追記項目
2017.11.25 -- inflated_image.pyを使用する際にフォルダの名前を書き換える必要があったので、追記しました。
はじめに
WindowsでYOLOを使う記事がいくつかあったのですが、自分なりにまとめておきたいと思ったのとQiitaに書く練習がてら記事として書いてみました。
題材としては、2017/11/11に公開された「ご注文はうさぎですか!?」を題材として使ってみることにしました(映画の画像じゃないよ)。画像はkoi先生のイラスト、第1期、第2期から適当に拝借。普通の題材でもよかったのですが、ごちうさでやっていれば心もぴょんぴょんしてきて、モチベ的に苦にならないので。ただ、何番煎じでしょうかね。
ごちうさと機械学習的なものはここが結構有名ですね(ご注文は機械学習ですか・ご注文はDeep Learningですか?)
プログラム
GitHubにYOLOで使われるプログラムを少し書き直したものを置いておきました。使用する場合は自己責任で。
※darknet.exeがありますが、各自の環境でビルドすることをオススメします。
Tool → yolo learning tools
※それぞれのプログラムのもとはこれ
BBox-Label-Tool
increase_picture
動作環境
Windows 10 Home Edition
GeForce GTX 1080Ti
core i7 7700K
Visual Studio 2015 Community
Anaconda 3 (Python 3)
CUDA 8.0
cudnn 5.1
下準備
工程として以下の工程があります。
- 画像を集める
- アノテーションする
- 画像を増やす
- YOLOで学習
- テスト
それぞれについて、簡単に解説していきます。基本的に必要なプログラムは各自でダウンロードしてください。
※必要なモノ
- Anaconda 3(Python 3)
- Visual Studio 2015
- CUDA ToolKit 8.0
- cudnn 5
darknetをダウンロードして、ビルド
YOLOのプログラムであるdarknetは →→→こちら←←←から取得します。
Visual Stduioは2015でしか試していないので最新版でできるかわかりません。
知っていてば教えていただければ。
2015に関しては、先ほどのサイトにISOファイルのリンクがあります。
darknetを動かす色々なツールなどのインストールは先ほどのサイトで。
取りあえず、ビルドが成功したということで話を進めていきます。
pythonにOpenCVをインストール
以下のコマンドでインストール
conda install opencv
「python」と入力して
>>>import cv2
と入力し、何もなければOK。
「Traceback (most recent call last):
File "", line 1, in
File "C:\Program Files\Anaconda3\lib\site-packages\cv2_init_.py", line 9, in
from .cv2 import *
ImportError: DLL load failed: 指定されたモジュールが見つかりません。
」
上記のエラーが出た場合は、Anacondaのインストールされているフォルダから「cv2」というフォルダを削除。
画像を集める
画像を集めるのは好きなように集めてくださいね。自分はGoogleやらで適当に集めました。のちにプログラムで1枚当たり18枚まで拡張するので、今回は各20種類(5キャラなので計100枚)ずつぐらい。
画像を格納するフォルダを適当に作成し、その中に画像は好きな順番に「001」「002」「003」・・・とフォルダを作成する。画像の名前は何でもいいが、できれば連番で統一しておくとよいかも。
※フリーソフトなどで簡単に名前を変更しておこう。
※画像は「.jpg(JPEG画像)」のみです。PNG画像などは「BBox-Label-Tool.py」の「127行目」を書き換えてください。
例)「test」フォルダを作成し、5キャラ「001」~「005」を「test」フォルダに作る。
test
|-001-chino_001.jpg~chino_020.jpg
|-002-rize001.jpg~rize020.jpg
|-003-cocoa_001.jpg~cocoa020.jpg
|-004-sharo_001.jpg~sharo_020.jpg
|-005-chia_001.jpg~chia_020.jpg
使用した画像の例





フォルダ内にclasses.txtを作成し、クラス名を記入する。
classes.txtにクラス名を記述。今回の場合は
・chino
・rize
・cocoa
・sharo
・chia
アノテーション(ここが一番つらい)
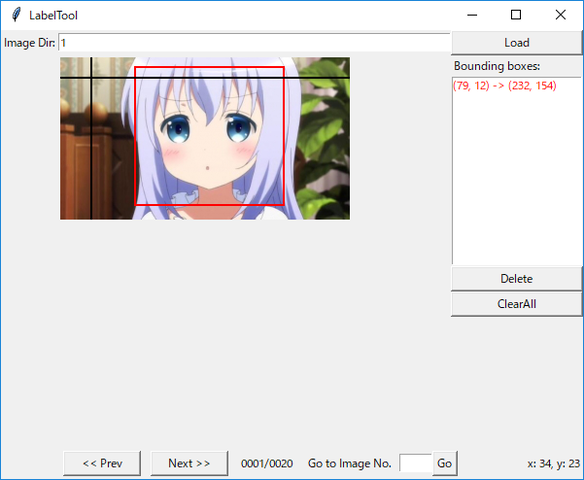
ダウンロードしたプログラム「BBox-Label-Tool.py」を起動する。コマンドプロンプトかWindows Shellにて
python BBox-Label-Tool.py [フォルダ名]
- 「Image Dir:」に番号(1~5)を記入すると画像を読み込む。
- 画像が表示されたらクリックして認識したいものを囲む
- 「Next」ボタンで次の画像を読み込む(この時に囲んだ座標は登録されるので必ず押すこと)
- ラベルデータを作成できればOK
画像の増幅
とりあえず、機械学習は画像が多ければ多いほどいいのよ。過学習になっちゃうとダメだけど、ひとまずは置いておいて。コマンドは以下の通り
python inflate_images.py [フォルダ名] [出力フォルダ(ない場合はobjフォルダが生成)]
[出力フォルダ(ない場合はobjフォルダが生成)]とinflated_labelsができていればOK
今回の場合は
python inflate_images.py test gochiusa
※出力フォルダには「image」という単語を含まないようにします。
※このとき、先ほど作成した「classes.txt」の中身と同じになるようにフォルダ名を書き換えます。今回の場合は「001」→「chino」、「002」→「rize」・・・。
ラベルの変換と設定ファイルの作成
アノテーションしたファイルを変換する必要があります。
また、認識するための設定ファイルを作成する必要があります。
次のコマンドで設定ファイルも作成することができます。
python convert.py [フォルダ名] [inflated_imageで出力フォルダを指定した名前] [学習数の比率]
今回の場合は
python convert.py test gochiusa
※inflated_imageで出力フォルダをして指定ない場合で、学習数の比率を変更したい場合は、「obj」と入力
学習数の比率は指定しない場合は「学習数:テスト数=1:1」となります(学習画像とテスト画像が同じ)。学習数の比率は0.1~0.9の間で指定してください。
今回は何も指定していません。
学習
先ほど作成したファイルで必要なのが、以下の2点です。
- 出力フォルダ(objもしくは自分で決めた名前)
- configフォルダ
これを、darknetの実行するフォルダに持っていきます。訓練のコマンドは以下の通りです。
.\darknet.exe detector train [dataファイル] [cfgファイル] .\darknet19_448.conv.23
今回の場合は
.\darknet.exe detector train .\test\config\learning.data .\test\config\learning.cfg .\darknet19_448.conv.23
となります。とりあえず10000回まわします。
あとは、実行が終わるのを待つだけ。。。
もし、もっと回したい、減らしたいという人は15行目のmax_batches = 10000を変更してください。
結果
学習について
1エポック当たり1.5[s]だったので,約4[h]くらいで学習は終わりました。
未知データについて(画像)
とりあえず、画像で試してみた。コマンドは以下の通り。
.\darknet.exe detector test [dataファイル] [cfgファイル] [weightファイル] -i 0
今回の場合は、
.\darknet.exe detector test .\test\config\learning.data .\test\config\learning.cfg .\backup_final.weights -i 0

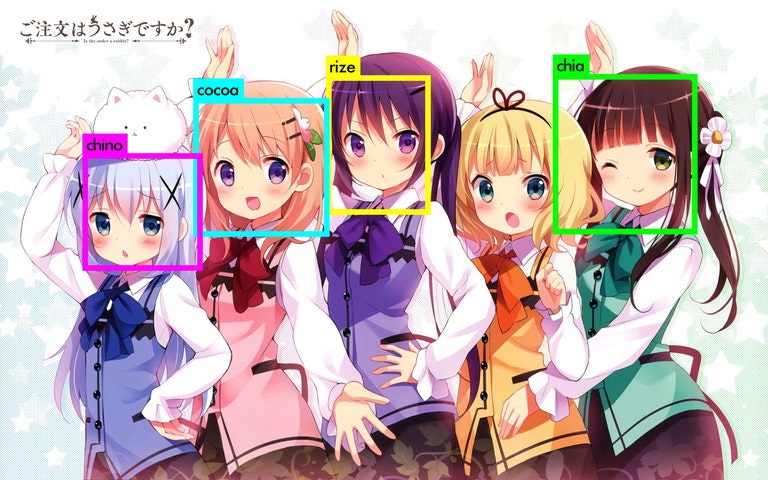
アニメの画像はうまくいっている感じですね。koi先生のイラストはもう少し学習データに入れる必要性がありそうですね。
起動したら、画像ファイルを入力してください。
未知データについて(動画)
動画の場合は次のコマンドです。
.\darknet.exe detector test [dataファイル] [cfgファイル] [weightファイル] [動画ファイル] -i 0 -out_filename [出力ファイル名]
今回の場合は、
.\darknet.exe detector demo .\test\config\learning.data .\test\config\learning.cfg .\backup_final.weights .\gochiusa_op.mp4 -i 0 -out_filename res.avi
動画でも試してみました。映像は1期、2期映像から(音声のずれは見逃してね)
https://nico.ms/sm32303411
まとめ
動画で見てみると、ご認識がまだまだ多いですね。ココアとモカさんとかマヤ・メグ・青山さんなどは学習していませんしね。
いろんなバリエーションの画像を増やせばもっと精度が上がるかな。
簡単に認識もできますし、リアルタイム処理もほぼほぼできるので今後の研究に使っていきます。