名寄せ(entity recognition, deduplication) で使える特徴量
レコードやオブジェクトを教師あり学習・教師なし学習や検索エンジンで
名寄せ(Entity Recognition・Deduplication)するときに、それぞれのフィールドから特徴量を抜き出す必要があります。
意外とまとまって言及しているリファレンスは少ないので、
特に文字列のフィールドでよく使われる特徴量を上げてみました。
データベースのブロッキングに使われるものも含まれます。
特徴量の種類
分類は独自の基準に基づきます。
- Token
- 固有表現
- 音素
- 分散表現/次元圧縮
- 検索スコア
- 距離・擬似距離 (レコードのペアの場合)
各特徴量の概要
1. Token
文字列から、さらに小さい構成単位を抽出します。
ただし、次元が大きいsparse matrixになるため、機械学習やクラスタリングで用いるには次元に対して大量のデータが必要か、工夫が必要です。
-
character ngram
ご存じ文字単位のngram。辞書によらないため、
- 表記ゆれ・誤字脱字がある
- 一つのフィールドはそこまで長くない
entity match, deduplicationタスクには有効です。
日本語や中国語など文字の種類が大きい場合、
BoWでもよい特徴量になります。
(characterのtokenの場合BoWと呼んでいいかわかりませんが・・・) -
word ngram
これもnlpの特徴量としてはおなじみ。
英語など単語間に区切りがある言語ならそのまま単語を抽出できます。-
形態素
日本語や中国語などあらかじめ単語に区切られていない言語で使われます。
ただし名寄せ特有の事情として以下の点に注意点があります。- 単語にはそもそも表記ゆれや誤字脱字があるかもしれないため、単純に辞書と比較するのではなく、形態素分割に工夫が必要
- フィールド対象が往々にして固有名詞が多いため、辞書のカスタマイズが必要
-
-
文字種の変換後抜き出されたToken
- カタカナ <=> 英語
- 漢字 <=> かな
文字種をどちらかに統一します。
もちろん変換が正しく行われる保証はありませんが、他の特徴量と一緒に使うには問題ありません。 -
数字の抜き出し
数字以外も含む文字列から数字の部分を抜き出します。
例:
"ノートPC dynabook Satellite B453(2013年7月)"
=> 453, 2013, 7 -
sentence piece (sub-word units) (NEW!)
NN翻訳などで日本語など単語間の区切りがない場合によく使われる手法。
単語ではなく、それより小さい単位にまとめてエンコードします。単語や品詞の区切りと一致するとは限りません。
誤字・脱字がある場合にcharacter n-gramよりは規則性をもってまとめてくれるので、有効かもしれません。- Mecabの作者がhttps://github.com/google/sentencepiece
で高速な実装を提供している。ありがたや・・・
- Mecabの作者がhttps://github.com/google/sentencepiece
2. 音素
名寄せや音声認識特有の特徴量です。
文字列ではなく、そこから推測される音素に注目します。
-
phonetic fingerprints (音素の指紋)
アルファベットを使う言語でよく使われる手法です。
発音に注目し、エンコードします。(対応言語のエンコーダーが必要)
英語のエンコーダーには- metapohne3
- soundex
などがあります。
発音が同じもしくは似ている文字列が、
同じコードにエンコードされます。スペルミスなどに対応できます。例:soundexの場合
- Jakson => J250
- Jucksn => J250
3. 分散表現
こちらもdeep learningを使ったnlpではおなじみ、Tokenを低次元で表現する(=埋め込む)特徴。
- Word2Vec, fastText, GloVecなど
- 単語を埋め込む場合表記ゆれを考慮するために、char-ngramから推測できるfastTextモデルが有効だという報告があります。
(参考 Deep learning based approach for entity resolution in databases Kooli N Allesiardo R Pigneul E 2018 vol: 10752 (January), DOI 10.1007/978-3-319-75420-8 )
ただし、名寄せでよく使われる固有名詞の学習は事前学習済みの分散表現では十分に学習されてない(相対的に頻度が少ないので切られていたりまとめられている)ことが多いので、自分で学習させることが必要になります。
また類似語は同じようなベクトルで表現されてしまうので、直接Tokenを使うよりぼやけてしまうことがあると述べている文献
(参考 Deep Learning for Entity Matching: A Design Space Exploration, Mudgal S Li H Rekatsinas T Doan A Park Y Krishnan G Deep R Arcaute E Raghavendra V Park Y, 2018, pp: 16)もあります。
単体で使うよりは他の特徴量と組み合わせたほうがよさそうです。
4. 固有表現(要素のパース・表記の標準化を含む)
ここでも性能を上げるためには素直な辞書ベースの系列ラベリングではなく、表記ゆれ対策が必要です。
- パース
例
株式会社○○開発部3課
=> 株式会社○○
開発部
3課
- 抽出
例
"映像も綺麗で満足しています。GoPro3を持ってますが、今後は、こちらの使用頻度は多くなると思います。"
=> GoPro3
5. 検索スコア
ご存じSolrやElasticsearchなど検索エンジンで使われているスコア。呼び名が正しいかは不明。
単独でも、ケースによっては十分な性能が得られます。
検索スコアを算出するのにTokenなどが必要ですが、
そこからさらに特徴量抽出したものです。
代表的なスコア
- TF-IDF
- Okapi MB25
6. 類似度
こちらはレコードのペアに対して定義されます。
-
距離・記事距離
2つのレコードの間の距離を定義します。
アルゴリズムによっては、正確に三角不等式が成り立つ必要はありません。代表的な距離
- Jaccard Similarity
- 編集距離
例
- 編集距離(レーベンシュタイン距離)
最少の回数で2つの文字列を同じにする編集の組み合わせを探す
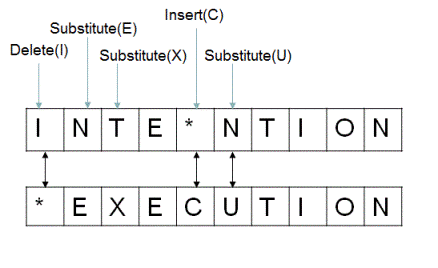
この場合は距離は5
欠点(編集距離の場合)
- 基本的にはスペルミスなどわずかな違いがあるものしか検知できない
- インデックスを用意するなどの事前計算がしにくい
- 複数フィールドを比較する場合、重みづけなど定義が難しい
-
ベクトル空間ベースの類似度
cosine similalityなどが該当します。
ただ上記の特徴量などがベクトルとして抜き出せているので、
そのまま機械学習なり・検索エンジンに使ったほうが確実かと思われます。
わざわざベクトル空間ベース類似度に変換するメリットは、計算量・メモリ量の削減以外あまり思いつきません。
まとめ
機械学習・検索エンジンを使った名寄せで使われる特徴量をまとめてみました。
もちろんどの特徴量の組み合わせがいいかは、
データやアルゴリズムに依存するのでそのたびに試してみる必要があります。
参考文献
- Mudgal, S., Li, H., Rekatsinas, T., Doan, A., Park, Y., Krishnan, G., … Park, Y. (2018). Deep Learning for Entity Matching: A Design Space Exploration, 16. https://doi.org/10.1145/3183713.3196926
- Bilenko, M., Kamath, B., & Mooney, R. J. (2006). Adaptive blocking: Learning to scale up record linkage. In Proceedings - IEEE International Conference on Data Mining, ICDM (pp. 87–96). https://doi.org/10.1109/ICDM.2006.13
- Kooli, N., Allesiardo, R., & Pigneul, E. (2018). Deep learning based approach for entity resolution in databases, 10752(January). https://doi.org/10.1007/978-3-319-75420-8
- Clustering In Depth · OpenRefine/OpenRefine Wiki
- Febrl - Freely extensible biomedical record linkage
- Konda, P., Das, S., Suganthan, P., Doan, A., Ardalan, A., Ballard, J. R., … Raghavendra, V. (2150). Magellan: Toward Building Entity Matching Management Systems. Retrieved from http://www.vldb.org/pvldb/vol9/p1197-pkonda.pdf
- Winkler, W. E. (2006). Overview of record linkage and current research directions. Current, (2006–2), 1–28. https://doi.org/10.1206/3728.2