畳み込みニューラルネットワークでMNISTの手書き数字の分類問題をやろうとしたらエラーが出てちょっとハマったのでメモ。
以下、コード抜粋
# CNNモデルアーキテクチャ
model = models.Sequential()
model.add(
layers.Conv2D(
32,
(3, 3),
activation='relu',
input_shape=(28, 28, 1)
)
)
model.add(layers.MaxPool2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPool2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 1次テンソルへ変換
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# modelに訓練データをバインド
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics = ['accuracy']
)
# 訓練の実施
model.fit(train_images, train_labels, epochs=5, batch_size=64)
で実行したところ以下のエラーが出て前に進まない。
どうやらCNNの初期化に失敗してるらしい。
UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node conv2d_1/convolution}} = Conv2D[T=DT_FLOAT, _class=["loc:@training/RMSprop/gradients/conv2d_1/convolution_grad/Conv2DBackpropFilter"], data_format="NCHW", dilations=[1, 1, 1, 1], padding="VALID", strides=[1, 1, 1, 1], use_cudnn_on_gpu=true, _device="/job:localhost/replica:0/task:0/device:GPU:0"](training/RMSprop/gradients/conv2d_1/convolution_grad/Conv2DBackpropFilter-0-TransposeNHWCToNCHW-LayoutOptimizer, conv2d_1/kernel/read)]]
ググってみると、[Build from source on Windows] (https://www.tensorflow.org/install/source_windows#gpu)を確認しろとのこと。
TensorFlowをソースからビルドする手順が書いてある。
そしてページの下のほうを見るとこんな表があると思います。
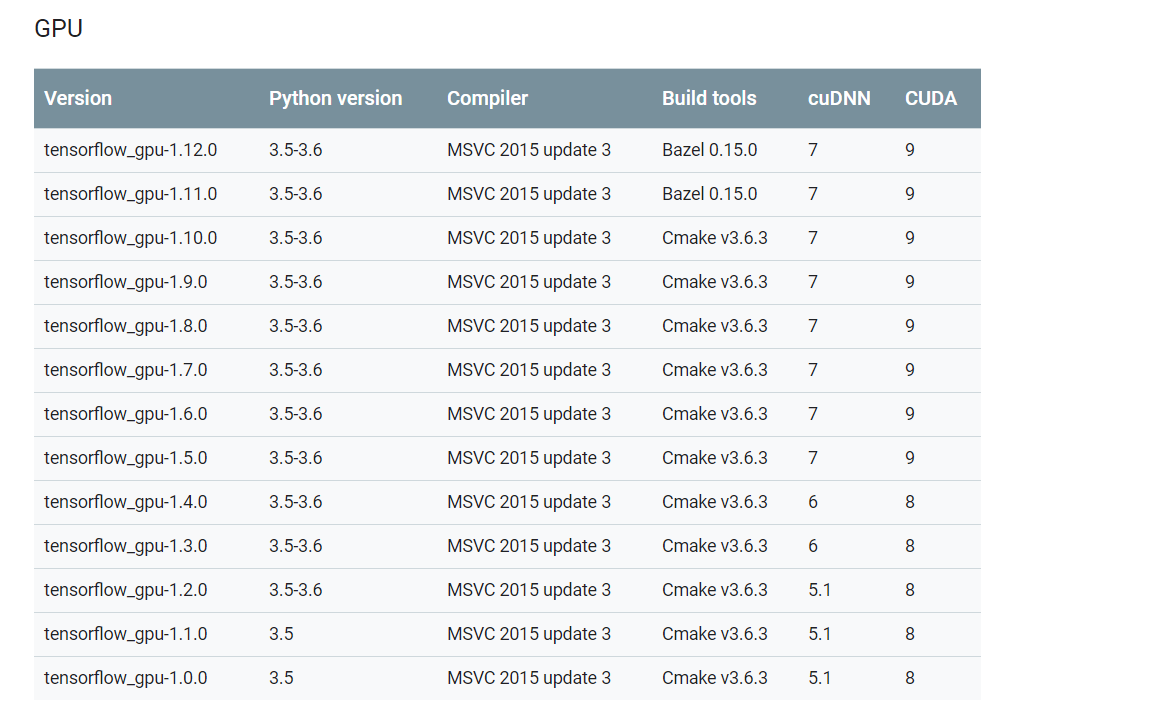
これはTensorFlow、Python、cuDNN、CUDAのバージョン対応表で、バージョンがあってないとうまくいかないとのこと。
環境構築あるあるですね。
というわけでバージョンチェック
まずは、pythonとTensorFlow-GPU
> python --version
Python 3.6.4 :: Anaconda custom (64-bit)
# 修正 tensorflow=1.8.0, tensorflow-gpu=1.12.0じゃないと動かないことが判明
> conda list tensorflow
# Name Version Build Channel
tensorflow 1.8.0 0
tensorflow-base 1.8.0 py36h1a1b453_0
tensorflow-gpu 1.12.0 pypi_0 pypi
python - TensorFlowのバージョンは問題なさそう。
annaconda3を導入している場合、バージョン指定してのインストールは下記の通りです。
conda install python=3.6
# 今のところビルドバージョンは関係ないっぽい3.6.4でも3.6.8でも動くっぽいです
# python3.7.* はNGです
conda install tensorflow=1.8.0
conda install tensorflow-gpu=1.12.0
次にCUDAのバージョンを確認。
下記のコマンドでcudaのバージョンをチェック「Cuda compilation tools, release 9.0, V9.0.176」
> nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:32_Central_Daylight_Time_2017
Cuda compilation tools, release 9.0, V9.0.176
ちなみにannacondaを導入してる人はこれでも確認できる
こっちのほうが見やすい
> conda list cudatoolkit
# Name Version Build Channel
cudatoolkit 9.0 1
CUDAのバージョンも問題ない。
ということは問題はcuDNNか?
そうであってほしい。。。
環境構築で一番ハマるのは原因が特定できない時だ。
だから問題が特定できたほうがありがたい。
というわけでcuDNNのバージョンを確認。
これもやっぱりannacondaを導入してる人はこれで確認できる。
> conda list cudnn
# Name Version Build Channel
入ってなかった!
原因はこれか!
というわけでcudnnを導入します。
cudnn導入手順を簡単に紹介
- ダウンロードは[NVIDIA cuDNN] (https://developer.nvidia.com/cudnn)ページからWindows10の場合はzip版をダウンロード。
- zipファイルを解凍し適当な場所に配置
minaraiの場合
(C:直下にtoolsディレクトリを作成)
2-1. cd C:\
2-2. mkdir tools
2-3. 解凍したファイルの中のcudaディレクトリを「C:\tools」に放り込む
(パスを通す)
2-4. システム > システム情報 > システムの詳細設定 > 環境変数 > 「path」の編集で「C:\tools\cuda\bin」を追加 - もう一度、cuDNNのバージョンを確認してみる
> conda list cudnn
# Name Version Build Channel
cudnn 7.3.1 cuda9.0_0
無事、認識されていることが確認できました。
最後にspyder(Jupyter Notebook)を再起動してプログラムを実行したら無事動きました!
> model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics = ['accuracy']
)
> model.fit(train_images, train_labels, epochs=5, batch_size=64)
Epoch 1/5
60000/60000 [==============================] - 7s 113us/step - loss: 0.1725 - acc: 0.9462
Epoch 2/5
60000/60000 [==============================] - 6s 106us/step - loss: 0.0486 - acc: 0.9850
Epoch 3/5
60000/60000 [==============================] - 6s 105us/step - loss: 0.0345 - acc: 0.9893
Epoch 4/5
60000/60000 [==============================] - 6s 107us/step - loss: 0.0249 - acc: 0.9922
Epoch 5/5
60000/60000 [==============================] - 6s 106us/step - loss: 0.0195 - acc: 0.9941
めでたしめでたし!
後日談
後日、何気なく conda install tensorflowをしたら、何だがまたエラーがを吐くようになってしまった。
どうやらtensorflowのバージョンを1.12.0に上げたのが原因だったみたいでtensorflow=1.8.0, tensorflow-gpu=1.12.0じゃないと動かないことが判明しました。
後々になってわかったことだけど、どうやらGPUが認識されてなかったようで通常版のTensorFlowが利用されていたっぽい。
今になって思うと、TensorFlow1.8.0を入れないとエラーになっていたのも通常版のTensorFlowのバージョンが何かのライブラリと相性があってなかったのだろう。
上記については試行錯誤してわかったこと言うより動くようになったという事実を持って推察しているまでなので確実とは言えないけど自分用のためにメモっておきます。
要約
自分の環境(Win10 + Annaconda)の場合、TensorFlowがあると通常版を利用しようとします。
なので、通常版のTensorFlowをアンインストールしました。
だけど、TensorFlow-gpuだけだとTensorFlowライブラリの読み込みエラーになってしまいます。
ん?どうしたらいいの?ってなってたんだけど。。。
TensorFlow-Baseが入ってればいいんじゃね?って思ってやってみたら正解でした。
> conda list tensorflow
# Name Version Build Channel
tensorflow 1.8.0 0
tensorflow-base 1.8.0 py36h1a1b453_0
tensorflow-gpu 1.12.0 pypi_0 pypi
このように3つ出てる状態がまずかったみたいです。
なので、tensorflow通常版だけを削除してあげてら上手くうごきました。
GPUが認識されるようになるまでの道のり
- Python, TensorFlow-gpu、CUDA, CuDNNはキチンと(互換バージョン)が入っている前提です。
1 TensorFlow(通常版)をアンインストール
pip uninstall tensorflow
# または
conda uninstall tensorflow
2 TensorFlow-baseをインストール
conda install tensorflow-base
3 確認
>>> python
>>> from tensorflow.python.client import device_lib
>>> device_lib.list_local_devices()
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 17389511133406422280, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 3163724185
locality {
bus_id: 1
links {
}
}
incarnation: 9818280376550559816
physical_device_desc: "device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0, compute capability: 6.1"]