Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, Bryan Catanzaro
NVIDIA, MIT CSAIL
NIPS2018
arXiv, pdf, project page, movie, github
どんなもの?
GANを用いて(例えばセマンティックセグメンテーション)画像シーケンスから(リアルな)画像シーケンスを生成する手法を提案.
以下はCityscapesによる結果.
左上が入力画像,右上がpix2pixHD [70],左下がCOVST [8],右下が提案手法のvid2vid.

先行研究との差分
- Conditional GANを用いて高解像度の画像を生成可能(2K (1920x1080) の画像を30秒以内に生成可能)
- 入力画像のラベル情報を入れ替えることで(treeをbuildingなどに変更),生成する画像を操作可能
- style transfer, future video predictionのstate-of-the-artの性能を上回る
技術や手法のキモ
source画像のシーケンス,targetの真値画像シーケンス,生成画像のシーケンスをそれぞれ
s_1^T = \{s_1, s_2, \dots, s_T\} \\
x_1^T = \{x_1, x_2, \dots, x_T\} \\
\tilde{x}_1^T = \{\tilde{x}_1, \tilde{x}_2, \dots, \tilde{x}_T\}
とし,以下のような分布を学習するのが目的.
p(\tilde{x}_1^T|s_1^T) = p(x_1^T |s_1^T)
これを学習するために以下のミニマックス問題を解く.
\max_D\min_GE_{(x_1^T, s_1^T)}[\log D(x_1^T, s_1^T)] + E_{(s_1^T)}[\log (1 - D(G(s_1^T), s_1^T))]
しかし,これを解くことは難しいので,以下のようにしてgenerator, discriminatorを設計する.
Sequential generator F
source画像から画像を生成する条件付き確率を以下のように積の形に分解.
これは生成される画像は,現在のsource画像$s_t$,過去$L$枚のsource画像$s_{t-L}^{t-1}$,過去$L$枚の生成画像$\tilde{x}_{t-L}^{t-1}$に依存することを意味する.($L=2$)
p(\tilde{x}_1^T|s_1^T) = \prod_{t=1}^{T}p(\tilde{x}_t | \tilde{x}_{t-L}^{t-1}, s_{t-L}^{t})
なので
\tilde{x}_t = F(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t})
のようなネットワーク$F$を学習する.
オプティカルフロー,hallucination(幻覚?),オクルージョンなどを考慮して,以下のように$F$を定義する.
F(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t}) = (1 - \tilde{m}_t) \odot \tilde{w}_{t-1}(\tilde{x}_{t-1}) + \tilde{m}_t \odot \tilde{h}_t
- estimated optical flow
\tilde{w}_{t-1} = W(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t})
- hallucinated image
\tilde{h}_t = H(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t})
- occlusion mask
\tilde{m}_t = M(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t})
$M$, $W$, $H$はresidual network architecture.
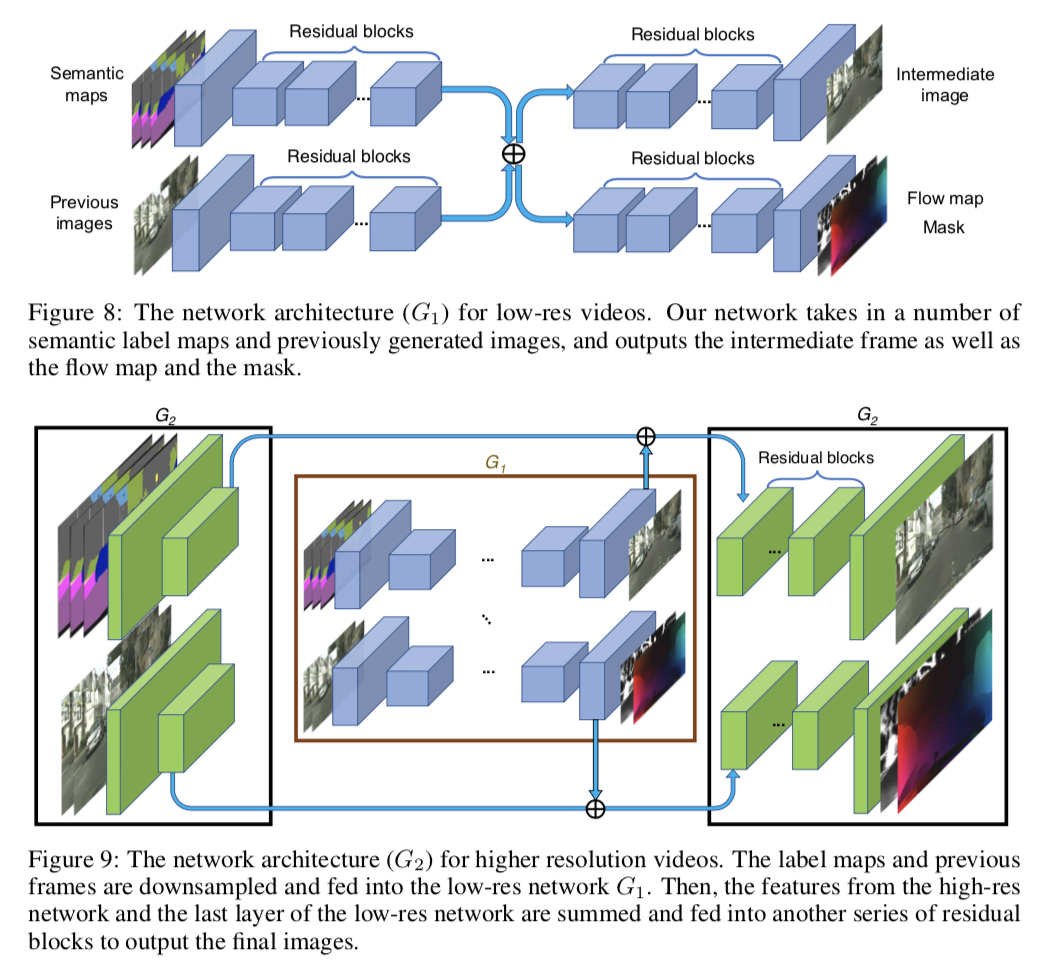
このgeneratorは[70](
同じ筆者のCVPR2018の論文)を参考に設計され,coarse-to-fineに($G_1$→$G_2$にrefine)画像を生成する.
Conditional discriminator DI and DV
discriminator $D_I$は生成画像か真の画像かを判別する.
discriminator $D_V$は生成画像シーケンスか真の画像シーケンスかを判別する.
ランダムに画像をサンプリングする$\phi_I$とランダムに$K$枚の画像シーケンスをサンプリングする$\phi_V$を定義する.
(ランダムに自然数$i$をサンプリングする)
\phi_I(x_1^T, s_1^T) = (x_i, s_i) \\
\phi_V(w_1^{T-1}, x_1^T, s_1^T) = (w_{i-K}^{i-2}, x_{i-K}^{i-1}, s_{i-K}^{i-1})
以上の関数を使って以下のミニマックス問題を定義.
\min_F(\max_{D_I}L_I(F, D_I) + \max_{D_V}L_V(F, D_V)) + \lambda_WL_W(F) \\
L_I = E_{\phi_I(x_1^T, s_1^T)}[\log D_I(x_i, s_i)] + E_{\phi_I(\tilde{x}_1^T, s_1^T)}[\log (1 - D_I(\tilde{x}_i, s_i))] \\
L_V = E_{\phi_V(w_1^{T-1}, x_1^T, s_1^T)}[\log D_V(x_{i-K}^{i-1}, w_{i-K}^{i-2})] + E_{\phi_V(w_1^{T-1}, \tilde{x}_1^T, s_1^T)}[\log (1 - D_V(\tilde{x}_{i-K}^{i-1}, w_{i-K}^{i-2}))] \\
L_W = \frac{1}{T-1}\sum_{t=1}^{T-1}(||\tilde{w}_t - w_t||_1 + ||\tilde{w}_t(x_t) - x_{t+1}||_1)
flow loss $L_W$は生成したフローが真のフローと似ているか,そのフローで移動したフレームが次のフレームと似ているかを測る.
Foreground-background prior
ラベルにはbuildingやroadのようなbackground areaのものと,carやpedestrianのようなforeground areaのものが存在する.
それを考慮してhallucination function $H$を分解して再定義することでより良くなるらしい.(foregroundのオプティカルフローを求めるのは難しいので,hallucinationでカバーする感じ?)
F(\tilde{x}_{t-L}^{t-1}, s_{t-L}^{t}) = (1 - \tilde{m}_t) \odot \tilde{w}_{t-1}(\tilde{x}_{t-1}) + \tilde{m}_t \odot ((1 - m_{B, t}) \odot \tilde{h}_{F, t} + m_{B, t} \odot \tilde{h}_{B, t})
$m_{B, t}$は$s_t$のbackground areaの真値マスク.
Multimodal synthesis
同じセマンティックセグメンテーション画像を入力しても,バリエーションに富んだフレームを生成するためにfeature embedding scheme [70]を適用する.
インスタンスレベルの情報を特徴マップに付与するものらしい.
どうやって有効性を検証したか
4種類のデータセットで実験.
- Cityscapes [11]
- Apolloscape [27]
- Cityscapesと同様にしてデータを作成
- Face video dataset [54]
- sketch video to face video synthesis taskに使用
- face alignment algorithm [35]でスケッチ画像を生成
- Dance video dataset
2種類の従来手法と比較.
- pix2pixHD [70]
- state-of-the-artのimage-to-image translation手法
- ビデオの毎フレームに適用して実験
- COVST
- [8]のstylization networkをpix2pixHDで置き換えたもの
- オプティカルフローを使って時間方向に一貫性の取れた画像を生成する
- 入力のオプティカルフローには真値フローを使用(提案手法は推定したフローを使用)
評価指標は2つ.
- Human preference score
- FréchetInceptionDistance(FID)[25]
Main results
以下の表は,Cityscapesを使用した実験結果(Apolloscapeの表は割愛).
提案手法が最もFIDが小さく,人間にも好まれる動画を生成できていることが分かる.

以下の動画はApolloscapeによる実験で生成された動画(Cityscapesの結果はページトップ).
(左がpix2pixHD,中央がCOVST,右が提案手法のvid2vid.)

以下の表は,提案手法とそこから色々な要素を省いたものの比較.
どの要素も重要.

Multimodal results
以下はroad部分の特徴ベクトルを変えたもの.

Semantic manipulation
以下はラベル情報を入れ替えて生成したもの.
左は全てのtreeラベルをbuildingと入れ替えたもの.
右はbuildingラベルをtreeと入れ替えたもの.

Sketch-to-video synthesis
以下はスケッチから現実的な画像を生成したもの.

Pose-to-video synthesis
以下は姿勢推定結果から現実的な画像を生成したもの.
見えていない部分(姿勢推定からは分からない)の体型もうまく処理できている.
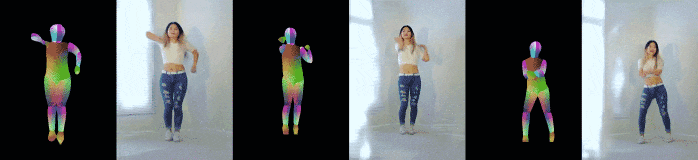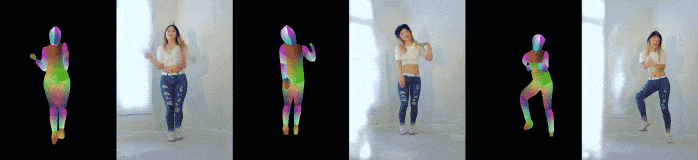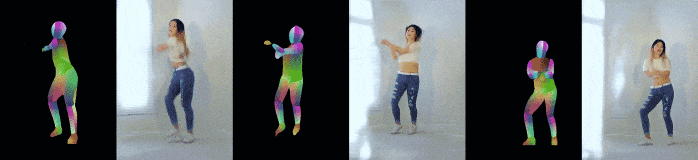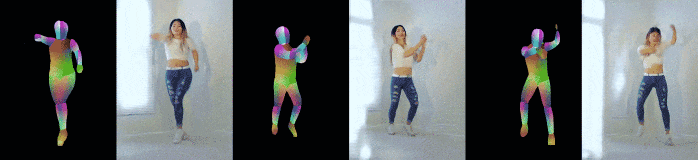
Future video prediction
これまでのフレームからセマンティックセグメンテーション結果を推定し,それを使用して画像を生成するように拡張.
state-of-the-artの2種類の手法と比較.
PredNet[42], MCNet[65].
以下の表から,提案手法が最もFIDが小さく,人間に好まれる動画を生成できていることが分かる.
動画から,比較手法は時間が進むにつれて画像の質が落ちているが,提案手法は質と一貫性を保てている.


議論はあるか
-
Conditional GANを用いたVideo-to-Video synthesisの手法を提案
-
generatorとdiscriminatorの設計を工夫することで,高解像度で現実的な時空間的に一貫性のとれたフレームを生成する
-
image-to-imageやfuture video prediction taskのstate-of-the-artの手法を上回った
-
Limitations
- depth情報が無いためか,方向転換する車の生成が難しい
- 登場する物体の時間的な一貫性が保証できない(車の色が変わったり)
- ラベル情報を操作した際にアーティファクトが発生する(buildingとtreeの形が異なることから)
次に読むべき論文
この研究で使われたGAN
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs