けものフレンズの二期も発表され👏、ちょうどコミケの時期でもあるということで、TensorFlow / Kerasの勉強も兼ねて、写真をアップロードするとなんのフレンズか識別するサービスを作ってみた。
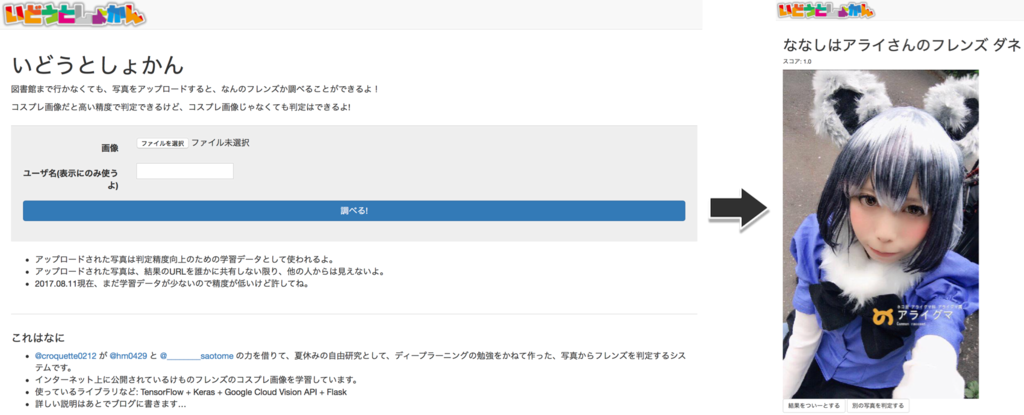
全容としては、
- TensorFlow + KerasでCNNを構築し独自データの学習を行う
- VGG16ベースの転移学習を行って精度を向上させる
- 学習結果を使って、入力画像を分類する
- Cloud Vision APIのFace Detectionと組み合わせて精度をあげる
- Flaskを使ってWebサービスとして提供する
といったところだ。
CNN(VGG16ベース)を使った、大分オーソドックスな画像分類なのだが、実際にWebサービスとして構築する上で細かい部分で苦戦することがあったので、記録として残しておこうと思う。
長くなるので、まずは学習データの用意編から。
学習データ
何を学習させるか
- アニメに出てくるキャラクターを学習させる
- コスプレ画像を学習させる
- 両方合わせる
最初はアニメに出てくるキャラクターを学習させた上で、入力した実際の写真からキャラクターを推定する仕組みにしようかと思ったのだが、どう考えても納得感のある結果が出る気がしなかったので、まずはインターネット上に公開されているコスプレ画像を拝借して学習させることにした。
コスプレ画像を集める
Google画像検索とTwitterで、ひたすらコスプレ画像を探して手動で分類をしていく。なるべく自動化したかったのだが、APIが廃止されていたりノイズが多かったりで、結局手動で頑張らなければいけない部分が大きかった…。
久しぶりにGoogleの画像検索のAPIを使おうとしたら、なんと廃止されていて使えなかった。どうやら調べてみると他の検索エンジンも軒並み、APIの提供を廃止したり縮小したりしていた。
Googleの場合は、Custom Searchを使えば一応画像検索ができるようだ。登録が面倒くさいけれども…。
google_image_fetcherというgemを使うと、比較的簡単に検索結果の画像をダウンロードしてこれるのだが、ページングに対応していなかったので、forkしてページングに対応させて使った。
一応公開しておいたので、もし使いたい人がいればどうぞ。bundle exec google_image search --max_page=10のような形で利用できます。
Twitterの場合も、数年前に比べてAPIの制限はどんどん厳しくなってきている様子…。過去一週間を遡ってAPIで画像を検索するのは現実的に無理そうだった…。
集めた画像の分類
集めた画像はキャラクター毎に、フォルダに分類して保存していく。
- original
- 000_kaban
- image1.jpeg
- image2.jpeg
- ...
- 001_serval
- 002_arai
- ...
- 000_kaban
後述のとおり、このデータはKerasのImageDataGeneratorを使って読み込ませていく。ImageDataGeneratorでは、ディレクトリがalphanumericalな順番で読み込まれていくので、先頭に数字をつけて順番がわかるようにしておくと何かと便利。
複数の人物(キャラクター)が写っている画像に関しては、キャラクター毎に切り分けて分類した。
なるべく沢山集めたかったのだが、各キャラ80枚前後、合計で600枚集めるので精一杯だった。
顔周辺を切り取る
集めたコスプレ画像は、全身が写っているものから顔周辺しか写っていないものまで色々あった。そのまま学習させてしまうと、画像内に写っているキャラクター以外の要素(背景など)を学習してしまい、判定の精度が上がらない可能性がある。
本来であれば、キャラクターの全身のみを切り出して学習させたいところなのだが、画像内からキャラクターの写っている部分を自動的に抽出するのは難しい。学習用データのみであれば、手動で一枚ずつクロップしていく形でも良いのだが、判定時に入力画像からキャラクターの部分だけを正確に自動的に抽出させるのは結構難易度が高い。
そこで、今回は顔周辺のみをクロップする形にした。顔の検出であれば、OpenCVやGoogle Cloud Vision APIなど、既製のライブラリやAPIを使って簡単に範囲を抽出することができる。コスプレしている画像だと、普通の顔検出よりも精度が低くなってしまう問題はあるのだが、とりあえず今回は顔検出をして、顔周辺の情報を学習・推論に利用する方向にした。
| Library/API | 検出成功数(枚) | 誤検知数(個) |
|---|---|---|
| Cloud Vision API | 53 / 71 | 0 |
| OpenCV(default) | 36 / 71 | 85 |
| OpenCV(alt) | 24 / 71 | 2 |
顔検出の実装は、OpenCVを使うのと大分シンプルに実装できるのだが、精度を比較して見たらCloud Vision APIが圧倒的に良かったため、Cloud Vision APIを利用することにした。
集めた全身画像を別のディレクトリにコピーする。そして、一枚ずつCloud Vision APIで顔検出を行い、顔周辺をクロップして保存していく。なお、出力された顔のBounding Boxから上下左右に20%ほどマージンをもたせてクロップしている。これは、キャラクターの特徴を表す髪や服装といった要素をなるべく含めるようにしたいからだ。
Cloud Vision APIで検出に失敗した画像に関しては、仕方がないので手動で顔周辺をクロップしていく。
- faces
- 000_kaban
- image1.jpeg
- image2.jpeg
- ...
- 001_serval
- 002_arai
- ...
- 000_kaban
なお、順番が前後してしまうが、Google Cloud Vision APIを使った顔検出と、検出した顔の周辺をクロップする方法についてはTensorFlow + Kerasでフレンズ識別する - その4: 顔周辺の切り出し編に簡単に記述した。
前処理(リサイズ)をしておく
顔周辺をクロップしたデータを、全て128px * 128pxにリサイズしておく。KerasのImageDataGeneratorの機能で、入力時にリサイズをしてくれるというものがあるのだが、あらかじめリサイズしておいた方が読み込みのスピードが上がって、学習の処理が速くなる。特に元画像が不要に大きい場合は結構パフォーマンスに影響があったので、あらかじめリサイズしておくのがおすすめ。
Python内で完結したい場合はPillowを使って簡単に実装できるが、ImageMagickを使った方が楽かも。
学習データとテストデータに分ける
最後に、集めたサンプルを学習用データとテストデータ(検証データ)に分ける。とりあえず学習データ:テストデータ=5:1の割合になるように、ランダムに画像を分類させた。
KerasのImageDataGeneratorで読み込ませるため、その形に合わせたフォルダ構成にする。
- data
- train
- 000_kaban
- image1.jpeg
- image2.jpeg
- ...
- 001_serval
- 002_arai
- ...
- 000_kaban
- test
- 000_kaban
- image3.jpeg
- ...
- 001_serval
- ...
- 000_kaban
- train
準備完了
なんだかんだで、手作業の泥臭い作業が非常に多く苦労したが、学習データの準備は完了。
顔周辺クロップやリサイズ、学習データ・テストデータ分類などは、割と汎用的に使えそうな処理なので、後でツール化しておこうと思う。
とりあえず、次はこのデータを使って学習させていく。