Deep Learning の、特に画像分類系のタスクでよく使用される、 Test Time Augmentation (TTA) という Augmentation の手法を友人 (@hattan0523) に聞いたので、実際変わるものかと思ってカジュアルに試してみました。
なんかコンペとかでは必須らしい。
※ 間違いなどご指摘歓迎です。
Test Time Augmentation (TTA) とは
機械学習、特に Deep Learning では、大きなモデルを学習させるためにたくさんの訓練データが必要になります。
データが増えるほど精度が上がったり、複雑なモデルも学習できるようになることが知られています。
そこで、訓練用データを少し加工し別のデータとしてデータセットに加えることで、学習に使えるデータの量を増やす試みがよく行われており、 Data Augmentation と呼ばれます。
特に画像系のタスクでよく使われており、元の画像を回転したり反転したりした画像を新たなデータとすることで、データ量を2倍、3倍と増やすことが出来るという仕組みです。
TTA は、学習時ではなく、推論時にも Augmentation を行うことで、推論の精度を上げる手法です。
推論時のデータを加工することで、1つのデータを数種類作成します。
その数種類のデータに対して学習したモデルで推論を行い、結果の平均や多数決をとってそれを推論結果とすることで精度を上げます。バギングのようなイメージですね。
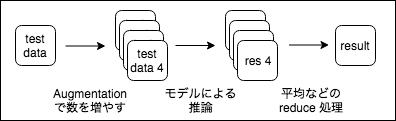
シンプルなタスクで実験
今回は cifar10 を使って、簡単な分類問題を試してみました。
TensorFlow を使っています。
単純化のため、augmentation は Horizontal Flip だけを足しています。
下記の4種類の実験を行ってみました。
- Augmentation なし
- Data Augmentation を追加
- Test Time Augmentation を追加
- Data Augmentation と Test Time Augmentation を追加
Data Augmentation は各バッチのデータごとに確率0.5で Flip を行うようにしました。
TTA は、二種類の画像(オリジナルと Horizontal Flip したもの)で、最終的に得られる確率(出力の softmax )が高い方の結果を採用するようにしました。どちらも同じ推論結果になった場合はもちろん影響ありません。
実装
こちらの記事で使ったものとだいたい同じモデルを使いました。 TensorFlow でモデルを書いていて、記事のCNNモデルクラスをそのまま使ったので、今回は Augmentation や TTA 自体は numpy で計算してます。
# 画像を水平方向に Flip
def horizontal_flip(img: np.array, rate: float=0.5):
if rate > np.random.rand():
return img[:, ::-1, :]
return img
効率を見るなら TTA も TensorFlow のオペレーションで書いたほうが良さそう。
もしくは Keras の ImageGenerator というものがあるそうで、次の記事などが参考になりそうです。
Kerasでデータ拡張(Data Augmentation)後の画像を表示する
その他の実装は https://github.com/cfiken/tta-try に置いてますが、ipynb 上でやってる上に結構雑なので参考にならないと思います。。
結果
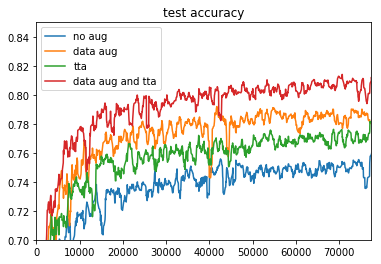
わかりやすい結果になってよかった。
Data Augmentation がある場合、ない場合それぞれに対して、TTA を入れるとだいたい 0.02 ほど精度が向上しています。
Horizontal Flip だけでこれなので、種類を増やせばもう少し上がることは期待できそうです。
まとめ
精度を上げたいなら、トレーニング時の Data Augmentation だけじゃなく TTA も入れましょう。