はじめに
前回の記事「Instana API で NVIDIA GPU 温度アラートを一括作成」で、70°C閾値のGPU温度アラートを作成しましたが、PyTorch負荷テスト時も最大63°Cまでしか上がらず、アラートは発火しませんでした。
今回は、実際のアラート動作を検証するため、閾値を60°Cに調整して再テストを実施し、以下の項目を確認します:
- アラートの発火(60°C閾値で正常にトリガー)
- Instana UIでのイベント表示
- メトリクス推移の可視化
- 自動回復(Grace Period後のClose)
前提条件
本記事で使用する環境構成は以下の通りです。実際の環境に応じて適宜読み替えてください:
| 項目 | 記事での表記 | 説明 |
|---|---|---|
| Kubernetes Namespace | gpu-observe |
GPU監視用のNamespace(任意) |
| GPUノード | your-h200-gpu-node |
NVIDIA H200搭載ノードのホスト名 |
| DCGM Exporter | localhost:9400 |
DCGM Exporterのエンドポイント |
| Instana URL | https://<your-tenant>.instana.io |
InstanaテナントのURL |
| API Token | YOUR_API_TOKEN |
Instana API Token |
必要なコンポーネント:
- Kubernetes クラスタ(GPU搭載ノード含む)
- NVIDIA GPU Operator または NVIDIA Device Plugin
- DCGM Exporter(DaemonSet)
- OpenTelemetry Collector
- Instana SaaS または On-Premise
1. アラート閾値の調整(70°C → 60°C)
なぜ60°Cに変更したのか
- 実測温度: 負荷テスト時に最大63°C
- 70°C閾値では「無風」(アラート発火せず)
- 検証目的で一時的に60°Cに変更
Instana API(PUT)による一括更新
既存のアラートを更新するには、PUT メソッドを使用します:
#!/bin/bash
# update-all-gpu-alerts-to-60c.sh
INSTANA_URL="https://<your-tenant>.instana.io"
API_TOKEN="YOUR_API_TOKEN"
echo "=== Updating All GPU Temperature Alerts to 60°C ==="
for CORE in {0..7}; do
# 既存アラート情報を取得
ALERT_INFO=$(curl -s -H "Authorization: apiToken ${API_TOKEN}" \
"${INSTANA_URL}/api/events/settings/event-specifications/custom" \
| jq -r ".[] | select(.name == \"GPU Temperature - Core ${CORE} - Critical (Test: 70C)\")")
ALERT_ID=$(echo "$ALERT_INFO" | jq -r '.id')
if [ "$ALERT_ID" != "null" ] && [ -n "$ALERT_ID" ]; then
echo "Updating Core ${CORE} (ID: ${ALERT_ID})..."
# conditionValue を 60 に変更
UPDATED_PAYLOAD=$(echo "$ALERT_INFO" | jq \
--arg newName "GPU Temperature - Core ${CORE} - Critical (Test: 60C)" \
--arg newDesc "Test alert: GPU Core ${CORE} temperature >= 60C for validation" \
'.name = $newName | .description = $newDesc | .rules[0].conditionValue = 60')
# PUT リクエストで更新
UPDATE_RESULT=$(curl -s -X PUT \
-H "Authorization: apiToken ${API_TOKEN}" \
-H "Content-Type: application/json" \
"${INSTANA_URL}/api/events/settings/event-specifications/custom/${ALERT_ID}" \
-d "$UPDATED_PAYLOAD")
NEW_THRESHOLD=$(echo "$UPDATE_RESULT" | jq -r '.rules[0].conditionValue')
if [ "$NEW_THRESHOLD" == "60" ]; then
echo " Core ${CORE}: Successfully updated to 60°C"
else
echo " Core ${CORE}: Update failed"
fi
fi
done
echo ""
echo "=== Verification ==="
curl -s -H "Authorization: apiToken ${API_TOKEN}" \
"${INSTANA_URL}/api/events/settings/event-specifications/custom" \
| jq '.[] | select(.name | contains("GPU Temperature - Core")) |
{name: .name, threshold: .rules[0].conditionValue, aggregation: .rules[0].aggregation}'
更新結果の確認
スクリプト実行後、全8コア(Core 0-7)が以下の設定で更新されます:
{
"name": "GPU Temperature - Core 0 - Critical (Test: 60C)",
"threshold": 60,
"aggregation": "max"
}
2. GPU負荷テストの実施
テスト環境
- GPU: NVIDIA H200 × 8コア
- 負荷テスト: PyTorch 5000x5000行列演算
- 実行時間: 約10分間
-
Namespace:
gpu-observe
gpu-pytorch-stress.yaml の作成
apiVersion: v1
kind: Pod
metadata:
name: gpu-pytorch-stress
namespace: gpu-observe # 環境に応じて変更
spec:
restartPolicy: Never
containers:
- name: pytorch-stress
image: pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime
command: ["/bin/bash", "-c"]
args:
- |
pip install -q numpy
python3 << 'EOF'
import torch
import time
from datetime import datetime
print("=" * 60)
print("Starting GPU stress test...")
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
device = torch.device("cuda:0")
print(f"GPU device: {torch.cuda.get_device_name(0)}")
print("=" * 60)
matrix_size = 5000
duration_seconds = 600
start_time = time.time()
iteration = 0
print(f"\nRunning matrix multiplication ({matrix_size}x{matrix_size}) for {duration_seconds} seconds...")
while (time.time() - start_time) < duration_seconds:
a = torch.randn(matrix_size, matrix_size, device=device)
b = torch.randn(matrix_size, matrix_size, device=device)
c = torch.matmul(a, b)
torch.cuda.synchronize()
iteration += 1
if iteration % 100 == 0:
elapsed = time.time() - start_time
print(f"[{datetime.now().strftime('%H:%M:%S')}] Iteration {iteration} | Elapsed: {elapsed:.1f}s")
print(f"\n{'=' * 60}")
print(f"Stress test completed!")
print(f"Total iterations: {iteration}")
print(f"Total time: {time.time() - start_time:.1f}s")
print(f"{'=' * 60}")
else:
print("ERROR: CUDA is not available!")
exit(1)
EOF
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
nodeSelector:
kubernetes.io/hostname: your-h200-gpu-node # 環境に応じて変更
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
デプロイと監視
デプロイコマンド:
# 環境変数で Namespace を設定
export NAMESPACE="gpu-observe"
# 既存Podの削除(存在する場合)
kubectl delete pod gpu-pytorch-stress -n $NAMESPACE 2>/dev/null
# GPU負荷テストPodのデプロイ
kubectl apply -f gpu-pytorch-stress.yaml
# ログをリアルタイムで確認
kubectl logs -f gpu-pytorch-stress -n $NAMESPACE
期待されるログ出力:
============================================================
Starting GPU stress test...
PyTorch version: 2.1.0+cu118
CUDA available: True
GPU device: NVIDIA H200
============================================================
Running matrix multiplication (5000x5000) for 600 seconds...
[03:35:20] Iteration 100 | Elapsed: 30.2s
[03:36:20] Iteration 200 | Elapsed: 90.8s
[03:37:20] Iteration 300 | Elapsed: 151.4s <- この辺りで60°C超え
...
リアルタイム温度監視(別ターミナル):
# 方法1: SSH接続
ssh user@gpu-node
watch -n 2 'curl -s http://localhost:9400/metrics | grep "DCGM_FI_DEV_GPU_TEMP{gpu=" | grep -v "^#"'
# 方法2: Kubernetes port-forward(推奨)
kubectl port-forward -n gpu-observe daemonset/dcgm-exporter 9400:9400
# 別ターミナルで温度監視
watch -n 2 'echo "=== $(date +"%H:%M:%S") ===" && \
curl -s http://localhost:9400/metrics | \
grep "DCGM_FI_DEV_GPU_TEMP{gpu=" | grep -v "^#" | \
awk -F"gpu=\"" "{core=substr(\$2,1,1); temp=\$NF; \
printf \"GPU %s: %3s C\", core, temp; \
if (temp >= 60) printf \" <- ALERT\"; print \"\"}" | sort -V'
3. アラート発火の確認
Instana UIでの確認
-
Instana UIにアクセス:
https://<your-tenant>.instana.io -
Eventsページに移動: 左メニュー >
Events -
フィルター設定:
-
Severity:
Critical -
State:
Open -
Time Range:
Last 15 minutes -
Search:
GPU TemperatureまたはTest: 60C
-
Severity:
Event詳細
- Event Name: GPU Temperature - Core 7 - Critical (Test: 60C)
- Started: 2025-12-01, 03:37:20 AM
- Ended: 2025-12-01, 03:38:20 AM
- Duration: 1m
- Severity: Critical
- State: Closed
- GPU Core: 7
- Peak Temperature: 68°C
スクリーンショット
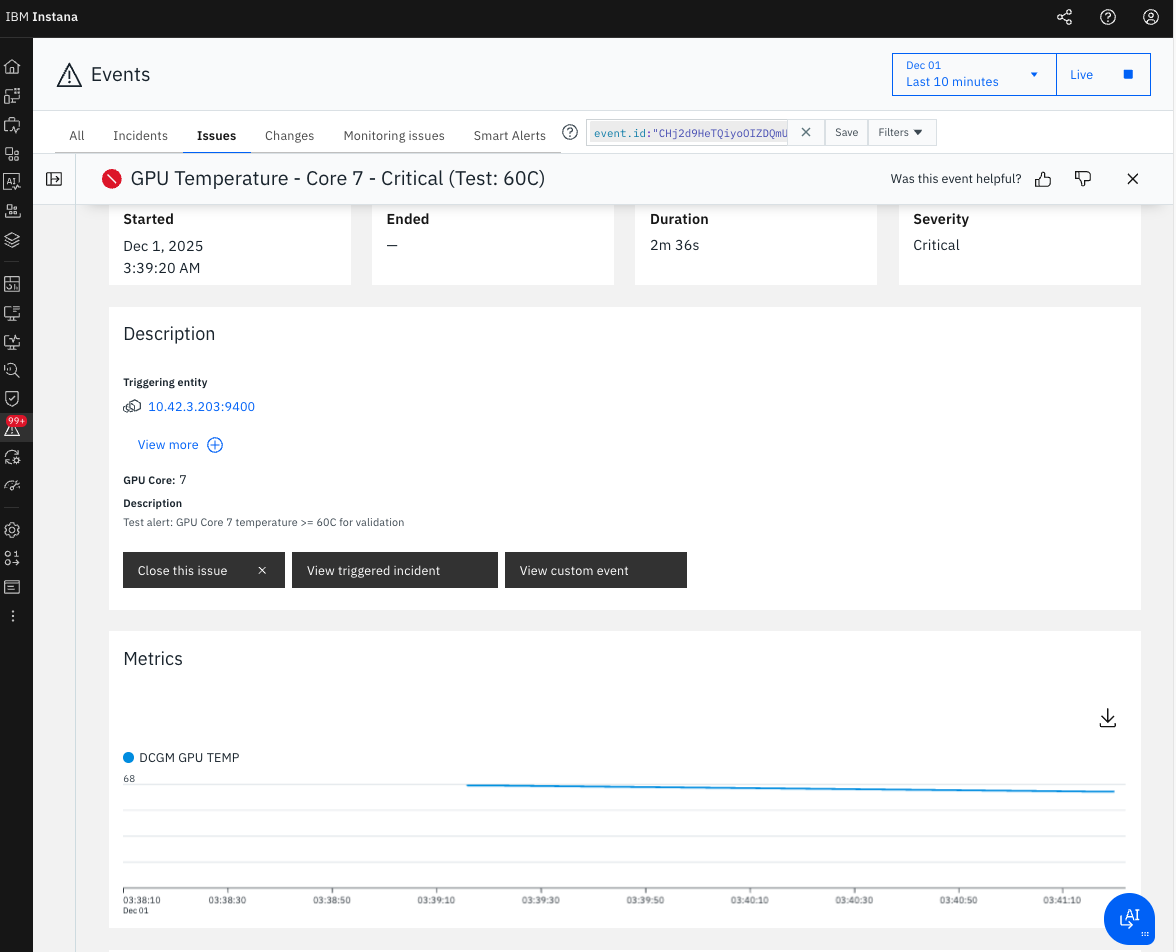
図1: GPU Temperature - Core 7のアラート詳細
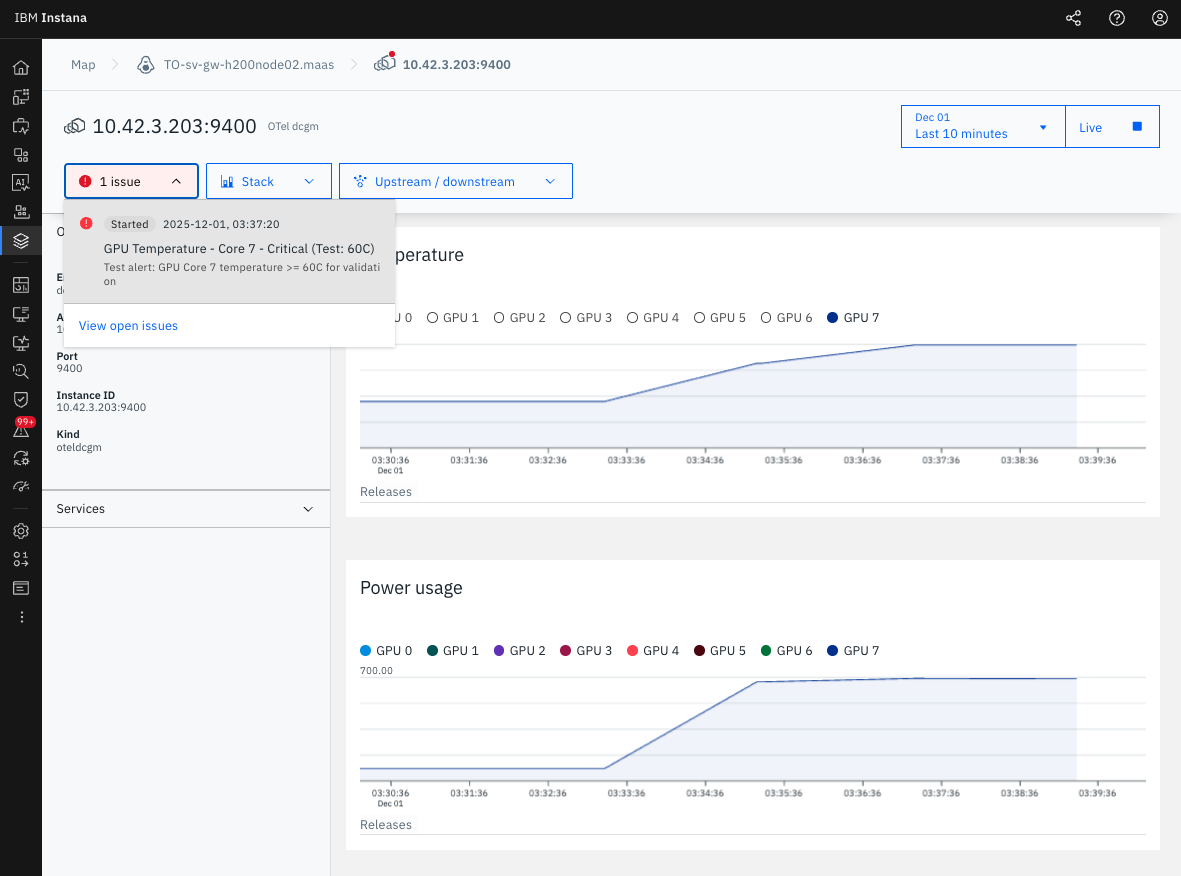
図2: GPU Core 7の温度推移(68°Cまで上昇)
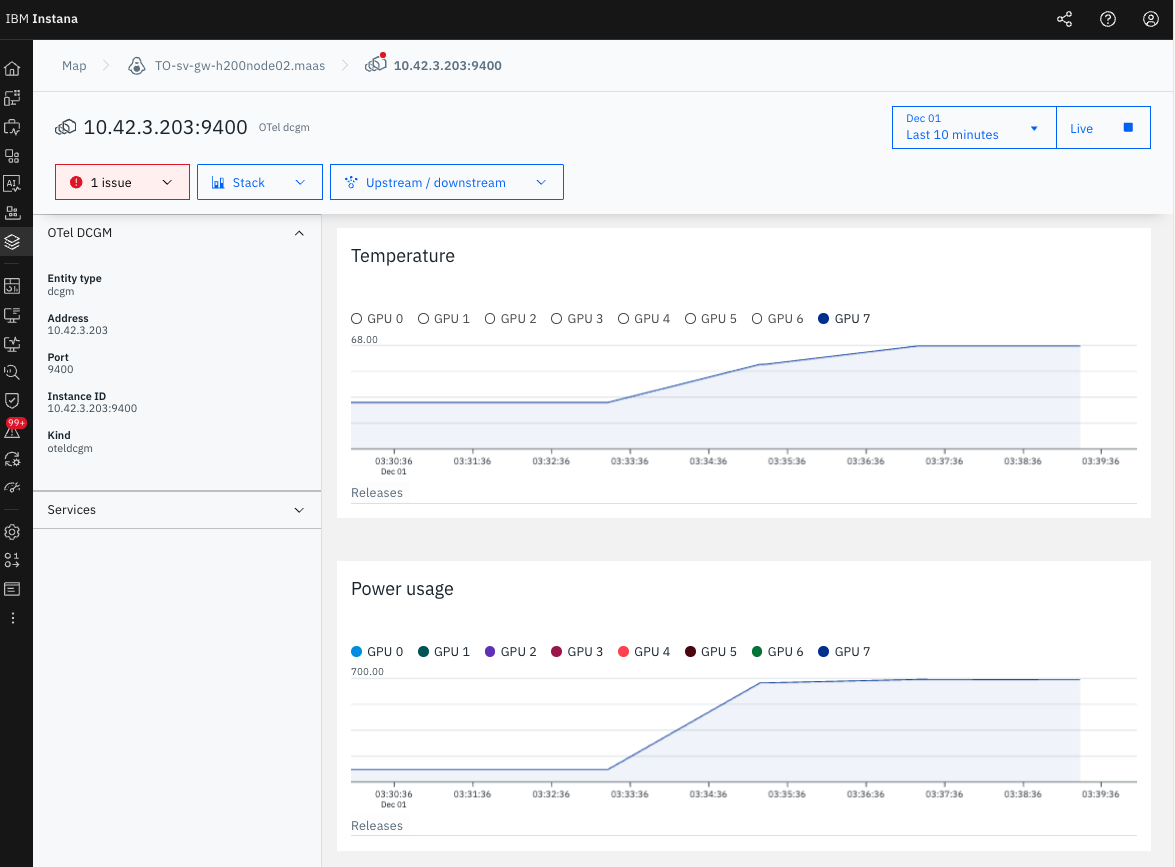
図3: GPU Core 7の電力使用量推移
4. 自動回復の検証
Pod削除による負荷テスト停止
kubectl delete pod gpu-pytorch-stress -n gpu-observe
自動回復プロセス
- GPU温度が60°C未満に低下
- Grace Period(60秒)経過
- アラートのStateが
Open→Closedに自動変更 - Duration: 1m(正確に60秒後にClose)
確認されたポイント
- アラートは自動的に回復(手動操作不要)
- Grace Period(
expirationTime: 60000)が正常動作 - Instana UIに
Closed状態で履歴が残る
5. 学習ポイント
今回の検証を通じて学んだ重要なポイントを4つにまとめます。
5-1. 実測データに基づく閾値設定
アラートの閾値は環境の実測データに基づいて設定する必要があります。今回、最初に70°Cで設定しましたが実際は63°Cまでしか上がらず、アラートは発火しませんでした。検証目的で60°Cに変更したところ、68°Cまで上昇してアラートが正常に発火しました。
ポイント:
- まず負荷テストで実測してから適切な閾値を設定する
- Instana APIを使えば、後から柔軟に閾値を変更可能
5-2. aggregation は必ず max を使用
Instanaは60秒間のGPU温度データを集約してアラート判定を行います。温度監視では必ず aggregation: max(最大値)を使用してください。
| 集約方法 | 60秒間: 55°C, 58°C, 62°C, 60°C | 判定値 | 結果 |
|---|---|---|---|
| max | 最大値 | 62°C | 瞬間的なスパイクも検出 |
| avg | 平均値 | 58.75°C | スパイクを見逃す可能性 |
| sum | 合計値 | 235°C | 温度監視では無意味 |
ポイント:
- 一瞬でも危険な温度に達したら検知する必要があるため
maxを使用 -
avgやsumは温度監視には不適切
5-3. Metric Patternで個別GPU Coreを監視
metricPattern.placeholder を使用することで、各GPU Coreを個別に監視できます。今回のテストではGPU Core 7だけが68°Cまで上昇し、他のコア(0-6)は30°C台のままでした。個別監視により、問題のあるコアを即座に特定できました。
metricPattern:
prefix: "DCGM_FI_DEV_GPU_TEMP"
placeholder: "7" # Core 7 を個別に監視
operator: "is"
ポイント:
- 8コア全体ではなく、問題のあるコアだけアラートが発火
- トラブルシューティングが迅速に行える
5-4. APIによる一括変更の効率性
Instana UIで8コア分のアラートを手動変更すると時間がかかり、ミスも発生しやすくなります。Instana APIの PUT /api/events/settings/event-specifications/custom/{id} を使用すれば、全8コアの閾値を数秒で一括変更できます。
ポイント:
- 複数のアラート設定を一括で変更可能
- 手作業によるミスを防ぎ、設定の一貫性を保てる
- Infrastructure as Code (IaC) として管理可能
6. まとめ
Instana APIで作成したGPU温度アラートが、以下の点で正常に動作することを確認しました:
- 60°C閾値でアラートが正常に発火
- GPU Core 7が68°Cまで上昇し、アラートトリガー
- Grace Period(60秒)後に自動回復
- Instana UIで詳細なイベント履歴とメトリクス推移を確認可能
- 個別GPU Coreの特定が可能(Core 7のみアラート)
次のステップ
- Alert Channel設定 - Email/Slack通知の追加
- 他のメトリクス監視 - GPU使用率、メモリ、電力消費
- 本番環境への適用 - 閾値を適切な値に設定して運用開始