はじめに
最近ほとんど使っていなかった自作デスクトップPCに、NVIDIA製のGPU(GeForce GTX960)が入っているのを思い出し、折角なのでこれを活用してDeep Learningが出来る環境を構築してみようと思いやってみました。
5年前に購入したGPUにも関わらず、処理速度が段違いに速くGPUの素晴らしさに驚きました(笑)
msi GeForce GTX960 Gaming 2G MGSV
環境
- Windows 10 Pro (Version 1909)
- Python 3.6.4 (Anaconda3 5.1.0)
必要なもの
- NVIDIA製のGPU
- Tensorflow-gpu
- Keras
- Microsoft Visual Studio C++ (MSVC)
- NVIDIA Driver
- CUDA
- cuDNN
バージョン確認
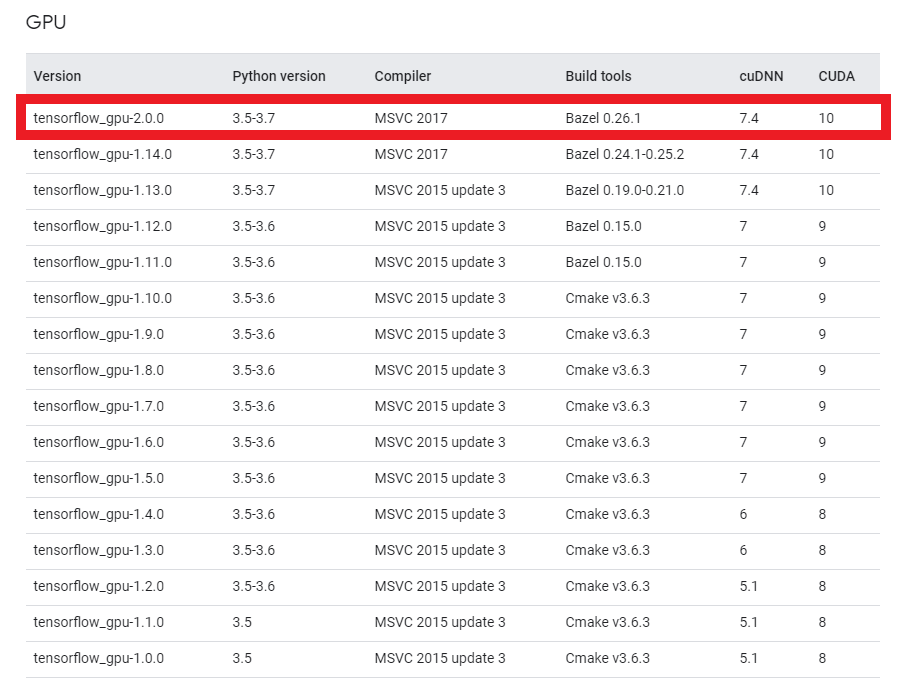
GPU環境でTensorflow/Kerasを使用するには、上記必要なものをそれぞれ対応するバージョンで合わせなければなりません。
Tensorflowのサイトにマッチングテーブルがありますので、必ず確認して下さい。
基本的には、Tensorflowのバージョンに合わせてそれぞれ対応するバージョンをインストールすれば良いと思います。
何か理由があってバージョン指定がなければ最新でOKです。
投稿時点(2020/03/21)では2.0.0が最新なので、2.0.0で構築します。
Conda環境作成&Tensorflow-gpuインストール
TensorflowのCPU版とGPU版が混在していると、CPU版が自動的に選択されるみたいなので新しく環境を作ります。
> conda create -n tf200gpu Python=3.6.4
作成完了したら、環境を有効化してTensorflow-gpuをインストールします。
> conda activate tf200gpu
(tf200gpu)> pip install tensorflow-gpu==2.0.0
↓このエラーが出る場合は以下記事を参照
ERROR: cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
インストール完了したら、pip listで以下内容を確認して下さい。
(この段階でPythonでimport tensorflowを実行しても、CUDA/cuDNNが入っていないのでエラーになります)
- CPU版Tensorflowがインストールされていないか?
- Tensorflow-gpuがインストールされていて、バージョンは2.0.0か?
Kerasのインストール
Kerasは特に問題無くインストール出来ると思います。僕の環境ではバージョン2.3.1が入りました。
(tf200gpu)> pip install keras
Tensorflow同様、pip listでインストールが出来ているか確認して下さい。
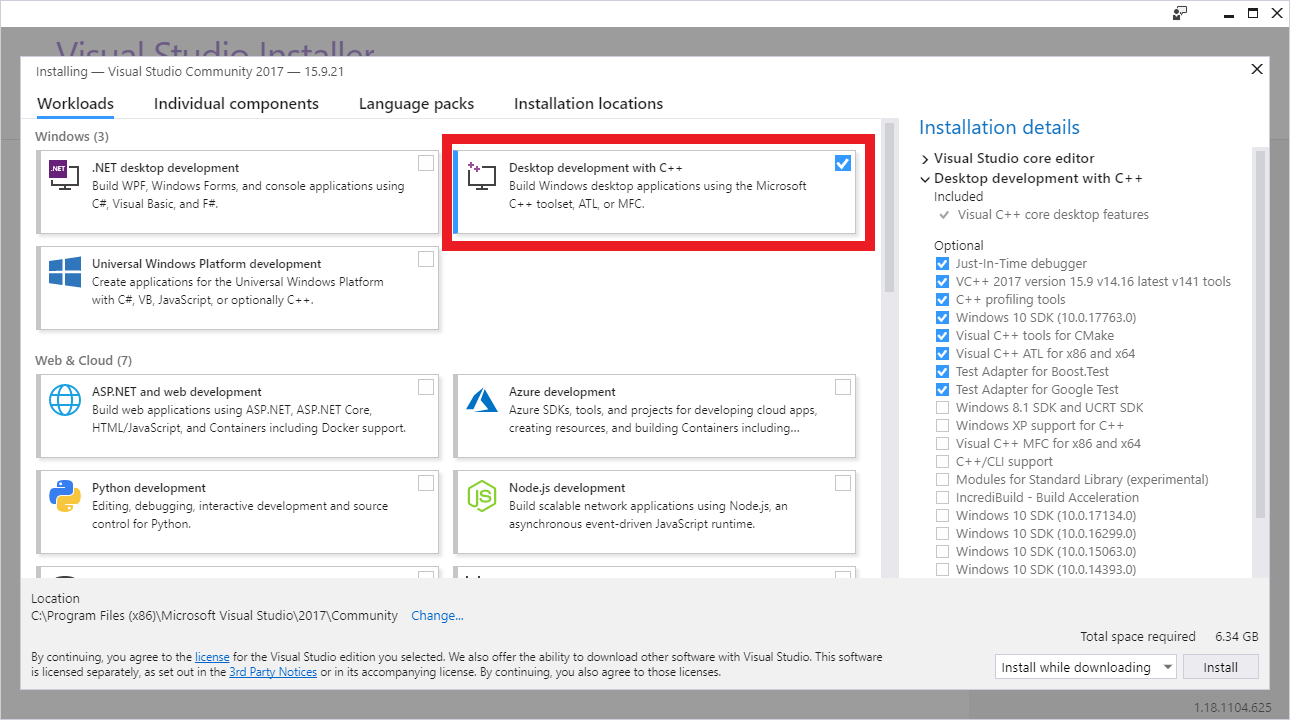
Visual Studio C++2017のインストール
TensorflowのバージョンとマッチしたVisual StudioをMicrosoftのダウンロードサイトから入手してインストールします。
今回は2017になりますので、Visual Studio Community 2017をインストール。
インストール時に「C++ ワークロードを使用したデスクトップ開発」にチェックを入れて下さい。
(結構時間かかる…)
NVIDIA Driverのインストール
NVIDIAのダウンロードサイトから、製品を選択してインストーラを入手。他のグラフィックボードの場合は、適宜変えて下さい。

特別なことは何もせず、「次に」を押し続けていれば問題無くインストール完了するはずです。
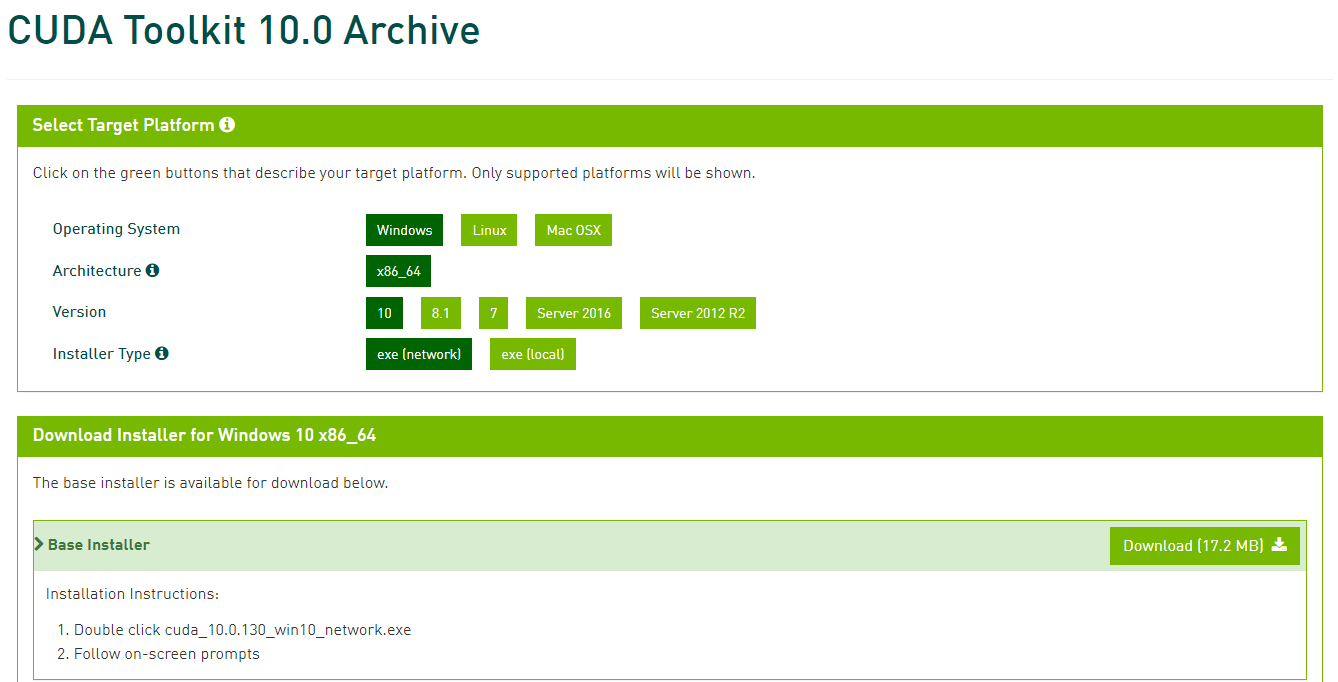
CUDAのインストール
CUDAはNVIDIAが開発・提供している、GPU向けの汎用並列コンピューティングプラットフォームです。
CUDA Toolkitのダウンロードサイトからインストーラを入手してインストールします。
インストーラを入手するのに無料アカウントの作成が必要なので、ちゃちゃっと作ります。
今回はCUDA Toolkit 10.0をインストールします。OSの種類やバージョンを選んで、exe(network)を選択します。
(ネット接続出来ないPCにインストールする場合はlocalを選んで下さい)
ダウンロードが終わったら、インストーラを起動し、Driver同様に「次に」を押し続ければインストール出来ます。
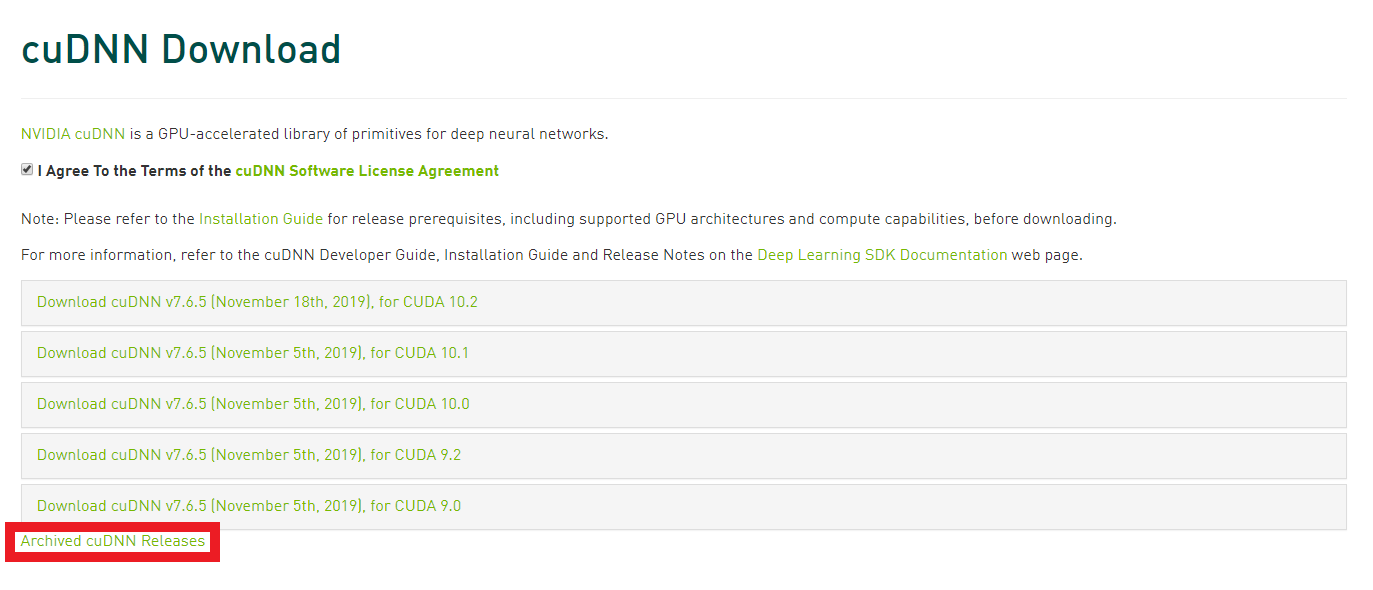
cuDNNのインストール
続いてNVIDAが公開するDeep Learning用のライブラリであるcuDNNをインストールします。
こちらもアカウントが必要になりますので、CUDAの時に作ったアカウントでログインして下さい。
今回は、7.4.2 for CUDA 10をcuDNNのダウンロードサイトから入手します。
「I Agree To the Terms of the cuDNN Software License Agreement」にチェックを入れると、いくつか選択肢が出てきます。この中に欲しいバージョンが無ければ、赤枠の「Archived cuDNN Releases」をクリックすれば過去のリリースが出てきます。
ダウンロードしたzipを解凍すると、bin、include、libの3つのフォルダと、NVIDIA_SLA_cuDNN_Support.txtというテキストファイルがあると思います。
Windows ExplorerでC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v.10.0を開き、そこにも同様にbin、include、libのフォルダが存在しますので、ダウンロードしたフォルダの中身をそれぞれ同じ名前のフォルダ内にコピペすることでインストール完了です。
管理者権限を求められることがありますので、許可してあげて下さい。
GPUが認識されているか確認
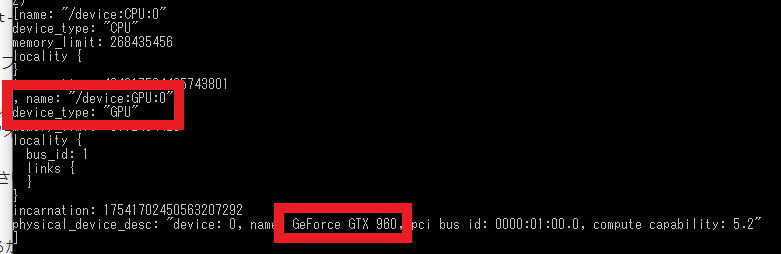
以上でインストール系は完了です。GPUがちゃんと認識されているかを確認するためにコマンドプロンプトで以下を実行してみます。
(tf200gpu)> python -c "from tensorflow.python.client import device_lib;print(device_lib.list_local_devices())"
ちゃんと認識されている…!!
いざ実行!
では早速Tensorflow-gpuを使って学習させてみる…も以下エラーに阻まれた。
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
こちらの記事を参考にしたところ、cudatooklitもcudnnもcondaのlistに出てこない…
ので、conda install cudnnしてみたら候補が出てきたので、インストールしてみる。
ちなみに、conda install cudnnで、cudatoolkitもcudnnもインストール出来るみたいです。
上記でインストールしたの:
- cudatoolkit 10.2.89
- cudnn 7.6.5
再度学習のコードを実行してみたら、GPUで問題無く動作するようになりました!!
CUDAとcuDNNは2回インストールしているので、これが正しい方法かはわかりませんが(しかもバージョン違うし)とりあえずは動いているので良しとします(笑)
今後何か問題が出たり、正しい方法がわかったら記事更新します!
(詳しい方、コメントで教えて下さい~(´;ω;`))
結果
某オンライン研修プログラムで作った以下学習用のPythonコードで測定してみます。
入力された画像をCNNを用いて3つのクラスに分類する画像認識プログラムの学習コードです。
学習用の画像データは、事前に.npy形式で保存してあるものをロードします。
50×50ピクセルの画像を157枚(中途半端)、バッチサイズ32、エポック100で学習させてみたところ…
| Processor | Time |
|---|---|
| CPU | 0:01:22.239975 |
| GPU | 0:00:15.542190 |
| GPUの方が約5.4倍速いですね。 | |
| (ちなみに搭載CPUはIntel Core i5-6600K @ 3.5GHzです) |
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import numpy as np
import datetime
classes = ["class1", "class2", "class3"]
num_classes = len(classes)
image_size = 50
def main():
X_train, X_test, y_train, y_test = np.load("./data.npy", allow_pickle=True)
X_train = X_train.astype("float") / 256
X_test = X_test.astype("float") / 256
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
model = model_train(X_train, y_train)
model_eval(model, X_test, y_test)
def model_train(X, y):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=X.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(3))
model.add(Activation('softmax'))
opt = keras.optimizers.adam(lr=0.0001, decay=1e-6)
model.compile(
loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy']
)
model.fit(X, y, batch_size=32, epochs=100)
return model
def model_eval(model, X, y):
scores = model.evaluate(X, y, verbose=1)
print('Test Loss: ', scores[0])
print('Test Accuracy: ', scores[1])
if __name__ == "__main__":
start_time = datetime.datetime.now()
main()
end_time = datetime.datetime.now()
print("Time: " + str(end_time - start_time))