Spark × Keras × Dockerでディープラーニングをスケーラブルにしてみた3 Kubernetes編
これまでのあらすじ
KerasをSpark上で稼働させるdist-kerasをDockerから起動させることで、ディープラーニングをスケーラブルにしようとしてきました。
Spark × Keras × Dockerでディープラーニングをスケーラブルにしてみた
Spark × Keras × Dockerでディープラーニングをスケーラブルにしてみた2 マルチホスト編
前回まででマルチホストでの分散処理に成功しました。
しかしマルチホストでDockerを起動する難点は、それぞれのホストで一々起動コマンドを実行し管理しなければならない点です。
そこで、DockerのオーケストレーションツールKubernetesを用いて、Docker管理を容易にスケーラブルにしてみました。
今回やること
これまで作ってきたDistKeras on DockerをKubernetesで動かします。
Kubernetesで複数のホストを管理し、Dockerコンテナの起動、コマンド実行、停止を可能にします。
また、replication controllerを使ってSpark workerをスケールアウトします。
Kubernetesとは
Dockerコンテナをオーケストレーションするツールです。
要は複数のDockerコンテナをマルチホストで実行したり管理したりするためのツールで、Googleが開発、OSS化したものです。
https://kubernetes.io/
Dockerコンテナのオーケストレーションツールは、他にもDocker SwarmやMesosがあります。
今回Kubernetesを選んだ特別な理由はありません。
Dockerのオーケストレーションツールを一つくらい触ってみたくなって、たまたま最近Kubernetesのユーザ会に参加したことがきっかけです。
Kubernetesはホスト上にインストールして使用します。
今回はCentOS 7.3にKubernetesをインストールします。
インストール方法はこちらをご参照ください。
https://kubernetes.io/docs/getting-started-guides/kubeadm/
https://kubernetes.io/docs/getting-started-guides/centos/centos_manual_config/
Kubernetesの使い方や概念、構築方法はこの記事では書きません。
その辺に興味ある方は、以下あたりが参考になると思います。
https://kubernetes.io/docs/tutorials/
https://kubernetes.io/docs/concepts/
https://access.redhat.com/ja/node/1273583
http://qiita.com/Arturias/items/8f16194f164aeacbe67d
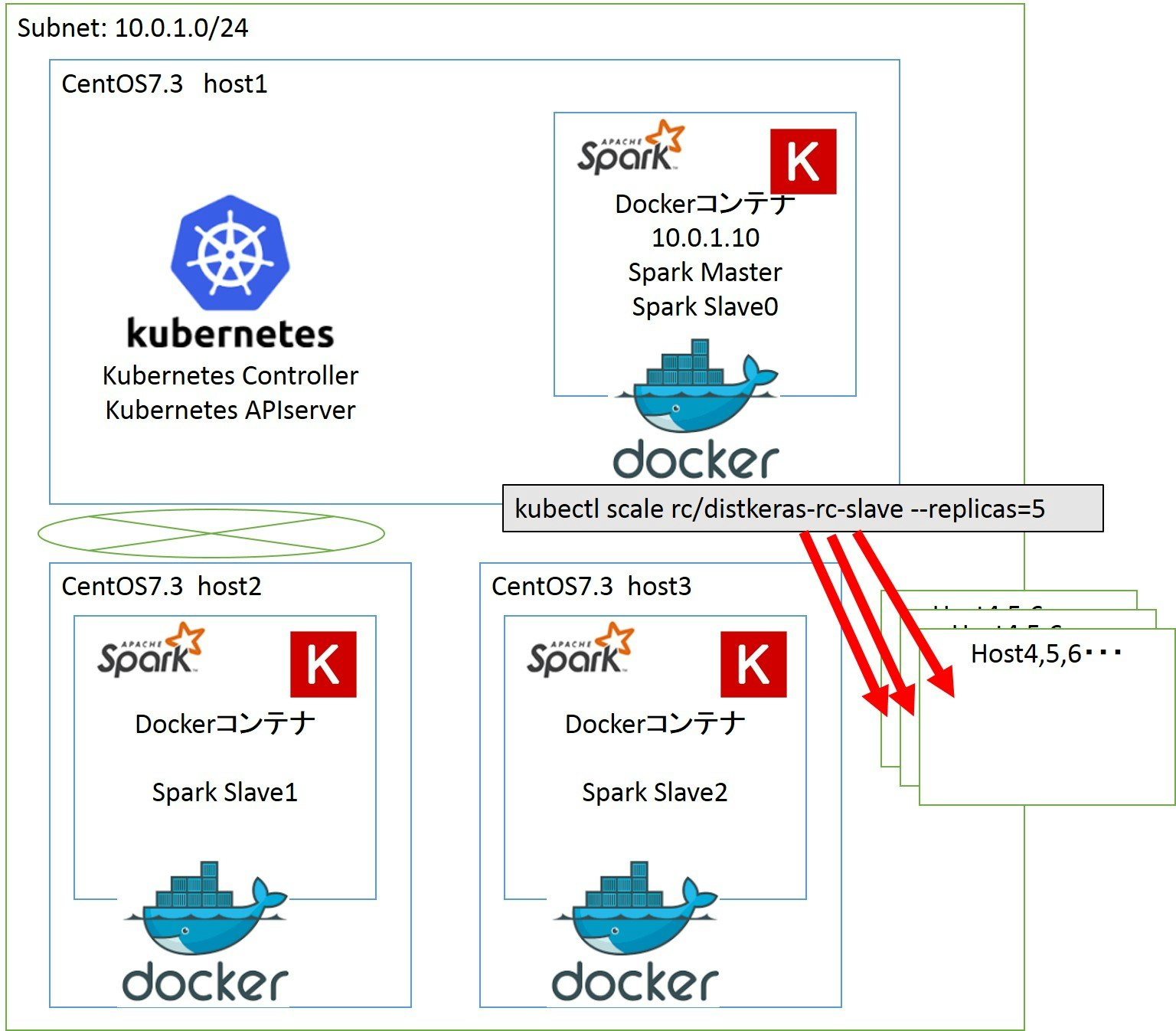
構成
今回の構成です。
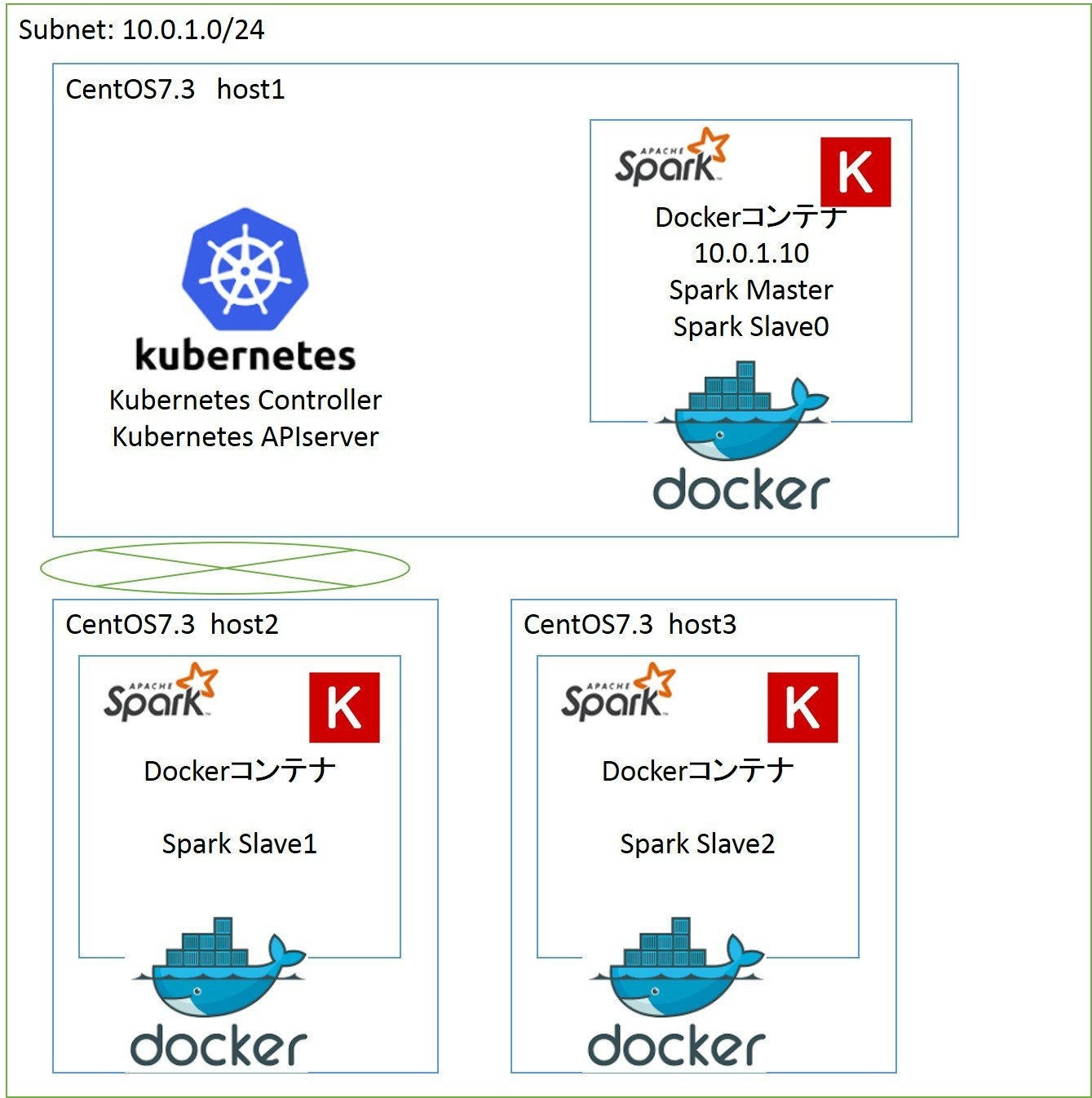
ネットワークはetcdとflannelを使ってoverlay networkを構成しています。
ホスト1にKubernetes ControllerとAPIサーバを搭載し、kubectlもホスト1から実行します。
Dockerイメージは以下にdockerfileからbuildします。
https://github.com/shibuiwilliam/distkeras-docker/tree/master/dist-keras-docker/kube_distkeras
kubectl get nodesの結果は以下になります。

Spark MasterとSpark workerでservice, replication controller定義ファイルymlを分けています。
serviceがKubernetesのpodsのネットワークを定義し、replication controllerがコンテナ数を定義します。
Spark Master用serviceはtype=LoadBalancerとして、公開するポート、クラスターIPアドレスを定義します。
Spark Master用replication controllerはレプリカ数1でSpark Master用のDockerコンテナを実行します。
Spark worker用serviceはtype=LoadBalancerとして、公開するポートを定義します。
Spark worker用replication controllerはレプリカ数2でSpark worker用のDockerコンテナを実行します。
| Spark | service | repl ctr, replica | ホスト label | docker image | Host |
|--------|--------|--------|--------|--------|
| Master | sv_master.yml | rc_master.yml, 1replica | distkeras-master | distkeras_master_kube:1.4 | Host1 |
| Slave | sv_slave.yml | rc_slave.yml, 2replicas | distkeras-slave | distkeras_slave_kube:1.4 | Host2, 3|
Dockerイメージの用意
Spark Master、Spark workerのDockerfileをそれぞれ用意しました。
Gitをクローンして、dockerイメージをbuildしてください。
git clone https://github.com/shibuiwilliam/distkeras-docker.git
cd ~/distkeras-docker/dist-keras-docker/kube_distkeras/master_docker
docker build -t distkeras_master_kube:1.4 .
cd ~/distkeras-docker/dist-keras-docker/kube_distkeras/slave_docker
docker build -t distkeras_slave_kube:1.4 .
distkeras_master_kube:1.4, distkeras_slave_kube:1.4というDockerイメージができます。
distkeras_master_kube:1.4はホスト1、distkeras_slave_kube:1.4はホスト2、3で起動します。
それぞれのホストでdocker imageをビルドします。
Kubernetesの設定ファイル
再掲になりますが、以下の構成でKubernetesクラスターをホスト1からコントロール(kubectlで操作)できるとします。
Kubernetesでクラスターをコンテナを起動するには、serviceやreplication controllerの構成を定義したymlファイルを作る必要があります。
今回はDistkeras_master(=spark master + slave)用のserviceとreplication controller、Distkeras_slave(=Spark worker)用のserviceとreplication controllerのファイルをそれぞれ作ります。
| Spark | service | repl ctr |
|--------|--------|--------|--------|--------|
| Master | sv_master.yml | rc_master.yml |
| Slave | sv_slave.yml | rc_slave.yml |
ファイルは以下にあります。
https://github.com/shibuiwilliam/distkeras-docker/tree/master/dist-keras-docker/kube_distkeras
DistKeras on Kubernetesを起動
上記の設定ファイルymlをkubectlからcreateすることで、Kubernetesクラスターを実行することができます。
作られたserviceとreplication controller、podsはkubectl getで情報を表示することができます。
まずはmasterを1レプリカ、slaveを1レプリカで起動します。
(rc_master.yml、rc_slave.ymlともにreplicas: 1とします)
kubectl create -f sv_master.yml
kubectl create -f rc_master.yml
kubectl create -f sv_slave.yml
kubectl create -f rc_slave.yml
アウトプットはこのようになります。
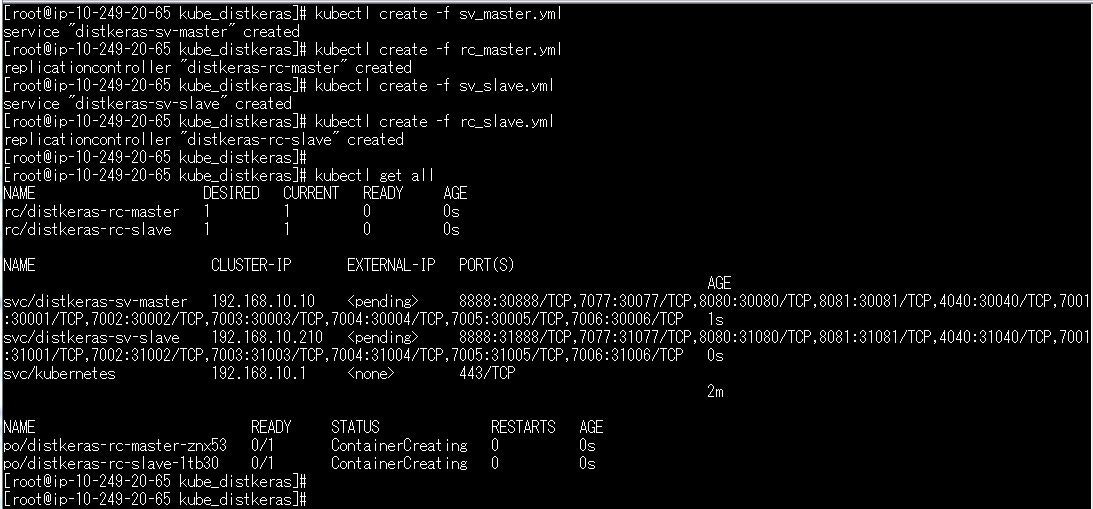
下の2行がpods情報で、masterのpodが1台、slaveのpodが1台で起動していることがわかると思います。
Master podではSpark masterとSpark workerが起動します。
Slave podではSpark workerのみが起動します。
SparkコンソールでもSpark workerが2台起動していることがわかります。
このような構成になっています。
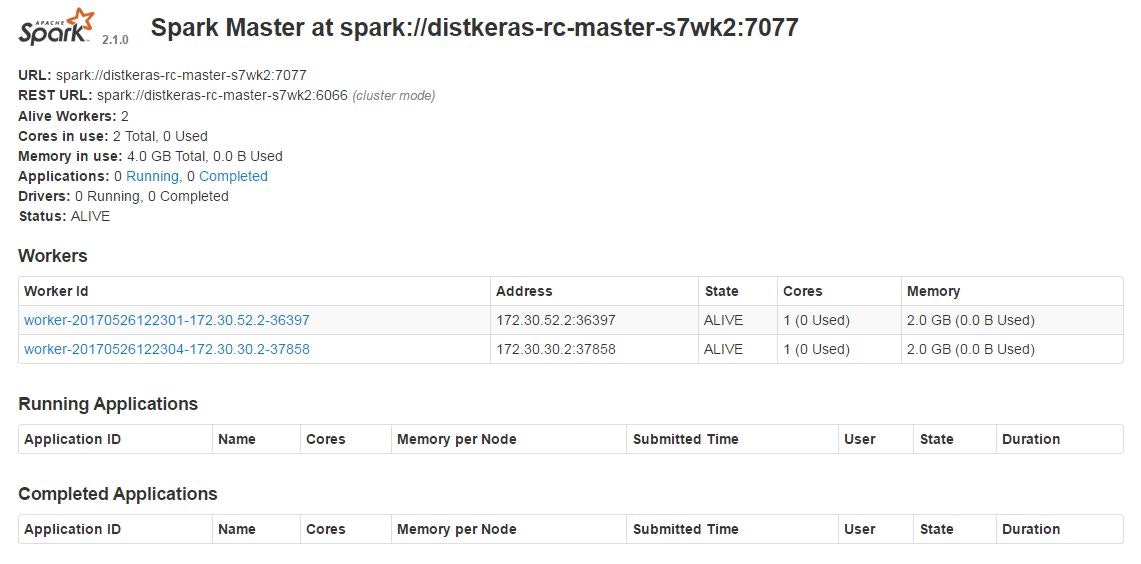
この状態でもSpark上でKerasを動かすことは可能です。
スケールアウト
プログラムを動かす前に、先にDistkeras slaveをスケールアウトしてみたいと思います。
スケールアウトにはDistkeras slaveのreplication controllerで、レプリカ数を1から2に変更します。
コマンドは以下です。
kubectl scale rc/distkeras-rc-slave --replicas=2
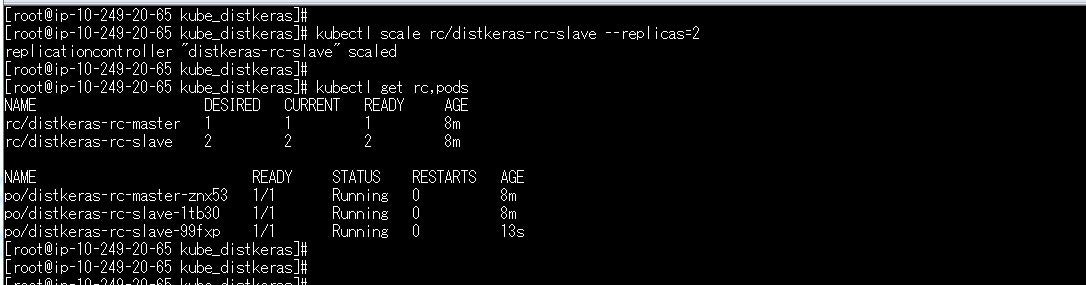
これでDistkeras slaveが2podsになりました。
Spark workerも増えていることを確認できます。
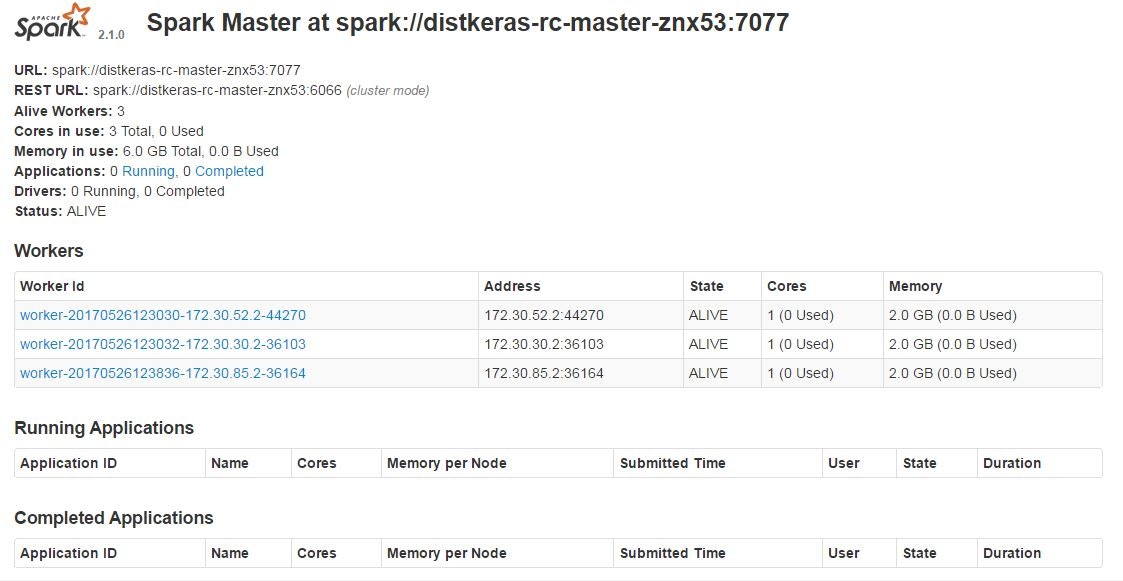
Distkeras_slaveのpod数を増やすことでSpark worker数が追加され、負荷分散することが可能になります。
耐障害性
スケーラブルにするメリットには、スケールアウトと耐障害性があります。
特にクラウド・コンテナ時代の耐障害性は、障害発生時には自動復旧することが求められます。
Kubernetesのreplication controllerが耐障害性を備えているか、試してみます。
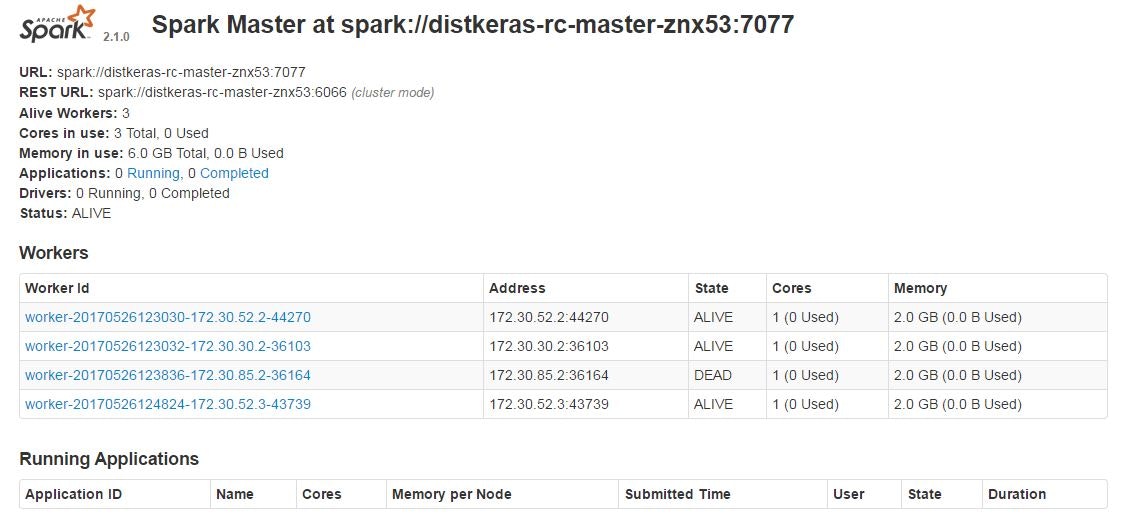
現在、Distkeras_slaveは2台のホストで1podずつ起動しています。
そのうち1台(ホスト3)を停止します。
この状態で数分ほど待つと、残っているホスト2でpodが2台起動します。
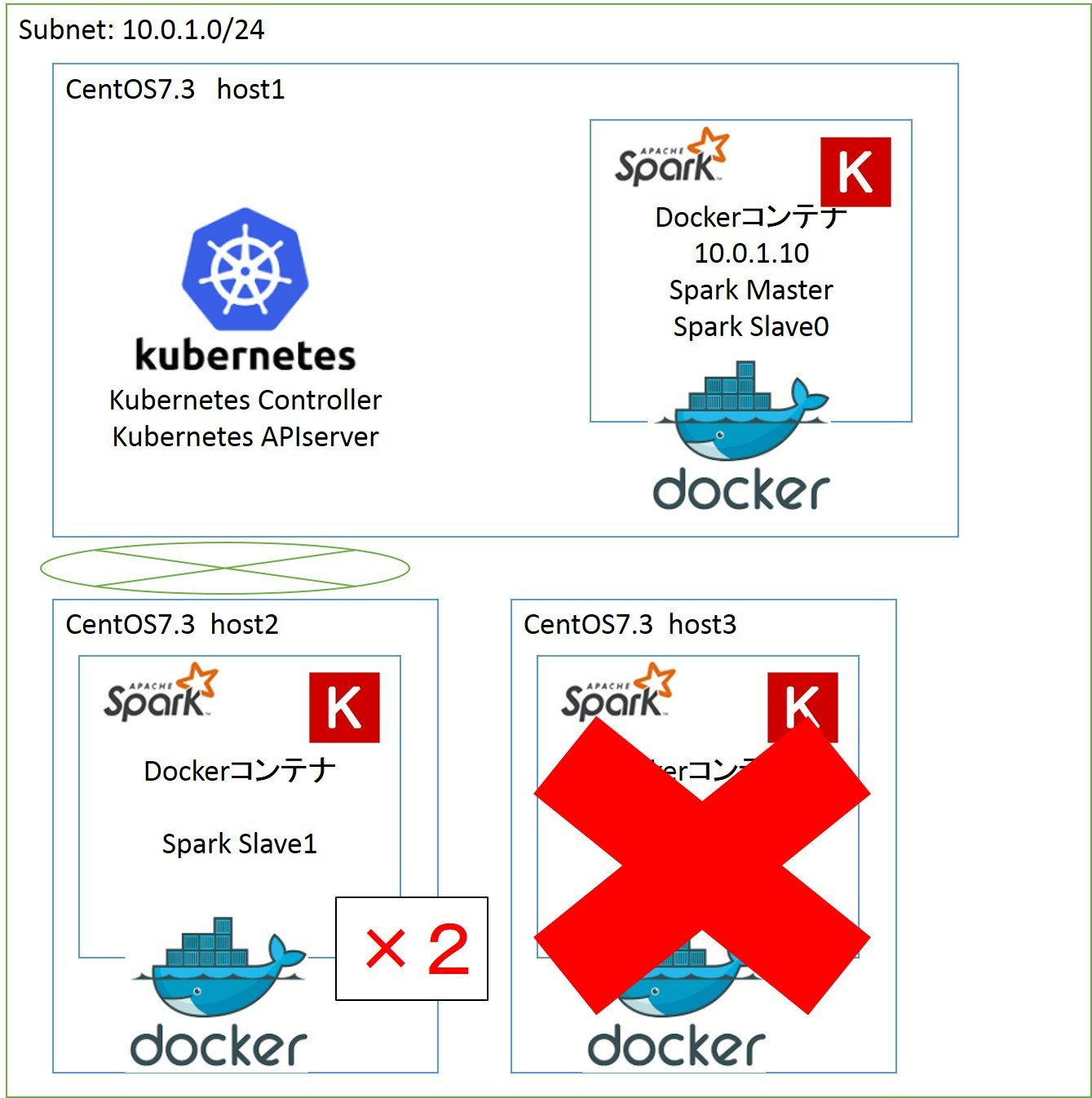
SparkでもWorkerが1台Deadになり、1台新規に追加されていることがわかります。
Distkerasを実行
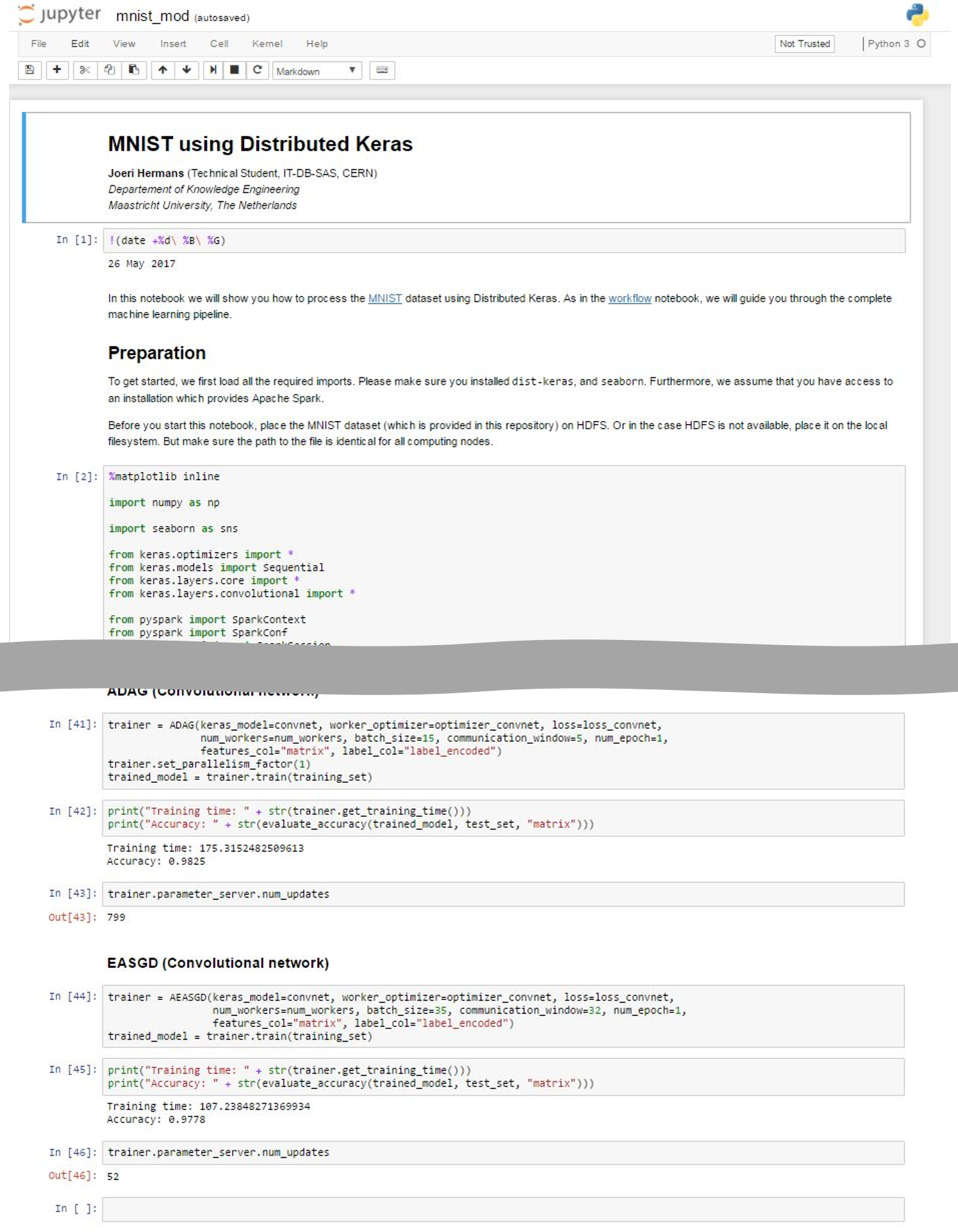
これでDistKerasをスケーラブルにできたので、次はKeras on Sparkのプログラムを実行してみたいと思います。
プログラムはこのMNIST Jupyter Notebookです。
おなじみのMNISTでして、これを今回のDistKeras on Docker on Kubernetesで実行します。
長いプログラムなので中間は省略していますが、全工程を無事実行することができます。
全工程はJupyter Notebookでご覧ください。
おわりに
「Spark × Keras × Dockerでディープラーニングをスケーラブル」でやりたかったことの一つが、ようやく完成しました。
本当はいろいろと直したいところはありますが、ひとまずKubernetes上でDistkeras on Dockerが動いたので、嬉しい限りです。
ディープラーニングの難点はモデル学習に時間がかかることで、その解決策のひとつとして、スケールアウトによるリソース増強を検証しました。
この後の目標として
- モデル学習中にスケールアウト
- モデル学習中にホストが停止しても動き続けること(耐障害性)
- GPUを使っても動かせること
を目指そうと思います。
ひとまず金銭的な理由により、1.、2.をやっていこうと思いますが、本当にやりたいのは3.です。