KubernetesからGPUを使ってTensorflowを動かす
Kubernetes 1.8ではα版(実験的)機能としてPodからGPUを使うことが可能になっています。
KubernetesからGPUを使うメリットは、ディープラーニングとコンテナ・オーケストレーションを組み合わせられることです。
ディープラーニングのトレーニングフェーズではGPUを使うことでスピードアップするのが一般的です。
NvidiaもDockerからGPUとCUDAを使うためのNvidia Dockerを提供しており、コンテナ上でGPUを使うのは有効な手段として広まっていっていると感じます。
KubernetesでもGPU使用が要望されており、現在はα版として使用可能になっています。
KubernetesからGPUを使う方法
詳しくは以下で書かれていますが、ホストサーバにインストールしたNvidia CUDAやCudnnのライブラリをPodにマウントして呼び出す仕組みになっています。
https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
なお、Kubernetes on GPUをKubernetes1.6で試している例もありますので、こちらも参考になります。
https://github.com/Langhalsdino/Kubernetes-GPU-Guide
環境
インフラ、ソフトウェアは以下を使います。
- 基盤:Google Cloud Platform(GCP)のCloud Engine(仮想マシン)1台
- スペック:4CPU, 15GB RAM, 100GB SSD, 1GPU(Nvidia K80)
- OS:Ubuntu16.04
- Docker CE 17.03
- Kubernetes 1.8
- Nvidia CUDA 8.0
- Nvidia Cudnn 6.0
- Podのコンテナイメージ:gcr.io/tensorflow/tensorflow:latest-gpu(現時点ではPython2.7、Tensorflow1.4)
各ソフトウェアのバージョンは、現時点(2017年11月)でいろいろ試した結果、うまくいった組み合わせです。
バージョン合わせるのって大変ですよね。
GCPを使ったのは仮想マシンの配備が速い&分単位課金だからです。
ソフトウェアのバージョンを変えつつ、安定して動かすのに何回も作って壊してを繰り返したので、すぐ作り直せてお金も無駄にならないことが必要でした。
・・・なんて思っていたら、AWS EC2は秒単位課金になっていたんですね(驚き)。
http://www.itmedia.co.jp/news/articles/1709/19/news049.html
まあ今回使うKubernetesもTensorflowもGoogle発ですし、クラウドもGoogleで揃えて良いでしょう。
構築
それでは早速構築していきます。
GCPのCloud EngineでUbuntu16.04仮想マシンを1台配備したら、まずはアップデートしてDocker CEをインストールして諸々設定します。
Docker CEのインストール方法は以下をご参照ください。
https://docs.docker.com/engine/installation/linux/docker-ce/ubuntu/
https://kubernetes.io/docs/setup/independent/install-kubeadm/
# update Linux and install docker
sudo su -
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
apt-get -y update && apt-get -y upgrade
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/docker.list
deb https://download.docker.com/linux/$(lsb_release -si | tr '[:upper:]' '[:lower:]') $(lsb_release -cs) stable
EOF
apt-get update && apt-get install -y curl apt-transport-https git vim jq docker-ce=$(apt-cache madison docker-ce | grep 17.03 | head -1 | awk '{print $3}')
# start docker
systemctl start docker && systemctl enable docker
# set network
cat << EOF > /tmp/host
localhost
10.10.0.2
EOF
mkdir -p ~/.ssh/
for i in $(cat /tmp/host); do ssh-keyscan -H $i >> ~/.ssh/known_hosts ; done
続いてCUDAとCudnnのインストールです。
KubernetesからGPUを使うときはホストサーバのライブラリを読み込むので、ホストサーバ側にCUDAとCudnnが必要になります。
CUDAもCudnnもバージョン指定でインストールします。
https://developer.nvidia.com/cuda-toolkit
## find nvidia GPU
lspci | grep -i nvidia
# install requirements for cuda and cndnn
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb
apt-get -y update
apt-get -y install --allow-unauthenticated cuda-8-0
echo 'export CUDA_HOME=/usr/local/cuda' >> /etc/profile
echo 'export PATH=/usr/local/cuda-8.0/bin:${PATH}' >> /etc/profile
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:/usr/lib/nvidia-384:/usr/lib/nvidia:${CUDA_HOME}:${LD_LIBRARY_PATH}' >> /etc/profile
source /etc/profile
CUDAはwgetでインストーラを入手できますが、Cudnnはブラウザからダウンロードしたものを仮想マシンにアップロードする必要があります。
以下のコマンドの前に、Cudnnをダウンロードして仮想マシンにアップロードしておいてください。
CudnnのダウンロードにはNvidiaへの登録とアンケート回答が必要になります。
https://developer.nvidia.com/rdp/cudnn-download
# prerequisite: upload cudnn to the server
tar zxvf cudnn-8.0-linux-x64-v6.0.tgz
cp cuda/include/cudnn.h /usr/local/cuda/include
cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
nvcc --version
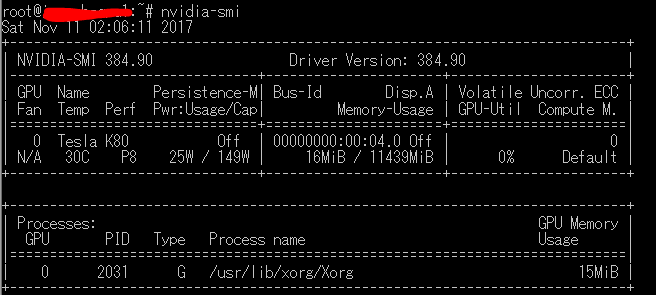
nvidia-smi
以下のようにGPUが認識されていることを確認してください。
続いてKubernetesをインストールします。
Kubeadmで構築しますので、まずはKubeadmをインストールします。
https://kubernetes.io/docs/setup/independent/install-kubeadm/
# install kube tools
apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get -y update
apt-get install -y --allow-unauthenticated kubelet kubeadm kubectl kubernetes-cni
KubernetesでGPUを使うためには、Kubeletの起動コマンドに--feature-gates=Accelerators=trueオプションを追加する必要があります。
このオプションは/etc/systemd/system/kubelet.service.d/配下の*-kubeadm.confファイルに追記することで追加可能です。
FILE_NAME=$(ls /etc/systemd/system/kubelet.service.d/*-kubeadm.conf)
sed -i '/^ExecStart=\/usr\/bin\/kubelet/ s/$/ --feature-gates=Accelerators=true/' ${FILE_NAME}
systemctl daemon-reload
systemctl restart kubelet
KubeadmからKubernetesクラスターを構築します。
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
# initialize kubeadm and kube cluster
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=$(hostname -i)
systemctl enable kubelet && systemctl start kubelet
systemctl status kubelet -l
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
kubectl cluster-info
# install flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.0/Documentation/kube-flannel.yml
kubectl get pods --all-namespaces
今回はマスター1台のみの構成にするので、マスターへのデプロイを有効化します。
# allow deployment to Kubernetes master
kubectl taint nodes --all node-role.kubernetes.io/master-
稼働確認として靴下ショップをデプロイします。
# deploy sample sock-shop app
kubectl create namespace sock-shop
kubectl apply -n sock-shop -f "https://github.com/microservices-demo/microservices-demo/blob/master/deploy/kubernetes/complete-demo.yaml?raw=true"
kubectl -n sock-shop get svc front-end
kubectl get pods -n sock-shop
無事デプロイできたら消します。
# delete after deployment
kubectl delete namespace sock-shop
KubernetesからGPUを使ってTensorflowを動かす
これで構築完了です。
それではKubernetesのPodからGPUを使ってTensorlfowを動かします。
Podの定義ymlは以下です。
環境変数にCUDAやCudnn等Nvidia GPUライブラリへのパスを設定します。
また、Kubernetesはホストサーバのライブラリを使ってGPUを動かすので、ホストサーバのCUDAやCudnn等Nvidia GPU系のディレクトリをコンテナにマウントします。
(いろいろマウントしまくっていますが、もしかしたら不要なものもあるかもしれません・・・)
cat <<- EOF > kubegpu.yml
kind: Pod
apiVersion: v1
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: gcr.io/tensorflow/tensorflow:latest-gpu
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
env:
- name: CUDA_HOME
value: '/usr/local/cuda'
- name: PATH
value: '/usr/local/cuda-8.0/bin:${PATH}'
- name: LD_LIBRARY_PATH
value: '/usr/local/cuda-8.0/lib64:/usr/lib/nvidia-384:/usr/lib/nvidia:${CUDA_HOME}:${LD_LIBRARY_PATH}'
volumeMounts:
- mountPath: /usr/lib/nvidia-384/bin
name: bin
- mountPath: /usr/lib/nvidia-384
name: lib
- mountPath: /usr/local/cuda-8.0
name: cuda
- mountPath: /usr/lib/x86_64-linux-gnu
name: gnu
- mountPath: /usr/bin/nvidia-smi
name: nvs
- mountPath: /usr/local/cuda/lib64
name: clib64
- mountPath: /usr/local/cuda/include
name: include
volumes:
- hostPath:
path: /usr/lib/nvidia-384/bin
name: bin
- hostPath:
path: /usr/lib/nvidia-384
name: lib
- hostPath:
path: /usr/local/cuda-8.0
name: cuda
- hostPath:
path: /usr/lib/x86_64-linux-gnu
name: gnu
- hostPath:
path: /usr/bin/nvidia-smi
name: nvs
- hostPath:
path: /usr/local/cuda/lib64
name: clib64
- hostPath:
path: /usr/local/cuda/include
name: include
EOF
動かしてみましょう。
# create pod
kubectl create -f kubegpu.yml
# see if it is running
kubectl get pods
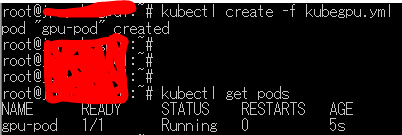
起動(Running)になったらpodにログインし、GPUを認識しているか確認してみましょう。
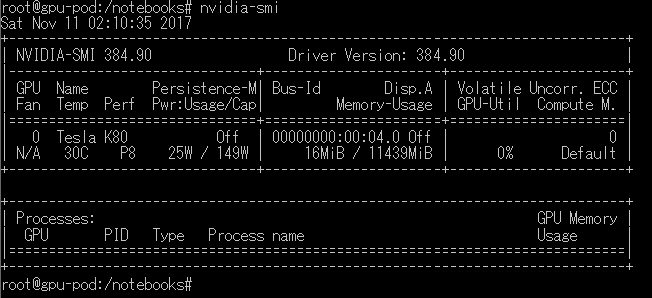
kubectl exec -it gpu-pod /bin/bash
nvidia-smi
GPUを認識できていたら、以下のように表示されます。
最後にTensorflowからGPUを使えるか試してみましょう。
プログラムは以下のものを使用しています。
https://www.tensorflow.org/tutorials/using_gpu
cat << EOF > ten.py
import tensorflow as tf
# Creates a graph.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(c))
EOF
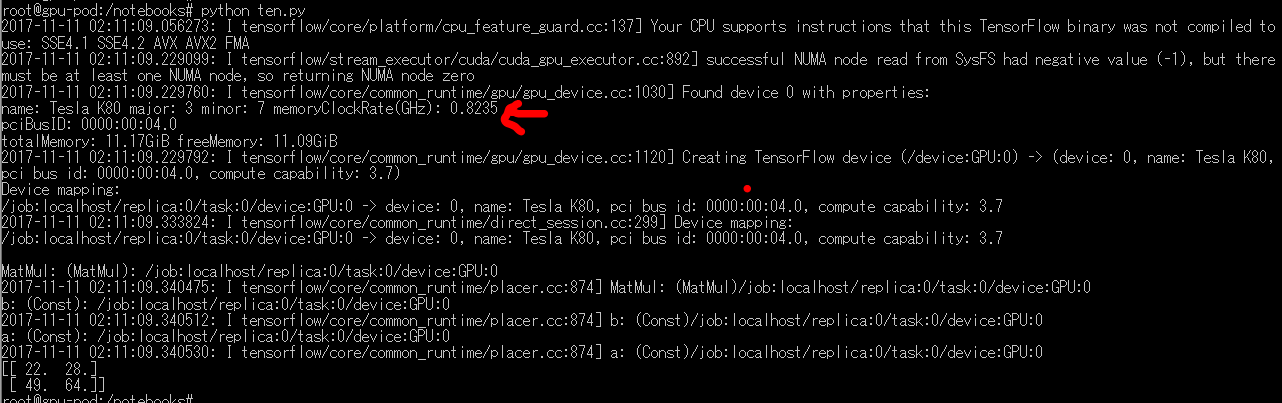
python ten.py
試しに上記のような簡単な計算を動かしていますが、無事GPUを認識して利用しているようです。
最後に
KubernetesからGPUを使ってTensorflowを動かすことができました。
ディープラーニングのトレーニングは一時的な稼働になることが多く、都度コンテナで環境を用意するのがちょうど良いと思います。
ディープラーニングを活用し始めると、違うモデル作成のために多数のコンテナを適時デプロイしてトレーニングを実行することになると思います。
そのためにはKubernetesのようなコンテナ・オーケストレーションが便利です。
コンテナでディープラーニングを行うためにNvidia-dockerでGPUを使う方法が有効ですが、多数のコンテナを管理しようとなると、KubernetesでGPUを使う必要が出てきます。
今回はこの両方のニーズを実現する方法を紹介しました。
KubernetesからGPUを使うのはまだ実験的なα版機能ですが、はやくGAしてもっと手軽に使えるようになってほしいものです。