はじめに
cyokozaiと申します.
千葉にある工業大学に通っています.
さて,今年もあと僅かとなりました.
今回は最適化問題を解く手法として知られているメタヒューリスティクス (Metaheuristics) について話します.
「メタヒューリスティクス」という用語を初めて聞いた方も多いかと思います.
大学で情報工学を専攻した人は「遺伝的アルゴリズム」の方が馴染み深いのではないでしょうか?
メタヒューリスティクスは機械学習と並んで歴史の深い情報工学の分野のひとつです.
これを読めばあなたもメタヒューリスティクスの面白さがわかるかもしれません.
ここで話すこと
- メタヒューリスティクスの楽しさ・面白さ
- 有名な最適化アルゴリズムの紹介
- メタヒューリスティクスの活用法
- 近年のメタヒューリスティクスの動向
ここで話さないこと
- 最適化問題やアルゴリズムに関連する数式や証明の解説
- 離散最適化問題
- 競プロなどで使えるテクニックなど
- 最適化アルゴリズムの解説
まずは,最適化問題とは何なのかについて簡単に説明をし,次にメタヒューリスティクスに関するあれこれを話していきます.
最適化問題
最適化 (Optimization) とは,普段私たちが何か意思決定をしたり問題解決を行う際に,与えられた制約の中で最もうまく問題を解決するための手段です.
特に数理最適化 (Mathematical optimization) の文脈で言うならば,「与えられた制約条件 (Constraint) のもと,目的関数 (Objective function) $f(x)$ を最大 / 最小にするような解(最適解 (Optimal solution))を求める問題」となります.
ちょっと日本語がややこしくなったので,ここでは最小化問題 (Minimization problem) について数式で簡単に整理します1.
数理最適化問題の一般的定義
決定変数を $x$,目的関数を $f(x)$ とすると,最適化問題は一般に以下の形式で記述されます2.
$$
\min_x f(x) \quad \text{subject to} \quad x \in S \quad (S \subseteq X).
$$
変数 $x$ は実数ないし整数の要素からなるベクトルで与えられます.
最適化問題の性質から探索空間 $X$ を導くのですが,大抵の場合は制約条件を満たした部分集合である $S$ について探索 (Exploration) を行います.
この集合 $S$ を特に実行可能領域 (Feasible region) と呼びます.
最適化問題の分類
最適化問題 (Optimization problem) は連続最適化 (Continuous optimization problem) と離散最適化 (Discrete optimization problem) の2種類に分類でき,問題の特徴ごとにさらに細かく分類します.
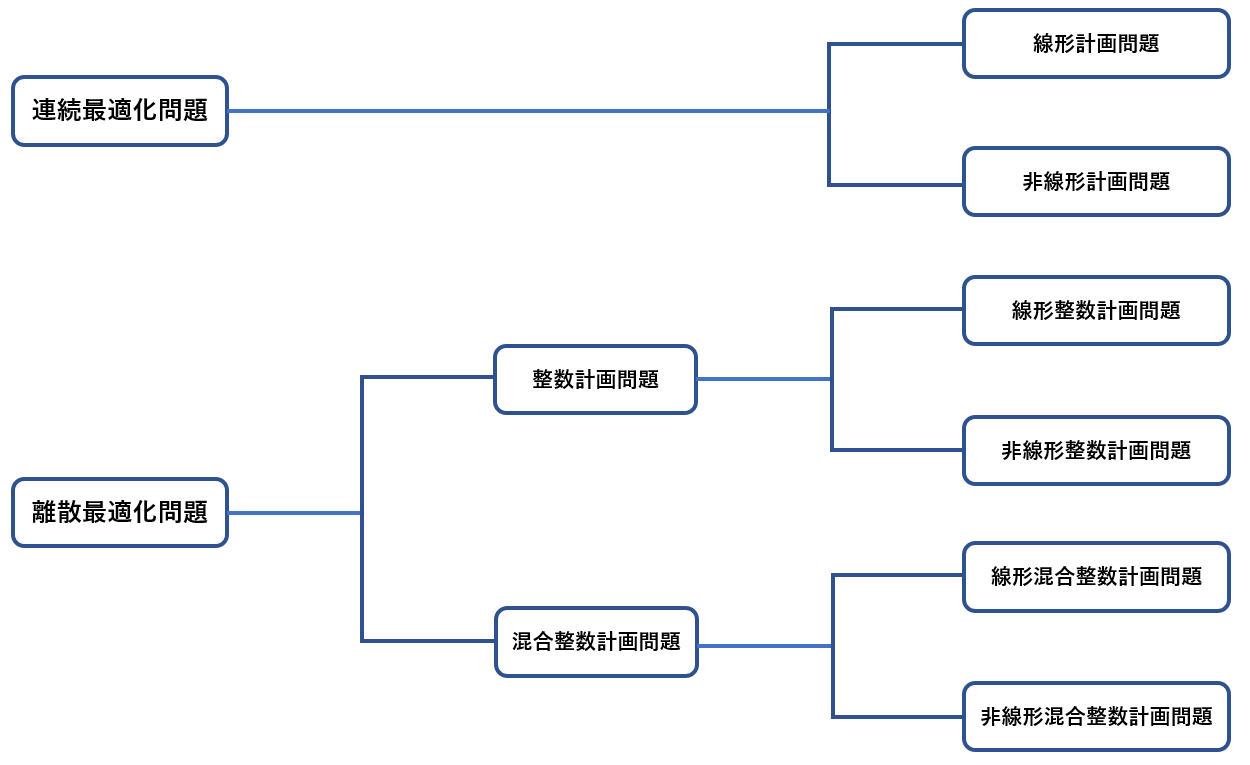
図1: 数理最適化問題の分類 (引用元)
本稿では連続最適化問題の特に非線形計画問題についてのみ扱います.
さて,目的関数は非常に様々で,非線形や多峰性などあらゆる種類が存在します.
図2 は最適化の難しさと目的関数の特徴の関係性を示した図です.
(a) ~ (e) はそれぞれ目的関数の形状を表しています.
- (a): 単峰性の関数
- (b): 多峰性の関数
- (c): 不連続点が存在する関数
- (d): 多峰性かつ深い谷が存在する関数
- (e): 不連続点が存在し非接続な関数
目的関数の特徴によっては,勾配降下法が使えなかったり,局所最適解 (Locally optimal solution) に陥りやすかったりするため,如何に本来求める大域最適解 (Globally optimal solution) を効率よく求めるかが重要になってきます.
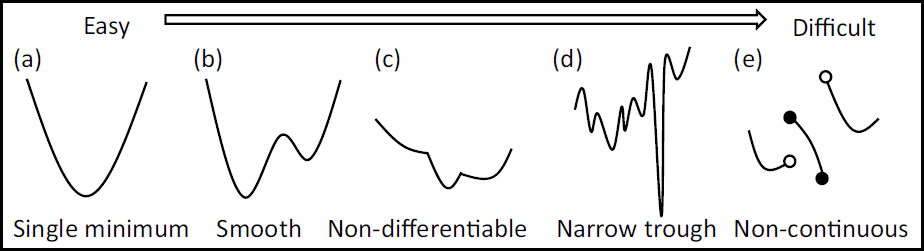
図2: 評価関数の形状の分類 (引用元)
最適化アルゴリズム
最適化を行うアルゴリズムを最適化アルゴリズム (Optimization algorithms) と呼びます.
アルゴリズムには大きく分けて以下の2種類が存在します.
- 厳密解法 (Exact Methods)
時間はかかっても,真の最適解を必ず求められる手法- 主な手法:
線形計画法,動的計画法,混合整数計画法など - メリット:
得られた解が理論上の真の最適解であることを保証できる
小規模な問題に対しては非常に強力 - デメリット:
問題の規模 (変数や制約条件) が大きくなると,組み合わせ爆発により計算時間が指数関数的に増大する
複雑な実社会の巨大な問題には現実的でない場合がある
- 主な手法:
- 近似解法 (Approximation/Heuristic Methods)
実用的な時間内で最適解の近似値(準最適解 (Suboptimal solution))を求める手法- 主な手法:
遺伝的アルゴリズム,焼きなまし法,貪欲法など - メリット:
厳密解法では一生終わらないような巨大な問題でも,現実的な時間で解を出せる
アルゴリズムの設計に柔軟性があり,複雑な制約条件を扱いやすい - デメリット:
得られた解が最良である保証はなく,たまたま見つけた局所最適解で止まってしまう可能性がある
- 主な手法:
どちらにもメリット・デメリットがあり,対象となる問題の性質や制約条件に応じて最適化アルゴリズムを選択します.
近似解法についてもう少し深掘りましょう.
ソフトコンピューティング
厳密な解 (Hard Computing) を求めることが困難な場合に,ある程度の不確かさを許容しつつ,実用的な解を柔軟に求める計算手法の総称をソフトコンピューティング (Soft computing) と呼びます.
人間の脳のような柔軟な情報処理を目指す分野であり,メタヒューリスティクス,ファジィ理論,ニューラルネットワークなどもここに含まれます.
ソフトコンピューティングの分野には以下の 3 つの重要な特性があります.
- Big Picture Thinking (大局的思考):
細部の厳密さに囚われすぎず,全体としての正しさや調和を重視すること - Flexibility (柔軟性):
環境の変化や不確実性に対して,頑健に適応できること - Subjectivity (主観性):
客観的な唯一解だけでなく,状況に応じた納得解を導き出すこと
近似解法の枠組み
最適化アルゴリズムのアルゴリズム設計の要素は,主に図3 の (i) ~ (iii) に分類されます.
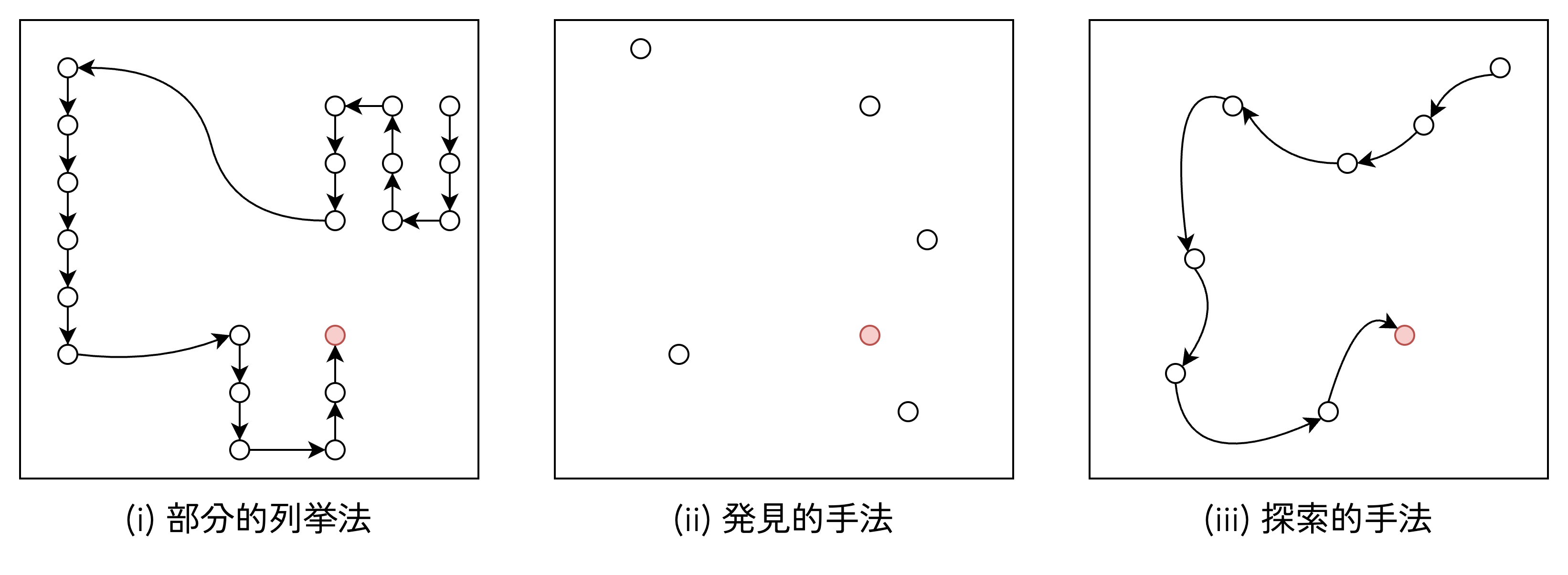
図3: 近似解法の基本的な考え方
(i): 部分的列挙法
実行可能解の一部を規則的に列挙し,その中で最も良い解を選択する手法です.
図の左側のように,しらみつぶしに近い形で順番に解を確認していくイメージです.
解の空間が小さい場合は確実に最適解を見つけられますが,問題が複雑になると計算時間が膨大になりすぎてしまう欠点があります.
(ii): 発見的手法 (ヒューリスティック)
経験則や直感,あるいは特定のルールに基づいて,解の候補をランダムに生成・評価する手法です.
図の中央のように,解空間の中に点在する候補をピンポイントで確認していくイメージです.
「だいたいこの辺りに正解がありそうだ」というルールを使うため,計算時間は短いですが,厳密解が得られる保証はありません.
(iii): 探索的手法
現在の解から,より良い解へと逐次的に探索を繰り返して最適解を目指す手法です.
図の右側のように,ある地点からスタートして,より良い結果が出る方向へ矢印を伸ばして進んでいくイメージです.メタヒューリスティクスはこのアプローチを高度化したもので,大域的な探索と局所的な探索をうまくバランスさせながら,効率よく最適解に近づこうとします.
メタヒューリスティクス
メタヒューリスティクス (Meta-heuristics) は,「高次の」「超越した」という意味の接頭辞メタ (meta) と「発見的法則」「経験則」という意味のヒューリスティック (heuristics) が合わさった用語です.
最適化アルゴリズムでは,ある数理最適化問題について特化した手法を考案します.
しかし,他の数理最適化問題に応用することが難しいという欠点がありました.
そこで,数理最適化問題を求解するためのアルゴリズム設計に必要な考え方の総称として,メタヒューリスティクスと呼ばれるようになりました.
メタヒューリスティクスの探索アルゴリズムは,最適解の多様化を目指す大域探索と,より良い解を集中的に求める局所探索の組み合わせで構成されています.
この探索は繰り返し何度も実行され,その探索フェーズの中では多様化と集中化がバランスよく行われます.
- 多様化:
探索が局所最適解で停滞することを避けるため,未探索の空間をランダムに探索する - 集中化:
過去の探索で求めた最適解と似た構造を持つ解を集中的に探索する
次元の呪いと向き合う
数理最適化問題は一般的に比較的高次元な構造を有しています.
問題設計にもよりますが,10次元前後の比較的簡単な問題から100次元以上の高次元問題も珍しくありません.
ここでは,次元の大きさが如何にして最適化アルゴリズムの探索を阻むのかについて紹介します.
次元の呪い
次元数が増えることは,単に計算量が増える以上の質的な変化をもたらします.
次元の呪い(Curse of Dimensionality) とは,探索空間の次元数が増加するにつれて,空間の体積が指数関数的に増大し,解を探索することが困難になる現象を指します.
直感的に理解するために,探索空間を均等なグリッド(格子点)で区切ってしらみつぶしに探すケースを考えてみましょう.
図4 左側のように探索範囲を 10 分割する場合を考えます.
- 1次元の場合: 探索点は $10^1 = 10$ 個
- 2次元の場合: 探索点は $10^2 = 100$ 個
- 3次元の場合: 探索点は $10^3 = 1,000$ 個
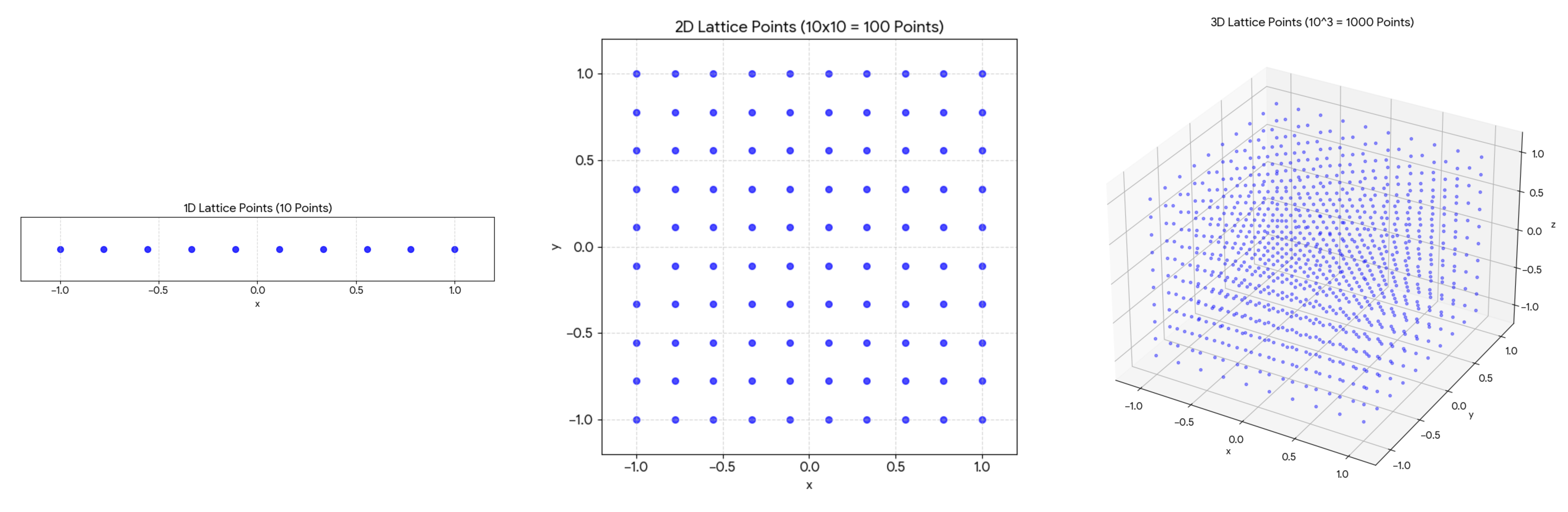
図4: 格子点の増加の様子
ここまではまだ想像の範疇ですが,これが例えば 20次元 になるとどうなるでしょうか.
必要な探索点は $10^{20}$ 個にもなります.
この点を全て探索することは現実的でないと理解していただけるでしょうか.
また高次元空間では,空間がスカスカな疎になり,ランダムに点を打っても最適解の近くに落ちる確率は低くなります.
これが,単純な探索手法が高次元問題で役に立たなくなる主な理由です.
球面集中現象
高次元空間には,私たちの3次元的な直感が通用しない不思議な性質があります.
その代表例が球面集中現象 (Concentration of Measure) です.
高次元の球体において,その体積のほとんどは表面の近くに集中するという現象です.
例えば,高次元のリンゴがあると想像してください.
皮の厚さが半径のわずか数%だったとしても,高次元ではその「皮」の部分に体積の 99.9...% が含まれてしまう,なんてことが起こります.
これは実験で確認が可能で,二つの球の体積の差を見ることで球面集中現象を再現できます.
図5 は表面から厚さ $0.1$ ($10 \text{%}$) の殻を考え,その中に含まれる体積の割合 $1 - (1 - 0.1)^d$ をプロットしました.
次元 $d$ が30を超えると,たった10%の厚さの殻の中に,球全体の体積の90%以上が含まれてしまうことがわかります.
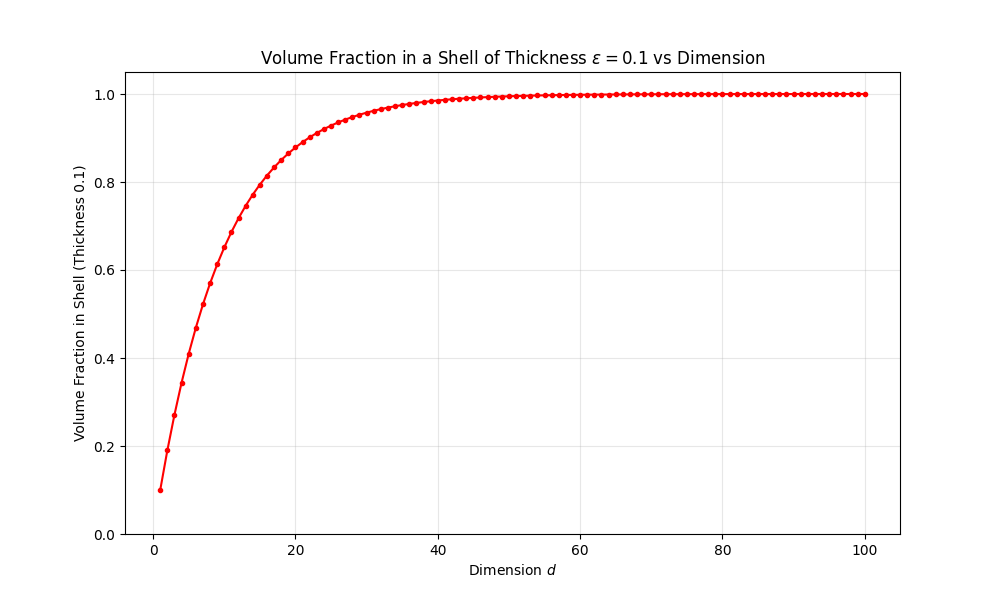
図5: 次元と殻の体積比率の関係
もうひとつ例をお見せします.
正規分布に従う点が原点からどのくらいの距離に分布するかをヒストグラムで示しました.
青い分布 ($d=1, 10$) は原点付近に確率密度が高いことがわかります.
右側の分布 ($d=50, 100, 500$) になると次元 $d$ が増えるにつれて,原点付近の確率はほぼ $0$ になり,分布のピークが $\sqrt{d}$ 付近に移動していく様子が見て取れます.
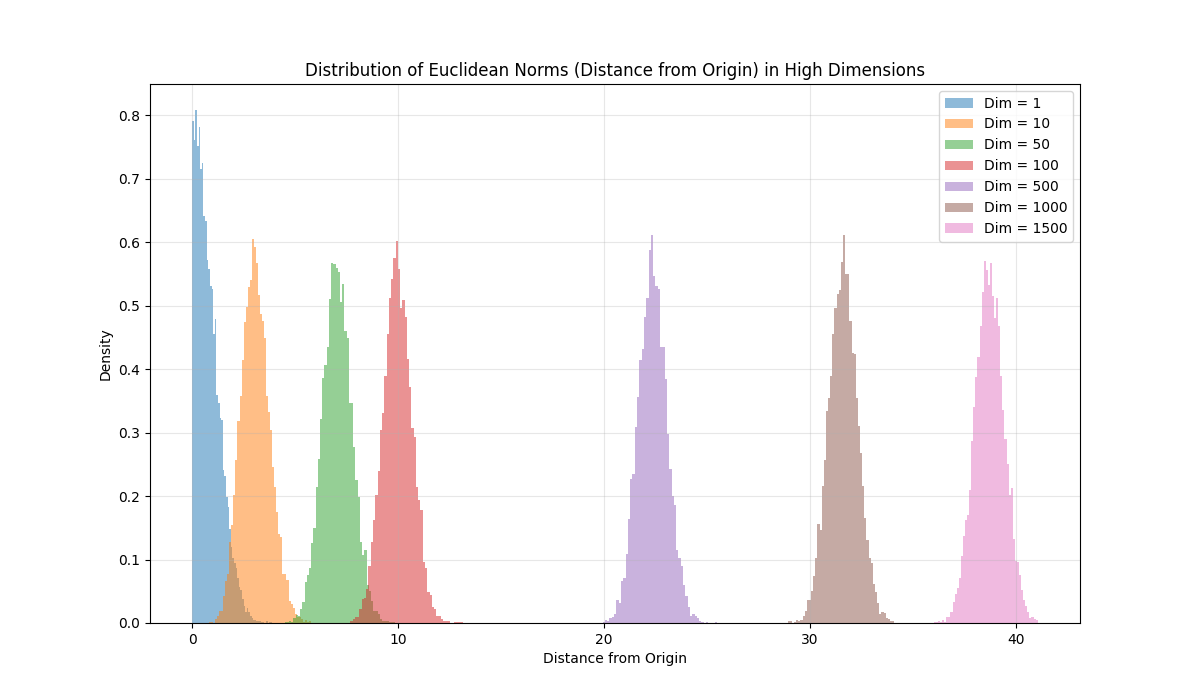
図6: 球面集中現象の様子
これを最適化問題に置き換えると,探索空間を高次元の超球と見なした場合,ランダムに生成した初期解のほとんどは,空間の中心付近ではなく端っこに配置されることを意味します.
中心付近に最適解がある場合,ランダムサーチではそこにたどり着くことすら困難になります.
また,高次元空間では「どの点とどの点の距離もだいたい同じになる」という現象も発生し,距離の近さを頼りにする探索手法の効率を悪化させます.
高次元への対策
次元の呪いや球面集中現象に対抗するため,メタヒューリスティクスでは以下のような戦略が重要になります.
- 多点探索 (群知能) の活用:
1つの解だけを更新するのではなく,複数の個体 (群れ) を空間に放ち,互いに情報を共有しながら探索します
下手な鉄砲も数撃ちゃ当たるの理屈 - 探索と活用のバランス:
広大な空間を闇雲に探す探索だけでなく,見つけた有望な谷を徹底的に降りていく活用のバランスを動的に調整します
これにより,無駄な空間の探索を早めに切り上げ,可能性のある領域に計算リソースを集中させます - 強力な局所探索:
大域的な探索だけでは高次元の谷底をピンポイントで当てることは不可能です
ある程度良い場所を見つけたら,そこから勾配情報や近傍探索を用いて,一気に解を局所最適解へ落とし込むハイブリッドなアプローチが有効です
この他にも,探索次元の次元削減を行ったり,複数の最適化アルゴリズムを組み合わせるなど,多種多様な戦略で高次元最適化問題に取り組んでいます.
メタヒューリスティクスはここが面白い
メタヒューリスティクスは物理現象や生物の生態など,様々な数理モデルから着想を得てアルゴリズムを構築します.
つまり,最適化アルゴリズムの鍵となる現象は,私たちの身の回りに溢れかえっているのです.
この着眼点を持つと,日々の生活の中で「あっこれアルゴリズムにできないかな」と気付く場面が増えました.
ここからは,そんなメタヒューリスティクスの有名なアルゴリズムをいくつか紹介します
多種多様なアルゴリズム
メタヒューリスティクスには,自然界の現象や生物の行動から着想を得たユニークなアルゴリズムが数多く存在します.
中でも遺伝的アルゴリズムやアリコロニー最適化などはポピュラーなアルゴリズムとして,日夜研究が進められています.
次章のデモで使用できるアルゴリズムについて紹介します
- 遺伝的アルゴリズム (GA):
生物の進化過程を模倣した手法
親となる個体を選び(選択),遺伝子を混ぜ合わせ(交叉),稀に突然変異を起こすことで,環境に適応した強い個体(解)を世代交代の中で進化する - 差分進化 (DE):
個体間のベクトルの差分を利用して新しい解を作り出す手法
シンプルながら非常に強力で,連続最適化問題において高い性能を発揮します - 粒子群最適化 (PSO):
鳥の群れや魚の魚群行動を模倣した手法
各粒子が「自分が見つけた最良の場所」と「群れ全体で見つけた最良の場所」の両方の情報を頼りに移動を行う - 人工蜂コロニー (ABC):
ミツバチが蜜源を探す行動を模倣した手法
収穫蜂,追従蜂,偵察蜂という役割分担を行い,効率よく最適解を探索します
銀の弾丸は存在しない
これだけ多くのアルゴリズムがあると,「結局どれが最強なの?」と気になるところですが,残念ながらあらゆる問題に対して万能な最強のアルゴリズムは存在しません.
これを数学的に証明したのが ノーフリーランチ定理 (No Free Lunch Theorem) です.
ある特定のクラスの問題に対して性能が良いアルゴリズムは,別のクラスの問題に対しては性能が劣る可能性があります.
だからこそ,私たちは最適化問題の性質 (凸か非凸か,変数の数は多いか少ないか,など) を見極め,適切な最適化アルゴリズムを選定・パラメータチューニングする必要があります.
この試行錯誤や工夫の余地は,メタヒューリスティクスの醍醐味と言っても過言ではありません.
メタヒューリスティクスを体験する
百聞は一見に如かず.
数式や理論の説明だけではイメージしづらい「群れの動き」や「収束の様子」を実際にブラウザ上で確認できるデモサイトを作成しました.
リポジトリは公開しています.
Rust と WebAssembly で実装しました.
使い方
スタートを押すと探索が開始されます
| 項目 | 内容 |
|---|---|
| Dimensions | 次元数 |
| Populations | 個体数 |
| Max Generations | 最大反復回数 |
| Benchmark | 目的関数(ベンチマーク関数) |
| Algorithm | 最適化アルゴリズム |
メタヒューリスティクスの応用例
ちょっと思いつきで実験をしてみました.
確率勾配降下法と差分進化を用いてニューラルネットワークの損失関数 (Loss function) を最小化の過程を比較します.
ソースコードは Gemini に作成してもらいました.
使用言語は Julia です.
ソースコード
using Flux
using Metaheuristics
using Statistics
using CairoMakie
using LinearAlgebra
using Random
# --- 1. 準備 ---
# データ生成
X_range = range(-2π, 2π, length=100)
X = reshape(collect(X_range), 1, :)
Y = sin.(X)
# モデル定義 (共通)
# 構造を定義
chain_struct = Chain(Dense(1 => 2, tanh), Dense(2 => 1))
# 初期パラメータと再構築関数を取得
p_init, re = Flux.destructure(f64(chain_struct))
D = length(p_init)
# 目的関数 (DE用: ベクトルを受け取る)
function objective_function(x)
m = re(x)
preds = m(X)
return min(mean(abs2, preds .- Y), 1e5) # 外れ値対策でキャップ
end
# --- 2. 差分進化 (DE) の実行 ---
println("--- [DE] 最適化開始 ---")
path_history_de = Vector{Vector{Float64}}()
function logger_de(status)
# 各世代の最良個体を記録
push!(path_history_de, copy(minimizer(status)))
end
# DEの設定
bounds = boxconstraints(lb = -5.0ones(D), ub = 5.0ones(D))
opts = Options(f_calls_limit = 50000, f_tol = 1e-5)
alg_de = DE(N=50, options=opts)
result_de = optimize(objective_function, bounds, alg_de, logger=logger_de)
best_params_de = minimizer(result_de)
println("DE 完了: ステップ数 $(length(path_history_de)), 最終Loss: $(minimum(result_de))")
# --- 3. 確率的勾配降下法 (SGD/GD) の実行 ---
println("--- [SGD] 最適化開始 ---")
path_history_sgd = Vector{Vector{Float64}}()
# SGD用にモデルを再初期化
model_sgd = f64(chain_struct)
p_current, _ = Flux.destructure(model_sgd)
push!(path_history_sgd, copy(p_current)) # 初期位置保存
# オプティマイザ設定
opt_state = Flux.setup(Flux.Descent(0.05), model_sgd)
sgd_epochs = 1000
for epoch in 1:sgd_epochs
# 勾配計算
grads = Flux.gradient(model_sgd) do m
preds = m(X)
mean(abs2, preds .- Y)
end
# パラメータ更新
Flux.update!(opt_state, model_sgd, grads[1])
# 履歴保存
p_now, _ = Flux.destructure(model_sgd)
push!(path_history_sgd, copy(p_now))
end
println("SGD 完了: ステップ数 $(length(path_history_sgd))")
# --- 4. 射影平面の作成 ---
# 基準点: DEの最適解
theta_star = best_params_de
# ランダムな2方向ベクトルを作成 (正規化)
Random.seed!(42)
dir1 = randn(D); dir1 /= norm(dir1)
dir2 = randn(D); dir2 -= (dot(dir1, dir2) * dir1); dir2 /= norm(dir2)
# --- 5. 軌跡データの射影計算関数 ---
function project_trajectory(history, center, d1, d2)
t_alpha, t_beta, t_z = Float64[], Float64[], Float64[]
for param in history
diff = param - center
push!(t_alpha, dot(diff, d1))
push!(t_beta, dot(diff, d2))
push!(t_z, objective_function(param))
end
return t_alpha, t_beta, t_z
end
# DEとSGDそれぞれの射影座標を計算
de_alpha, de_beta, de_z = project_trajectory(path_history_de, theta_star, dir1, dir2)
sgd_alpha, sgd_beta, sgd_z = project_trajectory(path_history_sgd, theta_star, dir1, dir2)
# --- 6. プロット作成 ---
println("--- グラフ描画中 ---")
# (a) 背景グリッド計算
grid_res = 50
range_lim = 3.0
alphas = range(-range_lim, range_lim, length=grid_res)
betas = range(-range_lim, range_lim, length=grid_res)
mse_grid = zeros(grid_res, grid_res)
for (i, a) in enumerate(alphas)
for (j, b) in enumerate(betas)
p = theta_star + a .* dir1 + b .* dir2
mse_grid[i, j] = objective_function(p)
end
end
z_limit = 2.0
mse_grid_clamped = min.(mse_grid, z_limit)
de_z_clamped = min.(de_z, z_limit)
sgd_z_clamped = min.(sgd_z, z_limit)
# (b) Makieによる描画
fig_traj = Figure(size = (1000, 700))
ax = Axis3(fig_traj[1, 1],
title = "Optimization Trajectory: DE vs SGD",
xlabel = "Direction 1", ylabel = "Direction 2", zlabel = "Loss (MSE)",
azimuth = 1.2pi, elevation = 0.1pi,
aspect = (1, 1, 0.5)
)
# 1. 地形
surface!(ax, alphas, betas, mse_grid_clamped, colormap = :plasma, shading = FastShading, alpha=0.4)
# 2. DEの軌跡
lines!(ax, de_alpha, de_beta, de_z_clamped, color = :black, linewidth = 3, label="DE (Evolution)")
# 【追加】DE Start (緑色の球)
scatter!(ax, [de_alpha[1]], [de_beta[1]], [de_z_clamped[1]], color=:green, markersize=15, label="DE Start")
# DE Final (赤色の球)
scatter!(ax, [de_alpha[end]], [de_beta[end]], [de_z_clamped[end]], color=:red, markersize=15, label="DE Final")
# 3. SGDの軌跡
lines!(ax, sgd_alpha, sgd_beta, sgd_z_clamped, color = :dodgerblue, linewidth = 3, label="SGD (Gradient)")
# SGD Start (青色の球)
scatter!(ax, [sgd_alpha[1]], [sgd_beta[1]], [sgd_z_clamped[1]], color=:blue, marker=:circle, markersize=10, label="SGD Start")
# SGD Final (水色の四角)
scatter!(ax, [sgd_alpha[end]], [sgd_beta[end]], [sgd_z_clamped[end]], color=:cyan, marker=:rect, markersize=15, label="SGD Final")
# 凡例表示
axislegend(ax)
save("optimization_comparison.png", fig_traj)
println("比較画像を 'optimization_comparison.png' に保存しました.")
実行すると図7 のような画像が出力されます.
差分進化は緑の点がスタート,赤の点が求まった大域最適解です.
確率勾配降下法は青の点がスタート,水色の点が求まった大域最適解です.
図を見ると,差分進化は谷底にある厳密解へ向けて大域探索と局所探索を駆使して進んでいる様子がわかります.
対して,確率勾配降下法は損失関数に沿って探索を行なっている様子が確認できます.
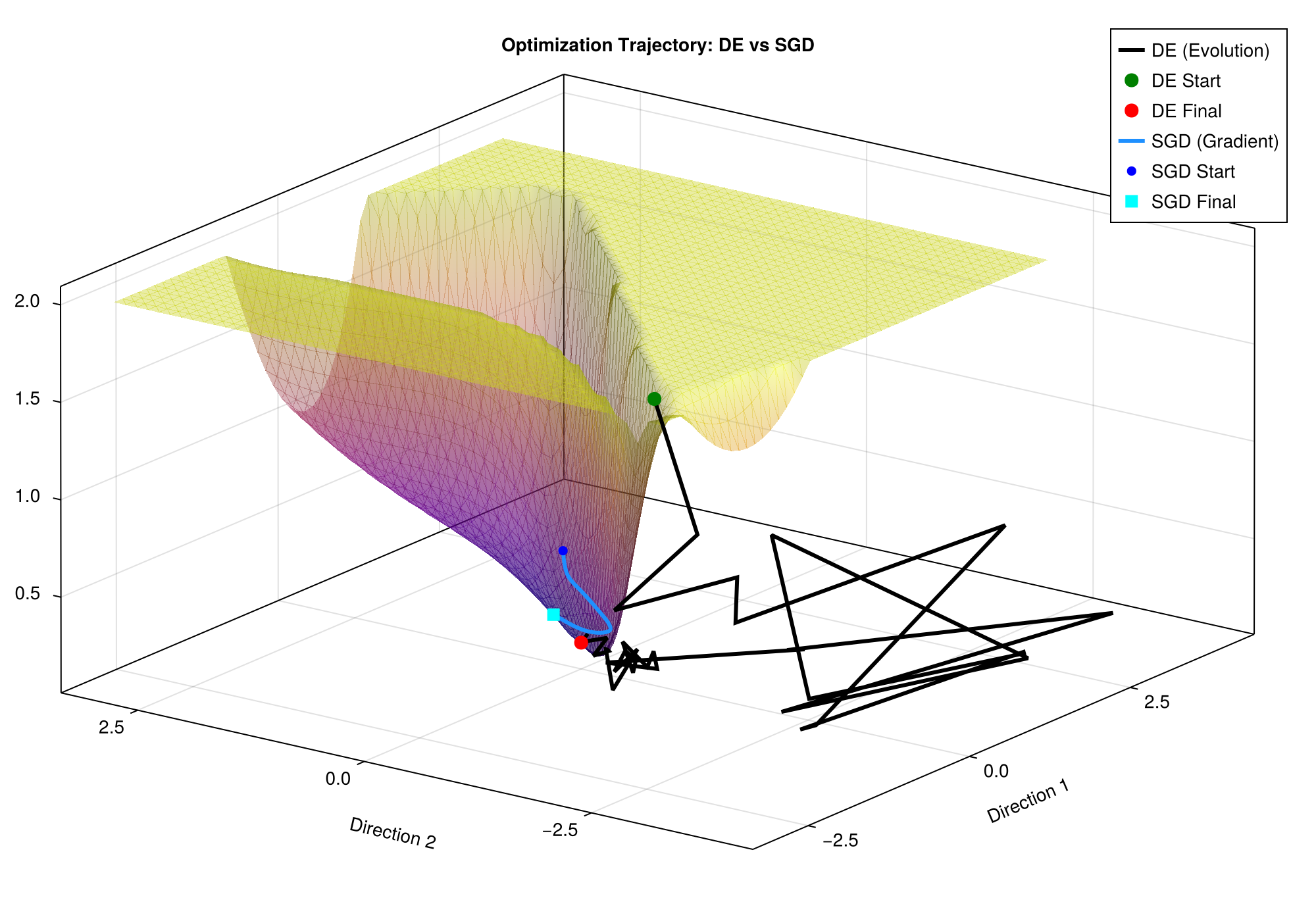
図7: 損失関数と探索の様子
メタヒューリスティクスの未来
多様性の追求
これまでの最適化は一つの大域最適解を見つけることがゴールでした.
しかし,現実世界の問題では性能は最高だけど実装コストが高すぎる解や,性能はそこそこだけど壊れにくい解といった現実世界の制約が存在します.
そこで注目されているのが Quality Diversity (QD) という概念です.
これは単に評価値を上げるだけでなく,解の特徴が異なるものをニッチとして捉え,積極的に類似の個体を残そうとするアプローチです.
例えばロボットの歩き方を学習させる際,「速く移動する」という観点だけでなく,「片足を引きずって速く歩く」「スキップしながら速く歩く」など,多種多様な「正解」を同時に探索します.
多様な最適解を持つことで,環境が急変しても生き残れるような,真にロバストな知能の実現が期待されています.
機械学習/LLM
近年,大規模言語モデル (LLM) の発展に伴い,機械学習とメタヒューリスティクスの融合が急速に進んでいます.
これまでは,遺伝的アルゴリズムとニューラルネットワークを組み合わせた Neuro-Evolution of Augmenting Topologies (NEAT) という,ネットワーク構造を変化させてより最適なニューラルネットワークを構成するアルゴリズムが有名でした.
近年では例えば,これまで人間が手作業で調整していたアルゴリズムのパラメータを AI に自動調整させる AutoML や,Algorithm Evolution using LLM という LLM 自身に新しい最適化アルゴリズムのコードを書かせる試みも始まっています.
AI が AI を進化させる手段は既に現実のものとして最適化の分野でその存在感を増してきています.
おわりに
今回は自分の研究分野を中心に,最適化問題から探索まで深く掘り下げてみました.
最適化問題は,物流のルート配送からシフト作成,AIのパラメータ調整まで,社会の至る所に潜んでいます.
このような厳密な解を求めることが難しい現実の複雑な問題に対して,確率と経験則,そして自然界の知恵を借りて挑むメタヒューリスティクスはロマンがあると思いませんか?
この記事を読んで面白そうだなと感じた方は,是非自分でアルゴリズムを書いて動かしてみてください.
参考資料