目的
YOLOv5の学習時に指定可能なオプションについて解説すると共に、理解をする。
背景
YOLOv5🚀の学習時に指定可能なオプションについての理解が不足していたのと、実際にどういった動作となるのか解説を見てもわからないことが多かったため、YOLOv5への理解を深める意味も含め、公式資料やソースコードを確認し動作を整理したいと思った。
前提条件
YOLOv5下記断面のソースにて調査
学習時(train.py実行時)のオプション一覧
| オプション名 | 説明 |
|---|---|
| --weights | 学習時のモデルを指定します。 |
| --cfg | モデル構成を指定します。 |
| --data | データセット構成を指定します。 |
| --hyp | ハイパーパラメータを指定します。 |
| --epochs | エポック数を指定します。 |
| --batch-size | バッチサイズを指定します。 |
| --imgsz,--img,--img-size | 学習時の入力画像サイズを指定します。 |
| --rect | 正方形画像ではなく、入力元画像のアスペクト比を維持したままの長方形画像での学習を指定します。 |
| --resume | 学習の再開を指定します。 |
| --nosave | 最終エポックのみモデルを保存するよう指定します。 |
| --noval | 最終エポックのみ検証を行うよう指定します。 |
| --noautoanchor | オートアンカーを無効に指定します。 |
| --noplots | 学習後に出力される画像ファイル全般を出力しないよう指定します。 |
| --evolve | ハイパーパラメータの遺伝、および、遺伝数を指定します。 |
| --bucket |
Google Cloud Storageのバケット名称を指定します。 |
| --cache | 訓練、検証用画像のキャッシュ先を指定します。 |
| --image-weights | 学習時に読み込まれる画像が加重選択されるよう指定します。 |
| --device | デバイスを指定します。 |
| --multi-scale | 学習時の画像サイズを+/- 50%範囲でランダムにスケールするよう指定します。 |
| --single-cls | 複数クラスを持つデータセットを単一クラスのデータセットとして学習を指定します。 |
| --optimizer | オプティマイザを指定します。 |
| --sync-bn | 分散学習時、バッチノーマライゼーションの計算で使用するチャネルごとの統計量をデバイス間で統一するよう指定します。 |
| --workers | データローダのワーカー数を指定します。 |
| --project | プロジェクトフォルダを指定します。 |
| --name | 学習結果を保存するフォルダを指定します。 |
| --exist-ok |
--nameで指定されたフォルダに学習結果を上書きするよう指定します。 |
| --quad | クアッドデータローダを指定します。 |
| --cos-lr | スケジューラにcosを指定します。 |
| --label-smoothing | クラスラベルの平滑化をする際に使用するε(イプシロン)を指定します。 |
| --patience | 学習精度が改善されない状態が指定エポック数続いた場合、学習を停止するよう指定します。 |
| --freeze | モデル内の固定する層を指定します。 |
| --save-period | 指定されたエポックごとにモデルのチェックポイントを保存する周期数を指定します。 |
| --seed | 学習時のランダムシード値を指定します。 |
| --local_rank | ノード内で何番目のプロセスかを指定します。 |
| --entity | W&B関連は割愛 次回以降の記事アップデート時に記述予定 |
| --upload_dataset | 同上 |
| --bbox_interval | 同上 |
| --artifact_alias | 同上 |
各オプション詳細
--weights <モデルファイル>
学習時のモデルを指定します。
転移学習など、学習済みモデルを元に学習を進める場合は指定が必要となります。
--weightsを省略した場合、ROOT1/yolov5s.ptが指定されます。
指定例
--weights yolov5s.pt
--weights runs/train/exp/weights/best.pt
YOLOv5が用意している学習済みモデルは下記となります。
- yolov5n.pt
- yolov5s.pt
- yolov5m.pt
- yolov5l.pt
- yolov5x.pt
- yolov5n6.pt
- yolov5s6.pt
- yolov5m6.pt
- yolov5l6.pt
- yolov5x6.pt
YOLOv5公式にて、転移学習についての解説があります。
--cfg <モデル構成ファイル>
モデル構成を指定します。
--weightsを指定しない(""を指定)場合は必要となります。
--cfgを省略した場合、""(指定なし)となります。
指定例
--cfg yolov5s.yaml
YOLOv5が用意しているモデル構成は下記となります。2
- yolov5n.yaml
- yolov5s.yaml
- yolov5m.yaml
- yolov5l.yaml
- yolov5x.yaml
--data <データセット構成ファイル>
データセット構成を指定します。データセットを用意できない場合、YOLOv5が用意しているデータセット構成を指定することも可能です。
--dataを省略した場合、ROOT1/data/coco128.yamlが指定されます。
指定例
--data coco128.yaml
--data data/data.yaml
YOLOv5が用意しているデータセット構成は下記となります。2
- Argoverse.yaml
- coco.yaml
- coco128.yaml
- GlobalWheat2020.yaml
- Objects365.yaml
- SKU-110K.yaml
- VisDrone.yaml
- VOC.yaml
- xView.yaml
YOLOv5が用意しているデータセット構成を指定すると、データセットをダウンロードし、アノテーションもYOLOv5が読み込めるように変換してくれます。本題とは逸れますが、変換が必要なデータセットについては、変換スクリプトがyamlファイルの中に記述されているため、自前で変換したい場合には非常に参考になります。
--hyp <ハイパーパラメータファイル>
ハイパーパラメータを指定します。
--hypを省略した場合、ROOT1/data/hyps/hyp.scratch-low.yamlが指定されます。
指定例
--hyp hyp.scratch-low.yaml
--hyp runs/evolve/exp/hyp_evolve.yaml
YOLOv5が用意しているハイパーパラメータは下記となります。2
- hyp.Objects365.yaml
- hyp.scratch-high.yaml
- hyp.scratch-low.yaml
- hyp.scratch-med.yaml
- hyp.VOC.yaml
--epochs <エポック数>
エポック数を指定します。
--epochsを省略した場合、300が指定されます。
指定例
--epochs 50
--batch-size <バッチサイズ>
バッチサイズを指定します。
--batch-sizeを省略した場合、16が指定されます。
-1を指定した場合、オートバッチとなり、最適なバッチサイズが設定されます。
指定例
--batch-size 16
--batch-size -1
--imgsz <画像サイズ>, --img <画像サイズ>, --img-size <画像サイズ>
学習時の入力画像サイズを指定します。
--imgsz、--img、--img-sizeを省略した場合、入力画像サイズは640x640となります。
指定例
--imgsz 320
--rect
正方形画像ではなく、入力元画像のアスペクト比を維持したままの長方形画像での学習を指定します。
--rectを省略した場合、--imgszで指定されたサイズで学習を行います。
--rectを指定するとデータローダのシャッフル指定がFalseになります。
if rect and shuffle:
LOGGER.warning('WARNING: --rect is incompatible with DataLoader shuffle, setting shuffle=False')
shuffle = False
--image_weightsが指定されている場合、--rectは無効になるようです。
self.rect = False if image_weights else rect
下記投稿がありましたので補足として掲載します。
images are never 'stretched', aspect ratio of objects is preserved at all times. --rect means rectangular training, it does not produce square batches.
画像は決して「引き伸ばされる」ことはなく、オブジェクトのアスペクト比は常に保持されます。--rectは 正方形のバッチを生成するのではなく、長方形のトレーニングを意味します。
--rect sorts the dataset by aspect ratio for maximum efficiency, which is naturally incompatible with shuffling.
--rectはデータセットをアスペクト比でソートし、効率を最大化するが、これは当然シャッフルとは相容れない。
--resume <チェックポイントモデルファイル>
学習の再開を指定します。
チェックポイントモデルファイルには、--save-periodにて保存したチェックポイントを指定します。
--resumeを省略した場合、最初から学習が開始されます。
指定例
--resume runs/train/opt/weights/epoch50.pt
チェックポイントモデルファイルの指定なしで、--resumeのみ指定した場合、ROOT1/runsの中から、最新のlast.ptが選択され、そこから再開されます。
尚、学習再開の際、再開する元のモデルに指定されたオプションが復元されます。
モデルの1つ上の階層にopt.yamlファイルがあり、このファイルが読み込まれます。(runs/train/XXXXの直下)
オプションが復元されることにより、train.py実行時に指定した--resume以外は上書きされます。
そのため、出力先ディレクトリ(--name)を指定していた場合、再開後の出力先を勘違いすることもありますのでご注意願います。
def main(opt, callbacks=Callbacks()):
# Checks
if RANK in {-1, 0}:
print_args(vars(opt))
check_git_status()
check_requirements(exclude=['thop'])
# Resume
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
# ====== ここでオプションが上書きされている。 ======
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
--nosave
最終エポックのみモデルを保存するよう指定します。
--nosaveを省略した場合、最終エポック以外でもモデルを保存します。
--noval
最終エポックのみ検証を行うよう指定します。
--novalを省略した場合、エポックごとに検証します。
--noautoanchor
オートアンカーを無効に指定します。
--noautoanchorを省略した場合、オートアンカーが行われます。
オートアンカーは学習前に実行され、アンカーがデータに適応しているかを確認し、適応していなければ新たにアンカーが設定されます。
anchors may be supplied in your model.yaml file as you have shown above. AutoAnchor runs before training to ensure your anchors are a good fit for your data. If they are not, then new anchors are computed and evolved and attached to your model automatically. No action is needed on your part. You can disable autoanchor with python train.py --noautoanchor.
アンカーはmodel.yamlファイルで指定することができます。AutoAnchorは学習の前に実行され、アンカーがデータにうまくフィットしているかどうかを確認します。もしそうでなければ、新しいアンカーが計算され、進化してモデルに自動的に取り付けられる。あなたは何もする必要がない。python train.py --noautoanchorで自動アンカーを無効化することができます。
anchors are never changed on a trained model. Also, you should train at the same size you intend to run inference at for best results.
アンカーは学習済みモデルで変更されることはありません。また、最良の結果を得るためには、推論を実行する予定のサイズと同じサイズで学習する必要があります。
--noplots
学習後に出力される画像ファイル全般を出力しないよう指定します。
--noplotsを省略した場合、出力が行われます。
--evolve <遺伝数>
ハイパーパラメータの遺伝、および、遺伝数を指定します。
--evolveのみを指定した場合、300が指定されます。
--evolveを指定しない場合、遺伝は行われません。
指定例
--evolve 500
YOLOv5公式にて、ハイパーパラメータ遺伝についての解説があります。
--bucket <バケット名>
Google Cloud Storageのバケット名称を指定します。
このオプションはハイパーパラメータの遺伝でのみ使用します。
遺伝に関わるファイル(evolve.csv)のダウンロード元、アップロード先のバケットを指定するために使用されます。
--bucketを省略した場合、""(バケット指定なし)が指定されます。
指定例
--bucket example_bucket
--cache <キャッシュ先>
訓練、検証用画像のキャッシュ先(ramordisk)を指定します。
--cacheのみ指定した場合、ramを指定した場合と同等となります。
--cacheを省略した場合、キャッシュを行いません。
ramを指定した場合、学習前に画像がメモリに読み込まれます。
diskを指定した場合、学習前に画像をnpyファイルとしてディスクに保存します。仕組みはあまりわかっていないのですが、ソースコメントを見る限り、この方が画像ファイルを直接開くよりは高速らしいです。
リソースとの相談ではありますが、基本はramを使う方が良さそうです。
指定例
--cache
--cache disk
--image-weights
学習時に読み込まれる画像が加重選択されるよう指定します。
--image-weightsを省略した場合、加重選択されず均一となります。
解説ではないですが、使い方の質問にて、動作の説明がありました。
--image-weightssamples images from the training set weighted by their inverse mAP from the previous epoch's testing (rather than sampling the images uniformly as in normal training). This will result in images with a high content of low-mAP objects being selected with higher likelihood during training.
--image-weightsは、前のエポックのテストからの逆mAPによって重み付けされたトレーニングセットから画像をサンプリングします(通常のトレーニングのように画像を均一にサンプリングするのではなく)。これにより、低mAPオブジェクトのコンテンツが多い画像が、トレーニング中に選択される可能性が高くなります。
--device <デバイス>
デバイスを指定します。
--deviceを指定しない場合、環境に合わせたデバイスが選択されます。
指定例
--device 0
--device cpu
--multi-scale
学習時の画像サイズを+/- 50%範囲でランダムにスケールするよう指定します。
--multi-scaleを省略した場合、スケールはしません。
--single-cls
複数クラスを持つデータセットを単一クラスのデータセットとして学習を指定します。
--single-clsを省略した場合、データセットのクラス指定に従います。
--optimizer <オプティマイザ名>
オプティマイザを指定します。
--optimizerを省略した場合、SGDが指定されます。
指定可能なオプティマイザは下記です。
- SGD
- Adam
- AdamW
指定例
--optimizer Adam
--sync-bn
分散学習時、バッチノーマライゼーションの計算で使用するチャネルごとの統計量(平均、分散)をデバイス間で統一するよう指定します。
--sync-bnを省略した場合、統計量の統一は行われません。
--workers <ワーカー数>
データローダのワーカー数を指定します。
--workersを省略した場合、8が指定されます。
ご利用の環境リソース次第では指定したワーカー数を下回る設定値に丸められる可能性があります。
ソースコードを確認したところ、CPU数/GPUデバイス数、バッチサイズ、--workersで指定した数のいずれかの最小値が割り当てられるようです。細かな処理は下記ソースを参照願います。
nd = torch.cuda.device_count() # number of CUDA devices
nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
--project <プロジェクトフォルダ>
プロジェクトフォルダを指定します。
--projectを省略した場合、ROOT1/runs/trainが指定されます。
--evolveを指定している、かつ、--projectがruns/trainの場合、当該オプションの指定値はruns/evolveに上書きされます。
指定例
--project runs/train_example
--name <フォルダ>
学習結果を保存するフォルダを指定します。
--projectで指定したプロジェクトフォルダの直下に作成されます。
--nameを省略した場合、expが指定されます。
指定例
--name exp_example
--exist-ok
--nameで指定されたフォルダに学習結果を上書きするよう指定します。
--exist-okを省略した場合、--nameで指定されたフォルダ名の後ろに連番をつけて新たにフォルダを作成します。
--quad
クアッドデータローダを指定します。
--quadを省略した場合、通常のデータローダとなります。
クアッドデータローダについてはあまりわかっていませんが、後述の投稿にて解説が載っています。ただし投稿日時が古く、既に解消している可能性があります。
投稿を見る限り、画像サイズを一部倍にリサイズし学習することにより、1280pxでの直接学習した時の結果も多少取り込んだいい感じのモデル(文中で中間的なモデルと言っている)ということなのでしょう。640pxを超える画像サイズだとどれぐらいのパフォーマンスなのかはわかっていませんが、学習パフォーマンスと精度のトレードオフを提案していると思われます。
読み取った限りのパフォーマンス順としては下記 悪<良
--img 1280<--img 640 --quad<img 640
現時点、1280pxに対応したyolov5s6.ptモデル等、xxxxx6.ptシリーズが出ているため、解消している可能性が高いです。
もしこの辺について詳しい方がいらっしゃったらコメント願います。
<2021/1時点の投稿>
the quad dataloader is an experimental feature we thought of that may allow some benefits of higher --img size training at lower --img sizes.
クアッドデータローダーは、私たちが考えた実験的な機能で、より大きな画像サイズのトレーニングを、より小さな画像サイズで行うことができるかもしれません。
This quad-collate function will reshapes a batch from 16x3x640x640 to 4x3x1280x1280, which does not have much effect by itself as it is only rearranging the mosaics in the batch, but which interestingly allows for 2x upscaling of some images within the batch (one of the 4 mosaics in each quad is upscaled by 2x, the other 3 mosaics are deleted). The upscaling probability is set here:
このquad-collate関数は、バッチを16x3x640x640から4x3x1280x1280にリシェイプします。バッチ内のモザイクを再配置するだけなのでそれ自体はあまり効果がありませんが、興味深いことにバッチ内のいくつかの画像を2倍にアップスケールできます(各quadの4モザイクのうちの1つが2倍にアップスケール、他の3モザイクは削除されます)。アップスケーリング確率はここで設定します。
We haven't been able to run as many experiments as we'd like on it yet, but we did train a normal YOLOv5l model and a YOLOv5l model with --quad, and the --quad model predictably can run inference at --img-sizes above 640, while the normal model suffers worse performance at > 640 image sizes (both models were trained at --img 640). The compromise though (there's always a compromise) is that the quad model performs slightly worse at 640. So you could consider --img 640 --quad as a middle ground that trains with the speed of --img 640 but with a bit of the higher mAP seen when training directly at --img 1280 (which of course would normally take 4x longer than training at --img 640).
まだ、思うような実験はできていませんが、通常のYOLOv5lモデルとYOLOv5lモデルを--quadで訓練しました。--quadモデルは予想通り640以上の画像サイズで推論を実行できますが、通常のモデルは640以上の画像サイズではパフォーマンスが悪くなります(両方のモデルは--img 640で訓練しました)。しかし、妥協点として(常に妥協点はあります)、quadモデルは640で若干パフォーマンスが悪くなります。つまり、--img 640 --quadは、--img 640のスピードで学習しつつ、--img 1280で直接学習したときに見られる高いmAP(もちろん、通常は--img 640での学習より4倍時間がかかる)を少し加えた中間的なモデルだと考えてもよいでしょう。
--cos-lr
スケジューラにcosを指定します。
--cos-lrを省略した場合、linearが利用されます。
Based on empirical results of training both ways on all YOLOv5 models. Before and after (300 epochs):
すべてのYOLOv5モデルで双方の学習を行った実証結果に基づきます。学習前と学習後(300エポック分)。
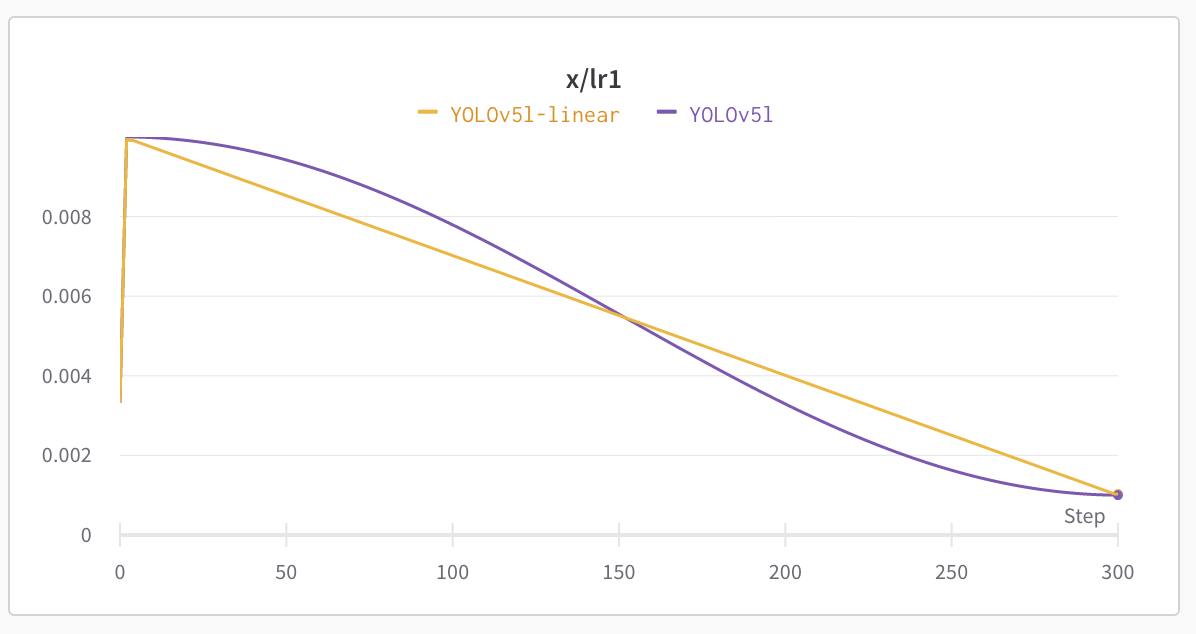
何が違うのか、スケジューラをちゃんと理解していないのでわかりませんが、linearが良かったのでしょうね。もう少しこの辺を押さえておこうと思います。
--label-smoothing <ε>
クラスラベルの平滑化をする際に使用するε(イプシロン)を指定します。
--label-smoothingを省略した場合、εに0.0が指定され、平滑化されずone-hotベクトル[1, 0, 0, 0, ...]が使用されます。
平滑化により、クラスラベルの表現が[0.0, 0.0, 0.9, 0.0, ...]となり、スムーズな値となります。
one-hotベクトルの場合、モデルが予測に自信を持ちすぎて過学習を起こしやすくなりますが、平滑化によりそれを防ぐらしいです。
この辺りはあまり詳しくないのですが、下記論文にて解説がされているようです。ソースコード中で紹介されていたリンクを掲載します。
私も勉強しておきます。
指定例
--label-smoothing 0.1
--patience <エポック数>
学習精度が改善されない状態が指定エポック数続いた場合、学習を停止するよう指定します。
--patienceを省略した場合、100が指定されます。
指定例
--patience 50
--freeze <モデル内の固定する層の数>
モデル内の固定する層を指定します。転移学習でバックボーン層を固定したい場合に利用します。
--freezeを指定しない場合、0が指定され層の固定は行われません。
オプションに対し1つの引数を指定した場合、先頭から指定した数分の層が固定されます。
複数の引数を指定した場合、指定した層を固定します。
層のインデックスは0始まりであることに注意してください。
モデルの構成についてはmodels/*.yamlを参照願います。
指定例
--freeze 10
--freeze 1 3
YOLOv5公式にて、転移学習についての解説があります。
--save-period <周期数>
指定されたエポックごとにモデルのチェックポイントを保存する周期数を指定します。
--save-periodを省略した場合、チェックポイントの保存は行われません。
指定する周期は0始まりのエポック数に対してであることに注意してください。
学習エポック数は0から始まるので、例えば5を指定した場合、5エポック目(6回目の学習)が完了した時点でモデルのチェックポイントが保存されます。
指定例
--save-period 5
--seed <シード値>
学習時のランダムシード値を指定します。
--seedを省略した場合、0が指定されます。
使用例
--seed 1
--local_rank <ランク数>
ノード内で何番目のプロセスかを指定します。
この値は分散学習時に利用されます。
使用例
--local_rank 2
--entity、--upload_dataset、--bbox_interval、--artifact_alias
W&B関連については今回割愛とさせていただきます。
YOLOv5公式の投稿にて、概要が掲載されておりますので、そちらを参照願います。
最後に
オプションという、機能の入り口を探ることで、知らなかった機能や、YOLOv5に捉われない機械学習の要素を知るきっかけができた。基礎的な知識が乏しい状態からスタートしたため、理解が難しかった部分が多々あり、基礎を固めてから進めるべきと思ったりもしたが、こういった切り口で知識を得たり、広げていくのも悪くないと思った。