PHP でも数値計算したいし、行列ライブラリくらいさすがにあるだろうと思っていたのですが、軽く探した限りでは見当たらなかったので作りました。
すべてを PHP コードで実装したものならいくつかあるようですが、以下で見るように PHP コードでの実装では遅すぎてお話になりません。今回は PHP のエクステンション機能を使って C 言語による実装をしました。また、更に高速化をするために線形代数数値計算ライブラリである OpenBLAS とその NVIDIA GPU 版である cuBLAS にリンクする試みをしました。
積の他にも成分ごとの積や転置などいくつかのメソッドを備えています。(これらは今のところ BLAS にはリンクできていません。)
用語
-
PHP エクステンション
C 言語で書かれる、 PHP 機能を拡張するモジュールです。普通の PHP スクリプトと比べてかなり速度が出ます。
作成方法など、詳しくは PHP7 でのエクステンションの書き方を調べた を参照ください。 -
OpenBLAS
基本的な線形代数の計算操作を実行する API の集まりである、BLAS (Basic Linear Algebra Subprograms) のオープンな実装です。高度な最適化が施され、非常に高速に動作します。CPU のコアをフルに使ってマルチスレッドで計算しているようです。公式サイトは OpenBLAS です。 -
cuBLAS
NVIDIA CUDA 上に作られた BLAS の実装です。GPU を使って更に高速に動作します。
http://docs.nvidia.com/cuda/cublas/index.html に解説があります。
作ったもの
GitHub にリポジトリを公開しました。エクステンションの通常の開発手順で試すことができます。cuBLAS サポートを有効にするには make する前に付属のシェルスクリプトで CUDA ファイルを先にビルドしておく必要があります。詳しくは README.md を参照ください。
呼び出し方
$a = Matrix::createFromData([[1, 2], [3, 4]]);
$b = Matrix::createFromData([[5, 6], [7, 8]]);
$c = $a->mul($b);
print_r($c->toArray());
実行結果
Array
(
[0] => Array
(
[0] => 19
[1] => 22
)
[1] => Array
(
[0] => 43
[1] => 50
)
)
のように、通常の二重配列から Matrix オブジェクトを生成し mul() メソッドを呼び出します。 toArray() メソッドでまた二重配列に戻すことができます。
パフォーマンス測定
$n \times n$ 正方行列どうしの積を10回計算してその平均値を測定しました。
実行環境はこんな感じ:
以下にプロットを示します。
- naive PHP: PHP コードで素直に三重ループする実装
- simple C: C言語で素直に三重ループする実装
- OpenBLAS: OpenBLAS にCPU計算させる実装
- cuBLAS: cuBLAS にGPU計算させる実装
です。
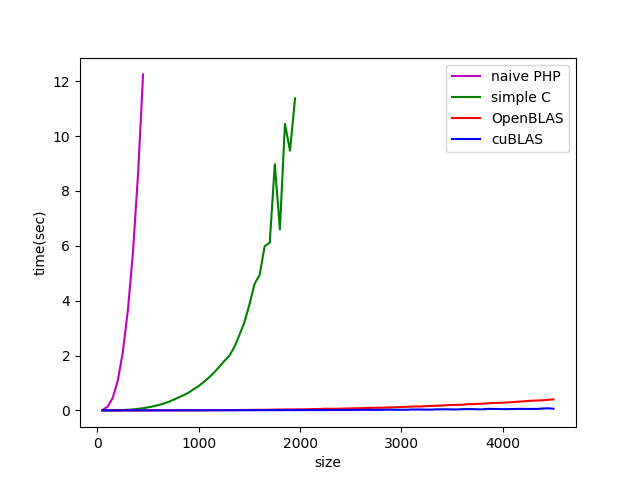
Naive PHP は $n = 450$ あたりで1回の計算時間が10秒を超えてしまい早々に使い物にならなくなります。実用するなら $n \sim 30$ くらい(実行時間 $\sim 0.01s$)までかも? Simple C はそれに比べるとかなり速く、$n \sim 220$ くらいまでは 0.01秒で計算できています。
OpenBLAS, cuBLAS はさらに圧倒的です・・・!OpenBLAS, おなじC言語(とアセンブラ)で書かれてて、CPU 実行なのにここまで速いとは驚きです。
このグラフでは潰れてしまってよくわからないので二者だけのプロットにしてみます。
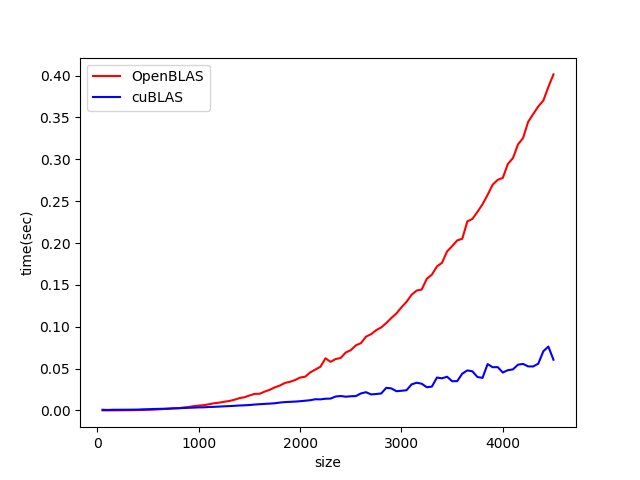
目安として0.01秒で計算できるサイズを挙げると、OpenBLAS では $n \sim 1200$, cuBLAS では $n \sim 2000$ 程度となりました。行列が小さいときは OpenBLAS のほうが cuBLAS よりも速いです。これは cuBLAS はホストとGPUの間でのデータ転送のオーバーヘッドが大きいためかと思われます。$n$の小さい領域のプロットを別に示すと、
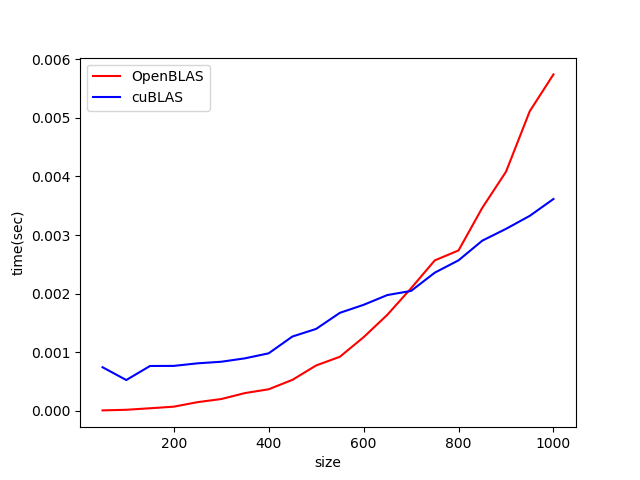
となり、$n \sim 700$ くらいまでの小さめの行列が中心の計算であれば OpenBLAS を使うほうが有利のようです。(計算のやり方を工夫してデータ転送回数を減らせば cuBLAS が勝つと思いますが。)
実装概要
(以下、興味がある方向け。)
実装の切り替え
configure のオプションで C 言語による単純な実装、 OpenBLAS を使う実装、cuBLAS を使う実装を切り替えることができます。
以下のように、PHP カスタムオブジェクトが持っている float のバッファをどのルーチンに投げるかをビルド時にプリプロセッサで切り替えています。
// 行列の積
PHP_METHOD(Matrix, mul) {
php_matrix* self = Z_MATRIX_OBJ_P(getThis());
zval* z_matrix;
php_matrix* matrix;
if (zend_parse_parameters(ZEND_NUM_ARGS(), "O", &z_matrix, matrix_ce) == FAILURE) {
return;
}
if (!self) {
RETURN_FALSE;
}
matrix = Z_MATRIX_OBJ_P(z_matrix);
int r1 = (int)self->numRows;
int c1 = (int)self->numCols;
int r2 = (int)matrix->numRows;
int c2 = (int)matrix->numCols;
// 結果の matrix を作成
php_matrix* result = init_return_value(return_value, r1, c2);
# if defined USE_OPENBLAS
_openblas_mul(self->data, matrix->data, result->data, r1, c1, r2, c2);
# elif defined USE_CUBLAS
_cublas_mul(self->data, matrix->data, result->data, r1, c1, r2, c2);
# else
_simple_mul(self->data, matrix->data, result->data, r1, c1, r2, c2);
# endif
}
Simple C
C 言語による単純な実装はこんな感じ:
static inline void _simple_mul(float* a, float* b, float* c, int r1, int c1, int r2, int c2) {
for (int i = 0; i < r1; ++i) {
for (int j = 0; j < c2; ++j) {
for (int k = 0; k < c1; ++k) {
c[i * c2 + j] += a[i * c1 + k] * b[k * c2 + j];
}
}
}
}
なんの工夫もありません・・・
OpenBLAS
OpenBLAS による実装は単に cblas_sgemm() 関数を呼び出すだけです。
static inline void _openblas_mul(float* a, float* b, float* c, int r1, int c1, int r2, int c2) {
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
r1, c2, c1,
1.0,
a, c1,
b, c2,
0.0,
c, c2);
}
cuBLAS
cuBLAS も基本的には cublasSgemm() 関数を呼ぶだけですが、ホストと GPU デバイス間でのデータの受け渡しをする必要があります。
extern "C" {
void _cublas_mul(float* a, float* b, float* c, int r1, int c1, int r2, int c2) {
//デバイス(GPU)側用
float *devA,*devB,*devC;
// 行列演算 C=αAB+βC のパラメータ
float alpha = 1.0f;
float beta = 0.0f;
size_t memSzA = r1 * c1 * sizeof(float);
size_t memSzB = r2 * c2 * sizeof(float);
size_t memSzC = r1 * c2 * sizeof(float);
//デバイス側メモリ確保
cudaMalloc((void **)&devA, memSzA);
cudaMalloc((void **)&devB, memSzB);
cudaMalloc((void **)&devC, memSzC);
//ホスト → デバイス memcpy
cublasSetVector(r1 * c1, sizeof(float), a, 1, devA, 1);
cublasSetVector(r2 * c2, sizeof(float), b, 1, devB, 1);
// デバイス側ハンドル作成
cublasHandle_t handle;
cublasCreate(&handle);
// 行列の積 演算
// CuBLAS は列指向であることに注意する!!
// https://stackoverflow.com/questions/13782012/how-to-transpose-a-matrix-in-cuda-cublas
cublasSgemm(
handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
c2,
r1,
c1,
&alpha,
devB,
c2,
devA,
c1,
&beta,
devC,
c2
);
// デバイス側ハンドル破棄
cublasDestroy(handle);
// ホスト ← デバイス memcpy (計算結果取得)
cublasGetVector(r1 * c2, sizeof(float), devC, 1, c, 1);
// デバイス側メモリ解放
cudaFree(devA);
cudaFree(devB);
cudaFree(devC);
}
}
config.m4
ドキュメントが少なく非常に苦労しました・・・
このあたりが共有ファイルをリンクする設定を書いているところです。雰囲気だけでも。
if test "$PHP_OPENBLAS" != "no"; then
AC_DEFINE(USE_OPENBLAS,1,[Include OpenBLAS support])
OPENBLAS_INCS=`PKG_CONFIG_PATH=$PHP_OPENBLAS/lib/pkgconfig pkg-config --cflags openblas`
OPENBLAS_LIBS=`PKG_CONFIG_PATH=$PHP_OPENBLAS/lib/pkgconfig pkg-config --libs openblas`
AC_MSG_RESULT(OPENBLAS_INCS = $OPENBLAS_INCS)
AC_MSG_RESULT(OPENBLAS_LIBS = $OPENBLAS_LIBS)
PHP_EVAL_INCLINE($OPENBLAS_INCS)
PHP_EVAL_LIBLINE($OPENBLAS_LIBS, MATRIX_SHARED_LIBADD)
fi
dnl Check wheter to enable cuBLAS support
if test "$PHP_CUBLAS" != "no"; then
AC_DEFINE(USE_CUBLAS,1,[Include cuBLAS support])
CUBLAS_DGEMM_LIBS="-L./modules -lcublas_sgemm"
AC_MSG_RESULT(CUBLAS_DGEMM_LIBS = $CUBLAS_DGEMM_LIBS)
PHP_EVAL_LIBLINE($CUBLAS_DGEMM_LIBS, MATRIX_SHARED_LIBADD)
fi
感想
GPU を使った cuBLAS が速いことはある意味当然としても、CPU でここまで頑張る OpenBLAS すごい・・・
あと、PHP遅い・・・実数の配列と言ってもその要素は ZVal というでかいオブジェクトで包まれていて、それを取り回しているのでまあ当然。
はてさて、せっかく作ったのでこれを使って機械学習などしてみたいところ。
参考サイト
冒頭に上げた公式サイト以外に特に以下のサイトを参考にさせていただきました。