Spark × Keras × Dockerでディープラーニングをスケーラブルにしてみた
2017年2月にYahoo!からTensorFlowをSparkで分散処理させるライブラリが出ました。
http://yahoohadoop.tumblr.com/post/157196317141/open-sourcing-tensorflowonspark-distributed-deep
これを個人的にDockerに乗せて遊んだりしていたのですが、じゃあKerasはどうなの?ってことで、今回はKerasをSparkで分散処理させるDist-KerasをDockerで動かしてみようと思います。
目標はディープラーニングライブラリをスケーラブルに利用することです。
GPGPUの活用によりディープラーニングはスケールアップ方面に力を入れている感じがします。
しかし、処理の高速化を演算装置の性能に求めるスケールアップと、演算装置の数に求めるスケールアウトを組み合わせればより高速な処理ができるようになる筈です。
さらに言えば、個人的にはGPUを持っていない貧乏人はスケールアウトで頑張ってみようという思いがあります(こっちのほうが切実(笑))。
そこで、DockerコンテナにディープラーニングライブラリのKerasを登載して、コンテナを複数起動してスケールアウトによる負荷分散ができないか、試してみました。
通常のKerasだとスケールアウトできないので、今回はKerasをSparkで動かすライブラリを使います。
Keras on Spark
KerasをSparkで分散処理するライブラリは2つあるようです。
ひとつめはElephasで、こちらは一年くらい前からあったようです。
http://maxpumperla.github.io/elephas/
もうひとつはDist-Kerasで、これはCERN(欧州原子核研究機構!)が出しているものです。
http://joerihermans.com/work/distributed-keras/
https://db-blog.web.cern.ch/blog/joeri-hermans/2017-01-distributed-deep-learning-apache-spark-and-keras
CERNといえばSTEINS;GATEのSERNの元ネタです。
CERNも岡部倫太郎をご存知のようです。
http://gigazine.net/news/20140623-ama-cern/
今回やること
今回はCERNのDist-KerasをDockerで動かして、MNISTを実行してみようと思います。
Dist-Kerasを選んだ理由は、単純に最近も更新されているのと、ちゃんと動いたからです。
Elephasも途中までは触ってみたので、またそのうち遊び出すかもしれません。
Dist-KerasをDockerで動かす理由は、コンテナの方が仮想マシンよりも簡単に環境を用意できるからです。
EC2を複数台たてても良いのですが、費用がかさむと困るので、1台の仮想マシンにDockerを3コンテナ起動しました。
1台がSparkマスター兼ワーカー(スレーブ)、残りがワーカーです。
このような構成になります。
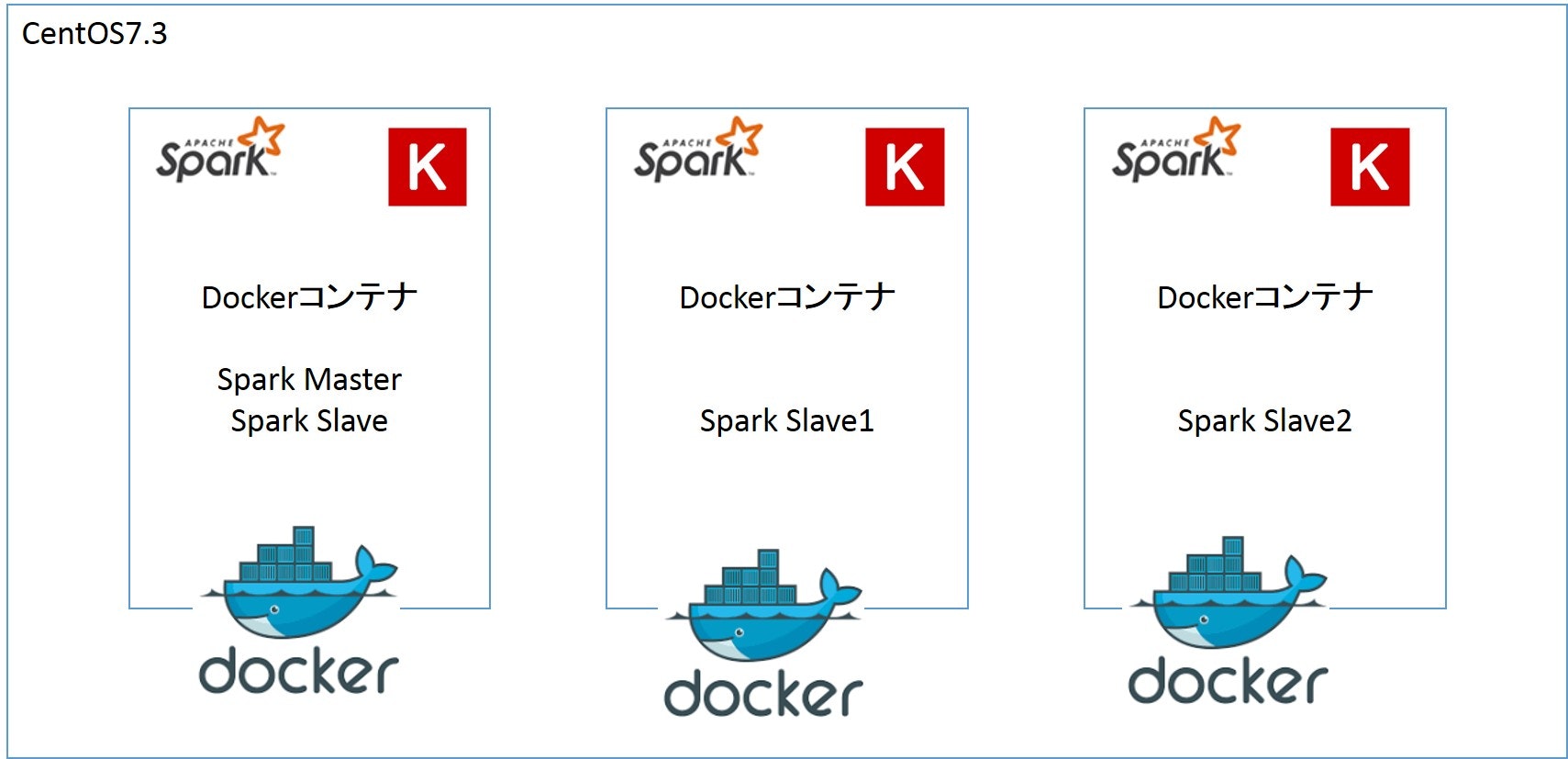
Dist-Keras
Dist-KerasについてはCERNが熱く語っていますので、こちらを読みましょう。
一部意訳しておきます。
Distributed Keras
Distributed KerasはApache SparkとKerasを用いて作られた分散型ディープラーニングフレームワークである。目的は機械学習の学習時間を大きく改善し、メモリ容量以上のデータセットを分析することを可能にすることである。このプロジェクトは2016年8月にCMSとの協同で開始された。
Architecture
基本的に、学習プロセスはLambdaファンクションによってSparkワーカーに渡される。しかし、例えばパラメータ・サーバのポート番号のような複数のパラメータを渡す場合、我々はそれらを全てオブジェクトで包み、Sparkに必要なパラメータを使える学習ファンクションに仕立て上げた。全体を俯瞰するため、以下の図で説明しよう。学習オブジェクトはまず、Sparkドライバーでパラメータ・サーバを起動する。続いてワーカー・プロセスを起動する。それにはKerasのモデルを学習するために必要なパラメータとプロセスが全て内包されている。更に、必要な数の並列処理を行うワーカーを用意するため、データセットを定められた容量で分割する。しかし、ビッグデータを処理する場合、並列処理の要素を増やすことが望ましい。そうすることで、あるワーカーがアイドルになっている一方で、他のより能力の低いワーカーがバッチを回し終わっていない状態を避けることができる(これをstraggler problemという)。こういう場合には、Sparkのドキュメントにあるように、分散要素を3に設定することを推奨する。
ただし、より大きな分散要素の使用を検討する必要がある場合もある。基本的に、分散処理とはパーティションの数(分割数)と比例する。たとえば、あるタスクに20ワーカーを割り当て、分散要素を3に設定したとしよう。Sparkはデータセットを60シャードに分割する。そしてワーカーはパーティションを処理し始める前に、まずはタスクを処理するために必要な全Pythonライブラリをロードする必要があり、更にはKerasモデルを非シリアル化してコンパイルしなければならない。この処理は大きなオーバーヘッドとなる。そのため、この技術は長いウォームアップのオーバーヘッドが必要な非異質なシステム(つまり、各ワーカーに異なったハードウェアまたは値のロードが生じる場合)で、大きなデータセットを扱う場合のみ有効である。
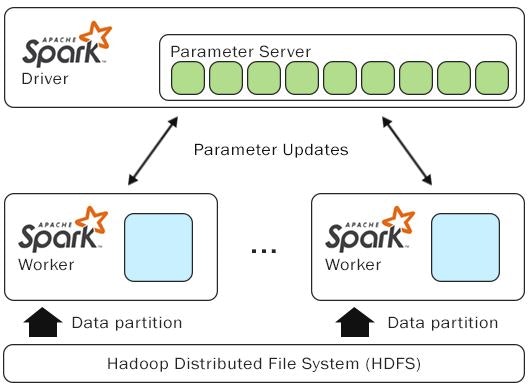
Dist-Keras Instrallation
Dist-KerasはGithubで公開されています。
https://github.com/cerndb/dist-keras
Dist-Kerasのインストール前にSparkとKerasのインストールが必要になります。
これらのインストール方法は以下になります。
https://spark.apache.org/docs/latest/index.html
https://keras.io/ja/
Dist-Kerasのインストール方法は以下のコマンドです。
## if you need git, run "yum -y install git" beforehand
git clone https://github.com/JoeriHermans/dist-keras
cd dist-keras
pip install -e .
私は仮想マシンのCentOS7.3とDockerコンテナ(CentOS7.3)で試しましたが、とくに引っかかることなくインストールできました。
あらためて、今回やること
さて、長くなりましたが、今回やることはDist-KerasをDockerコンテナで動かして、Kerasのモデル学習をコンテナ間で分散させることです。
あらためて、以下の構成をデプロイしていきます。
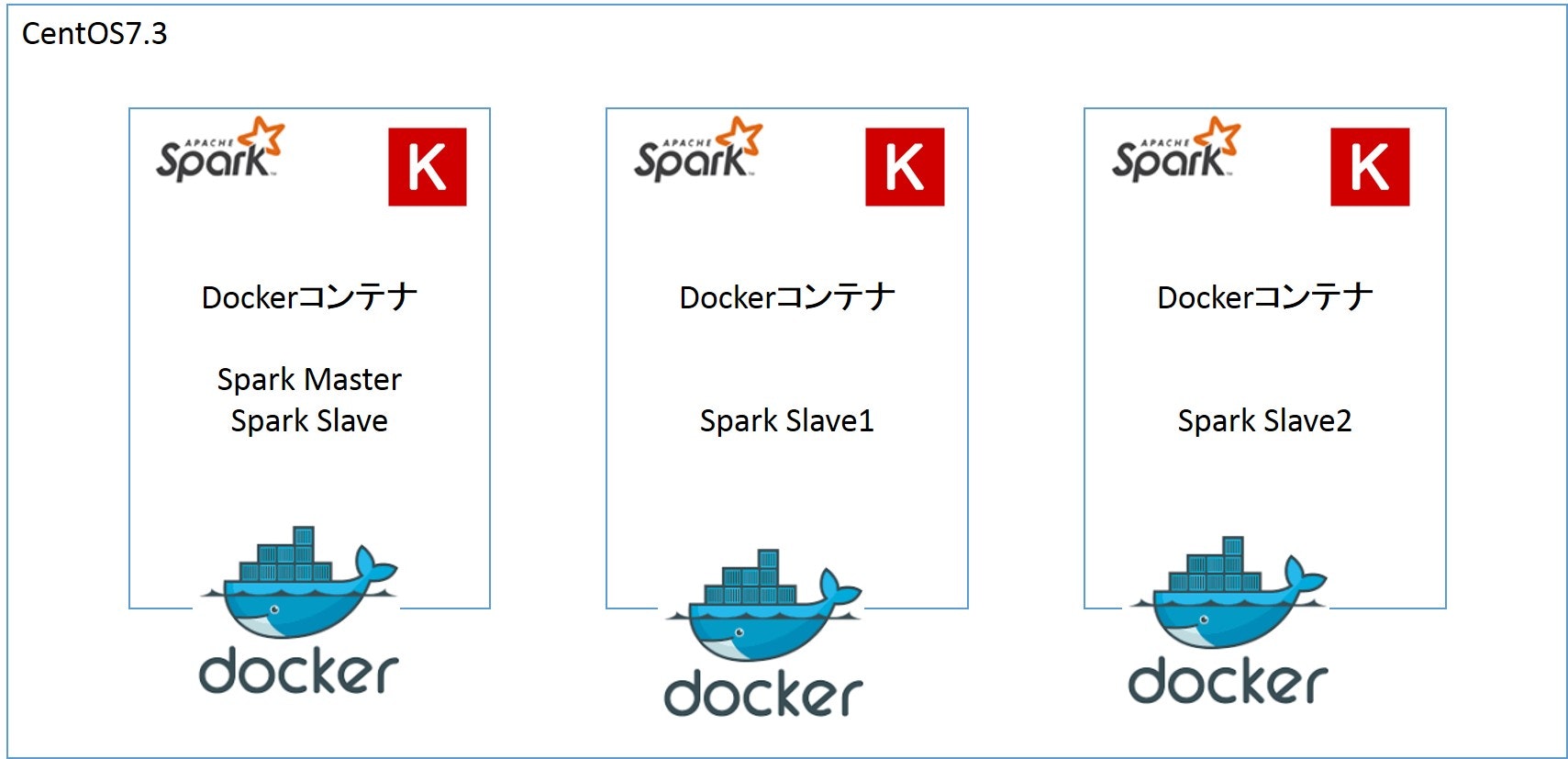
Dist-Keras on Docker
Dist-KerasはDockerfileもDockerイメージもないので、自作しました。
https://github.com/shibuiwilliam/distkeras-docker
git cloneするとDockerfileとspark_run.shがダウンロードされます。
git clone https://github.com/shibuiwilliam/distkeras-docker.git
distkeras-dockerディレクトリに移動してdocker buildします。
cd distkeras-docker
docker build -t distkeras .
時間がかかりますが、ゆっくり待ちましょう。
docker buildでやっていることは主に以下です。
- 必要なツールのインストール
- PythonやJupyter Notebookのインストール、構成
- Standalone Sparkのインストール、構成
- Dist kerasのインストール
- SparkMaster & Jupyter Notebook起動用スクリプトspark_master.sh、spark_slave.shを追加
ベースコンテナはCentOSです。
Sparkは2.1.0、Kerasは2.0.2で、いずれも最新版を利用しています。
docker buildが完了したら早速動かしてみましょう。
今回はスケールアウトさせるため、Dockerコンテナを3台起動させます。
# docker dist-keras for spark master and slave
docker run -it -p 18080:8080 -p 17077:7077 -p 18888:8888 -p 18081:8081 -p 14040:4040 -p 17001:7001 -p 17002:7002 \
-p 17003:7003 -p 17004:7004 -p 17005:7005 -p 17006:7006 --name spmaster -h spmaster distkeras /bin/bash
# docker dist-keras for spark slave1
docker run -it --link spmaster:master -p 28080:8080 -p 27077:7077 -p 28888:8888 -p 28081:8081 -p 24040:4040 -p 27001:7001 \
-p 27002:7002 -p 27003:7003 -p 27004:7004 -p 27005:7005 -p 27006:7006 --name spslave1 -h spslave1 distkeras /bin/bash
# docker dist-keras for spark slave2
docker run -it --link spmaster:master -p 38080:8080 -p 37077:7077 -p 38888:8888 -p 38081:8081 -p 34040:4040 -p 37001:7001 \
-p 37002:7002 -p 37003:7003 -p 37004:7004 -p 37005:7005 -p 37006:7006 --name spslave2 -h spslave2 distkeras /bin/bash
Spark マスター兼ワーカー(spmaster)とワーカー1(spslave1), ワーカー2(spslave2)という構成です。
spmasterでSparkマスター、ワーカーを動かし、spslave1, spslave2をワーカー(スレーブ)としてSparkクラスターに参加させます。
Sparkマスターとワーカーの起動スクリプトはそれぞれ /opt/spark_master.sh 、 /opt/spark_slave.sh として用意しています。
各コンテナの起動時に/opt/ディレクトリに移動するので、そこでコマンドを実行すればマスター、ワーカーを起動できます。
# Spark masterで実行
# マスターとワーカーが起動し、ワーカーがクラスターに参加
sh spark_master.sh
# Spark spslave1, 2で実行
# ワーカーが起動し、マスターのクラスターに参加
sh spark_slave.sh
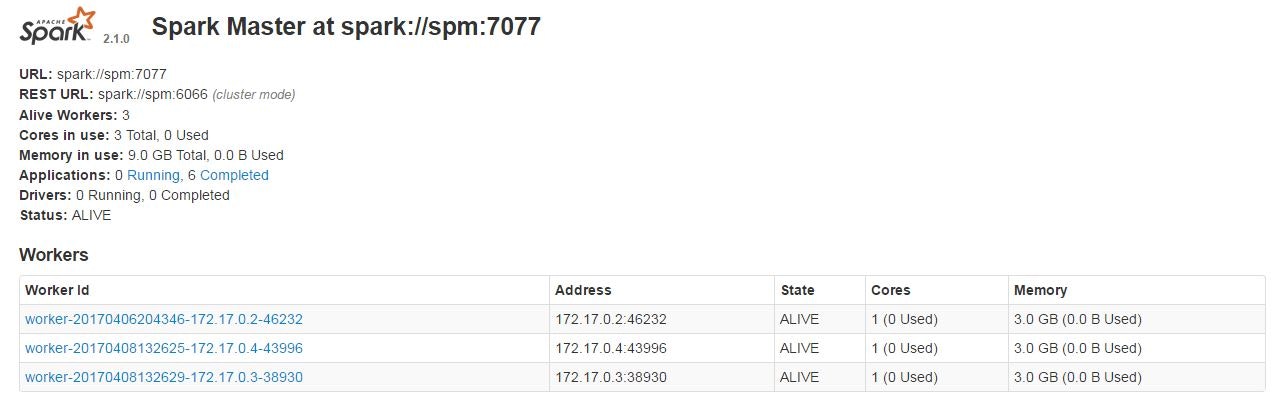
これでSparkクラスターにマスター1台、ワーカー3台が参加した状態になります。
Sparkマスターのコンソールで確認可能です。
http://<spark master>:18080
この辺はDocker composeとかSwarmとかで複数台を一度に起動させるようにしたいですが、これも後日の宿題です。
Keras on SparkでMNIST
Dist-KerasでMNISTをやってみます。
MNISTのサンプルコードはDist-Kerasで提供されています。
ディレクトリは /opt/dist-keras/examples で、そこに以下のサンプルデータとプログラムがあります。
[root@spm examples]# tree
.
|-- cifar-10-preprocessing.ipynb
|-- data
| |-- atlas_higgs.csv
| |-- mnist.csv
| |-- mnist.zip
| |-- mnist_test.csv
| `-- mnist_train.csv
|-- example_0_data_preprocessing.ipynb
|-- example_1_analysis.ipynb
|-- kafka_producer.py
|-- kafka_spark_high_throughput_ml_pipeline.ipynb
|-- mnist.ipynb
|-- mnist.py
|-- mnist_analysis.ipynb
|-- mnist_preprocessing.ipynb
|-- spark-warehouse
`-- workflow.ipynb
今回はmnist.pyを実行しますが、環境にあわせて一部コードの変更が必要です。
元ファイルをコピーしてバックアップし、以下の変更を当てます。
cp mnist.py mnist.py.bk
変更箇所1 SparkSessionのインポート
以下を冒頭に追加します。
from pyspark.sql import SparkSession
変更箇所2 パラメータの設定
Sparkのパラメータを今回の環境向けに変更します。
変更の意図は以下です。
- Spark2を使うこと
- ローカル環境を使うこと
- ローカル環境でマスターurlを定義
- ワーカー数を1から3に変更
# Modify these variables according to your needs.
application_name = "Distributed Keras MNIST"
using_spark_2 = True # False→True
local = True # False→True
path_train = "data/mnist_train.csv"
path_test = "data/mnist_test.csv"
if local:
# Tell master to use local resources.
# master = "local[*]" comment out
master = "spark://spm:7077" # add
num_processes = 1
num_executors = 3 # 1→3
else:
# Tell master to use YARN.
master = "yarn-client"
num_executors = 20
num_processes = 1
変更箇所3 ワーカーのメモリ
ワーカーのメモリを4Gから2Gにします。
これは単純に自分の環境に合わせただけなので、必須の変更ではありません。
conf = SparkConf()
conf.set("spark.app.name", application_name)
conf.set("spark.master", master)
conf.set("spark.executor.cores", `num_processes`)
conf.set("spark.executor.instances", `num_executors`)
conf.set("spark.executor.memory", "2g") # 4G→2G
conf.set("spark.locality.wait", "0")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
これで準備完了です。MNISTを動かしてみましょう。
python mnist.py
実行状況はSparkマスターのコンソールで確認可能です。
http://<spark master>:18080
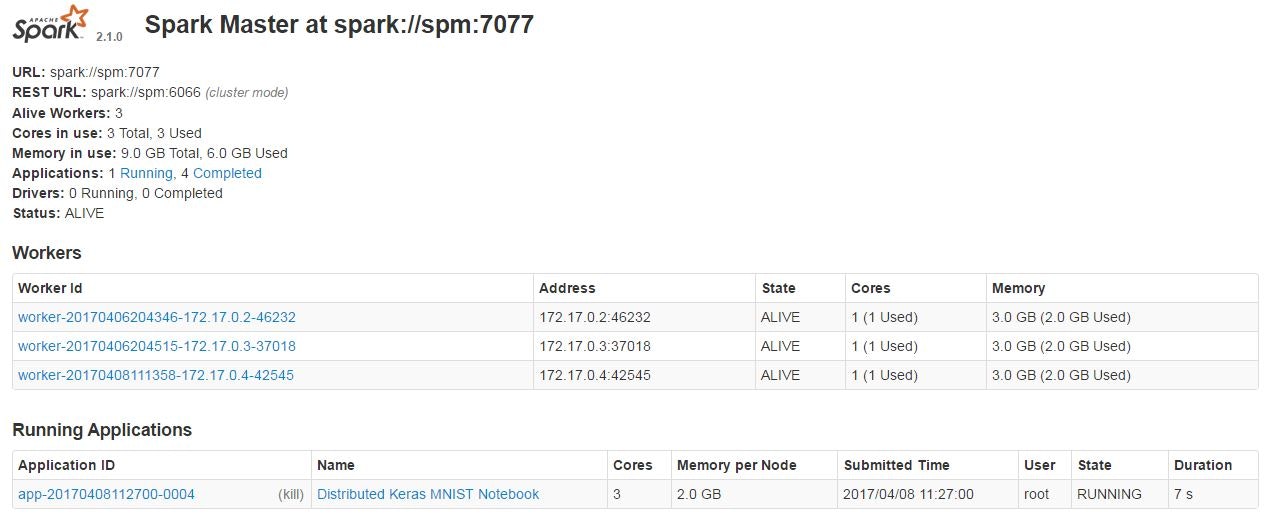
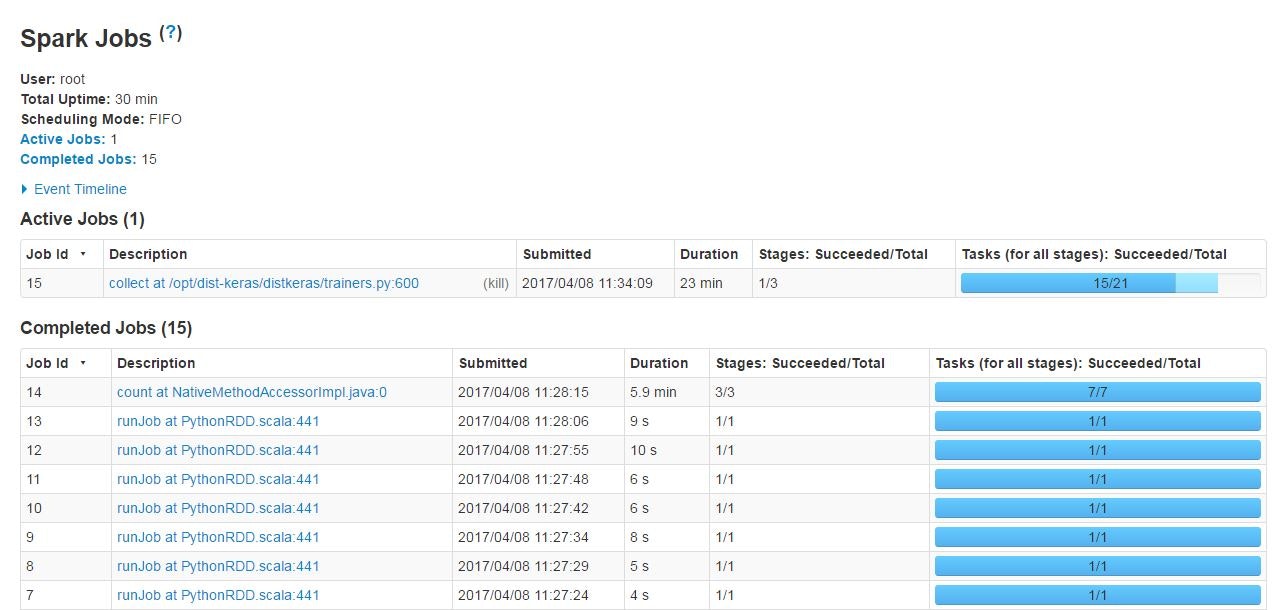
もちろんJobsやExecuter等、詳細を開くこともできます。
Jobs画面
Executer画面
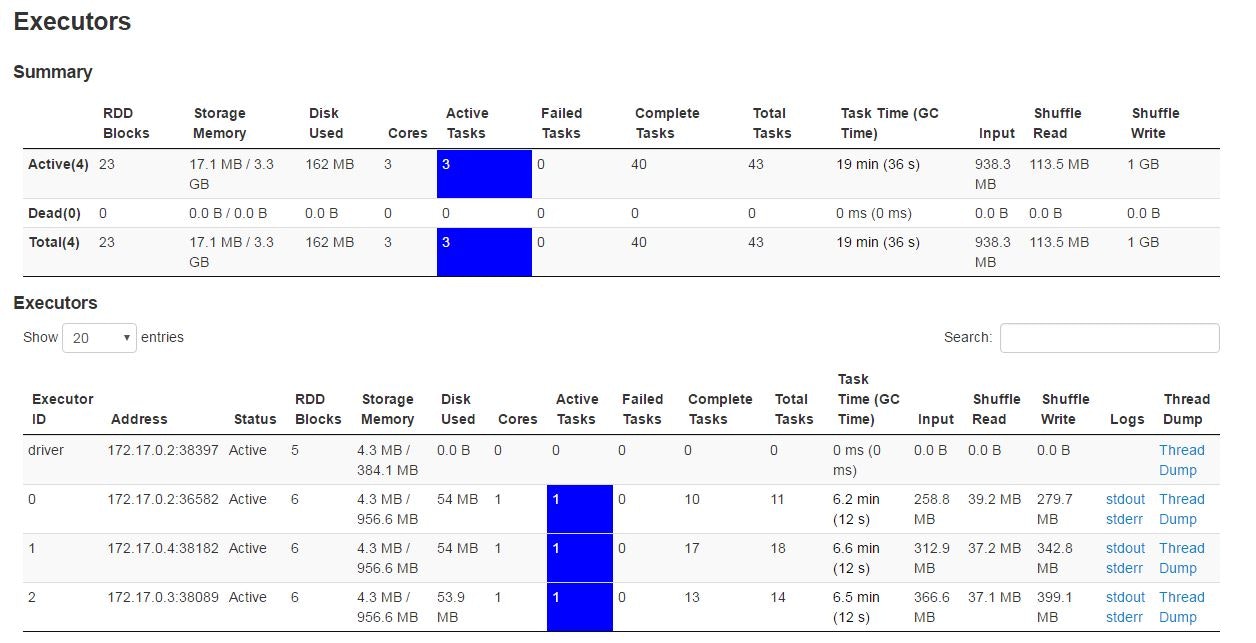
ワーカー3台にデータがロードされ、MNISTの学習を行っています。
ちなみにMNISTのモデルは以下のようになっています。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
activation_1 (Activation) (None, 26, 26, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 24, 24, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 24, 24, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_1 (Dense) (None, 225) 1037025
_________________________________________________________________
activation_3 (Activation) (None, 225) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 2260
_________________________________________________________________
activation_4 (Activation) (None, 10) 0
=================================================================
Total params: 1,048,853.0
Trainable params: 1,048,853.0
Non-trainable params: 0.0
_________________________________________________________________
プログラムは大体30分くらいで完了します。
MNISTの結果
ワーカー3台でやってみた結果は以下になります。
Training time: 1497.86584091
Accuracy: 0.9897
Number of parameter server updates: 3751
25分弱の学習時間で正答率0.9897の精度になりました。
まあまあです。
ついでですが、試しにワーカーを1台にしてやってみた結果は以下です。
Training time: 1572.04011703
Accuracy: 0.9878
Number of parameter server updates: 3751
・・・3ワーカーでも1ワーカーでも1分程度の差しかでてませんね(-_-;)
これが・・・シュタインズゲートの選択か・・・

今後の展望
今回は同一サーバでDockerコンテナを起動しましたが、本来の負荷分散はサーバをまたいで実現するものだと思います。
今後は複数サーバやECSでDist-Kerasコンテナを起動し、Sparkクラスターを構成して負荷分散してみたいです。
【2017/04/16 追記】
パフォーマンス改善方法を検証しました。
http://qiita.com/cvusk/items/f54ce15f8c76a396aeb1
【2017/05/26 追記】
Kubernetesでクラスターにしました。
http://qiita.com/cvusk/items/42a5ffd4e3228963234d