はじめに
NVIDIA GPU(H200など)のメトリクスをInstanaで監視する際、Custom Dashboardを活用することで、GPU温度、電力使用量、メモリ使用量、GPU使用率などを一元的に可視化できます。
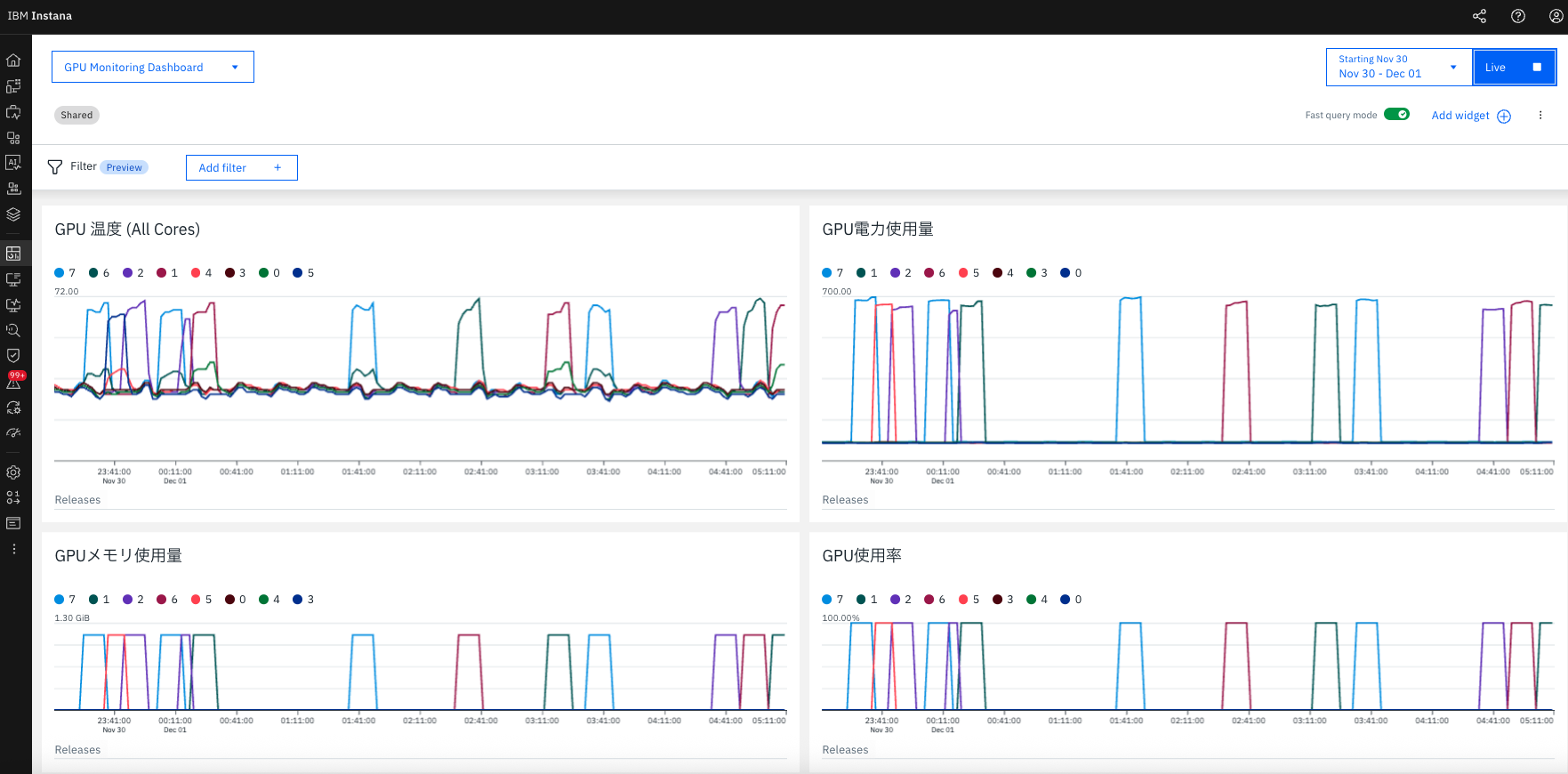
図: GPU Monitoring Dashboard - Load Test実行中の様子。GPU温度(左上)、電力使用量(右上)、メモリ使用量(左下)、GPU使用率(右下)の4つのWidgetで、全8コアのメトリクスをリアルタイム監視。GPU Core 7の温度が約68°C付近に達し、電力使用量は約700W、GPU使用率は100%に到達している。
本記事では、Instana UIを使用したCustom Dashboardの作成方法と、GPU Load Testによる動作確認、さらにダッシュボード設定のエクスポート・管理方法について解説します。
前提条件
以下が事前に設定されていることを前提とします。
- Kubernetes クラスター に NVIDIA GPU Operator がインストール済み
- DCGM Exporter が稼働中(GPU メトリクスを収集)
- OpenTelemetry Collector が DCGM Exporter からメトリクスを取得し、Instana にデータを送信
- Instana で oTelDcgm エンティティタイプが確認できる
1. Custom Dashboard の作成
ステップ1: ダッシュボード作成画面を開く
Instana UIでCustom Dashboardを新規作成します。
- Instana UI にログイン
- 左メニューから Dashboards → Custom Dashboards を選択
- 右上の + Create Dashboard ボタンをクリック
ステップ2: ダッシュボード名を設定
ダッシュボードの基本情報を設定します。
- ダッシュボード名を入力(例:
GPU Monitoring Dashboard) - Create をクリック
これで空のダッシュボードが作成され、Widget追加の準備が整います。
ステップ3: Widget を追加
以下の4つのWidgetを順番に追加します。各Widgetで全8コアのGPUメトリクスを可視化します。
Widget 1: GPU 温度 (All Cores)
GPU温度は、過熱によるパフォーマンス低下やハードウェア障害を防ぐために最も重要なメトリクスです。
作成手順:
- + Add Widget をクリック
- Chart: time series を選択
- 以下のように設定:
| 項目 | 設定値 |
|---|---|
| Title | GPU 温度 (All Cores) |
| Data Source | Infrastructure & Platforms |
| Entity Type |
oTel dcgm を検索して選択 |
| Metric |
OTel GPU > GPU temperatureまたは metrics.gauges.DCGM_FI_DEV_GPU_TEMP
|
| Aggregation |
max ※瞬間的な温度スパイクを検出するため |
| Group by |
Other > metric.tag.gpu を選択Top 10 を All に変更 ※全8コアを表示 |
- Save をクリック
重要ポイント:
- Aggregation: max を使用することで、60秒間の最高温度を検出し、瞬間的な温度スパイクを見逃さない
- Group by: metric.tag.gpu (All) で全8コア(Core 0-7)を個別に表示
Widget 2: GPU 電力使用量
GPU電力使用量は、ワークロードの負荷状況を把握するための重要な指標です。
作成手順:
- + Add Widget をクリック
- Chart: time series を選択
- 以下のように設定:
| 項目 | 設定値 |
|---|---|
| Title | GPU電力使用量 |
| Data Source | Infrastructure & Platforms |
| Entity Type | oTel dcgm |
| Metric |
OTel GPU > Power usageまたは metrics.gauges.DCGM_FI_DEV_POWER_USAGE
|
| Aggregation | max |
| Group by |
Other > metric.tag.gpu → All
|
- Save をクリック
期待される動作:
- Idle時: 低電力(各コア数十W)
- Load時: 約700W程度まで上昇(H200の場合)
Widget 3: GPU メモリ使用量
GPUメモリ使用量は、AI/MLワークロードでメモリ不足(OOM)を防ぐために監視が必要です。
作成手順:
- + Add Widget をクリック
- Chart: time series を選択
- 以下のように設定:
| 項目 | 設定値 |
|---|---|
| Title | GPUメモリ使用量 |
| Data Source | Infrastructure & Platforms |
| Entity Type | oTel dcgm |
| Metric |
OTel GPU > Frame buffer usedまたは metrics.gauges.DCGM_FI_DEV_FB_USED
|
| Aggregation | max |
| Group by |
Other > metric.tag.gpu → All
|
- Save をクリック
注意:
- メトリクス名は Frame buffer used または
DCGM_FI_DEV_FB_USED - 単位は自動的にMBまたはGBで表示されます
Widget 4: GPU 使用率
GPU使用率は、GPUコアの実行時間の割合を示し、ワークロードの効率を評価します。
作成手順:
- + Add Widget をクリック
- Chart: time series を選択
- 以下のように設定:
| 項目 | 設定値 |
|---|---|
| Title | GPU使用率 |
| Data Source | Infrastructure & Platforms |
| Entity Type | oTel dcgm |
| Metric |
OTel GPU > GPU utilizationまたは metrics.gauges.DCGM_FI_DEV_GPU_UTIL
|
| Aggregation | max |
| Group by |
Other > metric.tag.gpu → All
|
- Save をクリック
期待される動作:
- Idle時: 0%
- 軽負荷: 10-50%
- 高負荷(PyTorch/TensorFlowなど): 90-100%
ステップ4: レイアウト調整
4つのWidgetを追加したら、ドラッグ&ドロップで配置を調整します。
推奨レイアウト(2行×2列):
+---------------------------+---------------------------+
| GPU 温度 (All Cores) | GPU電力使用量 |
| Width: 6, Height: 17 | Width: 6, Height: 17 |
+---------------------------+---------------------------+
| GPUメモリ使用量 | GPU使用率 |
| Width: 6, Height: 13 | Width: 6, Height: 13 |
+---------------------------+---------------------------+
レイアウトのポイント:
- 温度と電力を上段に配置(最も重要なメトリクス)
- メモリと使用率を下段に配置
- 各Widgetの高さを調整し、視認性を向上
これでダッシュボードの作成が完了しました。
2. ダッシュボード設定のエクスポート
作成したダッシュボードの設定をJSON形式でエクスポートし、バージョン管理やバックアップに活用できます。
エクスポート手順
- ダッシュボード画面右上の Options (⋮) をクリック
- Edit as JSON を選択
- 表示されたJSON全体をコピー
- ファイルに保存(例:
gpu-monitoring-dashboard.json)
JSON のバージョン管理
エクスポートしたJSONファイルをGitなどのバージョン管理システムで管理することで、以下のメリットがあります。
# JSONファイルとして保存
cat > gpu-monitoring-dashboard.json <<EOF
{
"title": "GPU Monitoring Dashboard",
"rbacTags": [],
"accessRules": [
{
"accessType": "READ_WRITE",
"relationType": "USER",
"relatedId": "<your-user-id>"
},
{
"accessType": "READ",
"relationType": "GLOBAL",
"relatedId": ""
}
],
"widgets": [
... (エクスポートしたWidget設定)
]
}
EOF
# Gitでバージョン管理
git add gpu-monitoring-dashboard.json
git commit -m "Add GPU Monitoring Dashboard configuration"
git push
バージョン管理のメリット:
- ダッシュボード設定の変更履歴を追跡
- 複数環境(開発・検証・本番)への展開が容易
- チーム内での設定共有
- Infrastructure as Code (IaC) の一部として管理
JSON を使った復元・複製
エクスポートしたJSONは、別のInstana環境や同じ環境内で複製する際に利用できます(ただし、現時点ではAPI経由での作成に制限がある場合があるため、UI上での手動インポートを推奨します)。
3. GPU Load Test による動作確認
ダッシュボードが正しく動作するか、GPU Load Test を実行して確認します。
GPU Stress Test Pod の作成
以下のYAMLファイルを作成します。
# gpu-pytorch-stress.yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pytorch-stress
namespace: gpu-observe
spec:
restartPolicy: Never
containers:
- name: pytorch-gpu-stress
image: pytorch/pytorch:latest
command: ["/bin/bash", "-c"]
args:
- |
pip install torch
python -c "
import torch
import time
print('Starting GPU stress test...')
device = torch.device('cuda')
for i in range(60): # 10分間実行
a = torch.randn(5000, 5000, device=device)
b = torch.randn(5000, 5000, device=device)
c = torch.matmul(a, b)
time.sleep(10)
print(f'Iteration {i+1}/60 completed')
print('GPU stress test completed')
"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
kubernetes.io/hostname: <your-gpu-node-name>
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
設定のポイント:
- matrix multiplication (5000x5000): GPU負荷を生成
- 10分間実行: ダッシュボードでの変化を十分に観察可能
-
namespace:
gpu-observeを使用(環境に応じて変更) - nodeSelector: GPU搭載ノードを指定
デプロイと確認
# Load Test 実行
kubectl apply -f gpu-pytorch-stress.yaml
# ログ確認
kubectl logs -f gpu-pytorch-stress -n gpu-observe
Instana Dashboard で確認すべきポイント:
冒頭の画像のように、以下のメトリクス変化を確認できます。
-
GPU温度: 30°C(Idle) → 60°C以上(Load時)に上昇
- 特定のコア(例: Core 7)が他よりも高温になる場合がある
- 68°C程度まで上昇する可能性あり
-
GPU電力使用量: Idle時の低電力 → 約700W程度に上昇
- H200では最大700W程度の電力消費
-
GPU使用率: 0% → 100%に上昇
- PyTorchの行列演算により、GPUが完全に使用される
-
GPUメモリ使用量: ベースライン → 使用量増加
- 5000x5000行列を格納するためメモリ使用量が増加
-
全8コアが個別のラインで表示
- どのコアが負荷を受けているかを識別可能
Load Test終了後:
Load Testが完了すると、約60秒後(Grace Period)にメトリクスがIdle状態に戻ります。この自動回復も確認してください。
4. 継続的な GPU Load Test(6時間)
長時間の監視動作を確認するため、6時間の継続的なLoad Testを実行できます。これにより、以下を検証できます。
- GPU温度の周期的な変動パターン
- 長時間稼働時の安定性
- アラートの自動回復動作
6時間Load Testスクリプト
#!/bin/bash
# gpu-stress-loop-6hours.sh
END_TIME=$((SECONDS + 21600)) # 6時間 = 21600秒
ITERATION=0
echo "Starting 6-hour GPU stress test loop..."
echo "End time: $(date -d @$(($(date +%s) + 21600)) '+%Y-%m-%d %H:%M:%S')"
while [ $SECONDS -lt $END_TIME ]; do
ITERATION=$((ITERATION + 1))
ELAPSED=$((SECONDS))
REMAINING=$((END_TIME - SECONDS))
echo "=========================================="
echo "Iteration: ${ITERATION}"
echo "Elapsed: $((ELAPSED / 60))m / Remaining: $((REMAINING / 60))m"
echo "=========================================="
# 既存Podを削除
kubectl delete pod gpu-pytorch-stress --ignore-not-found=true
sleep 5
# 新しいPodをデプロイ
kubectl apply -f gpu-pytorch-stress.yaml
# Podが完了するまで待機
kubectl wait --for=condition=Ready pod/gpu-pytorch-stress --timeout=120s 2>/dev/null
kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-pytorch-stress --timeout=15m 2>/dev/null
# ログ確認
echo "Last log entries:"
kubectl logs gpu-pytorch-stress 2>/dev/null | tail -n 5
# Cooldown期間(GPUを冷却)
echo "Cooldown: 120s"
sleep 120
done
echo "6-hour GPU stress test completed!"
実行方法
# スクリプトに実行権限を付与
chmod +x gpu-stress-loop-6hours.sh
# バックグラウンド実行
nohup bash gpu-stress-loop-6hours.sh > gpu-stress-test.log 2>&1 &
# プロセスIDを確認
echo $! > gpu-stress-test.pid
# ログ確認
tail -f gpu-stress-test.log
# 停止する場合
kill $(cat gpu-stress-test.pid)
期待される動作
6時間のLoad Test実行により、Instana Dashboardで以下のパターンを観察できます。
GPU温度のトレンド:
- 各Iteration開始時: 30°C → 60°C以上に上昇
- Iteration終了後のCooldown: 60°C以上 → 30°Cに下降
- 約12分周期(10分Load + 2分Cooldown)で繰り返し
自動回復の確認:
- GPU温度が60°Cを超えた際のAlert発火
- Cooldown期間後の自動回復(Alert Close)
- 約30回のサイクルで安定性を確認
5. ダッシュボードの活用
作成したダッシュボードは以下の用途で活用できます。
リアルタイム監視
- 全8コアの状態を一画面で監視: 各GPUコアの温度、電力、メモリ、使用率を同時に確認
- 負荷テスト中の挙動確認: AI/MLワークロード実行時のリソース使用状況を把握
- 異常なGPUコアの特定: 特定コアだけ温度が高い、使用率が低いなどの異常を検出
活用例:
- PyTorch/TensorFlowトレーニング中のGPU状態監視
- モデル推論時のパフォーマンス分析
- 複数ジョブ実行時のGPUリソース割り当て確認
パフォーマンス分析
- ボトルネック特定: メモリ不足、温度制限(Thermal Throttling)、低使用率などを識別
- 複数GPUコア間の負荷バランス確認: 8コアが均等に使用されているかを確認
- 電力効率の評価: ワークロードあたりの電力消費を分析
分析ポイント:
- GPU使用率が100%でもメモリ使用量が低い場合、メモリバインドではなくComputeバインド
- 温度が70°C以上で使用率が低下する場合、Thermal Throttlingの可能性
- 特定コアだけ使用率が低い場合、ワークロードの分散に問題
Alert 連携
GPU温度や電力使用量のCustom Eventと連携し、アラート発火時にダッシュボードで詳細を確認できます。
Alert設定例:
- GPU温度が70°Cを超過した場合にCritical Alert
- Alert発火時、ダッシュボードのURLを通知に含める
- どのGPUコアが原因かをダッシュボードで即座に特定
連携フロー:
$$\text{GPU温度上昇} \rightarrow \text{Custom Event発火} \rightarrow \text{Alert通知} \rightarrow \text{Dashboardで詳細確認}$$
まとめ
Instana Custom Dashboard を使用することで、NVIDIA GPU の複数メトリクスを統合的に可視化し、リアルタイム監視とパフォーマンス分析が可能になります。
本記事のポイント:
ダッシュボード作成:
-
Entity Type:
oTel dcgmの選択が必須 -
Aggregation: 温度・電力は
maxを推奨(瞬間的なスパイクを検出) -
Grouping:
metric.tag.gpuで全コアを表示(Top 10 → All に変更) - 4つのWidget: 温度、電力、メモリ、使用率で包括的に監視
設定管理:
-
JSON Export:
Options > Edit as JSONでバックアップ可能 - バージョン管理: Gitなどで設定を管理し、環境間での共有が容易
- Infrastructure as Code: ダッシュボード設定をコードとして管理
動作確認:
- GPU Load Test: PyTorchによる行列演算で負荷を生成
- メトリクス変化: 温度・電力・使用率の上昇を確認
- 長時間監視: 6時間の継続テストで安定性を検証
次のステップ:
作成したダッシュボードを基に、さらに以下の拡張が可能です。
- GPU Alert の設定: 温度、電力使用量の閾値アラート(例: 70°C以上でCritical)
- 他のGPUメトリクスの追加: SM Clock、PCIe Throughput、ECC Errorsなど
- SLO設定とダッシュボード連携: GPU可用性やパフォーマンスのSLO監視
- 複数ノードの統合監視: 複数のGPUノードを1つのダッシュボードで監視
Instana Custom Dashboardを活用することで、NVIDIA GPUの包括的な監視基盤を構築し、AI/MLワークロードの安定稼働とパフォーマンス最適化を実現できます。