ご注文はYOLOv3ですか?
- 前回の記事で,YOLOを用いてみたわけですが、最近YOLOv3というさらに精度がよく、処理速度も速いとうわさがあったので、YOLOv3を用いて再度チャレンジ
- また、今回も心を癒されるためにごちうさを学習していきますよ~あぁ^~心がぴょんぴょんするんじゃぁ^~
使用環境
- Windows10
- CPU: Intel Core i7-8700K @ 3.70GHz
- RAM: 32GB
- NDIVIA Geforce GTX1080Ti(11GB)
YOLOv3の入手と環境構築
- Windows版のYOLOはここからダウンロードできます。
- 環境は、先ほどのサイトにもありますが私は以下のようにしました。
- OpenCV3.0
- CUDA9.1
- cuDNN v7
- python3(Anaconda)
- 環境構築できれば、[darknet.sln]を起動して、[Release]モードでビルドするだけ
- プログラムに少し細工をします
-
出力フォルダ
- プログラムを走らせた後に、weightファイルを出力するフォルダがないというエラーが出てきますので、フォルダを自動で生成するように以下のコードを追加
- 「detector.c」の「void train_detector(char *datacfg, char *cfgfile, char *weightfile, int *gpus, int ngpus, int clear, int dont_show)」関数の中の「char *backup_directory = option_find_str(options, "backup", "/backup/");」の後に「_mkdir(backup_directory);」を追加する。
-
weightファイルについて
- [detector.c]ファイルの180~182行目当たりのif文を変更するとweightファイルの書き出し方が変更になります。
- 自分は「if(i >= (iter_save + 100))」となっており、100エポック毎に出力されていました。
- ご自由に書き換えてください。
-
学習(Training)
- 学習の手順は前回の記事同様です。
- アノテーション
- 画像増幅
- 学習
-今回使用したプログラム(後日UP)
アノテーション
- 前回はBBox-Label-Tool.pyを用いて1つずつアノテーションしていましたが、今回は少し変更してみました。
- 今回もごちうさ(アニメ画像)を対象としていることと、YOLOで必要なアノテーションが「個数,x座標(始点),y座標(始点),x座標(終点),y座標(終点)」なので、cascadeの顔検出を用いることにしました。
- アニメのcascadeはここにありますので、ここから「lbpcascade_animeface.xml」を拝借します。
- とりあえず、検出された画像ごとに、キーボードを打つようにします。
//顔検出
vector<cv::Rect> faces;
cascade.detectMultiScale(image, faces, 1.1, 3, 0, cv::Size(20, 20));
//顔検出
vector<int> face_cnt(label);
vector<vector<cv::Rect>> face_rect(label);
//初期化
for (int i = 0; i < face_cnt.size(); ++i)
face_cnt[i] = 0;
//検出結果を表示
cv::Mat f = image.clone();
for (int i = 0; i < faces.size(); ++i)
{
cv::rectangle(f, faces[i], cv::Scalar(0, 0, 255), 2);
}
//すべての画像を見やすくするためにサイズ変換(元の画像はいじらない)
cv::resize(f, f, cv::Size(320, 240));
cv::imshow("IMAGE", f);
//検出された顔画像だけ処理をする
for (int i = 0; i < faces.size(); ++i)
{
cv::Mat res;
res = image(faces[i]);
//検出された画像を表示する
cv::imshow("ROI", res);
char key = cv::waitKey(0);
//画像のIDをつける。
//スペースキー:なし、1,2,...,9,a,b,...,z
int no = ChartoInt(key);
printf("no -- %2d\n", no);
if (no >= 0)
{
//ID毎に保存する
face_cnt[no]++;
face_rect[no].push_back(faces[i]);
}
cv::destroyWindow("ROI");
}
- 例えば今回の場合は次のようにしました。
- チノ
- リゼ
- ココア
- シャロ
- チア
- マヤ
- めぐ
- モカさん
- 青山さん
- 他(お父さんなど)
その後、間違えた場合や少し四角形がおかしい場合「BBox-Label-Tool.py」にて修正を行います。
- この時点でのフォルダ構成
Trains(元のフォルダ)
|-tools(BBox-Label-Tool.py、convert.pyなど)
|-gochiusa(今回作成するフォルダ)
|-Images(プログラムで作成されているはず)
| |-クラス数だけフォルダがある
|
|-Label(プログラムで作成されているはず)
|-クラス数だけフォルダがある
増幅+YOLOの形式に変更
- 画像の増幅は前回と同じ「inflate_images.py」を起動します。これは、前回と同じ
inflate_images.py [フォルダ名]
- 今回の場合は
inflate_images.py gochiusa
- YOLOv3の形式に変更
- これは、前回のコードではいくつか修正する必要(主にfilterの計算部分)があったので、修正しました。
convert_v3.py [フォルダ名]
- 今回の場合は
convert_v3.py gochiusa
※前回と同様ですが、inflated_imageで出力フォルダをして指定ない場合で、学習数の比率を変更したい場合は、「obj」と入力
学習数の比率は指定しない場合は「学習数:テスト数=1:1」となります(学習画像とテスト画像が同じ)。学習数の比率は0.1~0.9の間で指定してください。
今回は何も指定していません。
学習
-
学習するために「darknet53.conv.74」をダウンロードしてきます。
- ここからダウンロードできます。
-
学習は基本、YOLOv2と同じですが、もう一度書いておきます。
-
これを、darknetの実行するフォルダに持っていきます。訓練のコマンドは以下の通りです。
.\darknet.exe detector train [dataファイル] [cfgファイル] .\darknet53.conv.74
今回の場合は
.\darknet.exe detector train .\gochiusa\config\learning.data .\gochiusa\config\learning.cfg .\darknet53.conv.74
となります。とりあえず10000回まわします。
あとは、実行が終わるのを待つだけ。。。
もし、もっと回したい、減らしたいという人は15行目のmax_batches = 10000を変更してください。
-
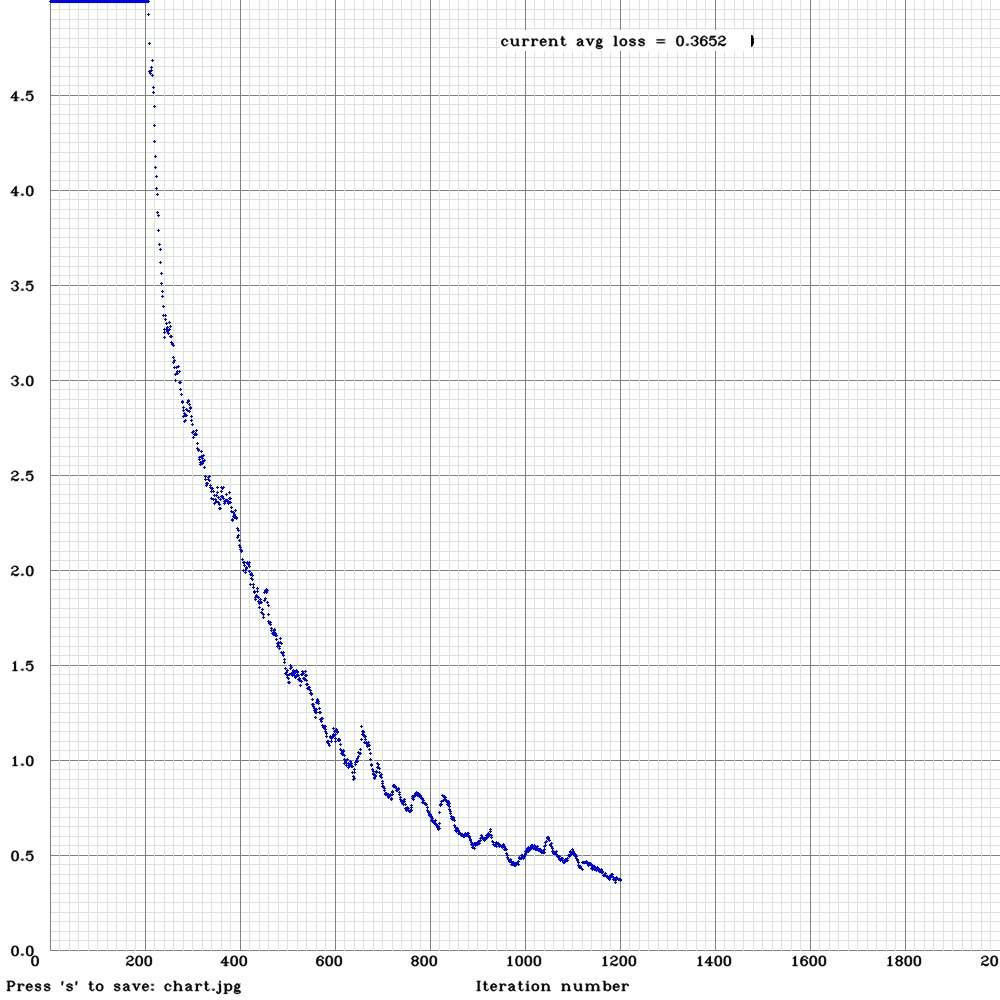
なんと、今回から処理中のグラフが表示されるようになっています(すばらしい!!)
-
途中で学習が悪いと思えば視覚的にやめることができるのはいいですね。
-
しかし、sキーを押したときだけ画像が出力ということらしいので、できればweightファイルと同じ時に出力がしたいと思ったので、detector.cを少し書き換えました。
-
さきほど紹介したweightファイルを書き込む部分(180~182行目あたりのif文)の中の「save_weights(net, buff);」の下にコードを追加
char bufcv[256];
sprintf(bufcv, "%s/chart_%d.jpg", backup_directory, i);
cvSaveImage(bufcv, img, 0);
結果
- 10,000回学習した結果になります。グラフで見ると1,000回に至る段階で急激にエラー率が落ちていますね。
- とりあえず、100回、1,000回、5,000回、10,000回の結果を表示します。!
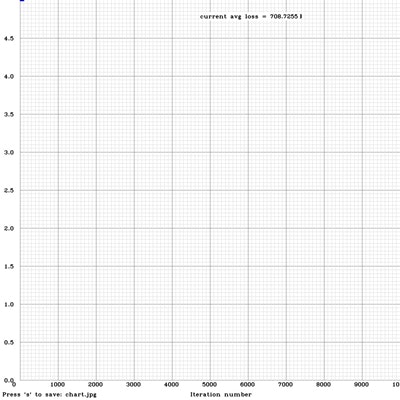
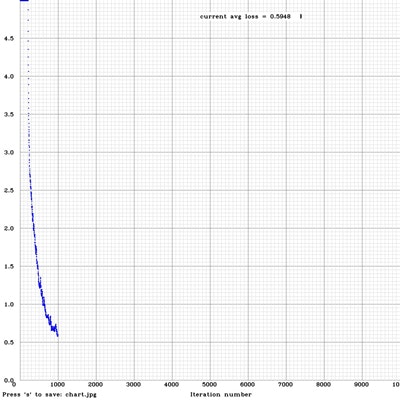
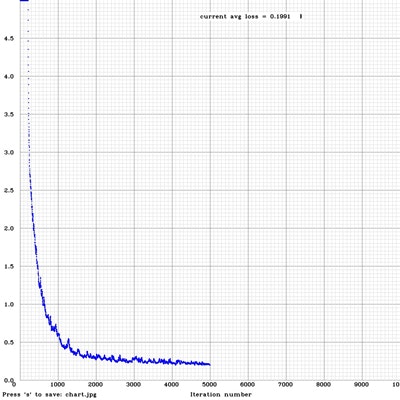
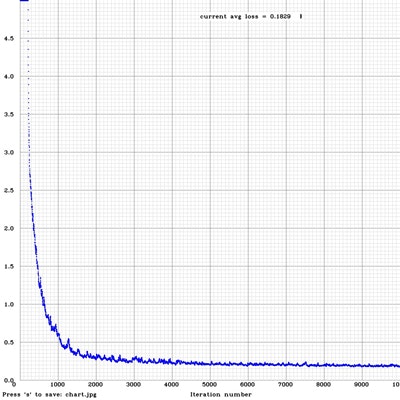
-
まずは、前回と同じ画像を入力してみます。


-
あれっ、YOLOv2よりも精度が悪い・・・
-
今回はイラスト系の画像は一切なく、アニメから抜粋した画像だったから・・・??
-
とりあえず、学習ができていないかったのか・・・・????
-
一応、前回と同様でOPで試してみました。
ご注文はYOLOv3ですか!? -
なんと、そこそこ検出できているではないですか?静止画だと悪いのはなぜ?
-
もしかして、YOLOv3のアノテーションの形式がv2とは違う?ってことはないと思うのですが。。。イラスト系も入れて再度学習してみてもいいかもですね。
-
ついでに、10,000回のイテレーションに約10時間程度でした。
-
今回は、ココアちゃんとモカさんが識別できているので良しとしますか。
-
引用先