はじめに
この記事は、私がいままでに約1万冊の薄い本や薄くない本をスキャンしてきたお話のまとめです。
この記事にはコードは殆ど含まれていませんが、ノウハウは含まれていますので、参考になるかと思います。
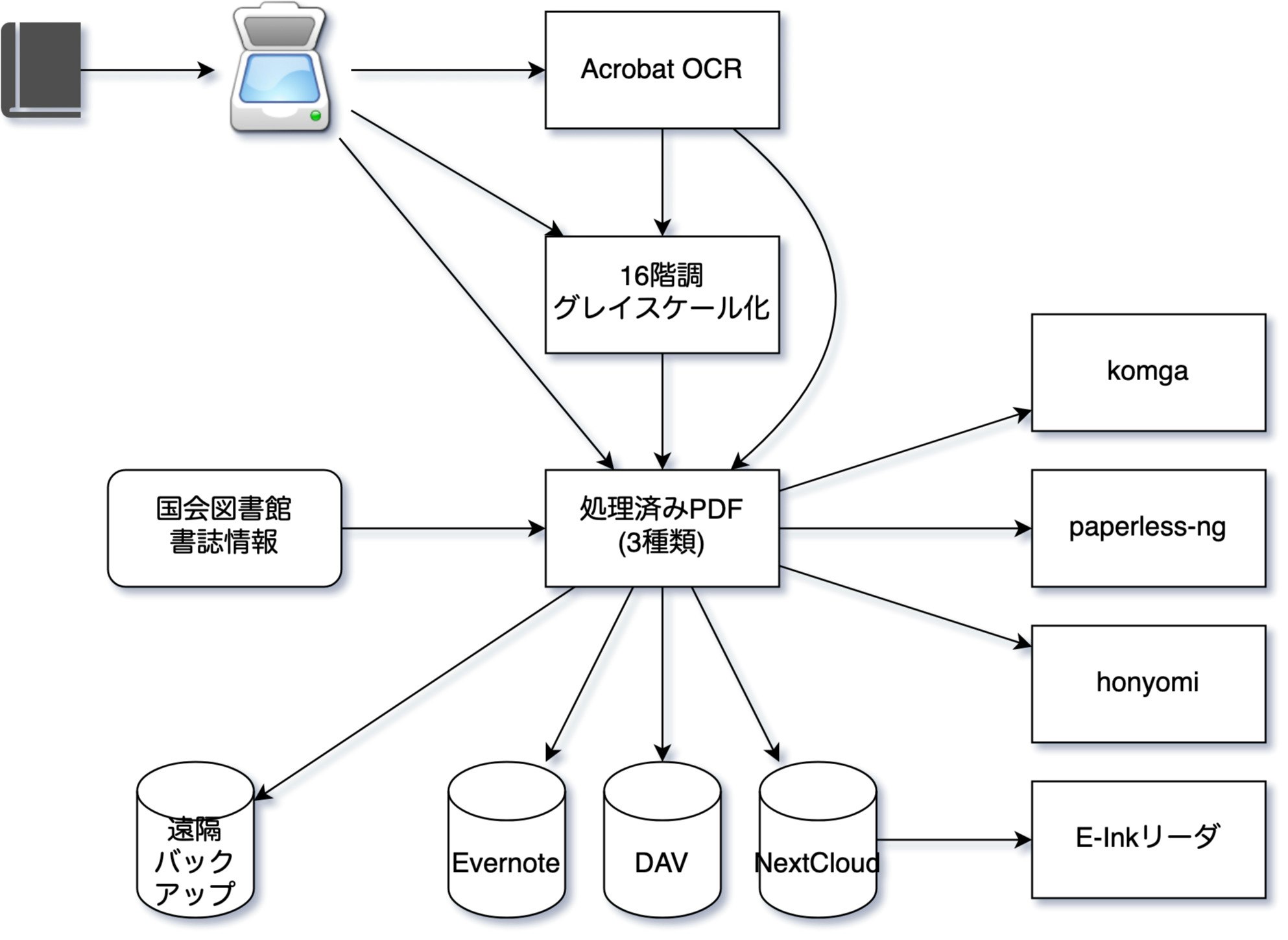
スキャンしてできたpdfはそのままでは役に立たないので、変換や整理をして便利にしましょう、ということですね。
手段と目的
書籍スキャン、つまり自炊をするにあたって最初に注意しなければならないのは、「自炊は目的か手段か」をはっきりさせることではないでしょうか。
世の中には自炊紹介をするサイトや同人誌がたくさんありますが、私が自ら自炊するにあたっては「自炊は手段」「目的は読書」として行なっています。
趣味というのは仕事と異なり、目的と手段の交換が許される世界です。たとえば鉄道というのもは一般に移動手段であり道具にすぎないのですが、鉄道趣味の人は鉄道そのものが目的となります。
「自炊が趣味」でしたら、「自炊だけひたすらして、読書をせず満足」ということもおきるわけですが、私の場合はあくまで「電子化された書籍を読む」ことを目的としています。スキャナもOCRも蔵書管理もE-Inkリーダーも、あくまで道具であって目的ではありません。
従って道具の作成や改善を頑張るにしても、あくまで自己目的化してしまわない範囲で改良して、本当の目的の時間を減らすことがないようにします。
なにもこれは自炊だけの話ではありませんね。
「awsの構築を自動化しよう」「システムを監視しよう」とかやっていると、いつのまにか自動化や監視そのものが目的となってしまうという本末転倒なことがおこります。人生においても、お金や職業は人生の道具であって目的ではないはずですが、仕事人間になってしまっている人はよくみかけます。
趣味だからこそ、目的と手段の定義ははっきりさせたいところです。
(当初の)要件と想定ユースケース
-
Evernoteに検索用PDFがはいっており、全文検索ができる。
- Evernote公式クライアントや、APIを用いて全文検索ができる。
-
NextCloudにはE Ink端末にフレンドリーな16階調グレースケールPDFも入っており、E Ink端末から簡単にアクセスできる。
- Android E Ink端末 (Onyx Booxなど) ではNextCloudの公式クライアントや、WebDAV対応PDFビューアで本を探して読むことができる。
- 単なるWebDAVではなくNextCloudを使うことにより、名前を変更しても同一ファイルとして追尾する、タグ、コメント、アクティビティ確認、プレビュー、プラグインによる付加的機能(elasticsearchの全文検索など)が使える。
-
Evernoteの容量制限を気にしないで済むようにする
- スキャンしたままのものでは容量が大きすぎる
-
環境の構築、実際の運用は自動化する。Dockerがあれば、何処でも簡単に動くようにする。
-
想定ユースケース1 「E Ink端末で読書」
- NextCloudまたはEvernoteで全文検索をし、目的の本を探す
- E Ink端末でNextCloudにあるE Ink用PDFにアクセスする
- 読む
-
想定ユースケース2 「iPadで調べ物」
- iPadのEvernoteクライアントで検索をする
- ヒットした複数の本について、小容量PDFで必要な所だけ調べる
- 本全体を読み返したい、積ん読スタックの優先順序を操作したい時は、EvernoteやNextCloudのタグを使ってメモをしておく
- E Ink端末で読む(iPadで読んでもいいけど)
追記 2023春
- evernoteはもう使っていませんが、別のノートアプリで同じようなことをしています
- 全文検索はocr結果を用いてmeilisearchで行うことができます
- meilisearchの検索やその他色々をwebuiで行うようにしています
- E-Ink端末としてKindle Scribeでほぼ同じような使い勝手を実現しています
- Send-To-Kindleは使いにくいので、USB接続すると自動で同期するようにMacを設定しました
- なんだかんだいって2万冊くらい薄い本や薄くない本をスキャンしました
- コロナ禍で積読率が下がって既読率が上がっております...
人と計算機の記憶階層
計算機が扱うデータ全てをSRAMに乗せることはできませんので、レジスタ、キャッシュメモリ、主記憶、SSDの補助記憶、HDDの補助記憶、磁気テープや光学メディア、と階層を組みますよね。
人間と「第二の脳」というEvernoteの下に「倉庫としてのNextCloud」をつけるというのがこの記事の味噌です。
Evernoteには容量制限があり、全てをEvernoteに入れることはできません。
月数十枚程度の紙切れしかスキャンしないのであればこんな方法は不要なのですが、Evernoteの容量では足りないテラバイト級のPDFを管理するとなると、「オールフラッシュストレージでは足りないから磁気ディスク復活するしかないな」みたいな話と同じことが登場するわけです。
さらに言うと、NextCloudもオーバーヘッドがありますので、検索が不要ならDavやNFSといった普通のプロトコルを話す普通のストレージに出すということも可能です。
また、NextCloudの「外部ストレージ機能」で普通のNextCloudのガワを被せることもできます。この場合はDavでmvする度に後述のFile IDが変化してしまいますが、コメント等の機能は使えます。
| ストレージ | 総容量 | 速度 | 全文検索 | PDF編集 | 履歴 |
|---|---|---|---|---|---|
| 人間の脳 | 人による | 人による | 人による | 不可 | 人による |
| Evernote | 数百GB程度 | 速い | 可能(課金) | 可能 | 可能 |
| NextCloud | 制約なし | 環境依存 | 遅いが可能 | 不可 | 可能 |
| DAVアクセス | 制約なし | 速い | 不可 | 不可 | 不可 |
という感じで、「人間の頭を頂点とした階層型ストレージを組み、そこに書籍をいれる」というお話がこの記事のキモになります。
Evernote社自体がDropboxやGoogle Driveを下層ストレージとして扱う機能を提供していればいいのですが、現状ではEvernote社とDropbox社はライバルみたいなものですから(実際は使い方が全く異なるにも関わらず)、このようなことは自分でやるしかありませんね。
また、必要に応じてこれらの階層を外から補助するソフトを使います。
前提
- linux, docker, kvm, ghostscript, imagemagickなどの知識があること
- ISBNのない本も多いので、あればラッキーとすること
- windowsの正規余剰ライセンスがあること
- Adobe Acrobat (NOT Reader) windows版の正規余剰ライセンスがあること
- Evernoteは信用するものとすること
- NextCloudは設定済みで、elasticsearch全文検索などが有効になっており、充分な容量があること
既存のものとの比較
PDF書籍・文書管理はたくさんありまして、ScanSnap Homeでもpaperless-ngでも足りる人はそれで良いのですが、「冊数が万を超える」「容量がTBを超える」「OCRや圧縮はAdobe Acrobatを使う(GhostScriptやtesseract-ocrでは不満)」という点が異なります。
手順
人力で裁断してスキャンする
ま、このへんの設定やノウハウはあえて説明する必要もありませんね。
自動化を極端に目指しているとは言え、裁断とスキャンとScanSnap Managerの操作は人力です(笑)。
細かいことだと、
- 横置きでもスキャンできるサイズの本の場合、横向きに置くとスキャン速度が縦置きの√2倍になります。
- 裁断機には、よく使う本のサイズの場所にシールを貼っておきましょう。「コミックはココにあわせる」とか「スキャナ取り込み限界はココまで」とかです。
- スキャン結果はNASの上におくようにします。
- スキャン完了までの間のPDFは不完全です。このファイルを移動したりしてScanSnapがファイルハンドルでアクセスできなくなると、そこまでのスキャン結果は失われてしまいます。
- このNASを、後述のDockerが動いているマシンでnfs mountしています。
- 多少のかすれを気にしてもキリがないので、お気楽にいきます。
スキャンが終わったら、次の圧縮コンテナを起動するだけです。
手動で起動してもいいですし、毎晩うごくようにcronを仕込んでも大丈夫です。
スキャン途中で放置したとしても、スキャン途中のファイルは無視されるだけですから破壊されることはありません。
圧縮コンテナ
このコンテナは圧縮作業をおこない、EvernoteとNextCloudにはOCR済みの検索可能になった小さなPDFや、E Ink用PDFをいれてくれます。
あとは時々暇なときに、Evernoteを見ると小さくなったPDFが書誌情報(仮)つきで入っているので、人手で書誌情報を修正したり追加しておきます。
このコンテナの中では、
- Acrobatを起動して、OCR全文検索可能で小さなPDFを生成する
- E Ink用にあわせた解像度、白黒16階調のPDFを生成する
- NextCloudにこの生成された2種類のPDFをアップロードする
- 16階調PDFへのリンクつきで、全文検索用軽量PDFをEvernoteにアップロードする
ということをします。
ここから全部、このコンテナの中の話です。
PDF完全性確認
処理対象のオリジナルのPDFがスキャンの途中(不完全)でないことを確認します。
不完全かどうかは、pdfinfoで総ページ数が取れるかどうかで判別できます。ページ数が取れないPDFは、たぶんDockerの外でScanSnapが書き込んでいる最中のものですから、触らないでおきます。移動するとそのファイルはPDFではなく単なるゴミになります。
Adobe Acrobat inside KVM inside Docker
ghostscriptでPDFの縮小や、tesseractでOCRといったことも出来るのですが、売り物のAcrobatの品質には敵わないのが現状です。
仕方ないので、AcrobatにOCR済の圧縮PDFをつくってもらいます。
コンテナの中でKVMを起動します。
Dockerの中でKVMを使う場合、
volumes:
- /dev/kvm:/dev/kvm:rw
privileged: true
としておけば行けます(ホスト側が/dev/kvmを出している必要はあります)。
参考: dockerでKVM
あとはwindowsの話で、立ち上げると
- windows外部のサーバから処理対象PDFを取ってくる
- Acrobatを起動する
- マウスイベントを画面に注入し、Acrobatを無人操作する
- kvmの外からvncdotoolを使ってvnc経由でイベントを注入しました。OS毎騙してしまいます。
- Acrobatがアクションウィザードを実行する
- アクションウィザードのパラメータは予め調整しておきます。私の設定では、少女漫画単行本一冊で概ね13MBくらいになります。
- 定期的にAcrobatの出力ディレクトリの中にできたPDFを、windows外部に取り出す
という流れにします。
私は普通にコードを書いて自動化しましたが、最近流行のRPAという手もあるんでしょうね。
参考:
自動化ツールの比較
RPAExpressを使って漫画自炊の効率化を行った話 - Qiita
また、PDFを置くのは「windows外部のサーバ」といっても、クラウドではなく、このコンテナの中のhttpdで充分です。
kvmの中からkvmの外だけどコンテナの中にアクセスするということです。
無脳な無人操作は「アプリケーションがエラーを出していた」「何か人間に質問してきていた」「OSが何か文句をいっている」といった場合でもそのまま続いてしまうので、「2時間以上成果物が出てこなければ、kvmをつくるところからやりなおし」といった監視をかけておきます。
vmの中での変更は一切次に引き継がれないという使い捨てvmとして、qemu-img createでbacking_fileつきのqcow2を毎回つくり、vmが死んだらそれは棄て、またやり直しとします。
やり直してもAcrobatの出力はvmの外のhttpdの中ですから、うまくいかなかったファイルからやり直すことができますね。
参考: qemu-img Backing Files: A Poor Man's Snapshot/Rollback
vmなのでCPUの効率が悪そうに見えますが、人間が物理マシンを操作してAcrobatを動かすより「人間」の効率はずっと良いので、そこは我慢して、人間が寝ている間も人間が働いている間も、タスクが残っている限り働いてもらいます。
可哀想なAcrobatたん、夜な夜などんなに努力して成果物を作っても、それはvmの外からかすめ取られ、人間に操作されていると思ってもそれは異世界(vmの外)の機械(vncdotool)で、生きた証(クラッシュレポートやログ)もvmの消滅と共に消える運命… なんたる畜生労働!
E Ink端末向けモノクロ16階調PDFをつくる
ここからはAcrobatではなく、ImageMagickを使います。
Acrobatに適用するのは無理なのですが、ここから先の時間が掛かる変換はGNU Parallelを使うようにすると、ジョブをCPUの数だけ詰め込んでくれます。
参考: GNU parallel
- gsでPDFをページ毎にpngにする
- 各ページについて、
- ImageMagickで文字のある領域を判定する
- 文字の領域が狭ければ、そのページは白紙なのでスキップする
- 文字のある領域のみ取り出して、E Ink端末にあったDPIと階調のpngに変換する。
- pngを最適化する
- img2pdfでpngをそのままPDFにする
- Acrobatが生成したOCR結果つきPDFを切り刻み、背景として重ねる
- 全ページのpdfが揃ったらpdftkで繋げて一つのpdfにする
PDFではなくDjVuのほうが小さくなりますので、DjVuで困らない人はDjVuでもいいでしょう。
私も昔はDjVuを使っていましたが、DjVuリーダーよりPDFリーダのほうが選択肢が多いこともあり、今は多少の容量には目をつぶってPDFにしています。
参考: What is High Compression PDF?
文字のある場所だけの画像をIMで作るには以下のサイトが参考になります。
参考: スキャンした書籍や書類の余白をImageMagickで除去する
OCRされたPDFをE Ink用のPDFの背景として重ねることにより、検索が可能になります。
背景としてPDFを重ねるのは、pdftk backgroundコマンドを使います。
重ねるためのPDFはOCRで検出された文字だけあればいいので、
gs -o 出力pdf -sDEVICE=pdfwrite -dFILTERVECTOR -dFILTERIMAGE 入力pdf
として生成した真っ白(文字の検索はできる)pdfで大丈夫です。
(acrobatでのOCRの設定によってはこの方法は使えないかもしれません)
このモノクロ16階調化はE Ink端末を想定した最適化なのですが、普通のカラータブレットでも恩恵はあります。
スキャンのかすれや裏写りがなくなり、読みやすくなります。
国会図書館から書誌情報をとってくる
さらに、ついでに以下の処理もします。
- 本の後ろから順に何ページか、pngをzbarのバーコードリーダにかける
- 古い本でバーコードがないときでも、OCR結果にはISBNの数字がはいっていることもあります。ISBNには一定のルールがあるので、それを満たしていればOCR結果もバーコード結果と同様に扱えます。
- ISBNが取れたら、国会図書館APIを使って書誌情報をとってきます
- 短時間で沢山アクセスすると怒られますが、PDFを変換しながらの頻度であれば問題ありません
- 書誌情報はyamlで保存しておきます
生成されたPDFをNextCloudにアップロード
NextCloudは単なるWebDAVとして操作できるので、アップロードはそのままWebDAV操作です。
ポイントはこの後で、
<?xml version="1.0"?>
<d:propfind xmlns:d="DAV:" xmlns:oc="http://owncloud.org/ns" xmlns:nc="http://nextcloud.org/ns">
<d:prop>
<oc:fileid />
</d:prop>
</d:propfind>
というメッセージを
https://NextCloudホスト/remote.php/webdav/アップロードしたpdf
に対して、PROPFINDで、ヘッダにDepth:1をつけて送り込みます。
すると、xmlでoc:fileidという数値が取れます。
この数値はファイルを識別するためのIDで、ファイル名が変わったりしても変わりません。
ここへのリンクは、許可されたNextCloudユーザであれば、
https://NextCloudホスト/index.php/f/ファイルID
でアクセスできます。
参考: Using PROPFIND with custom properties (owncloud / nextcloud)
参考: Basic APIs — Nextcloud 15 Developer Manual 15 documentation
ということで、16階調PDFに書誌情報を反映させたファイル名をつけ、NextCloudにあげ、このIDを取っておきます。
実はNextCloudはこれ以外にも、コメントやタグも外から操作できます。
「EvernoteへのリンクをNextCloudのコメントにいれ、NextCloudへのリンクをEvernoteにいれる」
といった相互参照を作ると、「検索はEvernote、保管はNextCloud」といういいとこ取り環境ができます。
参考: Comments API :: ownCloud Documentation
私の場合、オリジナルのPDF(ScanSnapが生成したPDF)はdavでアクセスできる場所にいれ、NextCloudには入れていません。
ウチのNextCloudもそんなに高速ってわけではないので、検索、共有、履歴といったものが不要なものまでは入れていません。
Evernoteにいれる
Evernote apiはpythonで簡単に操作できます。
Evernoteのノートは、ENMLという名前のxhtmlのサブセットですが、PDFなどは<en-media>というタグで参照します。
Acrobatが作った縮小PDFをこれでリソースとしてノートにつけ、上記のNextCloudへのリンクもつけたENMLをつくり、Evernoteに入れます。
私はタイトルを
yyyymmddHHMMSS 筆者名/書籍タイトル名 巻数
で統一しています。
もちろんEvernoteである必要はまったくありません。
商用ならNotion, フリーならJoplinやLeanoteでも問題ありません。
Evernoteに課金していればPDF検索ができますが、PDF検索を別の方法でできるのならそれでいいのです。
ここまで、スキャン後の変換コンテナでした。
クラウドバックアップコンテナ
これとは別のコンテナで、PDFをgpgで自分宛に暗号化したのち、どこか遠くにも転送するようにします。
万が一NASが吹っ飛んでも、オリジナルのPDFは保護できるようにします。
クラウドでもいいですし、実家や友人や何か合法的に置いておける遠隔地にRaspberry PiとHDDを置いておいてVPN経由で飛ばすといった方法でDR, BCPします。
暗号化の相手としてYubikeyの鍵も入れておけば、たとえ津波で自宅が崩壊したとしても、Yubikeyさえ無くさなければなんとかなりますね。
参考: yubikeyでセキュリティ筋力を鍛える · JoeMPhilips
ちなみに我が家のNASはAsustorの8TB x 4 (RAID5, 実効24TB, ext4)なのですが、一度リビルド中に別のHDDが死んで冷や汗をかいたことがあります。
mdadmと格闘の末なんとか復活しましたが、その時もこのバックアップがあることで焦らずに済みました。
RAID崩壊時の最大の敵は「焦って人為的に壊してしまう」なので、心理的安心を確保するというのはとても大切ですね。
ファイル名同期コンテナ
上記コンテナが動いてしばらくしてから、人間がEvernoteにアクセスすると、縮小PDFが取得した書誌情報と共に上がってきます。
暇なときに確認して、ノートのタイトルにはいってる書誌情報の確認と修正をします。
同人誌などは書誌情報はとれませんので(稀に評論本で国会図書館に納本してあることがあるが😆)、そこは手でつけます。
商業本でも、副題をつけるつけない等、細かい修正が必要なこともあります。
そのあと、定期的に夜中に起動するコンテナで、Evernoteの各PDFのノートのタイトルとNextCloudのPDFのファイル名を同期させます。
EvernoteのENMLからNextCloudのファイルIDをとり、
<?xml version="1.0" encoding="UTF-8"?>
<d:searchrequest xmlns:d="DAV:" xmlns:oc="http://owncloud.org/ns">
<d:basicsearch>
<d:select>
<d:prop>
<d:displayname/>
<oc:fileid/>
<oc:size/>
</d:prop>
</d:select>
<d:from>
<d:scope>
<d:href>/files/ユーザID</d:href>
<d:depth>infinity</d:depth>
</d:scope>
</d:from>
<d:where>
<d:eq>
<d:prop>
<oc:fileid/>
</d:prop>
<d:literal>探す対象のファイルID</d:literal>
</d:eq>
</d:where>
<d:orderby/>
</d:basicsearch>
</d:searchrequest>
を/remote.php/dav/に向かってSEARCHで投げると、ファイル名が取れます。
そのファイル名に向かってWebDAVとしてMOVEリクエストを投げると、IDそのままで名前を変える(移動させる)ことができます。
名前を変えてもファイルIDはそのままで、そのファイルのアクティビティ(変更履歴)に名前が変わったことが記載されます。
私はEvernoteの本には、その本のジャンル(「創作少女」「RMC」など)や入手場所(「コミケ65」「コミティア100」「技術書展3」など)をつけています。
NextCloudにも同じタグを反映させています。
PDFにはjpegのEXIF, mp3のID3のようなプロパティがありますので、これも更新しておきます。
pdftkのupdate_info_utf8コマンドで更新できます。
参考: PDFtkでPDFのタイトルや作成者を設定する - A Micro Toolbox
NextCloudのFile IDとEvernoteのノートのGUIDを相互参照をしているのですが、何らかの理由でたまに相互参照が崩れることがあり、みなしご(orphan)なリンクになってしまうことがあります。
整合性確認と自動修正をするスクリプトをつくり、定期的に走らせます。
ただし1万冊以上あると数日かかります。
基本的には設計変更したりしたときだけやっています。
転送スクリプト
PDFをE-Inkリーダーに転送してくれるスクリプトを作っておきます。
私はAndroidなE-Inkリーダを使っているので、スクリプトではNextCloudの特定の場所にputするようにし、リーダ側ではDAV同期ソフトを使ってpullしています。
Kindleの場合、(自動化が面倒なWebUIを除いて)デバイスにPDFを転送をする方法は二つあります。
一つはSend-To-Kindleのメールを使う方法と、USB接続です。
前者は最大50MBのPDFをメールに添付して送ると処理してくれるというものですが、
- 50MBというのはあまりに小さい (pdftkで切り刻む必要がある)
- amazonのクラウドに処理されるのは気持ち悪い (仕事でawsを散々使ってい今更ですが...)
ということで、USB接続で転送します。
macにKindleが接続されたら、rcloneでNextCloudの特定の場所の中身をkindleの中に書き込むようにします。
同期スクリプト
#!/bin/sh
if [ ! -e /Volumes/Kindle/documents/ ] ;then
exit
fi
echo "Kindleを同期しています" | say
/usr/local/bin/rclone copy --modify-window 2s -P nextcloud:/pdf転送/ /Volumes/Kindle/documents/
diskutil unmount /Volumes/kindle
echo "Kindleの同期が終了しました。デバイスを取り外してください" | say
を書き、
macos - How to start an application when a specific disk is mounted - Ask Different
の方法で、
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>local.StartOnMount.Kindle</string>
<key>ProgramArguments</key>
<array>
<string>/Users/hoge/bin/synckindle.sh</string>
</array>
<key>RunAtLoad</key>
<false/>
<key>StartOnMount</key>
<true/>
</dict>
</plist>
と書いてlaunchctl load local.StartOnMount.kindle.plistするとあら不思議、KindleをMacに接続すると自動でpdfの転送が始まって、終わったら音声で取り外していいことを教えてくれます。
書籍以外の紙
ここまでは書籍の話でしたが、E Ink最適化のみ省略する「ペラペラ紙切れ向け」の処理も行っています。
郵便物、どこかで貰ってきたチラシ、同人ペーパー、レシートといったものも同様にスキャンし、AcrobatでOCRと縮小をし、NextCloudとEvernoteに入れています。
この手の紙切れにはQRコードが印刷されていることが多いのですが、OCRではQRコードは認識できませんので、zbarを使ってバーコード類を認識してEvernoteのノートにはPDFと同時に入れてあげます。
EAN13コード(いわゆる「JANコード」)のバーコードを見つけたらAmazonの検索にリンク、といったこともします。
ところでQRコードってShift JISだったんですね1。
発明された1990年代中ばってすでにUCS2とutf16とutf8がゴチャゴチャ戦っていた頃だったと思うんですけど。
zbarでも非ASCIIなQRコードはうまく扱えないことがありますが、流石に仕方ないよね...
更にEvernote上で整理した上でアクション(返事や新作購入など)が必要なものはタグにいれておくと、やはり同期が走ってtodoistに登録する、ということもしています。
また、この手の小さい紙の検索や閲覧はpaperless-ngを使うのが便利です。
他のソフトとの連携
検索
pdfはhonyomiやFESSでも検索ができます。
honyomiはRESTではなくcliなので、docker exec honyomi ...という形で操作します。
Honyomi - Rubyで書かれたpdfの全文検索エンジン
オープンソース全文検索サーバー Fess
acrobatでocrした結果がありますので、それをMeilisearchにいれることもできます。
リーダ
Komgaという漫画リーダがあります。
RESTで操作し、タグをつけたり筆者名での管理ができますのでコミケ100とか小説といったタグをつけて管理できます。
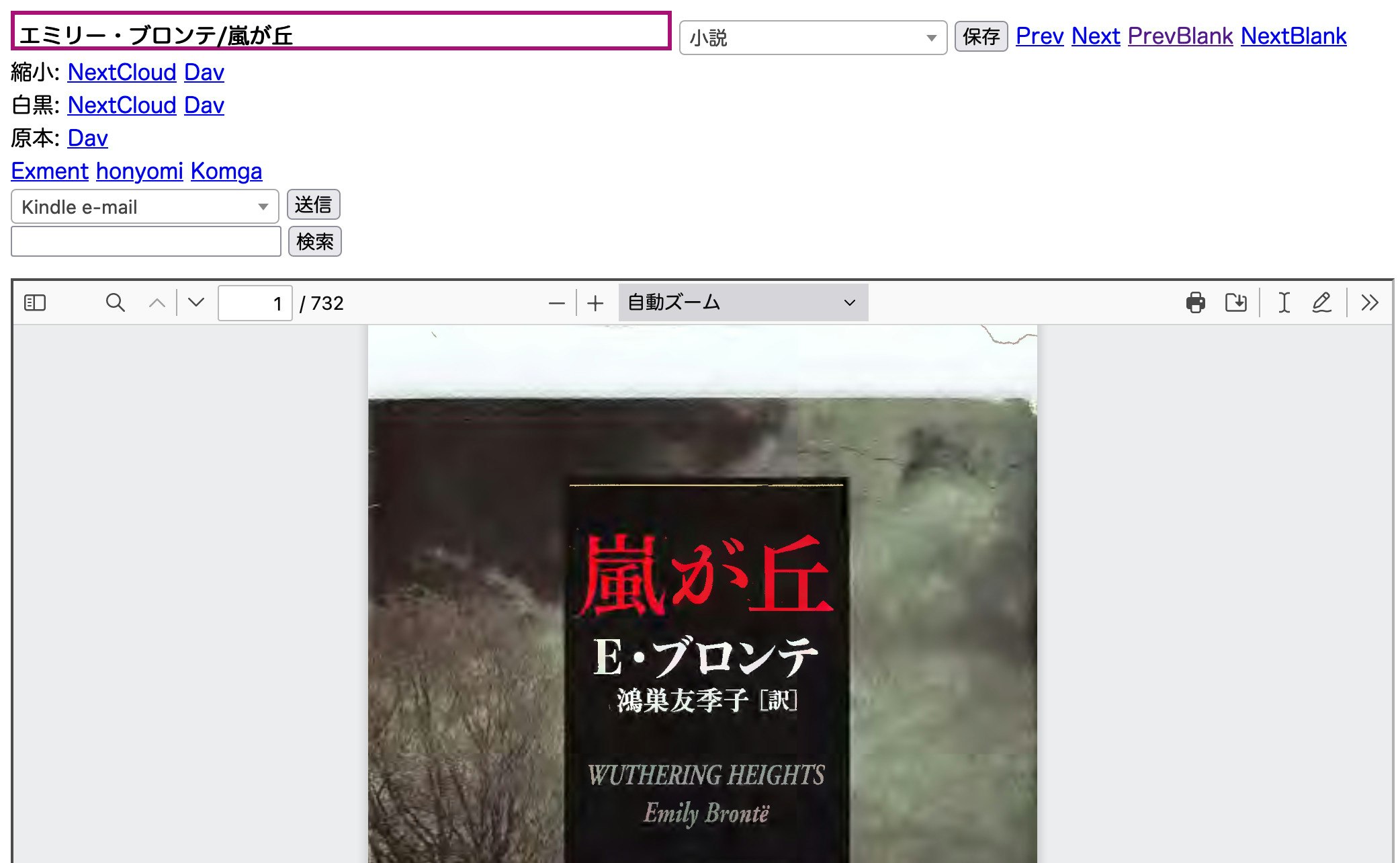
Webポータルページ
ひとつひとつのpdfについて、webブラウザ上でタイトルを変更したり、上記転送スクリプトをキックしてKindleや何かに送信したり、検索したりといったことができるページを作っております。
Future work
音声への適用
同様のアプローチで、音声データをいれることもできます。
Whisperで文字起こしができますので、Evernoteに文字起こししたあとのテキスト、NextCloudに元のmp3、ということができます。
Whisperでやってみたのですが、ノイズが多いと精度がよくないため、OCR全文検索に比べるとまだ改善の余地があるかな、という感じはします。
ジョブの最適化
PDFの変換コンテナですが、
- メモリはたくさん食べるが並列度はないAcrobat
- pdfのファイル数だけ並列に処理できるグレースケール化
- 軽くて逐次処理のNextCloudとEvernoteへの転送
という、性質の異なる3つのタスクが走っています。
これはバッチジョブスケジューラを用いると資源の効率的利用が可能ですね。
ただ、kube-jobは依存関係が出来ないみたいだったので監視して面倒をみてくれる親を一つつくるか、汎用のジョブスケジューラ(pbsやslurmなど)にDockerを叩かせるか、となってしまいます。
面倒な割に、そんなに必死になって詰めるほど資源が足りないわけでもないんですよね...
参考: Kubernetes Jobを用いたバッチシステムのリソース最適化 AbemaTVが抱えていた問題とその解決策 - ログミーTech
Evernote以外への引越し
Evernoteももう斜陽かもしれません...
でもご安心を、このような階層を組んでいるのであれば全部まとめて引っ越す必要はなく、その階層だけ差し替えればよいのです。
相互リンクの修正は必要ですがスクリプトを書いて回しておけば治ります。
いろいろあって私はJoplinに引っ越しまして、実はもうEvernoteはほとんど使っていません。
索引
索引なんか作らずに「全文検索すればいいよ」という暴力的解決方法を採用しているのですが、それでも「同じ作家の別の作品を読みたい」といったときは索引的なものがあると助かります。
NextCloudやEvernoteではなくdavの中でしたらln -sができますので、それを使って
/pdf/gray/by_author/お/小野不由美/yyyymmddHHMMSS_小野不由美_図南の翼.pdf
といったディレクトリわけができるわけですが、ここで問題となるのが「お」をどうやって取得するのか、です。
冊数が多いと階層をつくらずフラットに筆者名をリスティングすると遅くて大変なのです。
大抵はkakasiでうまくいくのですが、同人サークルや一般人の名前としてよくある表記ではないものについては結構難しいです。
例えば「冲方丁」先生は「ちゅうほうちょう」先生になってしまいます。
冲方丁の本が「ち」の棚に入っているというのを人間が想像するのはちょっと難しいですよね。
せめて「おきかたちょう」で「お」くらいでしょうか(笑)。
「うえとおのこうへい」「ひびにち」「やなぎみさと」とかまだ推測ができるので良いのですが、「きょうたかしなか」(姜尚中)は無理だわ...
以下の方法や、wikipediaやpixivから頑張るといった手もありますね。
参考: Namelti : 人名の読み仮名候補を自動列挙するためのライブラリ - LINE ENGINEERING
参考: mecabに人名辞書追加 - Qiita
まとめ
個々の技術は全然難しいものじゃありません。
偉いのはScanSnapやAcrobatやEvernoteやNextCloudやE Ink端末や、様々なソフトをGPLやBSDで公開している方達であって、私ではありません。
本の筆者にも、これらの作者にも、感謝です。
これらを組み合わせることにより、「たしかどこかの本に○○の話題があったはず」という全文検索をしたり、E Ink端末で気ままに目に優しい読書をすることができるようになります。
Evernoteはクラウドなので自分の手元を離れてしまう訳ですが、共有をしたりしない限りは、著作権上の問題もないはずです(厳密に確認したわけではないが)。
では、快適な電子書籍ライフを!
-
現在の仕様としてはutf-8も行けるらしいですが、相互運用性を考えると日本国内では事実上Shift JIS一択でしょうね。 ↩