XTechグループ2AdventCalendar2020の23日目はiXIT株式会社エンジニアの染谷(@kumi-someya)が担当いたします。
大学の専攻だった自然言語処理の技術をちょっと使ってお問い合わせデータの分析をします!
はじめに
普段は営業サイドからデータ抽出の依頼を受けてはSQLを組み...の生活を送っている私ですが、ふと
「そういえば、お問い合わせ内容をちゃんと見たことないな...」
と思ったのが始まりです。
そこで今回は、ユーザーがサービスで不便に感じている箇所を洗い出すべく、
お問い合わせなどの自由記述式のデータを、数値化してみようと思います!
【目的】自由記述式のデータを数値に表すことで、ユーザーの不満点を明らかにする。
【仮説】頻出単語を抜き出すことができれば、ユーザーがどこで躓きやすいかがわかるのではないか。
【概要】オープンソースの形態素解析エンジンMecabを使い、Pythonで簡易的な自然言語解析を行う。
簡単に使用ツールや用語などについて
Pyhon
言わずとしれたプログラミング言語。
自然言語処理や分析に便利なライブラリがたくさんあるのでよく用いられます。今回もPythonでプログラムを組んでいきます。
形態素解析
文章を単語(形態素)ごとに分けてくれる技術のことです。
(本来、形態素≠単語 ですが、今回は簡単に同じようなものということにしておきます。)
MeCab
オープンソースの形態素解析エンジン
インポートすることで、形態素解析を行えるようになります。
システム構成
- Python 3.8.5
- ( Jupyter notebook 6.1.4 )
準備するもの
① 環境(JupyterNotebook + MeCab)
② お問い合わせ内容のcsv
準備① 環境(JupyterNotebook + MeCab)
1. JupyterNotebookを使うためにAnacondaをインストール
JupyterNotebookを使わない方は飛ばしてください
*JupyterNotebook: Notebookと呼ばれる形式でコードを記述し、画像のようにプログラムを動かしながら実行結果を残せるツールです。実行した結果が残るのでとても便利です。
Anacondaのインストール:https://www.python.jp/install/anaconda/index.html
Anaconda使わない場合:MacでPython環境を用意し、Jupyter Notebookを設定するメモ
2. macabをインストール
MeCabインストールのためのコマンドをターミナルで実行します。
$ brew install mecab mecab-ipadic
実行できませんでした...
bruwコマンドを実行するためのHomeBrewがインストールされていないようなので、
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
で HomeBrewをインストールします。(20分くらいかかります)
先ほどのコマンド(bruw install...)でmacabをインストールします。
インストールが完了したら下記のように実行できるか確認します。
$ mecab
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
EOS
無事、形態素解析は行われているようです!
MeCabは動作していますが、まだPythonでは使えないので、pipコマンドでMeCabをPythonで使えるようにします。
$ pip install mecab-python3
これでnotebookからMeCabが使えるようになったので早速使っていきましょう!
Anacondaを立ち上げたら、notebookの「Launch」からnotebookの立ち上げができるはずです。

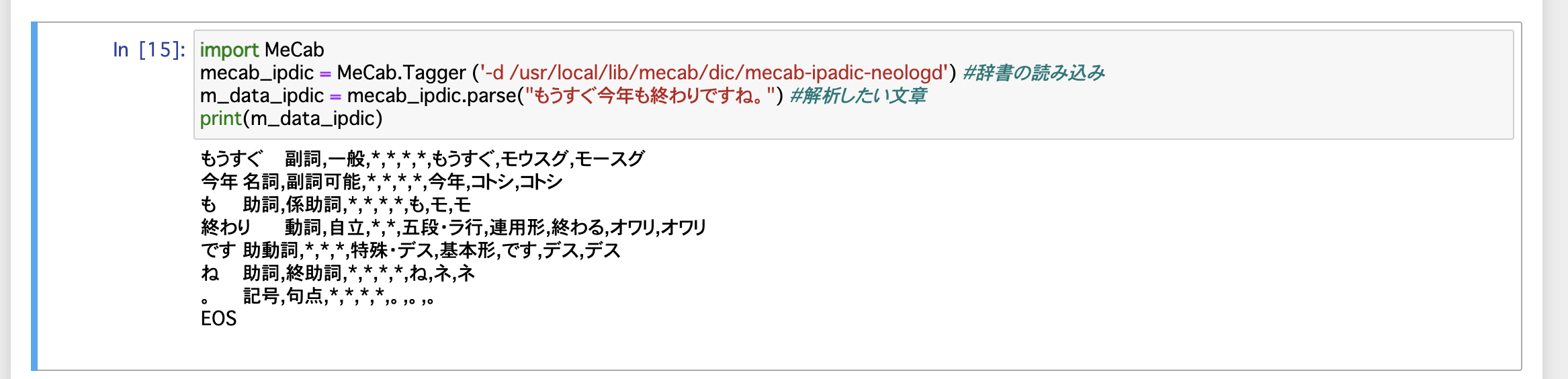
JupyterNotebookが立ち上がったら、早速MeCabで形態素解析を行いましょう!
こんな感じで実行できていればOKです! (念のため実行コードを置いておきます)
import MeCab #MeCabの読み込み
mecab_chasen = MeCab.Tagger ("-Ochasen") #辞書の読み込み
m_data = mecab_chasen.parse("もうすぐ今年も終わりですね。") #解析したい文章
print(m_data)
準備② お問い合わせ内容のcsv
今回私が使うのはお問い合わせ内容のデータ(2,831行)です。
各自が携わるサービスのデータベースからよしなに取得してください。
"content","created"
"イグジットテスト","2019-05-30 17:17:31"
"店舗での利用方法や利用回数などのFAQがおかしいリンクになってる気がします。","2019-06-01 06:51:40"
"世田谷の成城学園前、祖師ヶ谷大蔵、千歳船橋、経堂あたりで店舗が欲しいです","2019-06-03 11:42:57"
"仮登録完了メールのURLから本登録の画面に行かず、本登録出来ません。","2019-06-03 17:31:14"
"仮登録完了メールが届きません。どの様にしたら宜しいですか?","2019-06-03 20:11:04"
"有効なメールアドレスと出るがその意味がわからない。","2019-06-03 20:34:03"
(以下略)
やっと全ての準備が整ったのでお問い合わせでの頻出単語を抽出しましょう!
頻出単語を抽出
今回の目的は、問い合わせ内容全体の調査なので、まずは先程のcontacts.csvを読み込んで、1つの文字列にしたものを処理してみます。
今回csvはnotebookファイルと同じ階層に置いてあります。
下記でcsvファイルのお問い合わせ内容を全てまとめたものに対してMeCabで形態素解析を行い、頻出単語の上位50個を出力しました。(実行コードは後ほど記載します)

('の', 2158 ) の場合は「の」が2158回出現しているという意味です。
意味がありそうな頻出単語は「購入」「利用」「パスポート(サービス内でのコンテンツを指す)」「更新」などでしょうか...?
単語だけでは全く文脈が汲み取れません...ここからではユーザーがどこに不満を持っているのかわかりそうにありませんね...
もう少し方法を変えてみることにします。
↓実行したコード↓
import MeCab
import csv
# csvの読み込み
all_contact_text = ''
with open('contacts.csv') as f: #csvを行ごとに読み込む
reader = csv.reader(f) # ['content', 'created'] の形で配列を作る
for row in reader:
all_contact_text += row[0] # 全てのお問い合わせ内容を1つの文字列にする
# all_contact_textに対してMeCabで形態素解析
mecab= MeCab.Tagger ("-Ochasen") # 辞書の読み込み
node = mecab.parseToNode(all_contact_text) # 形態素解析を実行
words=[]
while node:
hinshi = node.feature.split(",")[0]
if hinshi in ["名詞"]: # 今回は名詞のみ抽出する(形容詞、動詞などの指定、複数指定も可能)
origin = node.feature.split(",")[6]
words.append(origin)
node = node.next
# それぞれの単語の数をカウント
import collections
c = collections.Counter(words)
print(c.most_common(50)) # 使用頻度の上位50単語を表示
複数形態素で区切ってみる
前後に位置する他の単語との組み合わせで頻度を測れば、もう少し文脈がわかりやすくなるのではないでしょうか?
例えば記事のタイトル「お問い合わせ内容からユーザーの不満をとても簡易的に解析する」だと、形態素に分けた場合
お/問い合わせ/内容/から/ユーザー/の/不満/を/とても/簡易/的/に/解析/する
となります。
これを今回は下記のように i番目の形態素とi+1番目の形態素をセットにしていきます。(2つの形態素で区切る場合)
ついでに先ほどの実行結果で出てきていた「*」の文字も邪魔なので消しましょう。
お/問い合わせ,
問い合わせ/内容,
内容/から,
から/ユーザー
(以下略)
import MeCab
import csv
# csvの読み込み
all_contact_text = ''
with open('contacts.csv') as f: #csvを行ごとに読み込む
reader = csv.reader(f) # ['content', 'created'] の形で配列を作る
for row in reader:
all_contact_text += row[0] # 全てのお問い合わせ内容を1つの文字列にする
# all_contact_textに対してMeCabで形態素解析
mecab = MeCab.Tagger ("-Ochasen") #辞書の読み込み
node = mecab.parseToNode(all_contact_text)
word_arr=[]
while node:
hinshi = node.feature.split(",")[0]
if hinshi in ["名詞","形容詞","動詞"]: # 文脈を読みたいので形容詞と動詞も抽出対象に
origin = node.feature.split(",")[6]
word_arr.append(origin)
node = node.next
# 「*」を削除
word_arr_except_trash = []
not_trash_num = [i for i in range(len(word_arr)) if word_arr[i] != "*"]
for i in not_trash_num:
word_arr_except_trash.append(word_arr[i])
# 2つの形態素で区切る場合
join_word_arr = []
for i in range(len(word_arr_except_trash)-1):
join_word = word_arr_except_trash[i] + "/" +word_arr_except_trash[i+1]
join_word_arr.append(join_word)
# 3つの形態素で区切る場合
# join_word_arr = []
# for i in range(len(word_arr_except_trash)-2):
# join_word = word_arr_except_trash[i] + "/" +word_arr_except_trash[i+1]+"/"+word_arr_except_trash[i+2]
# join_word_arr.append(join_word)
# 4つの形態素で区切る場合
# join_word_arr = []
# for i in range(len(word_arr_except_trash)-3):
# join_word = word_arr_except_trash[i] + "/" +word_arr_except_trash[i+1]+"/"+word_arr_except_trash[i+2]+"/"+word_arr_except_trash[i+3]
# join_word_arr.append(join_word)
# 単語の数をカウント
import collections
c = collections.Counter(join_word_arr)
print(c.most_common(50))
上記を実行し、2〜4つの形態素で区切った結果を出しました。
2つの形態素で区切る場合:
('購入/する', 599),('利用/する', 436),('登録/する', 320),('更新/日', 239), ('自動/更新', 235) など
だいぶ意味がわかるようになった気がします。
少なくともサービスに携わる人ならユーザーがどこで躓いて問い合わせをしているのかは、ざっくりわかるようになったのではないでしょうか?
3つの形態素で区切る場合:
('更新/する/れる', 202),('自動/更新/する', 128),('次回/更新/日', 68),('新規/登録/する', 48),('プラン/変更/する', 30)など
だいぶピンポイントになりました。
「する」の活用系は全て「する」として形態素になっているので「'更新/する/れる'」は「更新される」だと思われます。
これに疑問詞をつけて考えると「いつ更新される」といったお問い合わせが多いのではと推測できます。
ここから次回更新日がいつかわかりにくい、という不満点が読み取れました。
4つの形態素で区切る場合:
('自動/更新/する/れる', 111),('表示/する/れる/いる', 51),('更新/する/れる/いる', 50)('更新/する/れる/しまう', 30),('更新/日/月/日', 17)など
それぞれの組み合わせの意味合いとしては3つの形態素で区切った場合と似たようなものも抽出されましたが、
面白いことに、問い合わせの内容に関係のない
('する/れる/いる/の', 28), ('する/せる/いただく/おる', 21), ('する/れる/いる/まま', 19)
などの組み合わせも増え、データ全体の精度は落ちた印象を受けます。
結果
上記から、3つの形態素で区切る場合が一番データとしての有用性が高かったので、その結果から
・ いつ自動更新されるかわかりにくい
・ 新規登録の方法についてわかりにくい
・ プラン変更の方法についてわかりにくい
などの点がユーザーの不満・不便に感じている点ではないかと推測されました。
おわりに
もっと本格的に類語推定を使ったりすればより精度が高く、即戦力になるデータが出せると思うのですが、それには本格的な自然言語処理の技術が必要になるので要勉強です...
また、今回は全期間のお問い合わせ内容を対象としていたので、サービスの改修によって状況が変わっていてもそれは汲み取れません。
期間を絞るか、月別などで解析を行えば、リリース前後でのユーザーの反応なども探れるかもしれません。
お問い合わせ件数が多いサービスなどに対しては、(複雑な計算がいらないものにしては)使えると思うのでご活用いただければ嬉しいです!
明日のXTechグループAdventCalendar2020担当は @kohei_sasakiさん、@branch10480さんです。
引き続きお楽しみください!
参考
MeCabでの形態素解析 on Mac
初めての自然言語処理 入門 1 ~MeCabを動かしてみよう ~
Pythonで文章中の頻出単語を抽出する方法