り
- Adaptive Blocking
- Semi-supervised blocking
例
- k-mer
共通のsubstringを持つレコードを同じブロックに割り当てます。
Tokenを使って似たようなこともできます。
2. Clustering/kNNによるunder-sampling
クラスターサイズを大きめにとったクラスタリングやkを大きくしたkNNでブロッキングでレコードペアのunder-samplingを行います。
教師なしでもできるのが魅力ですが、再現率は下がりがちです。
関連記事
評価について
blockingやundersamplingを行ったとき、気になるのが評価用のデータに
- blocking/undersamplingしたレコードペア
- 特に数を減らさないそのままのレコードぺア
のどちらをつかうべきか判断に迷うかもしれません。
先行論文では1が多いみたいなのですが、
blocking/undersamplingを含めたpipelineの性能評価となると2で評価しないと意味がないと思うのですが・・・
実務で使うなら、両方を行うことになるでしょう。
データセット
性能比較に使えるデータセットは以下のリンク参照
名寄せのベンチマークに使えるレコードデータセットまとめ record linkage, Entity Resolution, Deduplication) - Qiita
まとめ
- 名寄せの自動化・省力化には様々なアプローチがある
- 近傍探索、クラスタリングや機械学習に落とし込むことはできるが、様々な考慮事項がある
結局データとか要件次第という他のタスクでもよく聞く流れですね・・・。
参考文献
-
Data Matching - Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection2. http://users.umiacs.umd.edu/~getoor/Tutorials/ER_VLDB2012.pdf
-
Ashwin Machanavajjhala Lise Getoor, L. G., & Machanavajjhala, A. (n.d.). Entity Resolution: Tutorial. Retrieved from http://goo.gl/f5eym
-
Sayers, A., Ben-Shlomo, Y., Blom, A. W., & Steele, F. (2015). Probabilistic record linkage. International Journal of Epidemiology, (December 2015), in press. https://doi.org/10.1093/ije/dyv322
-
Dusetzina, S. B., Tyree, S., Meyer, A.-M., Meyer, A., Green, L., & Carpenter, W. R. (2014). An overview of record linkage methods. Linking Data for Health Services Research: A Framework and Instructional Guide, 29–49. https://doi.org/AHRQ No.14-EHC033
-
Chu, X., & Ilyas, I. (n.d.). Qualitative Data Cleaning, 1605–1608.
-
Ashwin Machanavajjhala Lise Getoor, L. G., & Machanavajjhala, A. (n.d.). Entity Resolution: Tutorial. Retrieved from http://goo.gl/f5eym
-
Brizan, D. G., & Tansel, A. U. (2006). A Survey of Entity Resolution and Record Linkage Methodologies. Communications of the IIMA, 6(3), 41–50.
-
Scholar, P. G. (2016). A Survey On Duplicate Record Detection In Real World Data, 1–5.
-
Konda, P., Das, S., Suganthan, P., Doan, A., Ardalan, A., Ballard, J. R., … Raghavendra, V. (2015). Magellan: Toward Building Entity Matching Management Systems. Retrieved from http://www.vldb.org/pvldb/vol9/p1197-pkonda.pdf
-
PROBABILISTIC LINKAGE OF LARGE PUBLIC HEALTH. (n.d.).
-
Sayers, A., Ben-Shlomo, Y., Blom, A. W., & Steele, F. (2015). Probabilistic record linkage. International Journal of Epidemiology, (December 2015), in press. https://doi.org/10.1093/ije/dyv322
-
Christen, P., Hegland, M., Roberts, S., Nielsen, O. M., Churches, T., Lim, K., & Al., E. (2002). Parallel computing techniques for high-performance probabilistic record linkage. Symposium on Health Data Linkage, 19. Retrieved from http://www.publichealth.gov.au/pdf/reports_papers/symposium_procdngs_2003/christen.pdf
-
Pita, R., Pinto, C., Melo, P., Silva, M., Barreto, M., & Rasella, D. (2015). A Spark-based workflow for probabilistic record linkage of healthcare data. In CEUR Workshop Proceedings.
-
Data_Quality_and_Record_Linkage. (n.d.).
-
Ebraheem, M., Thirumuruganathan, S., Joty, S., Ouzzani, M., & Tang, N. (n.d.). Distributed Representations of Tuples for Entity Resolution. Retrieved from https://arxiv.org/pdf/1710.00597.pdf
-
Hellerstein, J. M. (2008). Quantitative Data Cleaning for Large Databases. United Nations Economic Commission for Europe, 42. Retrieved from http://db.cs.berkeley.edu/jmh/cleaning-unece.pdf%5Cnpapers2://publication/uuid/DC7173AB-6B26-4B8B-AEC3-4C7E65CEEFED
-
Christen, P., Churches, T., & Hegland, M. (2004). Febrl – A parallel open source data linkage system, (May).
-
Christen, P. (2016). Data Linkage : Introduction , Recent Advances , and Privacy, (July).
-
Steorts, R., Ventura, S., Sadinle, M., & Fienberg, S. (2014). A Comparison of Blocking Methods for Record Linkage. International Conference on Privacy in Statistical Databases, (2014), 253–268.
-
Bilenko, M., Kamath, B., & Mooney, R. J. (2006). Adaptive blocking: Learning to scale up record linkage. In Proceedings - IEEE International Conference on Data Mining, ICDM (pp. 87–96). https://doi.org/10.1109/ICDM.2006.13
-
Mamun, A. Al, Aseltine, R., & Rajasekaran, S. (2016). Efficient record linkage algorithms using complete linkage clustering. PLoS ONE, 11(4), 1–21. https://doi.org/10.1371/journal.pone.0154446
-
Zhou, Y., Howroyd, J., Danicic, S., & Bishop, J. M. (2015). Extending naive Bayes classifier with hierarchy feature level information for record linkage. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). https://doi.org/10.1007/978-3-319-28379-1_7
-
Mudgal, S., Li, H., Rekatsinas, T., Doan, A., Park, Y., Krishnan, G., … Park, Y. (2018). Deep Learning for Entity Matching: A Design Space Exploration, 16. https://doi.org/10.1145/3183713.3196926