その1はこちら
その3はこちら
ヘルシンキ大学の教材のWeek3-Week4の解答と補足をまとめていきます。
Week3
3-1 ショッピングセンターのジオコーディング
ヘルシンキにある大型ショッピングモールの周囲1.5kmに住んでいる住民の数、すなわち商圏人口を求めることが目標です。自分でネットで検索してモールの住所を調べる必要があります。
住所から座標に変換するジオコーディングが登場します。日本では東京大学が提供しているCSVアドレスマッチングサービスが有名ですね。
またバッファリング・空間結合といったQGISでお馴染みの操作も登場します。
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import requests
import geojson
from shapely.geometry import Polygon, LineString, Point
from pyproj import CRS
import os
# データ読み込み
data = pd.read_table('shopping_centers.txt', sep=';', header=None)
data.index.name = 'id'
data.columns=['name', 'addr']
# ジオコーディング
geo = geocode(data['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4)
# データの結合
geo = geo.to_crs(CRS.from_epsg(3879))
geodata = geo.join(data)
# バッファリング
geodata['buffer']=None
geodata['buffer'] = geodata['geometry'].buffer(distance=1500)
geodata['geometry'] = geodata['buffer']
# 人口のグリッドデータの取得
url = 'https://kartta.hsy.fi/geoserver/wfs'
params = dict(service='WFS',version='2.0.0',request='GetFeature',
typeName='asuminen_ja_maankaytto:Vaestotietoruudukko_2018',outputFormat='json')
r = requests.get(url, params=params)
pop = gpd.GeoDataFrame.from_features(geojson.loads(r.content))
# 座標系変換
pop = pop[['geometry', 'asukkaita']]
pop.crs = CRS.from_epsg(3879).to_wkt()
geodata = geodata.to_crs(pop.crs)
# 空間結合
join = gpd.sjoin(geodata, pop, how="inner", op="intersects")
# 商圏人口の計算
grouped = join.groupby('name')
for key, group in grouped:
print('store: ', key,"\n", 'population:', sum(group['asukkaita']))
3-2 最寄りのショッピングセンター
自分の家と職場から最寄りのショッピングセンターを求めます。フィンランドに住んでいる方は別ですが、適当なヘルシンキのスポットを基点の住所として置きましょう。
(以下ライブラリのインポートは省略しています。)
# データの読み込み
home = pd.read_table('activity_locations.txt', sep=';', header=None)
home.index.name='id'
home.columns = ['name', 'addr']
shop = pd.read_table('shopping_centers.txt', sep=';', header=None)
shop.index.name = 'id'
shop.columns=['name', 'addr']
# ジオコーディング
geo_home = geocode(home['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4)
geo_shop = geocode(shop['addr'], provider='nominatim', user_agent='autogis_xx', timeout=4)
# 最寄り店を求める
destinations = MultiPoint(list(geo_shop['geometry']))
for home in geo_home['geometry']:
nearest_geoms = nearest_points(home, destinations)
print(nearest_geoms[1])
Week4
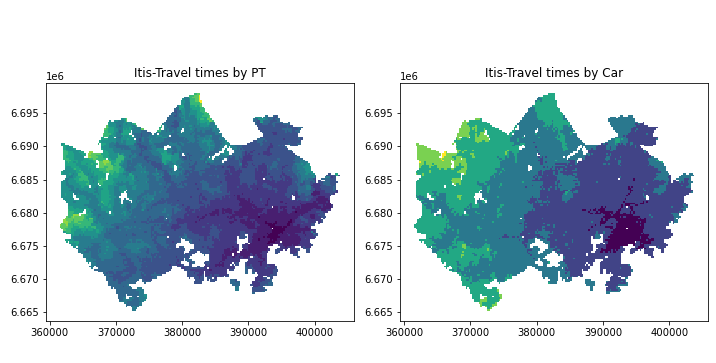
4-1 アクセシビリティデータの可視化
移動時間データと地下鉄網のデータを組み合わせて、アクセシビリティを可視化します。
# データの読み込み
grid = gpd.read_file('data/MetropAccess_YKR_grid_EurefFIN.shp')
data = pd.read_table('data/TravelTimes_to_5944003_Itis.txt', sep=';')
data = data[["pt_r_t", "car_r_t", "from_id", "to_id"]]
# データ結合
data_geo = grid.merge(data, left_on='YKR_ID', right_on='from_id')
# 無効データ(-1)の除外
import numpy as np
data_geo = data_geo.replace(-1, np.nan)
data_geo = data_geo.dropna()
# データの階層化
import mapclassify
bins = [15, 30, 45, 60, 75, 90, 105, 120, 135, 150, 165, 180]
classifier = mapclassify.UserDefined.make(bins = bins)
data_geo['pt_r_t_cl'] = data_geo[['pt_r_t']].apply(classifier)
data_geo['car_r_t_cl'] = data_geo[['car_r_t']].apply(classifier)
# 可視化
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(1, 2, 1) #公共交通
data_geo.plot(ax=ax1, column='pt_r_t_cl')
ax1.set_title("Itis-Travel times by PT")
ax2 = fig.add_subplot(1, 2, 2) #自家用車
data_geo.plot(ax=ax2, column='car_r_t_cl')
ax2.set_title("Itis-Travel times by Car")
plt.tight_layout()
plt.show()
fig.savefig('itis_accessibility.png')
こんな感じで表示されます。
4-2ショッピングモールの勢力圏
4-1で得たアクセシビリティのデータをもとに、各グリッドの最寄りのショッピングモールを求めることで勢力圏の可視化を目指します。
# データの読み込み
filepaths = glob.glob('data/TravelTimes*.txt')
for path in filepaths:
data = pd.read_table(path, sep=';')
data = data[['from_id', 'pt_r_t']]
data = data.rename(columns={'from_id':'YKR_ID'})
#カラム名を'pt_r_t_{store}'に変更
newname = path.replace('data/TravelTimes_to_', '')
newname = newname.replace('.txt', '')
newname = re.sub('\d{7}_', '', newname)
data = data.rename(columns={'pt_r_t':'pt_r_t_'+newname})
grid = grid.merge(data) #データの結合
grid = gpd.read_file('data/MetropAccess_YKR_grid_EurefFIN.shp')
# 無効データ(-1)の除外
import numpy as np
grid = grid.replace(-1, np.nan)
grid = grid.dropna()
# 各グリッドのモールへの最短距離・モール名
grid['min_t'] = None
grid['dominant_service'] = None
columns = ['pt_r_t_Ruoholahti', 'pt_r_t_Myyrmanni','pt_r_t_Itis', 'pt_r_t_Jumbo', 'pt_r_t_IsoOmena', 'pt_r_t_Dixi','pt_r_t_Forum']
mini = lambda row:row[columns].min()
idx = lambda row:row[columns].astype(float).idxmin()
grid['min_t'] = grid.apply(mini, axis=1)
grid['dominant_service'] = grid.apply(idx, axis=1)
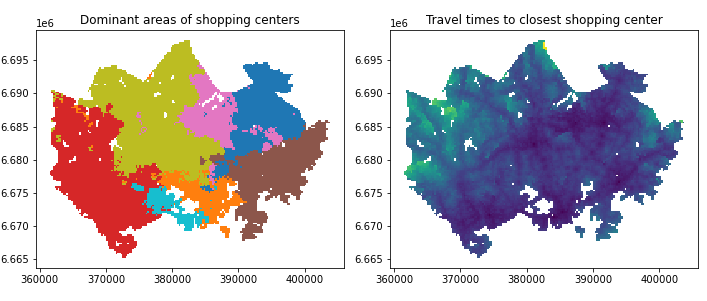
4-3 ショッピングモールの勢圏人口
グリッドデータに対してディゾルブを使い集約化しインターセクションで勢圏人口を求める、というベタなものです。
4-2と重複する箇所は省略します。
# 4-2のステップを進め, 勢圏を含むpopデータを作成
# ディゾルブしてインターセクション
dissolved = grid.dissolve(by = 'dominant_service')
pop = pop[['geometry', 'asukkaita']] #必要なデータに限定
intersection = gpd.overlay(grid, pop, how='intersection')
# 勢圏でグルーピングして勢圏人口を求める
grouped = intersection.groupby('dominant_service')
for key, group in grouped:
print(key, ':', sum(group['asukkaita']))