概要
「Qiita夏祭り」、「機械学習を使って、データから予測モデルを作って使おう!」の記事です。
👇コチラも読んでください!
DataRobotによるAutoML超入門
本記事は機械学習超入門として、PyCaretとGoogle Colaboratoryを使って、比較的少ない準備、コード量で機械学習を試す方法について紹介します。
今日、自動機械学習(AutoML)が開発されています。これにより、機械学習はコーディングや機械学習のスキルはなくても様々な人が今よりも低いハードルで利用できる技術になりつつあるかと思います。それゆえ、機械学習とはどんなものなのか、まずは簡単に触ってみたいという人も増えるかと思い、本記事を執筆しました。
※本記事を読みながら試してくださった方々へ。本記事はローコンテクストであるほど良いと思っています。わかりにくい表記や追記すべき内容などありましたら気兼ねなく編集リクエストや、コメントをしてくださると幸いです。🙇♂️
対象読者
とにかく機械学習を試してみたいと思っている以下のような方々を対象としています。
- 機械学習はなんとなく理解した
- とにかく使ってみたいが環境構築や例外でつまづきたくはない
- 細かいテクニックや応用については後回しでいい
- まずは予測モデルを生成して結果を出してみたい
PyCaret
機械学習において必要になるであろう、データの前処理、予測モデルの生成、評価などをたった数行のコードで実現させることができるPython言語のライブラリです。 分類、回帰、クラスタリング、異常検出、自然言語処理、アソシエーションルールマイニングを扱うことが可能です。コーディングのハードルが低く、プログラミングが苦手、未経験な方でも簡単に実践的な機械学習を試すことができます。このような点でAutoMLであるDataRobotとの類似点も多いです。DataRobotなどAutoML導入の検討のためにも利用してみてはいかがでしょうか。
しかし、利用しているPythonのバージョンなど環境によって、環境構築、導入についてつまずくこともちらほらあるかと思います。実際、自分もローカルの環境で試そうとしてつまずくことがありました。それゆえ、Google Colaboratoryでつまずく事なく試す方法を紹介します。
PyCaretとGoogle Colaboratoryによる機械学習
0. 前提
今回は、Kaggleで公開されているデータセットを用いて「タイタニックの生存者予測」を実施します。ラベルSurvivedに対して、正負の二値を分類します。
必要なもの
- Googleアカウント
- データセットのダウンロード
1. 準備
データの保存
Kaggleより取得した、今回扱うデータであるtrain.csv、test.csvをマイドライブ内に作成したdataというフォルダ内に保存します。
PyCaretのインストール
適当なノートブックを用意します。はじめに、PyCaretをインストールします。
! pip install pycaret
Google Driveのマウント
Google Driveをマウントします。これにより、ノートブックからGoogle Drive内のファイルの操作が可能となります。
from google.colab import drive
from google.colab import files
drive.mount("/content/drive")
実行後、出現するURLにアクセスし、authorization codeを取得してください。そして、Enter your authorization code:以下の入力欄にペーストしてエンターを押下してください。これによりマウントが完了します。

Mounted at /content/driveと出力されていたらOK。
例えば、マイドライブ内のhoge.csvというファイルを選択したい場合のパスはdrive/My Drive/hoge.csvとなります。
今回扱うデータであるtrain.csv、test.csvをマイドライブ内に設けたColab Notebooks内のdataというフォルダ内に保存しました。この時、それぞれのパスは、drive/My Drive/Colab Notebooks/data/train.csv、drive/My Drive/Colab Notebooks/data/test.csvとなります。
2. データの読み込み・確認
まずはー型式でトレーニングデータを読み込みます。中身を確認したところ、予測を試みる正解データの名前はSurvivedであることがわかります。
import pandas as pd
train_data = pd.read_csv("drive/My Drive/Colab Notebooks/data/train.csv")
train_data.head()

3. 前処理
setup()を利用して、データの前処理を行います。今回は分類を行うためpycaret.classificationをimportします。その時、目的変数を引数targetでSurvivedと指定します。以下を実行し、質問に答えるだけで、少なくとも予測モデルの生成に必要な最低限の前処理が完了します。
from pycaret.classification import *
exp_clf101 = setup(data = train_data, target = "Survived", session_id = 123)
データ型の解釈が表示されます。問題ない場合はエンターを押下すると実行が進みます。問題ある場合は、引数による明示的な設定が必要です。入力欄にquitと入力して実行を止めてください。

前処理の結果の詳細が表示されます。

(今回は省略していますが、項目は41までありました。)
4. 予測モデルの比較
compare_models()で、データセットを複数の予測モデルを用いて分析を行い、その結果を表として出力します。予測モデルの選択をするさい、役に立つ機能です。PyCaret version 1.0.0が提供する予測モデルは14種類です。下記のリンクで確認が可能です。
compare_models()

黄色のハイライトを受けている部分がその評価値における最も優れた予測モデルを差します。
5. 予測モデルの生成
create_model()により予測モデルを生成します。今回は、Kaggleなどでも利用される頻度の高い予測モデルであるLightGBMを利用します。
利用したい予測モデルとその引数の文字列との対応は以下より確認してください。
model = create_model("lightgbm")
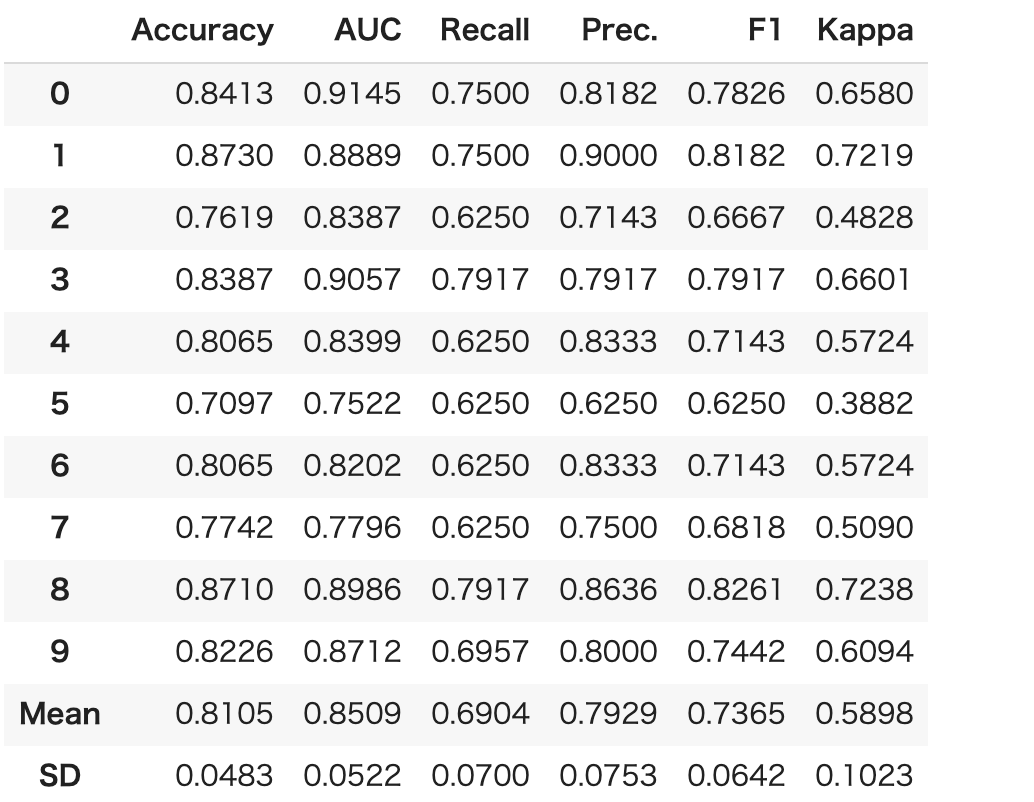
6. 予測モデルの評価
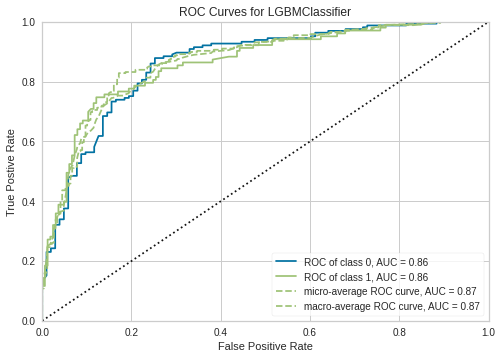
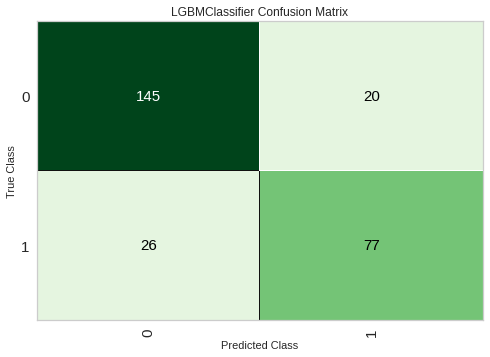
evaluate_model()を使い、同時に複数の評価値の確認が可能です。本来、クロスバリデーションなどによりテストデータを分割する作業が必要ですが、PyCaretはそこも勝手にやってくれます。
evaluate_model(model)
以下より、可視化したい評価値を選択できます。
AUCを選択した場合

Confusion Matrixを選択した場合

Precision Recallを選択した場合

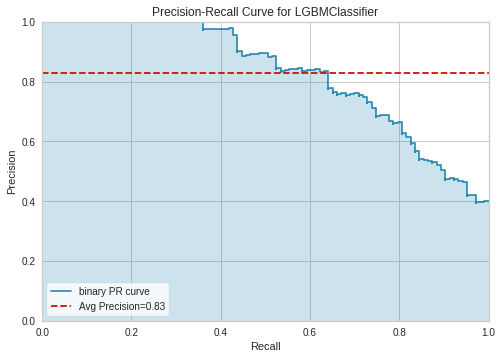
7. 予測
finalize_model()で予測モデルをFinalizeした後、predict_model()で予測します。
予測の時には、テストデータ(ここでは、test.csv)を使います。
final_model = finalize_model(model)
data_unseen = pd.read_csv("drive/My Drive/Colab Notebooks/data/test.csv")
result = predict_model(final_model, data = data_unseen)
元の内容に対して、LabelとScoreという予測結果に関する列が追加されています。
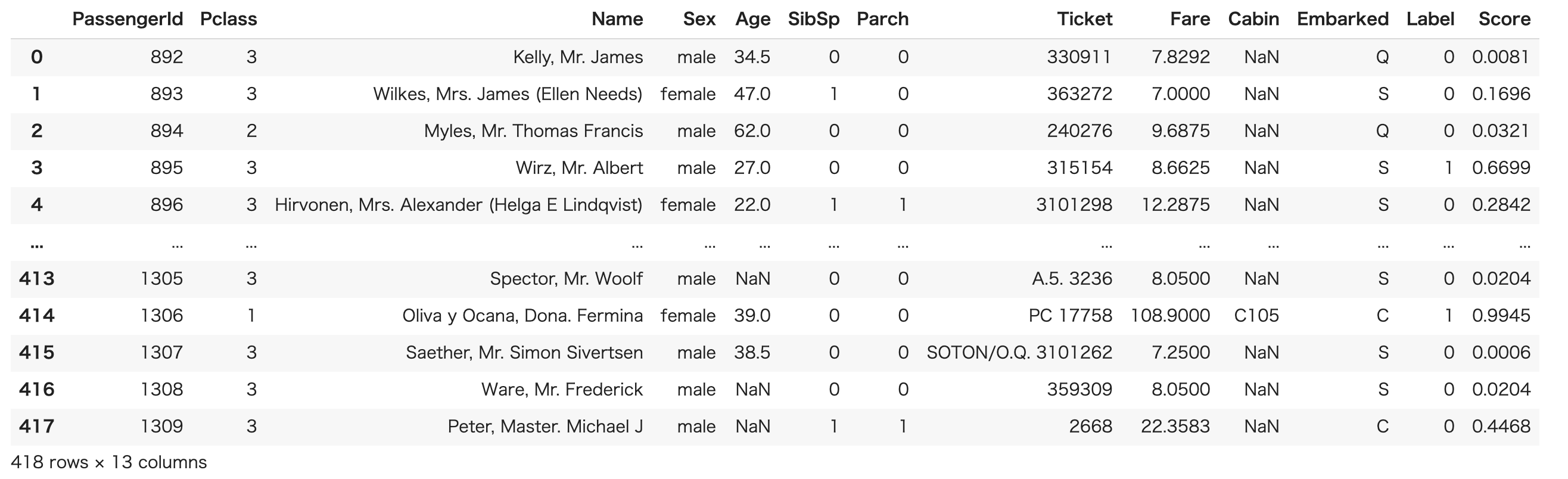
Kaggleなどのコンペでは最終的に出力するファイルの形が決められていることがほとんどです。出力結果からPassengerIdと予測値であるLabelをSurvivedに置換してcsvとして出力する例を以下に示します。
result[["PassengerId", "Label"]].rename(columns={"Label": "Survived"}).to_csv("drive/My Drive/Colab Notebooks/data/submit.csv", index=False)
まとめ
タイタニック生存予測のデータセットを利用し、PyCaretとGoogle Colaboratoryによる機械学習超入門を紹介しました。機械学習へのハードルを低く感じていただけたら幸いです。
(2020年07月01日追記)
以下の記事に掲載していただきました!ありがとうございます!
- Python記事まとめ(毎日自動更新)(2020年07月01日 00時00分更新 )
おまけ
a.前処理時にカテゴリ変数と量的変数を明示的に指定する方法
cat_features = ["Pclass","Name", "Sex", "SibSp", "Parch", "Ticket", "Cabin", "Embarked"]
num_features = ["Age", "Fare"]
from pycaret.classification import *
exp_titanic = setup(data = train_df, target = "is_canceled", session_id = 123, categorical_features=cat_features, numeric_features = num_features)
b. 予測モデルをチューニングする方法
tuned_model = tune_model("lightgbm")
c. アンサンブルをする方法
決定木をバギング
dt = create_model("dt")
dt_bagged = ensemble_model(dt, method = "Bagging")
決定木をブースティング
dt = create_model("dt")
dt_boosted = ensemble_model(dt, method = "Boosting")
d. ブレンドをする方法
3つの予測モデルをブレンドさせた予測モデルblenderを生成
model1 = create_model("lightgbm")
model2 = create_model("rf")
model3 = create_model("xgboost")
blender = blend_models([model1, model2, model3])
全ての予測モデルをブレンドさせた予測モデルblend_allを生成
blend_all = blend_models()
e. スタッキングをする方法
model1 = create_model("lightgbm")
model2 = create_model("rf")
model3 = create_model("xgboost")
stacker = stack_models(estimator_list = [model2, model3], meta_model = model1)