Spark × Keras × Dockerでディープラーニングをスケーラブルにしてみた2
以前、Dist-kerasをDockerに載せてスケーラブルなディープラーニングを作ってみました。
http://qiita.com/cvusk/items/3e6c3bade8c0e1c0d9bf
当時の反省点はパフォーマンスが出なかったことですが、よく見直したらパラメータの設定が間違っていたようです。
そこで反省がてら、いろいろ試してみました。
前回までのあらすじ
Dist-Keras自体の説明は以前の投稿をご参照いただきたいのですが、要はSparkクラスター上で動作するKerasです。
私はこれをDockerイメージにして、スケールアウトを簡単にできるようにしてみました。
なお、DockerfileはGitHubで公開しています。
https://github.com/shibuiwilliam/distkeras-docker
今回やること
今回はDist-Keras on Dockerをシングルホスト、マルチホストで検証してパフォーマンスを改善してみたいと思います。
前回はシングルホストで複数コンテナを起ち上げて、Sparkクラスターを作っていました。
今回はパターンを増やしてみます。
実行するのはMNISTです。
MNISTの学習プログラムはdist-kerasで提供されているものをカスタマイズして使います。
検証した構成
シングルホストとマルチホストで検証します。
いずれもSparkマスター+ワーカーという構成で、ワーカー数やワーカーのスペックを調整します。
マルチホストの場合はサーバ2台です。
なお、ホストはAWS EC2 CentOS7.3のm4.xlargeを使っています。
| no | hosts | workers | resources |
|---|---|---|---|
| 1 | single | 1 | 1 processor, 2GB RAM |
| 2 | single | 2 | 2 processors, 5GB RAM |
| 3 | single | 3 | 1 processor, 3GB RAM |
| 4 | multihost | 2 | 2 processors, 5GB RAM |
| 5 | multihost | 2 | 3 processors, 8GB RAM |
| 6 | multihost | 4 | 2 processors, 5GB RAM |
シングルホストの設定方法
シングルホストの場合のイメージはこんな感じです。
Dockerコンテナの台数は検証条件で上下します。
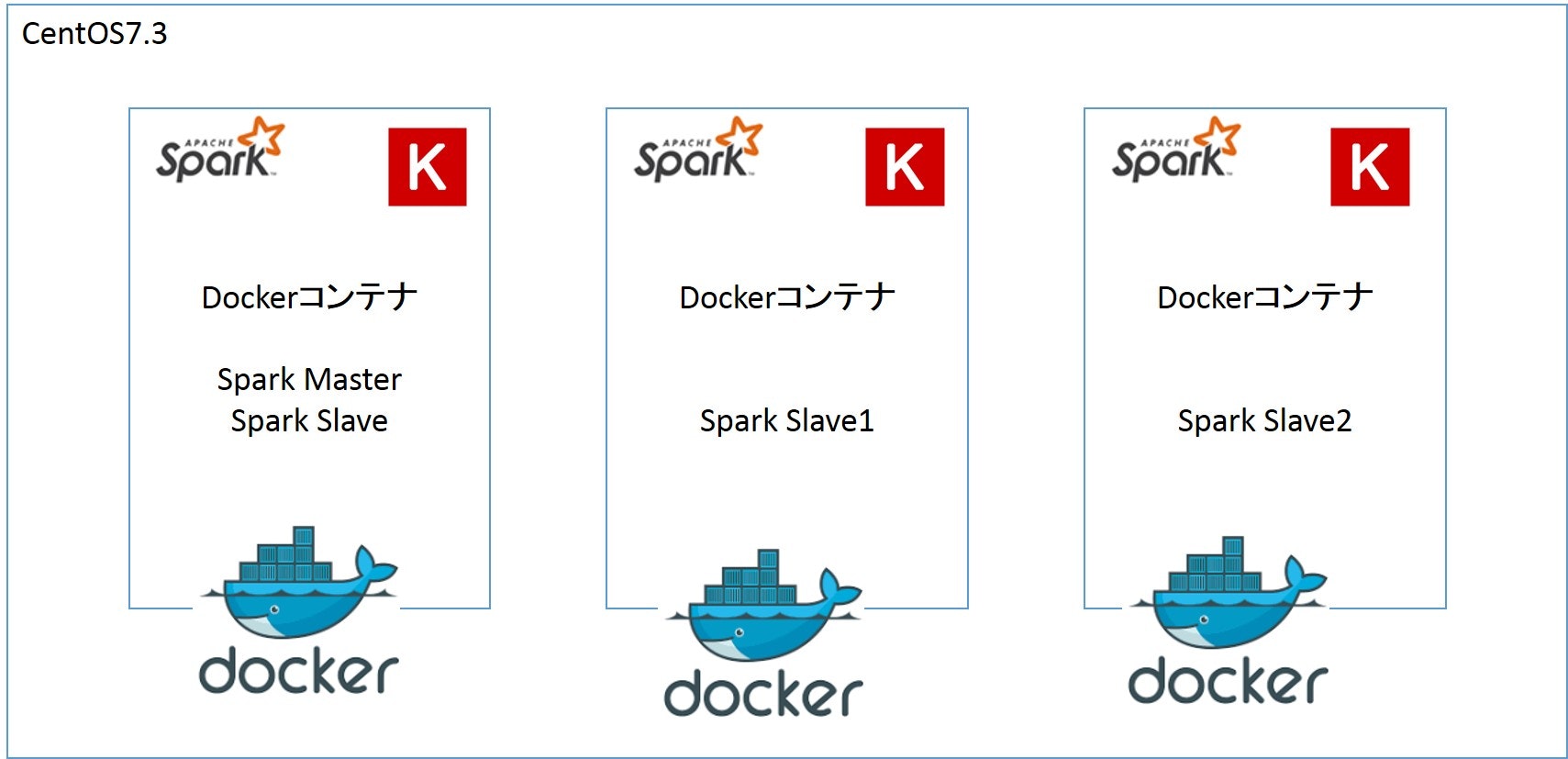
シングルホストの場合は同一ホスト上で複数のDockerコンテナを起動します。
# docker dist-keras for spark master and slave
docker run -it -p 18080:8080 -p 17077:7077 -p 18888:8888 -p 18081:8081 -p 14040:4040 -p 17001:7001 -p 17002:7002 \
-p 17003:7003 -p 17004:7004 -p 17005:7005 -p 17006:7006 --name spmaster -h spmaster distkeras /bin/bash
# docker dist-keras for spark slave1
docker run -it --link spmaster:master -p 28080:8080 -p 27077:7077 -p 28888:8888 -p 28081:8081 -p 24040:4040 -p 27001:7001 \
-p 27002:7002 -p 27003:7003 -p 27004:7004 -p 27005:7005 -p 27006:7006 --name spslave1 -h spslave1 distkeras /bin/bash
# docker dist-keras for spark slave2
docker run -it --link spmaster:master -p 38080:8080 -p 37077:7077 -p 38888:8888 -p 38081:8081 -p 34040:4040 -p 37001:7001 \
-p 37002:7002 -p 37003:7003 -p 37004:7004 -p 37005:7005 -p 37006:7006 --name spslave2 -h spslave2 distkeras /bin/bash
Spark masterでSparkマスターとワーカーを起動し、Spark slaveはワーカーのみを起動します。
# for spark master
${SPARK_HOME}/sbin/start-master.sh
# for spark worker
${SPARK_HOME}/sbin/start-slave.sh -c 1 -m 3G spark://spmaster:${SPARK_MASTER_PORT}
次にSparkマスターでMNISTのプログラムをカスタマイズします。
MNISTのサンプルコードはDist-Kerasで提供されています。
ディレクトリは /opt/dist-keras/examples で、そこに以下のサンプルデータとプログラムがあります。
[root@spm examples]# tree
.
|-- cifar-10-preprocessing.ipynb
|-- data
| |-- atlas_higgs.csv
| |-- mnist.csv
| |-- mnist.zip
| |-- mnist_test.csv
| `-- mnist_train.csv
|-- example_0_data_preprocessing.ipynb
|-- example_1_analysis.ipynb
|-- kafka_producer.py
|-- kafka_spark_high_throughput_ml_pipeline.ipynb
|-- mnist.ipynb
|-- mnist.py
|-- mnist_analysis.ipynb
|-- mnist_preprocessing.ipynb
|-- spark-warehouse
`-- workflow.ipynb
元ファイルをコピーしてバックアップし、以下の変更を当てます。
cp mnist.py mnist.py.bk
変更箇所1 SparkSessionのインポート
以下を冒頭に追加します。
from pyspark.sql import SparkSession
変更箇所2 パラメータの設定
Sparkのパラメータを今回の環境向けに変更します。
変更の意図は以下です。
- Spark2を使うこと
- ローカル環境を使うこと
- ローカル環境でマスターurlを定義
- プロセッサ数を検証条件に合わせて変更
- ワーカー数を検証条件い合わせて変更
# Modify these variables according to your needs.
application_name = "Distributed Keras MNIST"
using_spark_2 = True # False to True
local = True # False to True
path_train = "data/mnist_train.csv"
path_test = "data/mnist_test.csv"
if local:
# Tell master to use local resources.
# master = "local[*]" comment out
master = "spark://spm:7077" # add
num_processes = 1 # change to number of processors per worker
num_executors = 3 # change to number of workers
else:
# Tell master to use YARN.
master = "yarn-client"
num_executors = 20
num_processes = 1
変更箇所3 ワーカーのメモリ
ワーカーのメモリを検証条件に合わせて変更します。
conf = SparkConf()
conf.set("spark.app.name", application_name)
conf.set("spark.master", master)
conf.set("spark.executor.cores", `num_processes`)
conf.set("spark.executor.instances", `num_executors`)
conf.set("spark.executor.memory", "4g") # change RAM size
conf.set("spark.locality.wait", "0")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
あとはSparkマスターでpython mnist.pyで実行できます。
マルチホストの設定方法
マルチホストの構成はこんな感じにします。
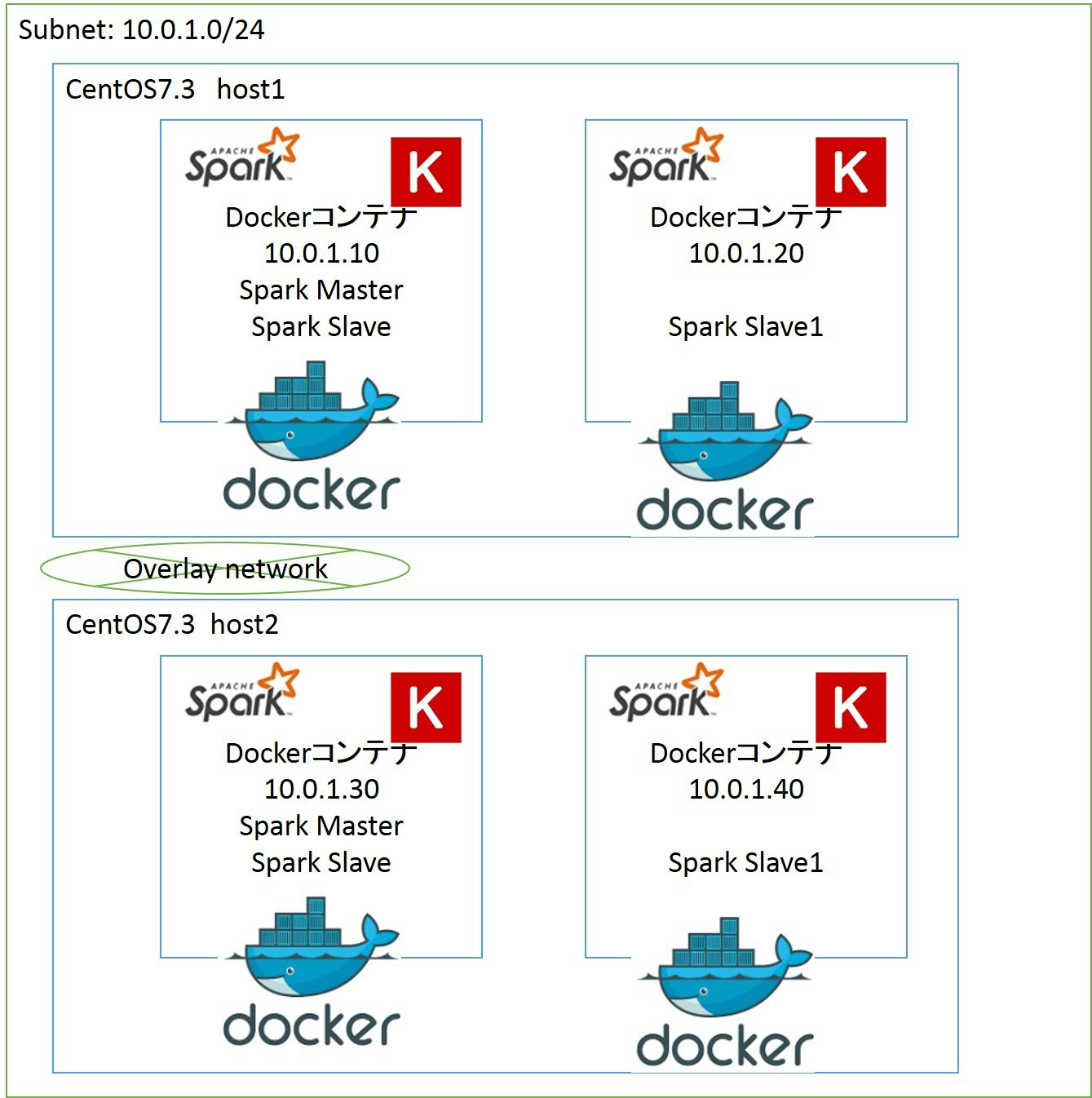
マルチホストではDockerコンテナをoverlayネットワークで接続する必要があります。
マルチホストでのDockerネットワーク構築方法の詳細は以下をご参照ください。
http://knowledge.sakura.ad.jp/knowledge/4786/
http://christina04.hatenablog.com/entry/2016/05/16/065853
ここでは私の手順のみを書きます。
EC2でhost1とhost2を用意して、host1にetcdをインストールし、起動します。
yum -y install etcd
vi /etc/etcd/etcd.conf
systemctl enable etcd
systemctl start etcd
次にhost1, host2両方にdocker-networkの設定を加えます。
# edit docker-network file
vi /etc/sysconfig/docker-network
# for host1
DOCKER_NETWORK_OPTIONS='--cluster-store=etcd://<host1>:2379 --cluster-advertise=<host1>:2376'
# for host2
DOCKER_NETWORK_OPTIONS='--cluster-store=etcd://<host1>:2379 --cluster-advertise=<host2>:2376'
# from host2 to ensure network connection to host1 etcd is available
curl -L http://<host1>:2379/version
{"etcdserver":"3.1.3","etcdcluster":"3.1.0"}
これでdocker間のネットワーク接続が可能になるので、あとはhost1でdocker networkを作成します。
ここではサブネット10.0.1.0/24でtest1というdocker networkを作ります。
# for host1
docker network create --subnet=10.0.1.0/24 -d overlay test1
最後にdocker network lsを実行し、test1ネットワークが追加されていればOKです。
NETWORK ID NAME DRIVER SCOPE
feb90a5a5901 bridge bridge local
de3c98c59ba6 docker_gwbridge bridge local
d7bd500d1822 host host local
d09ac0b6fed4 none null local
9d4c66170ea0 test1 overlay global
あとはtest1ネットワークにDockerコンテナを追加します。
host1, host2それぞれにDockerコンテナを配備してみます。
# for host1 as spark master
docker run -it --net=test1 --ip=10.0.1.10 -p 18080:8080 -p 17077:7077 -p 18888:8888 -p 18081:8081 -p 14040:4040 -p 17001:7001 -p 17002:7002 \
-p 17003:7003 -p 17004:7004 -p 17005:7005 -p 17006:7006 --name spm -h spm distkeras /bin/bash
# for host2 as spark slave
docker run -it --net=test1 --ip=10.0.1.20 --link=spm:master -p 28080:8080 -p 27077:7077 -p 28888:8888 -p 28081:8081 -p 24040:4040 -p 27001:7001 \
-p 27002:7002 -p 27003:7003 -p 27004:7004 -p 27005:7005 -p 27006:7006 --name sps1 -h sps1 distkeras /bin/bash
これでtest1ネットワークにマルチホストでDockerコンテナが2台配備されました。
あとはシングルホスト同様の手順でSparkマスターとSparkワーカーを起動し、MNIST.pyを編集してpython mnist.pyを実行します。
パフォーマンス検証結果
それぞれの構成でパフォーマンスを検証してみた結果です。
今回は完了までの所要時間(秒)を測っています。
| no. | hosts | workers | resources | time in second |
|---|---|---|---|---|
| 1 | single | 1 | 1 processor, 2GB RAM | 1615.63757 |
| 2 | single | 2 | 2 processors, 5GB RAM | 1418.56935 |
| 3 | single | 3 | 1 processor, 3GB RAM | 1475.84212 |
| 4 | multihost | 2 | 2 processors, 5GB RAM | 805.382518 |
| 5 | multihost | 2 | 3 processors, 8GB RAM | 734.290324 |
| 6 | multihost | 4 | 2 processors, 5GB RAM | 723.878466 |
マルチホストにしたほうがパフォーマンスが出ていますね。
単純に空いているリソース量がパフォーマンス差を生み出していると思います。
検証2と検証4はDockerコンテナの構成やワーカーの使うリソースは同じ設定なのですが、それでも600秒の差が出ています。
検証1と検証2、または検証4と検証5、検証6を比較しても、Sparkワーカー数、リソース量自体が大きなパフォーマンス差を生むものではないようです。
大きくパフォーマンス改善したいのであれば、素直にマルチホストにするのが良いのでしょう。
【2017/05/26 追記】
Kubernetesでクラスターにしました。
http://qiita.com/cvusk/items/42a5ffd4e3228963234d