サーバー上のアクセルログを毎日zip化してs3に投げてます。(アクセスログ以外、いくつ他のファイルも同じzipファイルに保存されます。)
普段このアクセルログを使わないので、それでも問題ないですが、3月一度このアクセルログに対して履歴分析を行います。
zip化されたので、直接分析できないです。毎回s3からzipファイルをs3からダウンロードして、ローカルで解凍して、必要なファイルだけを洗い出し、またs3にアップロードします。結構時間かかりますね…
なので、今回Lambdaを使ってzipファイルの一括処理を行いました。
アクセル権限
Lambda関数を作成時、実行ロールが聞かされます。

プロジェクトに既に適切なロールがありますので、それを使いました。
もし、まだ使えるロールがない場合、「AWS ポリシーテンプレートから新しいロールを作成」を使ってください。例え:
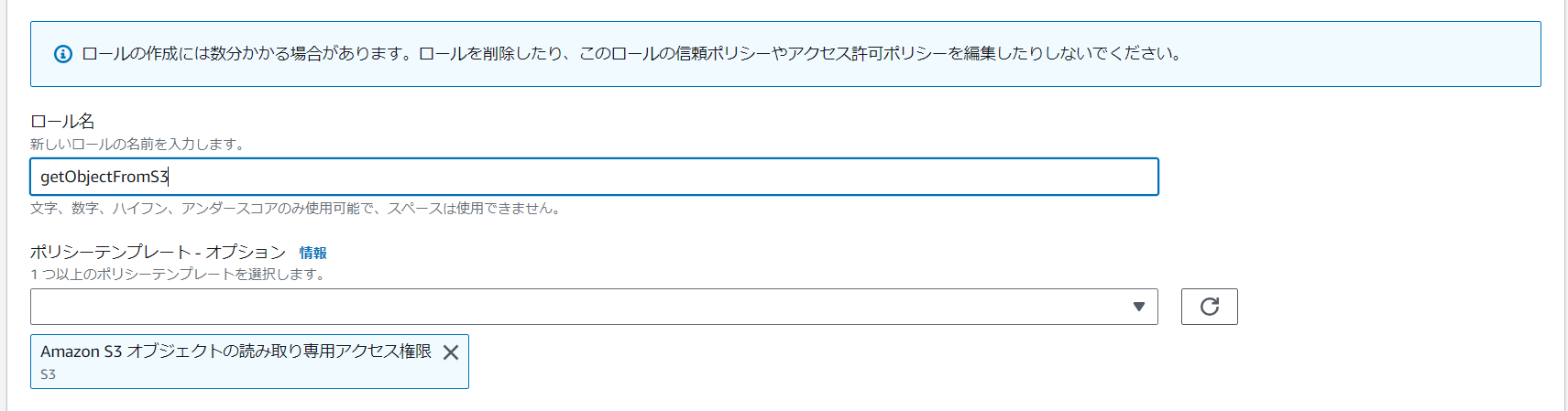
※画像の場合、ファイルの取得が可能ですが、S3にアップロードができないです。
もし新しいロールを作成したいなら、以下画像を参考してください。
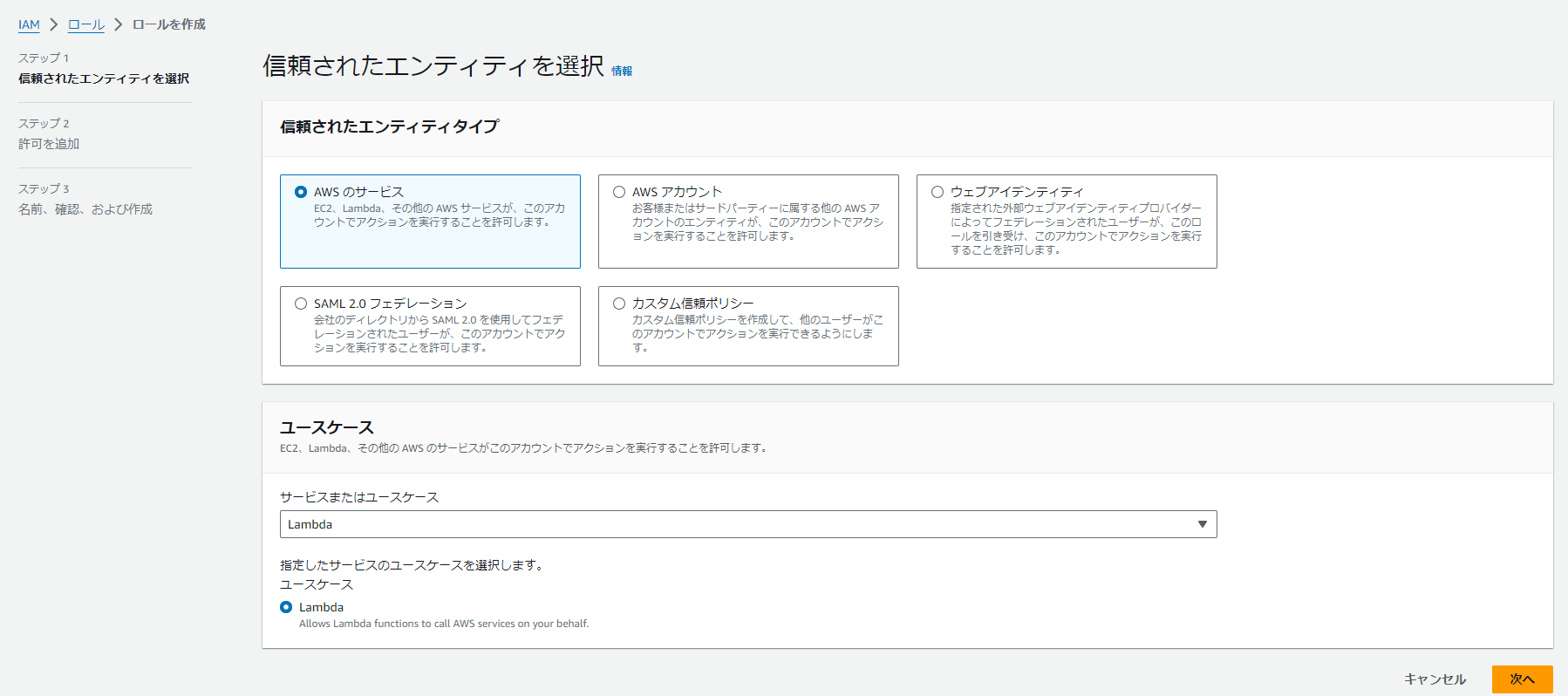
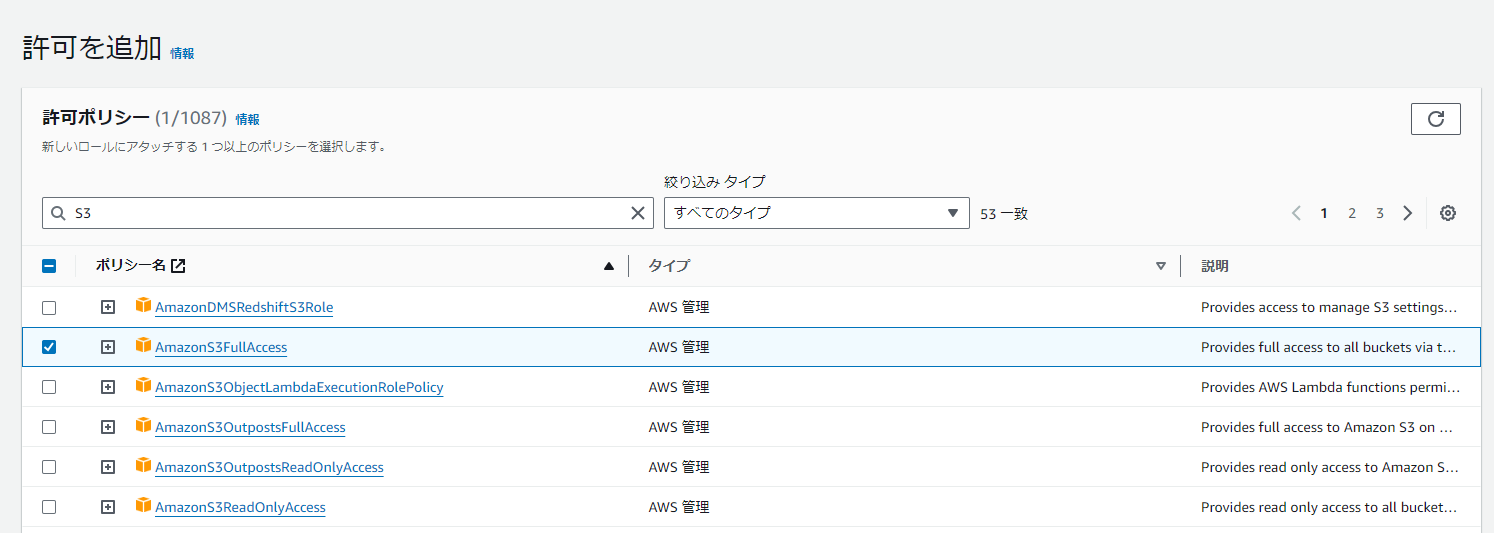
使う言語と一般設定
今回はpython3.11を使います。
一般設定のタイムアウトを少し上げる方がおすすめです。(じゃないとタイムアウトで実行できないです。Lambdaは実行回数と時間で課金しますが、ここの数値を上げても別に料金が高くなることないと思います。)

import s3
以下記事を参考しました。
https://dev.classmethod.jp/articles/lambda-s3/
https://qiita.com/kazama1209/items/0c51c8f25f735719f6a1
今回s3に関する操作は以下です:
①s3から作業対象の情報を定義しているcsvファイルを読み込み
csvファイルの第一列にはzipファイルの名前、第二列はzipから洗い出したいファイルの名前です。
②s3からzipファイルを取得します。
③s3にログファイルをアップロードします。
import s3
import csv
import boto3
import os
# 一時的な読み書き用ファイル(後で消す)
tmp_csv = '/tmp/test.csv'.format(ts=timestamp)
s3 = boto3.client('s3')
#bucket_nameとkey_nameを環境変数から取得の処理が必要です
def lambda_handler(event, context):
s3_object = s3.get_object(Bucket=bucket_name, Key=key_name)
data = s3_object['Body'].read()
contents = data.decode('utf-8')
try:
with open(tmp_csv, 'a') as csv_data:
csv_data.write(contents)
with open(tmp_csv) as csv_data:
csv_reader = csv.reader(csv_data)
for csv_row in csv_reader:
#defoldderに具体的な処理を行う
defolder(csv_row)
os.remove(tmp_csv)
except Exception as e:
print(e)
raise e
defolde関数の中、csvファイルの一行から作業zipと取得したいlogファイルを読み込みして
logファイルをs3の特定フォルダにアップロードします。
参考記事:https://qiita.com/goosys/items/11f5042e047a9b00eeb9
Lambdaでのzip操作
import zipfile
import urllib.parse
def defolder(csv_data)
zipFileName=csv_data[0]
uploadFileName=csv_data[0]
FileListInZip = []
Object = urllib.parse.unquote_plus(event['detail']['object']['key'], encoding='utf-8')
Bucket = urllib.parse.unquote_plus(event['detail']['bucket']['name'], encoding='utf-8')
FilePath = '/tmp/' + Object
#/tmp/配下保存
s3.download_file(Bucket, Object, FilePath)
#zipファイル内一覧取得
zfile = zipfile.ZipFile(FilePath)
FileListInZip = zfile.namelist()
#/tmp/配下展開
zfile.extractall('/tmp/')
zfile.close()
#展開したファイルをS3アップロード
for f in FileListInZip:
try:
if os.path.isfile('/tmp/' + f):
s3.upload_file('/tmp/'+f, Bucket, f)
except Exception as e:
print(e)
pass
else:
pass
#Lambda /tmp/配下削除
for p in glob.glob('/tmp/' + '*'):
if os.path.isfile(p):
os.remove(p)
return 0
完成品のgithub
注意:
プロジェクトの情報を漏れないように、環境変数を使ってます。
環境変数はLambdaの「設定」画面で定義できます。
関数中keyを読み込みして、valueを取得できます。