yolov5を使う上で自分が調べた事、理解した挙動、実装方法(学習から実装)、ラベリングの方法について纏めます。
学習データの用意から学習、そして目的の機材に実装するまでを全てセットで行う事となっています。その上で必要だった一連の流れを纏めます。
本稿は
・前準備としてのライブラリの準備
・学習データの用意
・学習、検証、テスト
・ラベリングの半自動化
・リアルタイム検出をする際の座標の取得出力及びjetson nanoへの実装
以上を纏めています。
環境(pc)
OS: macOS Catalina 10.15.7
Pythonバージョン: 3.9.7
環境(実装機材)
jetson nano b01 (4gbモデル)
os: ubuntu20.04
Python: 3.8.10
前準備としてのライブラリの準備
pythonでライブラリを使う知識があるという事を前提に進めます。
本項では以降の作業にも使ったライブラリの中で最低限必要と思う物、ピックアップします。
labelimg

ラベリングを行うソフトです。
pip install labelimg
でインストールできます。githubはこちら。pip以外でインストールする場合はgithub上の説明をご覧ください。
labelimg
以降は上のコマンドでshell、ターミナル、コマンドプロンプト上から起動します。
PIL
pip install Pillow
画像処理用ライブラリです。「学習データの用意」で使用します。
今回の用途として画像の反転といったデータ拡張を行うために使用します。画像を希望の方向に反転できれば良いだけなので、慣れた別の方法がある場合はそちらをご検討ください。コードは載せておきます。
他の方法としてnumpyやopencvなどを使う方法もあります。
Pytorch
機械学習用ライブラリです。詳しく無いため割愛。
https://pytorch.org/ よりインストール用のコードを作成してください。
サイトを開いて出てくる状態のRun this Commandをコピーすれば良いと思います。ここはos、使用しているpython環境などで変わるので私の画面とは違うという方もいるかと思います。
opencv
pilと同じく画像処理系のライブラリです。重たいし時間かかるしで代用する方法があれば各々の判断に任せます。用途は動画をフレーム単位に分割するためです。
yolov5のインストール
の前にultralyticsを
pip install ultralytics
でインストールしてください。私もあまり理解していませんがgoogle colaboratoryを用いyolov5を使用した時に求められたので。
yolov5のgithubは上より。
git clone https://github.com/ultralytics/yolov5
gitコマンドを使用しローカルリポジトリにダウンロードしていますが、gitを導入していない場合はgithubのサイトからダウンロードするなりwgetなりで一式をダウンロードしてください。
cd yolov5
pip install -r requirements.txt
ダウンロードが終わればyolov5のディレクトリに移動しインストールします。
余談ですが、yolov5で学習する際はgoogle colaboratoryでもインストールしておくと良いでしょう。https://colab.research.google.com/
google colaboratoryって何という方は自分で詳しく調べてください。軽く説明するとオンラインで使えるipynb環境です。無料でもGPUを使用できるため私は機械学習、とりわけ物体検出で学習モデルを出力して使用しています。私のようにパソコンがgpu内蔵cpuといった貧弱なグラフィック性能の場合学習には相当な時間を要します。そういった場合に少し性能が高いgpuを使用して計算時間を削減しています。
話がそれましたが以上で事前準備完了です。
学習データの用意
ここから学習データの準備となります。
学習セットの数は各々の判断に任せます。私が使用した際は1クラスのみの検出で画像を170枚用意しました。またこの画像を左右反転させ340枚にデータ拡張した写真を学習用、検証用に使用しました。
本来機械学習では学習、検証、テストに分けてデータを使用します。
https://collab-it.net/2018/08/1536/
いくつかデータ分割の手法はあるようですが、今回は学習に元画像の1~128枚目と反転させた画像43~170枚目の計256枚、検証に元画像の128~170枚目と反転させた画像1~128枚目の計256枚を利用しました。実装を急いでいたこともあり、テスト用は後日撮影すれば良いという考えでここではテストに回していません。
labelimgの使用
labelimg
起動します。
色々ありますが使っているうちに分かると思います。
画像にラベル付けを施すにはまずopenかopen dirを選択します。画像が一枚や二枚、或いは特定の物に限る場合はopen、あるディレクトリに入っている画像一式を開きたい場合はopen dirを選択すると良いでしょう。

都合により既にラベリングの完了している物を出しますが、最初はこのボックスが何も表示されていない状態で始まります。解説のため途中経過が可能な限り分かるように努力します。open dirを選択するとFile listのようにずらりとディレクトリ内の画像が並んでいるのが分かると思います。今回「柱」1クラスのみでラベリングをしています。
cereate rectboxでボックス範囲をマウスカーソルで選択できるようになります。
ここで注意して欲しいのがyoloと書かれた部分です。これをクリックするとCreateMLやPascalVOCといったものも出てきます。yoloでラベリングする場合、ここはyoloにしてください。他でやるとラベル内容が変わってしまします。

(個人情報特定につながるデータは画像から一部切り抜いてあります。ご容赦ください。)
その後クラス名をつけます。今は1クラスのみですが、「柱」以外のクラスがあると右のbox labelにそれ以外の項目が出てきます。この作業がひたすら続きます。
ボックスをつける基準ですが、個人的には付随する情報等があればそれをボックスに含めると良いと思います。付随する情報とは、その物体と同時に存在する確率の高い物です。私は今回はこの橋部分の足場を検出するために海と橋部分を少しだけ含めてラベリングしています。また人間でも画像上で認識困難な物にはラベリングしない方針としました。
また頑健性の確保に関してですが、今回は、様々な角度からの撮影、潮位の時間変化による水面の高さ、光の当たり具合といった要因が分かる写真を用意しました。
データ拡張
何度か頑健性という言葉を出しました。ロバスト性とも言います。要は様々な条件に影響されにくく、また過学習を防げるモデルを作成したいわけです。
物体検出ではデータ拡張という手法があります。水増しとも言います。いくつか手法がありますが、代表的な物を挙げます。
・画像の反転(今回はこれを行います)
・光の調整
・拡大縮小
その他は以下を参照
https://qiita.com/zumax/items/0727e329f3322897d3e7
今回は画像の左右反転のみを行います。これ以外では画像の色具合を変える方法も検討しましたが、ある程度の精度で動けば良いという代物なのでパスします。
さて前項で行ったラベリングですがファイル構造は以下のようになっていると思います。
ファイル
├── classes.txt
├── image1.jpg
└── image1.txt

classes.txtは以下のようになっています。
柱
クラスが増えると改行されこの下に追加されていきます。これはラベリングで使用した全てのクラスが保管されています。
※このファイルが無く、しかし下のアノテーションデータがある場合labelimgがクラッシュする原因になります。
image1.txtは以下のようになっています。
0 0.541375 0.527167 0.054750 0.089667
0 0.419625 0.516500 0.070250 0.075000
・・・
ボックスが2つなので2行となっています。1行目を例にとり説明しますがこの値はそれぞれ
| 項目 | 内容 |
|---|---|
| 0 | クラス番号 |
| 0.541375 | xの座標 |
| 0.527167 | yの座標 |
| 0.054750 | xの横幅 |
| 0.089667 | yの横幅 |
となっています。当時こちらのサイトを元にデータ拡張のコードを作成しました。
https://qiita.com/garcoo/items/2ab8972ce304ffc8d225
以下は上サイトより引用
変換の考え方
上下 or 左右反転の場合、boxサイズについては変更なし
xとyの座標は左上が(0.00, 0.00)、右下が(1.00, 1.00)
上下反転の場合はy座標の反転になるので、(1 - y座標)
左右反転の場合はx座標の反転になるので、(1 - x座標)
上下左右の場合は、どちらも座標反転する(1 - x座標)(1 - y座標)
引用ここまで
以下データ拡張用(左右反転のみ)のコードは以下で折り畳み
コード例
from PIL import Image
import os
#コピーしたい物があるディレクトリ
indir="/Users/Desktop/画像"
#コピー先のディレクトリ
outdir="/Users/Desktop/画像/水増し"
#ディレクトリ移動
os.chdir(indir)
# ファイルが存在するディレクトリのパス
directory_path = indir
# ディレクトリ内のファイル名をリストで取得
file_list = os.listdir(directory_path)
print(file_list)
#jpgファイル抽出
jpg_files = [file for file in file_list if file.lower().endswith((".jpg"))]
# .jpg ファイル名のリストを表示
print(jpg_files)
#textファイル抽出
filtered_files = [file for file in file_list if file.endswith(".txt") and file != "classes.txt"]
# フィルタリングされたファイル名のリストを表示
print(filtered_files)
#画像反転用の関数
def flipeimage(imagename,outpath):
# 画像のパスを指定
#事前にコピーしたいファイルの一つ上のディレクトリに移動
input_image_path = imagename
output_image_path = outpath
# 画像を開く
image = Image.open(input_image_path)
# 画像を左右に反転
flipped_image = image.transpose(Image.FLIP_LEFT_RIGHT)
# 反転した画像を保存
flipped_image.save(output_image_path)
#jpeg画像の一括反転
for jfile_name in jpg_files:
#jfile_nameはコピーしたいファイル名.ectentionは水増しファイルとしての区別
jname_extension = "extension-"+jfile_name
# 出力先のディレクトリ+ファイル名にする
joutname=jname_extension
jnew=outdir+"/"+joutname#jnewがコピー先のファイル名
print(jnew)
flipeimage(jfile_name,jnew)
#今回は分類クラスが1つしかないため"ココ"は気にしなくて良い。
#上についてクラスが複数に分かれる場合の想定をしていないため注意
#ここからToDo
#書き込み先の.txtファイルがある想定で今は書いている。400ものファイルを用意する訳にはいかない
#写真ファイルと同じ名前のファイルを自動的に作るようにすること。
def flipetext(textname,outname):
# テキストファイルのパスを指定
file_path =textname
newpath=outname
# ファイルを読み込みモードで開く
with open(file_path, "r") as file:
# ファイルの内容を読み込む
#file_contents = file.read()
with open(newpath, "w") as Newfile:
for line in file:
a=line.strip() # strip() で改行文字を取り除く
print(a)
# 空白文字で分割してデータをリストに格納
data_list = line.split()
for index, item in enumerate(data_list):
if index==1: ##ココ
new=1-float(item)
Newfile.write(str(new))
Newfile.write(" ")
else:
new=item
#print(f"Index {index}: {item}")
Newfile.write(str(new))
Newfile.write(" ")
Newfile.write("\n") #改行 for lineの下のネスト
#アノテーションデータを反転させるfor文
for file_name in filtered_files:
# ファイル名に水増しの識別文字列を追加
name_extension = "extension-"+file_name
outname=name_extension
tnew=outdir+"/"+outname
print(tnew)
flipetext(file_name,tnew)
jupyter notebookで使用したコードを直でもってきたものなので見にくくて申し訳ありません。.pyで動かす際には関数の位置などを調整してください。あと冗長な書き方をしているのはご容赦ください。動けばなんでもいいのです。リーダブルコードなど目指してません。
※アノテーションファイルは画像ファイルと同じ名前にしてください。
学習セットの作成

構造的にはこのようなイメージでデータを割り振れば良いと思います。
先にも書いた通り今回trainに元画像の1~128枚目と反転させた画像43~170枚目の計256枚、valに元画像の128~170枚目と反転させた画像1~128枚目の計256枚を格納しています。
.yamlファイルの用意
形式はいくつかあったと思いますが今回は.yamlのファイルを用意します。ここには検出したいクラスの情報や学習データの保管先を書き込みます。テキストエディタなどで作成してください。
以下は私の使用したファイルです。参考程度にどうぞ。本稿ではこのファイルをcolum.yamlとして今後利用していきます。
train: /content/drive/My Drive/研究/data3/train
val: /content/drive/My Drive/研究/data3/val
nc: 1 #1クラスのみの検出,クラス数に応じて変える
# class names
names: ['柱'] #柱のみの検出なので1つだけ。['name1','name2','name3',・・・]
参考: https://wandb.ai/wandb_fc/japanese/reports/-PyTorch-YOLOv5---VmlldzoxODY0NzI4
学習、検証、テスト
ようやくデータセットの作成を終え学習、検証、テストなります。
学習前にですが、私はグラボを搭載していないパソコンを使用するため、ここからは以前推奨したgoogle colaboratoryを使用していきます。
google colaboではgoogle driveのデータをマウントできます。また学習データをgoogle driveに入れてdriveから直接マウントすることができます。
さて今回の学習のデータ配分は先に示した通りに行います。
さてgoogle colaboratoryですが、ランタイムのタイプをgpu t4にしてください。cpuで行うと時間が溶けますしランタイム上限に引っかかり計算が途中で終わりますので。
コード例
google driveの直結
from google.colab import drive
import os
import subprocess
drive.mount('/content/drive')
%cd /content/drive/My Drive/研究
githubからダウンロード
!git clone https://github.com/ultralytics/yolov5
%cd /content/drive/My Drive/研究/yolov5
!pwd
!pip install -r requirements.txt
以上でgoogle colaboratory環境にyolov5インストールできます。
yolov5ファイルのダウンロードは一度だけで良いですが、ランタイム(無料版では12時間)で環境がリセットされるので他の部分は適宜実行し直してください。
学習と検証
train.pyを実行して学習と検証は開始します。この際必要に応じてオプションを追加できますが、いちいち付け足さなくてもデフォルトの設定があります。今回は最低限のオプションでtrain.pyを実行します。--weightsにはyolov5n.ptを渡していますが、ここは書かなくてもデフォルトでyolov5s.ptがロードされます。
!python train.py --data colum.yaml --weights yolov5n.pt
本当に必要最低限にするなら↓
!python train.py --data colum.yaml
yolov5には精度や処理速度に応じていくつかの転移学習用モデルが用意されています。リアルタイム検出ということで私は最速の代わりに精度を犠牲にしたyolov5nを使っています。yolov5s以外のモデルを利用する場合は適宜ダウンロードする必要があります。
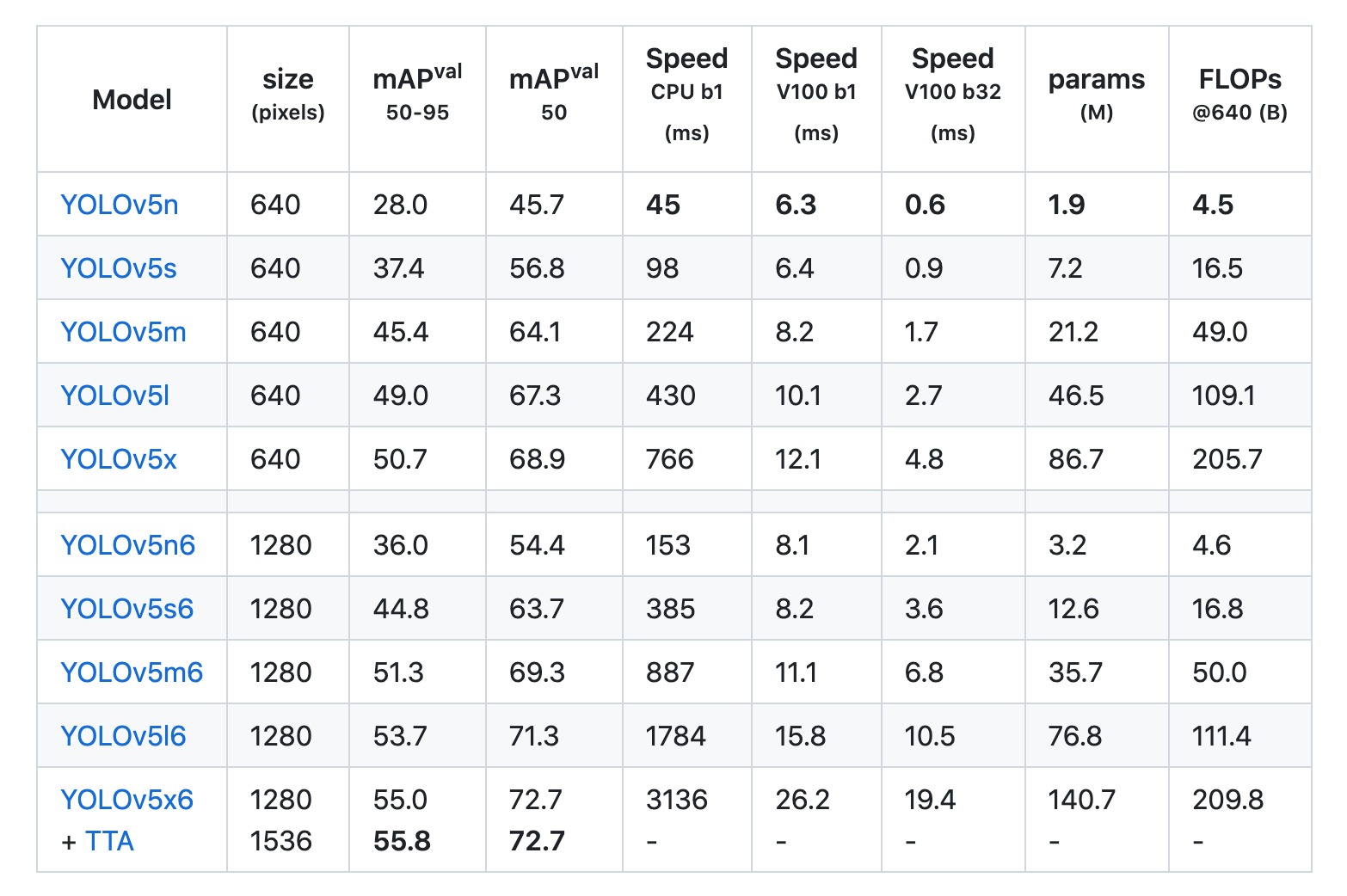
githubより引用
精度はmPA、速度はSpeedを参考にすると良いと思います。
https://github.com/ultralytics/yolov5
https://pytorch.org/hub/ultralytics_yolov5/
またその他のオプションはこちらかこちらを参考にしてください。
学習はデータ量によって変わりますが、私が学習用データ256枚をyolov5sで学習させた際には1時間半程度かかりました。あまりgpuリソースを使いすぎるとgoogle colaboratoryの制限に引っかかり使えなくなりますのでご注意ください。
学習と検証の結果
train.pyが実行された場合デフォルトでは/yolov5/runs/train/expに各種結果が保管されます。
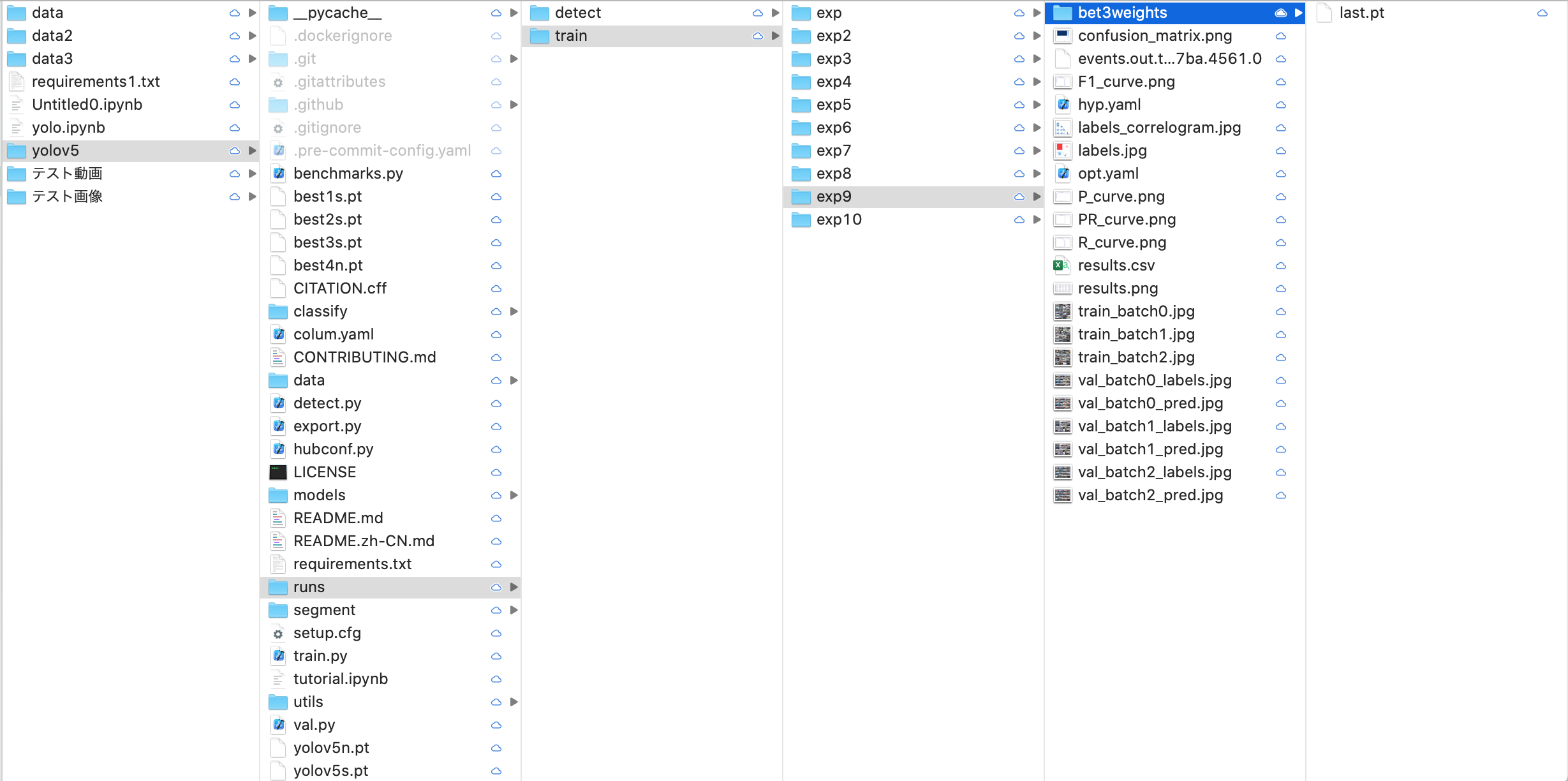
学習を繰り返せば経験値(exp)はどんどん溜まります。失敗やデータの変更を含めて私は10回前後回しましたのでゴミともいうべきデータが積もっています。
正常学習された場合weightsディレクトリ(ここではbest3weights)に学習結果の重みデータが保管されます。best.ptが一番高精度なモデルとなるのでそちらを利用すると良いでしょう。
検証データを用いた予測結果とresult.pngくらいしか私はデータしか見てませんが他の学習結果の指標も見方がわかれば載せるかもしれません。
Precision(適合率)=\frac{TP}{TP+FP}
Recall(再現率)=\frac{TP}{TP+FN}
True Positive (真陽性:TP)
True Negative (真陰性:TN)
False Positive (偽陽性:FP)
False Negative (偽陰性:FN)
で表されます。真〜は予測したもののうち実際に予測が正しかったもの、陽性陰性は本物か偽物かの予測となります。
以下引用
再現率(recall):正解が正例のもののうち、どれだけ正例と予測できたか
適合率(precision):正例と予測したもののうち、どれだけ正解だったか
lossはよく分かりません。自分はとりあえず0に近づけば良いと考えています。
モデルの動作テスト
次はdetect.pyを実行します。

!catの部分は行は無視してください。gpuの使用制限を調べる為だったと思いますが今回は関係ないので。
!python detect.py --source ../テスト動画/MOV_1553-2.mp4 --weights best3.pt --conf 0.50 --name trained_exp --exist-ok --save-txt
つらつらと書いていますがほとんどはオプションです。
--sourceに検出したい画像または動画
追記
0を入れるとwebカメラに接続されリアルタイム検出ができます。
detect.pyを参照すると使い方の説明が少しだけなされています。
また重みデータですが.pt以外にもいくつか対応形式があるので参考にしてください。
--conf には一定精度以上のものが欲しいので0.50以下は弾くように
--weightsに学習モデルを
--nameで保存先のディレクトリ名をtrained_expにしてます。
-exist-okと--save-txtではテスト結果とラベリングした座標を出力するようにしています。
ここでは--sourceとして動画を渡していますが、写真でやる方が当然ですがプログラムは早く終了します。
テスト結果は/yolov5/runs/detect/trained_expに保存されています。

ちなみに写真を--sourceに渡した結果はこんな感じです。



一部検出してくれてませんが概ね期待通りの動作はしてくれています。
ラベリングの半自動化
テストでは概ね期待通りの検出をしてくれたので、ここからはラベリングの半自動化を進めていきます。
※一発で綺麗に完了したように見えるでしょうがexp10の指し示す通りラベリングのやり方を変えたり動作検証をしたりでそこそこ時間がかかってます。上手くやってください。
detext.pyの実行で--save-txtのオプションを入れました。これはテストした際のラベリングの座標を出力してくれます。yolov5/runs/detect/ このあたりのどこかにlabelsとして保管されています。
これは出力されたラベルの一例です。
0 0.43151 0.459722 0.0546875 0.163889
0 0.589583 0.465741 0.059375 0.181481
・
・
・
このデータとlabelimgを使用し、正しくラベリングされているか人力で確認していきます。半自動化なので多少は人間が作業します。仕分け作業だけなので人間とAIの棲み分けみたいでいいですね。
※detect.pyに関してですがあるオプションを追加すれば各行の末尾に精度の情報を入れたり出来ます。しかし1行に6つを超える数値が入っているとlabelimgがクラッシュする原因になりますのでわざわざ入れなくてもいいでしょう。
作業の簡略化の為に今後の学習データ作りは動画を用いて行います。
この間動画データの構造を少し勉強したりしましたが、pythonでデータを解体する分にはopencvで処理出来ます。やり方は個々人に任せます。下に動画解体用に使ったコードを載せておきます。
コード例
import cv2
import os
# 入力のmp4ファイルと出力ディレクトリを指定
input_video = '/Users/***/Downloads/予測テスト/テスト動画/MOV_1553.mp4'
output_directory = '/Users/***/Downloads/予測テスト/動画解体'
file_name= os.path.basename(input_video)
fname = file_name.replace(".mp4", "")
print(fname)
# 出力ディレクトリが存在しない場合、作成
os.makedirs(output_directory, exist_ok=True)
# OpenCVを使用して動画を開く
cap = cv2.VideoCapture(input_video)
# フレームのカウンタ
frame_count = 0
while True:
# フレームを1つ読み込む
ret, frame = cap.read()
# フレームが読み込まれなかった場合、または動画の最後に達した場合は終了
if not ret:
break
frame_count += 1
# フレームを出力するファイル名を生成
output_file = os.path.join(output_directory,f'{fname}_{frame_count:01d}.jpg')
# フレームを保存
cv2.imwrite(output_file, frame)
# クリーンアップ
cap.release()
cv2.destroyAllWindows()
print(f'{frame_count} フレームを {output_directory} に保存しました。')
あまり綺麗なコードではありませんが動けば良い、また引き継ぎ用にすぎない記事なのでご容赦を。
ラベリングファイルと画像はファイル名が一致するようにしてください。
あとは適宜不要な画像を消してください。
jetson nanoへの実装
ここからは実装する段階に移行します。
今更ですが、本モデルは画像情報の座標を元に制御を行うつもりで作成しています。なので、モジュール化してwhile文で延々ぶん回す方が実装して座標を弾き出す上では都合が良いです。
!python detect.py xxxxx
などとつらつら書き、ターミナルを呼び出すようなコードで実装するわけにはいきません。detect.pyを一生懸命読み必要な部分だけを使おうかとも思いましたが、複雑なデータ型や引数や依存関係の前に挫折しました。もっと楽な方法に逃げることにします。
pytorchにモデルの動作確認
ここからはpytorchを使用します。jetson nanoに実装する上でGPUを使えるpytorchは最良に近い組み合わせでもあるでしょう。
また以降はgoogle colaboratoryは使いません。ローカルpcで行います。使用するモデルはgoogle colaboratoryで学習し出力したbest.ptです。
import torch
import cv2
im= cv2.imread('/Users/*****/Downloads/予測テスト/テスト画像/DSC_1552.JPG')
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #RGBカラー化
pt="/Users/***/Desktop/developper/yolo関連/best3.pt"
# Model
model = torch.hub.load('ultralytics/yolov5', "custom", path=pt)
model.conf = 0.5 #閾値
results = model(im)
results._run(pprint=True, show=True, save=False, crop=False, render=True, labels=True)
print(results.pandas().xywhn[0]["xcenter"])
print()
参考にしたサイトは以下
カスタムモデルのロードや使用デバイスの指定は以下に書かれています。ここの項ではカスタムモデルを使用をしますので上のコードで行います。
_run()の引数などはこちらのソースコード内のdef _run()を見て適宜変えてください。記事によって関数の内容が違う点から定期的に何かしらの変更が加えられていると思うので。class Detectionsの中をみれば分かるでしょう。

動作はしています。座標も出力できました。次は実際にjetsonに搭載します。
jetson nanoでの環境整備
Nvidia公式のjetpack sdkではubuntu18.04までしか対応してません。ubuntu18ではPython3.6隣Pytorchが使用できないため、ubuntu20を使えるサードパティーのosを使用します。
※自分でpython3.8を入れ直すという方法もあります。
sdk managerを使用する方法は上を参考にしてください。
jetson nanoに対応したubuntu20.04として以下を使用します。

imageをダウンロードする必要があります。8.7GBとかなり大きなファイルなので、時間がそれなりにかかります。
sdカードを焼くソフトは以下よりダウンロードできます。
img.xzの形式のまま焼けば書き込めます。
書き込みがおわり起動したらまずpytorchをインストールしてください。手順は先に書いたものと同じです。

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
次に好きな場所にyolov5をダウンロードしてください。またpipでインストールしてください。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
動作確認をします。以下のようにライブラリを読み込みyolov5を何事もなくロードできれば動作確認は終了です。
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
問題なくロードできたため実装してみます。
import torch
import cv2
im= cv2.imread('/home/jetson/Desktop/usv/test/DSC_1552.JPG')
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #RGBカラー化
pt="/home/jetson/Desktop/usv/best3.pt"
# Model
model = torch.hub.load('ultralytics/yolov5', "custom", path=pt)
model.conf = 0.5 #閾値
results = model(im)
results._run(pprint=True, show=True, save=False, crop=False, render=True, labels=True)
print(results.pandas().xywhn[0]["xcenter"])
print()
jetson nanoの画面のスクショを撮っていませんいませんが、これで精度つきの画像が出力できました。
以上です。