TensorFlowOnSparkをDocker runしてみた
TensorFlowOnSparkのスタンドアローン版をDockerイメージにしてみました。
TensorFlowOnSparkはTensorFlowをSpark上で稼働させられるようにしたもので、Yahooが先週くらいに発表していました(2017/02/13)。
https://github.com/yahoo/TensorFlowOnSpark/wiki
出た当日にスタンドアローン版の構築を試してみました。
http://qiita.com/cvusk/items/39a1861715e21b1dc191
ついでにDockerfileにしましたのが今回です。
練習がてら。
TensorFlowOnSpark on Docker
ホストOSにはCentOS7.3を使っています。
Dockerのインストール、起動以外は以下のとおりです。
sudo yum -y install docker
sudo systemctl start docker
sudo systemctl enable docker
Dockerfileを作るディレクトリを用意します。
sudo su -
mkdir -p /opt/tfos
cd /opt/tfos
今回はUbuntuイメージを使います。
https://hub.docker.com/_/ubuntu/
事前にpullしておきます。
docker pull ubuntu
Dockerfileを作る
/opt/tfos/配下にDockerfileを作成し、以下を記入して保存します。
(2017/02/23 修正しました。)
FROM ubuntu
MAINTAINER cvusk
# insert hostname on environmental variable
ENV HOSTNAME tensorflow.spark
# install prerequisites
RUN apt-get -y update
RUN apt-get -y upgrade
RUN apt-get -y install apt-utils
RUN apt-get -y install software-properties-common python-software-properties
RUN add-apt-repository ppa:openjdk-r/ppa
RUN apt-get -y update
RUN apt-get -y install wget curl zip unzip vim openjdk-7-jre openjdk-7-jdk git python-pip python-dev python-virtualenv
ENV JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
# git clone tensorflowonspark.git
WORKDIR /opt/
RUN git clone --recurse-submodules https://github.com/yahoo/TensorFlowOnSpark.git
WORKDIR /opt/TensorFlowOnSpark/
RUN git submodule init
RUN git submodule update --force
RUN git submodule foreach --recursive git clean -dfx
# environmental variable for tensorflowonspark home
ENV TFoS_HOME=/opt/TensorFlowOnSpark
WORKDIR /opt/TensorFlowOnSpark/src/
RUN zip -r /opt/TensorFlowOnSpark/tfspark.zip /opt/TensorFlowOnSpark/src/*
WORKDIR /opt/TensorFlowOnSpark/
# setup spark
RUN sh /opt/TensorFlowOnSpark/scripts/local-setup-spark.sh
ENV SPARK_HOME=/opt/TensorFlowOnSpark/spark-1.6.0-bin-hadoop2.6
ENV PATH=/opt/TensorFlowOnSpark/src:${PATH}
ENV PATH=${SPARK_HOME}/bin:${PATH}
ENV PYTHONPATH=/opt/TensorFlowOnSpark/src
# install tensorflow, jupyter and py4j
RUN pip install pip --upgrade
RUN python -m pip install tensorflow
RUN pip install jupyter jupyter[notebook]
RUN pip install py4j
# download mnist data
RUN mkdir /opt/TensorFlowOnSpark/mnist
WORKDIR /opt/TensorFlowOnSpark/mnist/
RUN curl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
RUN curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
RUN curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz"
RUN curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"
# create shellscript for starting spark standalone cluster
RUN echo '${SPARK_HOME}/sbin/start-master.sh' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo 'MASTER=spark://${HOSTNAME}:7077' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo 'SPARK_WORKER_INSTANCES=2' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo 'CORES_PER_WORKER=1' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo 'TOTAL_CORES=$((${CORES_PER_WORKER}*${SPARK_WORKER_INSTANCES}))' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo '${SPARK_HOME}/sbin/start-slave.sh -c $CORES_PER_WORKER -m 3G ${MASTER}' >> ${TFoS_HOME}/spark_cluster.sh
RUN echo '${SPARK_HOME}/sbin/start-slave.sh -c $CORES_PER_WORKER -m 3G ${MASTER}' >> ${TFoS_HOME}/spark_cluster.sh
ENV MASTER=spark://${HOSTNAME}:7077
ENV SPARK_WORKER_INSTANCES=2
ENV CORES_PER_WORKER=1
ENV TOTAL_CORES=2
# create shellscript for pyspark on jupyter and mnist data
WORKDIR /opt/TensorFlowOnSpark/
RUN echo "PYSPARK_DRIVER_PYTHON=\"jupyter\" PYSPARK_DRIVER_PYTHON_OPTS=\"notebook --no-browser --ip=* --NotebookApp.token=''\" pyspark --master ${MASTER} --conf spark.cores.max=${TOTAL_CORES} --conf spark.task.cpus=${CORES_PER_WORKER} --py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py --conf spark.executorEnv.JAVA_HOME=\"$JAVA_HOME\"" > ${TFoS_HOME}/pyspark_notebook.sh
RUN echo "${SPARK_HOME}/bin/spark-submit --master ${MASTER} ${TFoS_HOME}/examples/mnist/mnist_data_setup.py --output examples/mnist/csv --format csv" > ${TFoS_HOME}/mnist_data_setup.sh
やっていることとして、TensorFlowOnSparkスタンドアローン版の構築手順をDocker用に書き換えています。
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_standalone
spark master、slaveの起動をシェルスクリプトにしておきたかったので、その変数のために環境変数にHOSTNAME=tensorflow.sparkを定義しています。
もうちょいかっこいい方法でホスト名を使いたいのですが・・・。
これをビルドします。
cd /opt/tfos
docker build -t tfos/tfos .
こんな感じにできあがります。
docker images

動かしてみます
Dockerイメージができあがったら以下でrunします。
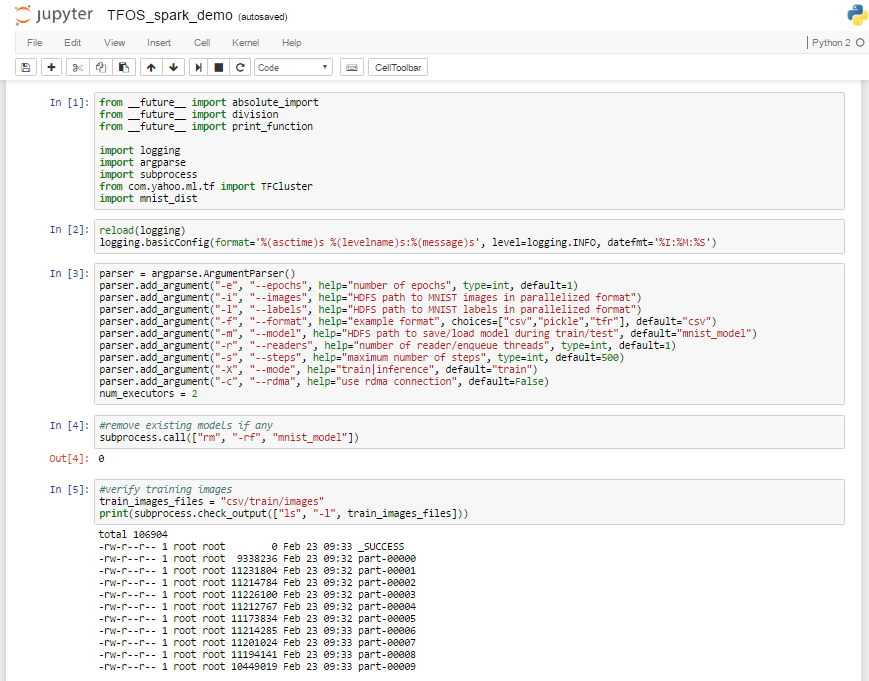
docker run -it -p 8889:8888 -h tensorflow.spark 5db5add35c10 /bin/bash
ポート番号は8889:8888(ホストOSのポート:コンテナのポート)で公開します。これはpyspark(Jupyter Notebook)用です。
ホスト名にtensorflow.sparkを指定しますが、これはDockerfileに書いたものを使っています。
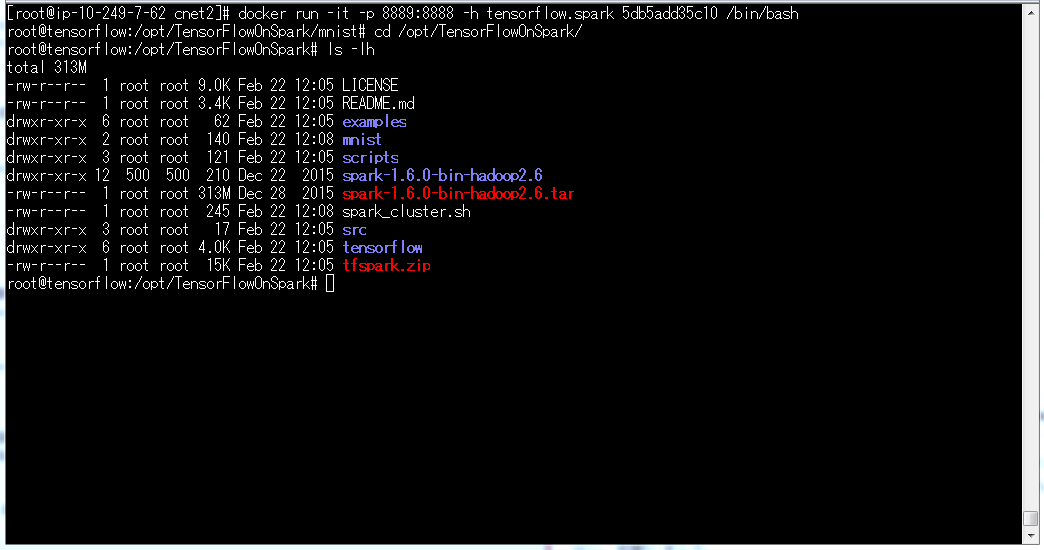
はい、起動しました。
/opt/TensorFlowOnSpark配下のspark_cluster.shを実行すると、このDockerコンテナがspark master兼slaveになります。
なお、slaveは2インスタンス起動しています。
cd /opt/TensorFlowOnSpark
sh ./spark_cluster.sh
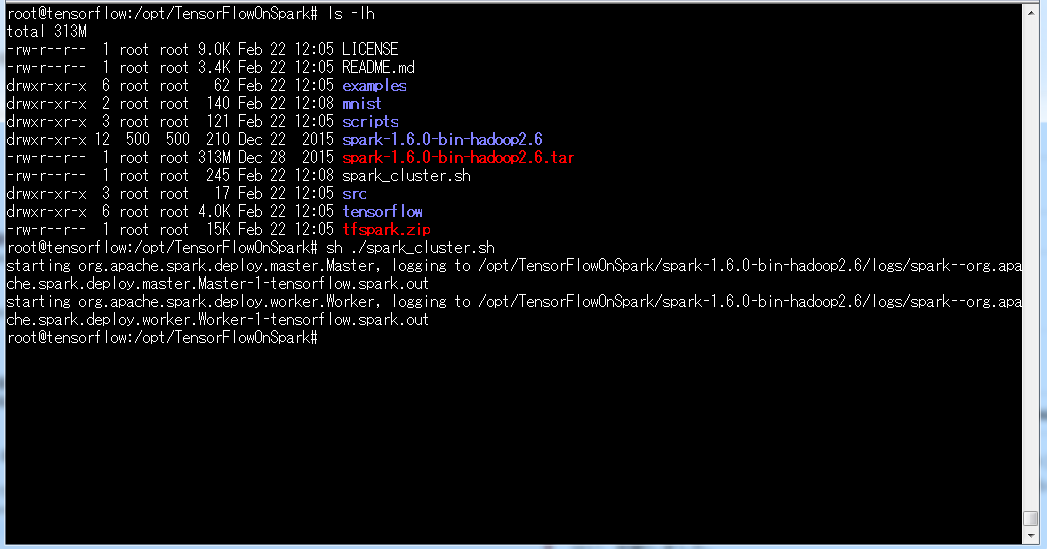
/opt/TensorFlowOnSpark/配下にMNISTのデータセットアップ用シェルスクリプトを用意しています。
これを実行して、MNISTのトレーニングとテストデータを生成します。
cd /opt/TensorFlowOnSpark/
sh ./mnist_data_setup.sh
/opt/TensorFlowOnSpark/配下にpysparkの起動用シェルスクリプトとしてpyspark_notebook.shを配置しています。
これを実行すると、pysparkがJupyter Notebookで起動します。
cd /opt/TensorFlowOnSpark/
sh ./pyspark_notebook.sh
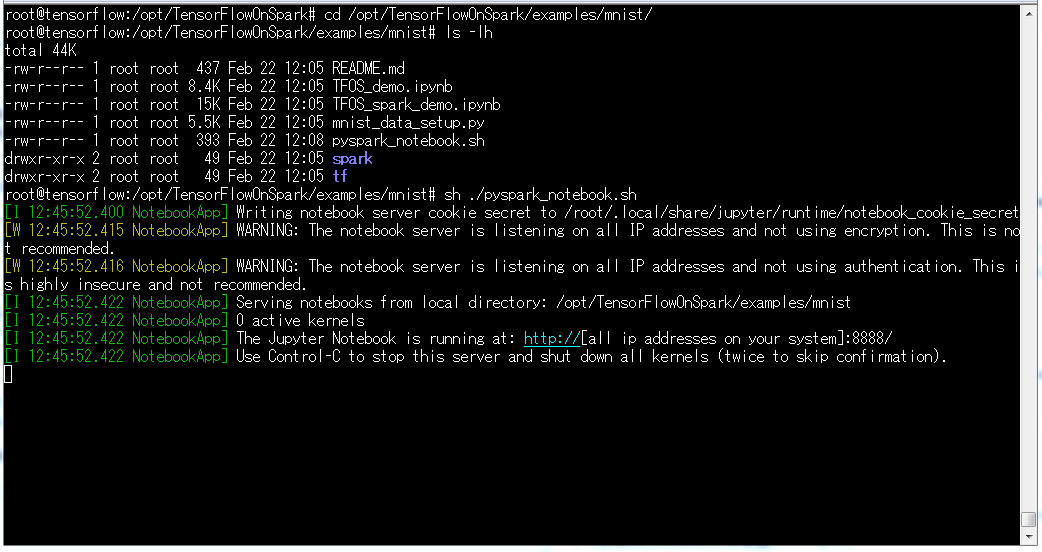
起動できました。
ブラウザで http://<ホストOSのIPアドレス>:8889 にアクセスします。
このように、Jupyter Notebookにアクセスできます。
最後に・・・できなかったこと(誰か教えてくださいm(_ _)m) → 解決しました。
ここでMNISTのデモ用に用意されている TFOS_spark_demo.ipynb を実行したいのですが、com.yahoo.ml.tf がインポートできなくてエラーになります。
(T_T)
ググっても情報が出てきませんし、どなたか解決策をご存じないでしょうか・・・?
なんか半煮えな終わり方ですが、ひとまずTensorFlowOnSparkOnDockerを構築できました(?)。
解決しました。
PYTHONPATHの指定が足りなかったようです。
Dockerfileに ENV PYTHONPATH=/opt/TensorFlowOnSpark/src 追加しました。
これでMNISTのデモ@Jupyter Notebookも成功します。