Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, Bryan Catanzaro
NVIDIA Corporation, UC Berkeley
CVPR2018
pdf, arXiv, github, project page
どんなもの?
前回紹介した論文の拡張元の論文.前回の論文中に比較手法として登場しているpix2pixHDを提案.
Conditional GANを用いた高解像度(2048x1024)のimage to imageの手法を提案.

先行研究との差分
- 高解像度(2048x1024)でリアルな画像を生成可能
- ラベル情報を操作することで Interactive Object Editing が可能
- Boundary map を使用することでより物体の境界が鮮明に
技術や手法のキモ
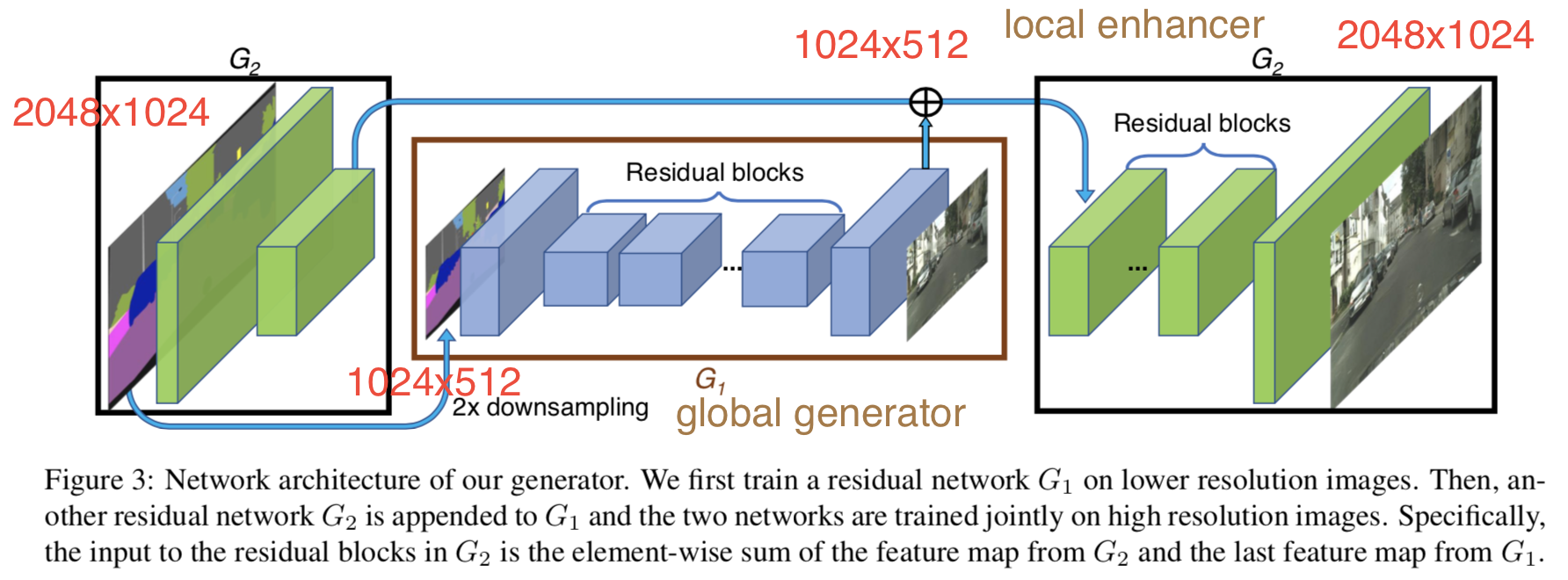
※論文中Figure 3を加工
Coarse-to-fine generator
$G_1$で4分の1サイズ(1024x512)の画像を生成,画像特徴を$G_2$でも使用し,画像をrefineし出力(2048x1024).
$G_1$には512x512のstyle transferで良い結果が得られた手法[22]のネットワークを使用.
学習時には初めに$G_1$を訓練し,その後$G_2$を訓練した後に全体でfine-tuning.
Multi-scale discriminators
高解像度の画像を判別するには大きな受容野が必要となる
→ そのためには深い構造や大きな畳み込みフィルタが必要
→ 大きなメモリが必要に,過学習の原因に
→ 元サイズ,2分の1サイズ,4分の1サイズの生成画像を判別する同じ構造のdiscriminator $D_1, D_2, D_3$を用意することで解決
\min_G\max_{D_1, D_2, D_3}\sum_{k=1, 2, 3}L_{GAN}(G, D_k)
Improved adversarial loss
discriminatorの角層の特徴マップでfeature matching lossを定義.
$k$番目のdiscriminatorの$i$層目の特徴マップを$D_k^{(i)}(s, x)$と表記.
L_{FM}(G, D_k) = \mathbb{E}_{(s, x)}\sum_{i=1}^T\frac{1}{N_i}\Bigl[\bigl|\bigl|D_k^{(i)}(s, x) - D_k^{(i)}(s, G(s))\bigr|\bigr|_1\Bigr]
最終的に以下の問題を解く.
\min_G\biggl(\Bigl(\max_{D_1, D_2, D_3}\sum_{k=1, 2, 3}L_{GAN}(G, D_k)\Bigr) + \lambda\sum_{k=1, 2, 3}L_{FM}(G, D_k) \biggr)
Using Instance Maps
入力とするセマンティックセグメンテーション画像では同じクラスの個体までは区別しない.
個体まで区別したいが,one-hot vectorなどで与えると,クラスごとでチャンネル数が異なってしまい現実的な解決法ではない.
→ 今回は個体の情報として個体間の境界線(instance boundary map,4近傍が異なるobject IDなら1,それ以外は0)を入力に与える.
以下はinstance boundary mapの例.
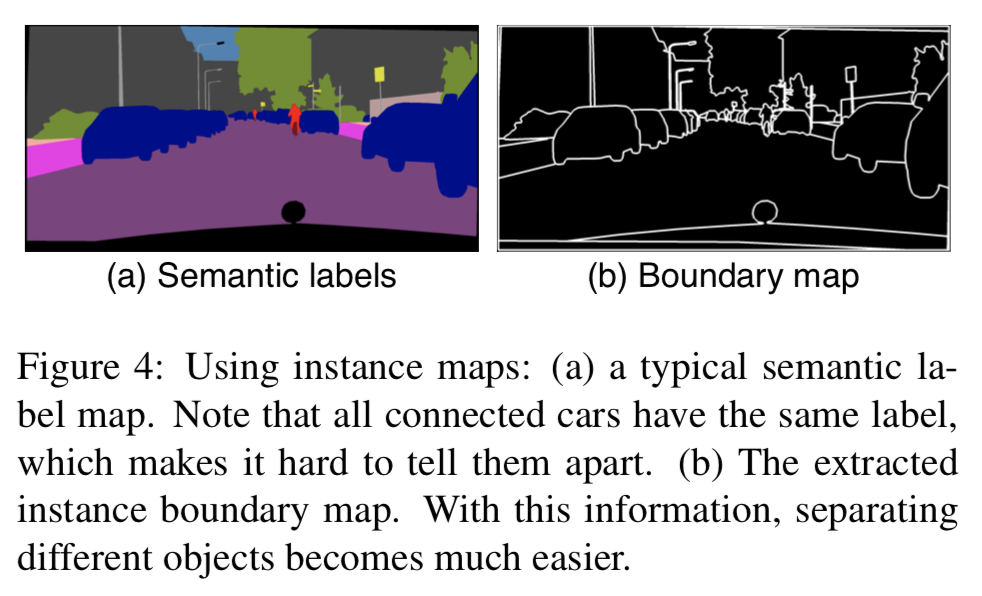
以下はinstance boundary mapの有無の比較.

Learning an Instance-level Feature Embedding
生成画像に多様性を持たせたり,ユーザーが生成画像をインスタンスレベルで操作できるように,低次元の画像特徴を入力に加える.
インスタンスの真値に対応した低次元特徴を抽出できるようにencoder-decoder network $E$を学習する.
ロス関数中の$G(s)$は$G(s, E(x))$に置き換えられる.
- 学習済みの$E$を使って,画像中の全てのインスタンスの特徴をエンコード
- 同じクラスに属する特徴量をK-meansクラスタリング
- こうすることで同じ"road"クラスでも asphalt や cobblestone textureを区別できる
- 推論時には同じクラス中から適当にエンコード済みの特徴を取ってくる
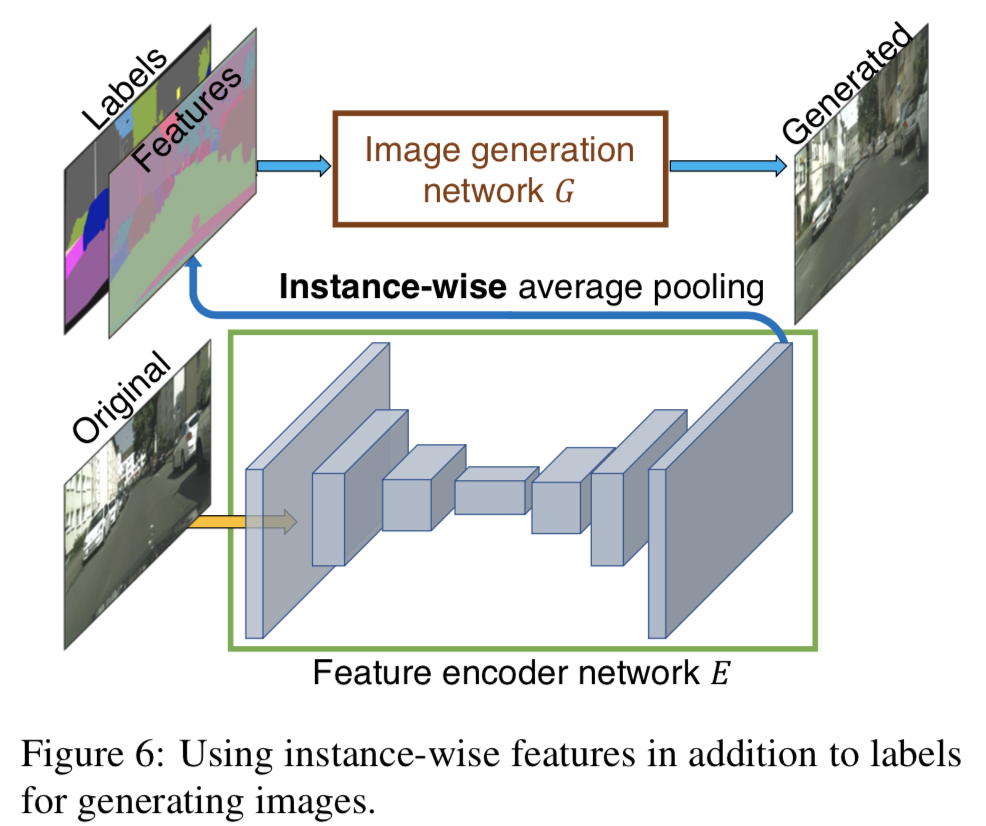
どうやって有効性を検証したか
Implementation details
- LSGANs を使用
- loss の重み$\lambda = 10$
- $K=10$ for K-means
- perceptual loss $\lambda\sum_{i=1}^{N}\frac{1}{M_i}\bigl[||F^{(i)}(x) - F^{(i)}(G(s))||_1\bigr]$も追加して実験
Datasets
- Cityscapes dataset
- NYU Indoor RGBD dataset
- ADK29K dataset
- Helen Face dataset
Baselines
- pix2pix
- CRN
Quantitative Comparisons
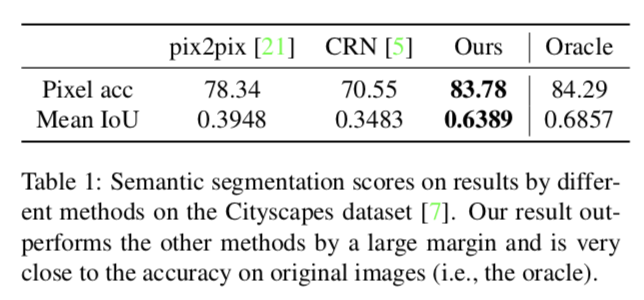
セマンティックセグメンテーション画像を入力としてリアルな画像を生成するタスクを評価.
生成した画像をPSPNetでセマンティックセグメンテーションした結果で比較.
以下の表は生成画像をPSPNetでセマンティックセグメンテーションした結果.
Oracle はオリジナル画像でセマンティックセグメンテーションした結果(理論的な上限).
提案手法で生成した画像が最も良い結果になっている(Oracle に近いことから,最もリアルな画像だ生成できていると言える).
Human Perceptual Study
人間にどちらの生成画像が好ましいかを判断してもらう.
-
Unlimited time
- 人間に2枚の画像をじっくりと見てもらって判断してもらう
-
Limited time
- 人間に2枚の画像を限られた時間だけ見てもらって判断してもらう
- 時間は1/8 ~ 8秒に設定
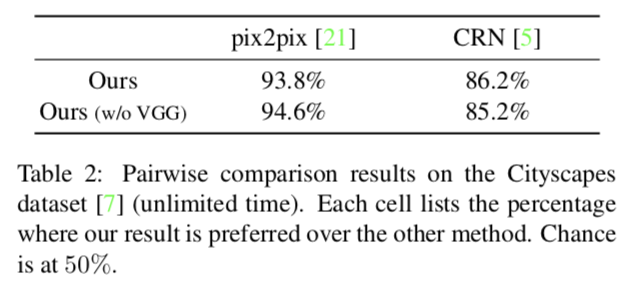
以下の表はUnlimited timeの結果.
9割近くの被験者が提案手法が優れていると判断している.
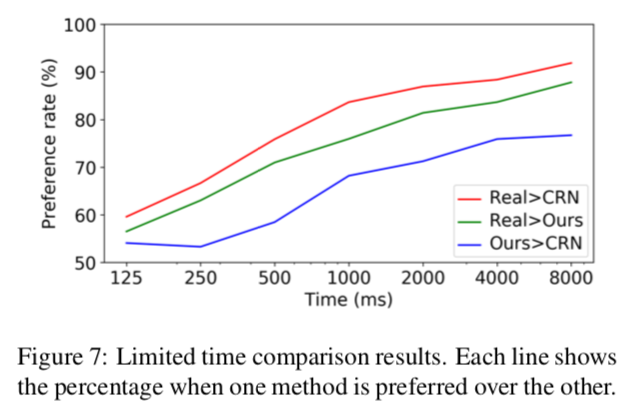
以下のグラフは設定時間毎のLimited timeの結果.
提案手法の方が"Real"に近い画像を生成できていると言える.
以下はそのときの生成画像の例.
より詳細な画像を生成できている.


- Using instance maps
- 64.34%の人がinstance maps有りで学習した画像を好ましいと判断した
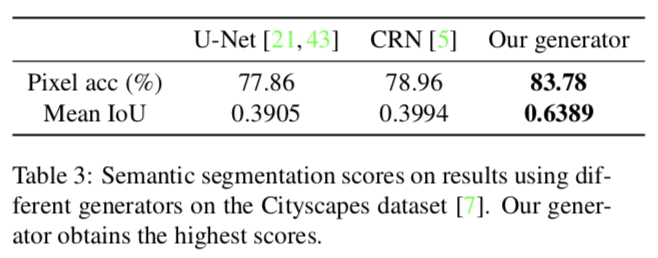
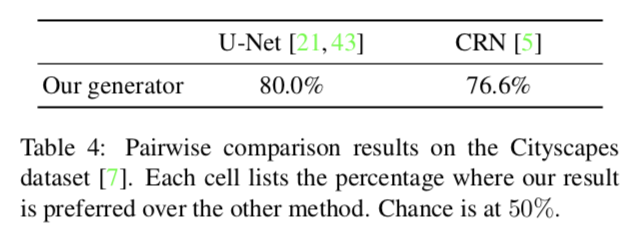
- Analysis of the generator
- generatorの構造をU-Net, CRNの場合と比較
以下の表はgeneratorの構造を変えた場合の比較結果.
提案手法がより良い結果を出している.
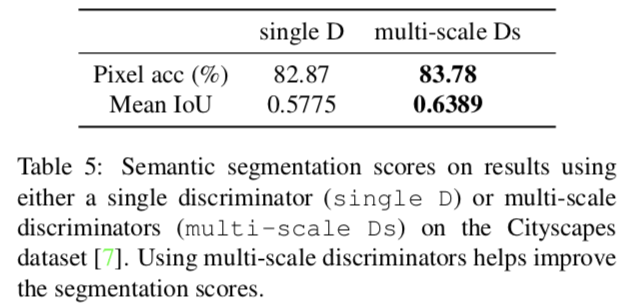
- Analysis of the discriminator
- multi-scale discriminators と only one discriminator で比較
- generator と ロス関数は固定
- 69.2%の人が multi-scale discriminators で生成した画像が好ましいと判断した
以下の表は multi-scale discriminators と only one discriminator の比較結果.
- Additional datasets
- NYU dataset, ADE20K dataset で実験
以下は2つのデータセットによる生成画像の例.


Interactive Object Editing
与えるインスタンスレベルの特徴を変更することで生成画像をinteractiveに変更できる.
以下はその生成画像の例.


議論はあるか
- Conditional GANsを用いた高解像度なリアルな画像生成手法を提案.
- インスタンスレベルの特徴を与えることで生成画像のtextureをinteractiveに変更することが可能.