はじめに
AWSのクラウドストレージであるAmazon S3は、AWS上にファイルを保存する際に第一の選択肢となるサービスです。その普及度の高さから進化も早く、最新機能も含めた全体像の理解は労力が掛かります。
そこで備忘録も兼ねて、2023年4月時点での機能および使用法を、初学者でも理解しやすいことを心掛けてまとめました。

網羅度にこだわってまとめたので、「S3の全体像を理解したい!」という方は、ぜひご一読頂ければと思います。
また、S3のセキュリティとバックアップ機能は別記事にまとめたので、よければこちらもご参照ください。
Amazon S3とは
「Amazon Simple Storage Service」の略です。後ろの3つの単語の頭文字が全てSなので、S3と略しているようです。
S3は端的に言うとクラウド上にファイルを保存するためのサービスで、Googleドライブのようなオンラインストレージと似ていますが、オブジェクトストレージと呼ばれるやや特殊な形式での保存法を採用しています。
オブジェクトストレージの特徴は以下で分かりやすく解説されていますが、データの検索性が高いことや、OSへの依存性が低いことがメリットのようです。
S3はSDKやAPIによるプログラムからのアクセス、ライフサイクルによるファイル保管コスト削減、静的Webサイトホスティングやデータレイク機能等、単なるストレージの枠を超えた多機能さが特徴で、AWSの根幹をなすサービスの一つです。
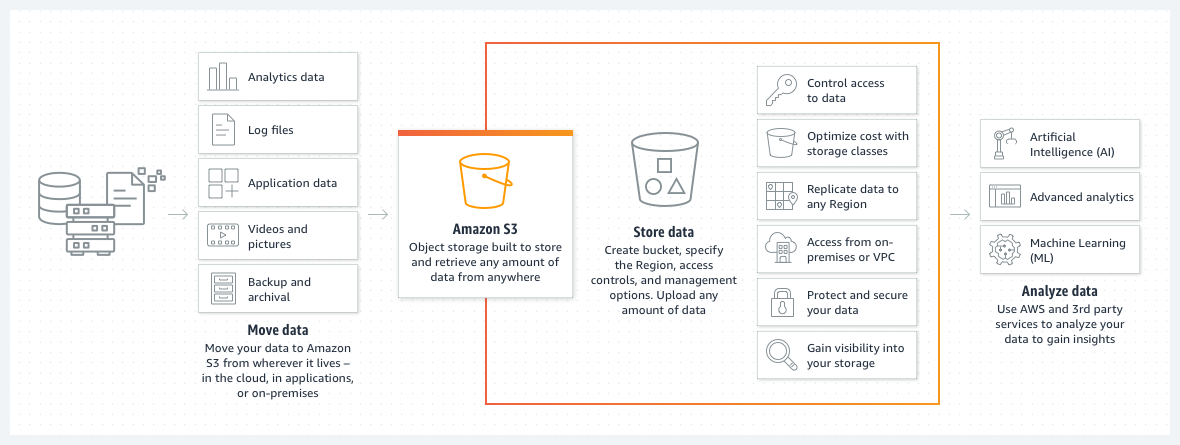
※画像はAWS公式より
EBSやEFSとの違い
AWSでよく使用されるストレージサービスとして、S3以外にEBS (Elastic Block Strage)とEFS (Elastic File System)が挙げられるため、これらの違いを考えてみます。
S3は静的サイトのホスティングに使用される事からも分かるように、それだけで独立したサービスとして動作するストレージであり、クラウドサービスとして独立しているという観点から、DropBoxやGoogleドライブのような存在とみなすと分かりやすいかと思います。
EBSやインスタンスストアはOSのイメージが入っていることから分かるように、EC2インスタンスと一緒に動作する事が前提となっており、通常のPCで言うと内蔵HDD(SSD)に相当します。
また、もう一つAWSでよく使用されるストレージにEFSが挙げられ、こちらはEBSのようにEC2にマウントでき、かつ複数のEC2インスタンスやFargateコンテナから共有ができるため、オフィス内の共有ドライブ、すなわちNASに近い存在と言えます (捉え方によってはS3とEBSの中間的な存在とみなせる)。またEFSはLambdaやFargate等のEC2以外のコンピューティングサービスでも使用できます。
その他、冗長化やデータの保持形式、コストにも以下のような差があります
(KMSによる暗号化ができる等、共通点もあります)
| 動作形態 | デフォルトの冗長化方法 | データ保持形式 | 東京リージョンでの料金 (1GB・月あたり) | |
|---|---|---|---|---|
| S3 | 単独のサービスとして動作 | 複数AZで冗長化 | オブジェクトストレージ | 0.025USD (S3標準), 0.005USD (Glacier Instant) |
| EBS | EC2インスタンスと一緒に動作 | 単一AZ内で冗長化 | ブロックストレージ | 0.12USD(gp2 SSD), 0.018USD(sc1 HDD) |
| EFS | EC2インスタンスにマウントされる事が多いが、他サービスからも利用可能 | 複数AZで冗長化 | ファイルストレージ | 0.36USD (標準), 0.0272USD(低頻度) |
上記を見れば分かるように、価格面を見るとS3はコストパフォーマンスの良いストレージと言えるでしょう
S3の仕組みと各種機能
S3の仕組みと各種機能について、以下のセクションに分けて解説します
長いですが、読了する頃には「S3完全に理解した!」と言えるような記事を目指したいと思います。
以下、詳細を解説します。
S3の構造
S3ではバケット、オブジェクトの階層構造でデータを管理します。
またバケットやオブジェクトは仮想化されたサーバ内での構造を表していますが、これら仮想システムが実際に動作する物理サーバの位置は、リージョン、AZ(アベイラビリティゾーン)により指定する事ができます。
以上を踏まえて、S3のデータ格納構造の概念図を下記します(あくまで概念図であり、厳密な物理構造を表さない事にご注意ください)
・S3のシステム概念図
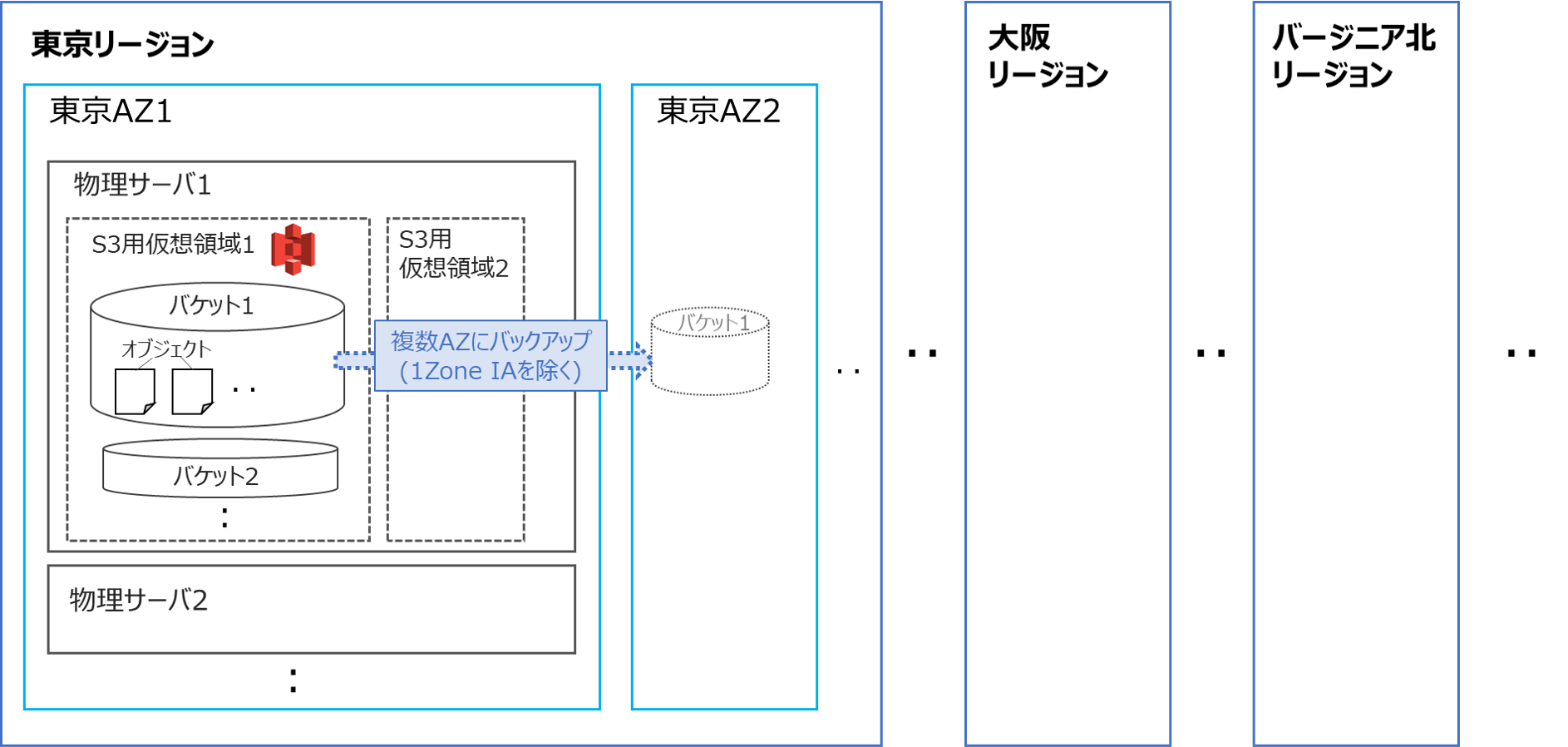
それぞれ解説します。
リージョン
データが実際に保存される地理的な位置を表します。
全世界に数十個のリージョンが存在しますが、日本からの使用頻度が高いリージョンは以下となります。
・主なリージョン
| リージョン名 | 英名 | 場所 | 特徴 |
|---|---|---|---|
| アジアパシフィック (東京) | ap-northeast-1 | 日本 東京都 | 日本国内からの利用では第一の選択肢となる |
| アジアパシフィック (大阪) | ap-northeast-3 | 日本 大阪府 | 西日本からの通信遅延(レイテンシ)が少ないが、機能が限定されている(例:Transfer Accelerationが使用不可) |
| アジアパシフィック (シンガポール) | ap-southeast-1 | シンガポール | アジアで最初のリージョン |
| 米国東部 (バージニア北部) | us-east-1 | 米国 バージニア州 | 世界で最初のリージョン、費用が安めでサービスが豊富。日本からは通信遅延大 |
アベイラビリティゾーン(AZ)
1つのリージョンは、実は地理的に離れた複数のデータセンターから構成されています。
実際の位置は公開されていませんが、例えば品川区と江東区にサーバが分散されているようなイメージです。
この個々のデータセンターのことをアベイラビリティゾーンを呼び、複数のアベイラビリティゾーンを跨いだ構成(マルチAZ)とすることで、リージョンを跨いだ場合と同様に可用性向上およびデータの消失対策に繋げられます
S3においては、基本的には3つ以上のAZ間でのレプリケーション(相互バックアップ)を実施するマルチAZ構成となっており、後述の1ゾーンIAのみ(参考)シングルAZ構成となっています
バケット
バケットとは、S3内のファイルを管理する基本単位となるストレージを表し、全世界で一意の名前を付与する必要があります。
このバケット単位で、後述のバージョン管理やセキュリティの設定が行われます
バケットの中にはさらにフォルダを階層状に作成する事ができ、最下層に後述のオブジェクトが配置されます。
ただし、厳密にはS3にはフォルダ構造は作成されず、ユーザが整理しやすいよう「プレフィックス」により仮想的なフォルダ構造を表現)しています (ざっくり用語を理解するのであれば、S3におけるフォルダ = プレフィックスとみなしてOKです。以後本記事で「フォルダ」と書いてあれば、「プレフィックス」と同義で使用されていると認識頂ければと思います)
詳しい機能と設定方法は、後述のバケットの設定を参照ください
オブジェクト
オブジェクトは、端的に言うとファイル1つ1つを表しています。
画像ファイル(.jpg, .png等)や表データ(.csv, .xlsx)等、普段見かけるファイル(値)に以下の要素(エレメント)を付与したものが、S3内で保管されるオブジェクトとなります。
| エレメント名 | 概要 |
|---|---|
| キー | フォルダ名も含めたオブジェクトのパス (例: 「◯.jpg」「フォルダ名/○.csv」) |
| 値 | データそのもの(画像ファイルや表データ等) |
| バージョンID | バージョン管理用のID |
| メタデータ | オブジェクトに関する情報を保存するための属性値(名前と値のペア) |
| サブリソース | オブジェクト固有の追加情報を保存する |
| アクセスコントロールの情報 | ACLやバケットポリシー等のアクセス制御情報 |
詳細は以下を参照ください
・オブジェクトにアクセスするためのパス
オブジェクトのパスは、以下のような階層構造で表されます (前述のようにフォルダ名は「プレフィックス」とも呼ばれ、複数階層とすることも、フォルダを作成しないことも可能です)
バケット名/フォルダ名/オブジェクト名
このオブジェクトにアクセスするには、主に以下のキー、S3 URI、オブジェクトURL、ARNと呼ばれる表記法が使用されます。
キー
フォルダ名とオブジェクト名を合わせて「キー」と呼び、バケット内でオブジェクトを一意に特定する際に使用されます。
フォルダ名/オブジェクト名
S3 URI
CLI等でオブジェクトにアクセスする際に使用されます。こちらの例のように、Python等のスクリプトからのアクセスでもよく利用されます。
s3://バケット名/フォルダ名/オブジェクト名
オブジェクトURL
HTTPリクエスト(REST API)でオブジェクトにアクセスする際に使用されます
https://バケット名.s3.リージョン名.amazonaws.com/フォルダ名/オブジェクト名
Amazon リソースネーム (ARN)
IAMポリシーでの指定時(Resourceフィールド)等、AWS内の他のリソースからの指定によく使用されます。
arn:aws:s3:::バケット名/フォルダ名/オブジェクト名
S3の種類 (ストレージクラス)
S3へのデータ格納方法には以下のような種類 (ストレージクラス)があります(参考)
下に行くほど可用性や通信遅延等の性能が低下しますが、その分価格が安くなります
(デフォルトのS3標準が、最も高機能だが高価格)
| 名称 | 耐久性 | 可用性 | 可用性SLA | 通信遅延 | 概要 |
|---|---|---|---|---|---|
| S3 標準 | 99.999999999% | 99.99% | 99.9% | ミリ秒 | デフォルト |
| S3 標準IA | 99.999999999% | 99.9% | 99% | ミリ秒 | S3標準より安価だが可用性がやや落ちる。アクセス頻度が低いファイル向け |
| S3 Intelligent-Tiering | 99.999999999% | 99.9% | 99% | ミリ秒 | オブジェクトのアクセス頻度に合わせ階層を自動切替 |
| S3 1ゾーンIA | 99.999999999% | 99.5% | 99% | ミリ秒 | 標準IAのシングルAZ版。より安価だが耐障害性も低下 |
| S3 Glacier Instant Retrieval | 99.999999999% | 99.9% | 99% | ミリ秒 | 安価だが最低料金期間が長め |
| S3 Glacier Flexible Retrieval | 99.999999999% | 99.99% | 99% | 分or時間単位 | 安価だがデータの取出に時間かかる |
| S3 Glacier Deep Archive | 99.999999999% | 99.5% | 99% | 分or時間単位 | 安価だがデータの取出に時間かかる |
ストレージクラスはバケット単位での設定ではなく、バケット作成後にフォルダ (プレフィックス)単位、またはオブジェクト単位で設定できます。
どのストレージクラスを選ぶかは、以下のフローチャートが参考になります (後述のS3のコストも参照ください)
以下、それぞれのストレージクラスについて解説します
S3 標準
デフォルトで選択されるストレージクラスです。
「標準」と名前がついていますが、最も高機能で高価格なクラスとなっています
複数のAZに冗長化されており、それ以外にも様々な工夫により、99.99%という高い可用性を実現しています。
S3 標準IA
可用性が99.9%とS3標準よりやや低いですが、それ以外はほぼ同等の機能(複数AZでの冗長化等)を持ったタイプです。
可用性以外のS3標準との差として、データ保存の料金が安い代わりに、30日最低料金やデータ取出料金が設定されている事が挙げられます。
保管コストが安くアクセスコスト高いという特性から、アクセス頻度が低く、かつある程度長期保管が想定されるファイルの格納に向いています。
S3 Intelligent-Tiering
アクセス頻度に合わせ、「高頻度にアクセスするファイル→高性能だが料金の高い階層」「アクセス頻度の低いファイル→低性能だが料金の低い階層」というように階層を自動で振り分ける、賢い(Intelligentな)ストレージクラスです。
これにより使用頻度に応じてコストとパフォーマンスのバランスを自動で調整する事ができます。
具体的には、以下の階層を自動で遷移します (参考)
- 高頻度アクセス階層: S3標準と同等
- 低頻度アクセス階層: 30日以上アクセスがないと移行。S3標準IAに相当
- インスタントアクセス階層: 90日以上アクセスがないと移行。S3 Glacier Instant Retrievalに相当
- アーカイブアクセス階層: 90-730日以上アクセスがないと移行。S3 Glacier Flexible Retrievalに相当 (オプション)
- ディープアーカイブアクセス階層: 180-730日以上アクセスがないと移行。Glacier Deep Archiveに相当 (オプション)
ディープアーカイブアクセス階層のみオプションで、有効化するためにはバケット作成時に指定する必要があります。
また低頻度アクセス、インスタントアクセス階層はファイルにアクセスがあると自動的に高頻度アクセス階層に戻されますが、アーカイブ、ディープアーカイブアクセス階層は階層を戻すための操作が必要です。
なお、Intelligent-Tieringと似た機能に「ライフサイクルルール」が挙げられますが、詳細はこちらを参照下さい
・Intelligent-Tiering Archive 設定
S3 Intelligent-Tieringのアーカイブアクセスおよびディープアーカイブアクセス階層はオプションのため、有効化するためにはバケットの設定から事前に設定を行う必要があります。
以下のように、両階層の有効無効と、その階層に移行するまでの日数 (連続してこの日数アクセスされないオブジェクトが移行)を指定する事ができます。

S3 1ゾーンIA
S3 標準IAから、複数AZでの冗長化を抜いたものに相当します。
料金は標準IAよりも安いですが、冗長化されていないために消えると困るファイルは置かない方が無難です。
アクセス頻度が低く、かつ可用性やデータの消失対策の必要性が低い用途に向いています
S3 Glacier Instant Retrieval
可用性99.9%や複数AZでの冗長化等、S3標準IAと似た機能を持っていますが、最低料金期間が90日と長く、より長期保存が前提となるファイルの保存に向いたクラスと言えます。
公式ドキュメントでは、各種バックアップや医療用画像等、「アクセス頻度は低いが、いざという時すぐにアクセスできる必要のあるファイル」の保存に向いていると書かれています。
基本的にはコストパフォーマンスの良いストレージクラスですが、後述のようにGETやPOSTリクエストによるアクセスコストは高めなのでご注意ください。
S3 Glacier Flexible Retrieval
S3 Glacier Instant Retrievalと名前が似ていますが、最大の差はデータの取り出しに数分〜数時間掛かる事です。
よって、すぐにアクセスできる必要のある用途には向きません。
その分料金は安く設定されているので、古いバージョンのバックアップの保管等に向いています
なお、本クラスでのデータ取り出し方法には、数分で取り出せるが料金が高めの「迅速取り出し」と、3〜5時間を要するが料金が安めの「標準取り出し」、最大12時間を要するが料金が最安の「大容量取り出し」の3種類が存在します。
S3 Glacier Deep Archive
S3 Glacier Flexible Retrievalよりもさらに取り出し時間が長く、最大12時間程度かかってしまいます。
よって、すぐにアクセスできる必要のある用途では使用できません。
一方で料金はS3の中でも最安で、S3標準と比べると90%以上の割引となります。古いバージョンのバックアップの保管を格安で実現したい場合に有効なクラスです
S3のセキュリティ機能
S3は大容量データを保管するという性質上、当然機密情報が含まれるケースを想定しなければなりません。
例えば、2021年に巷を騒がせた免許証流出も、(S3かは不明ですが)クラウドストレージで保管されていた機密情報への不正アクセスに起因しており、より厳しいセキュリティ対策が必要であることが記事中でも結論づけられています。
このような機密情報を守るためにS3は以下のセキュリティ機能を持ち、適切な利用によりセキュリティ強度を高める事ができます。
| 名称 | 概要 |
|---|---|
| ポリシーによるアクセス制御 | バケットにアクセスできるユーザーやアプリケーションを制限する |
| ACLによるアクセス制御 | バケットやオブジェクトにアクセスできるAWSアカウントを制限する |
| データの暗号化 | バケットに格納されたオブジェクトを暗号化する |
| ブロックパブリックアクセス | インターネットからのアクセスを禁止する |
| 署名付きURL | 時間制限付きで外部にオブジェクトを公開するURLを発行 |
| CORS | オリジン以外のドメインからのデータ取得を許可する |
| S3のアクセスアナライザー | 外部からのアクセスが可能なセキュリティリスクの高いバケットを検知 |
| アクセスログの記録 | アクセスログをS3サーバーログやCloudTrailで記録 |
詳細は以下の別記事にまとめましたので、各機能の詳細はリンク先を参照してください
バックアップとバージョン管理
前述のように、S3はマルチAZ構成による冗長化 (1ゾーンIAを除く)が行われており、デフォルトでも高い可用性、データ消失対策を実現できています。
よってS3はデータのバックアップ用途に使用される事が多いですが、以下の機能を活用することで、バックアップとしての利便性向上や保管コストの削減に繋げる事ができます。
| 名称 | 概要 |
|---|---|
| クロスリージョンレプリケーション | リージョンを跨ぐバケットのレプリケーションを実施 |
| バケットのバージョニング | バケット内のオブジェクトをバージョン管理する |
| ライフサイクルルール | 時間経過に応じてオブジェクトクラスやバージョンを自動移行する |
詳細は以下の別記事にまとめましたので、各機能の詳細はリンク先を参照してください
S3の分析機能 (データレイク)
S3の重要なユースケースの一つとして、データレイクが挙げられます。
データレイクとは構造化、非構造化を問わず様々な形式のデータを大量に保管するための仕組みで、主にビッグデータ分析に用いられます。
AWSにおいてはS3がこのデータレイクの役割を果たしており(Hadoop互換の分散ファイルシステムに対応)、S3に格納されたテキスト、CSV、Parquet形式等のデータと以下のサービスを組み合わせる事で、大量データに対する高速分析を実現する事ができます。
| 名称 | 概要 | ユースケース |
|---|---|---|
| S3 Select | S3に保存されたCSV, JSON, Parquet形式データに対しSQLクエリによるデータ取得・分析が可能 | 簡単なデータ分析 |
| Athena | S3に保存されたデータに対しSQLクエリによるデータ取得・分析が可能 (S3 Selectより高機能) | 高機能なデータ分析 |
| Redshift Spectrum | S3に保存されたデータに対し、Redshiftによる直接クエリ実行・分析が可能 | Redshiftの技術資産を活用したデータ分析 |
| EMR | Apache Spark等の分散データ処理フレームワークを利用して高速ビッグデータ分析が可能 | Sparkを活用した高速データ分析 |
データレイクについては後日詳細な記事を作成しますが、ここではそれぞれ簡単に解説します
S3 Select
S3に保存されたCSV, JSON, Parquet形式のデータ (GZIPやBZIP2による圧縮データでもOK)に対して、SQLクエリによるデータ取得ができる機能です。
単純にデータの集計や分析が出来る事以外にも、クエリでフィルタリングした後のデータのみを取得できるため、通信コストやデータ取得時間を抑えられるというメリットもあります。
コンソールからは以下のようにオブジェクトを開いた状態で「オブジェクトアクション」→「S3 Selectを使用したクエリ」で実行できます

コンソールだけでなくRest APIやSDK経由でプログラムからも実行できるので、S3からのデータ取得時間・コストを抑えたい場合の選択肢の一つとして検討しても良いかと思います。
詳細は以下の公式ドキュメントを参照ください
Athena
S3 Selectと同様に、S3に保存されたデータに対してクエリによるデータ取得ができるサービスですが、S3 Selectよりも高機能で、以下のような違いがあります。
・CSV, JSON, Parquet形式以外にも、txt等多数のデータ形式に対応
・対応する圧縮形式もS3 Selectより多い
・S3とは独立したサービスのため、S3以外のデータソースにも対応 (AWS Glueデータカタログにより接続)
Redshift Spectrum
Redshift Spectrumは、S3等に保存されたデータに対して直接Redshiftのクエリを実行できる機能です。
AWS上に分析用DBを構築する場合、データウェアハウス (DWH)であるRedshiftを用いる事が第一の選択肢となります。
S3上のデータをRedshiftで分析する場合、旧来はデータを整形してRedshift上のテーブルにコピー (Extract, Transform, Load = ETL)する必要がありましたが、Redshift Spectrumを用いることでこのようなETLシステム構築の手間を省くことができます。
ログ等の大規模データの分析に用いるという点でユースケースがAthenaと近く、両者の使い分けには以下の記事が参考となります。
まとめると以下のようなメリットデメリットが得られそうです。
| Redshift Spectrum | Athena | |
|---|---|---|
| メリット | Redshiftの機能をそのまま活用できる (Redshiftユーザなら学習コスト低) | サーバーレスのためクラスタの維持費が掛からない |
| デメリット | クラスタを常時起動するための維持費がかかる | Athena独自機能に対する学習コストが掛かる |
なお、サーバーレスかつDWHであるBigQueryの技術資産を流用できる、ある意味両者の良いとこ取りとも言えるGoogle CloudのBigQuery Omniも、マルチクラウドを許容できるのであれば選択肢に入れても良いかと思います。
EMR
EMRは、Apache Spark、Apache Hive、Presto 等の分散データ処理フレームワークを利用して高速ビッグデータ分析を実現できるサービスです。
EMRではクラスターと呼ばれる処理用のノード (実体はEC2インスタンス)を複数立ち上げ、これらを分散処理フレームワークで制御 (YARNの記事が参考になります)する事で、分散高速処理の恩恵を受けられるサービスです。
狭義の「データレイク」はこのような分散処理フレームワークを指すことが多いので、Redshiftと並んでAWSにおけるビッグデータ分析の王道のサービスと呼べるでしょう。
これだけ聞くと仰々しく感じますが、SparkはPython(PySpark)等のSDKを利用する事で簡易に分析スクリプトを作成する事ができるため、手軽に数千万行クラスのデータの高速分析を実現する事ができます。
具体例としてS3 + EMR + PySparkでの実装法を別記事で紹介したいと思います。
静的Webサイトのホスティング
S3でよく利用される機能として、静的Webサイト (DBアクセスのようなサーバーサイド処理をを持たないWebサイト)のホスティングが挙げられます。
S3をホスティングに使用するとストレージやリクエスト等の料金が掛かりますが、これらは一般的にEC2やFargateのようなコンピューティングサービスと比べ維持費が低額なため、低コストでWebサイトを公開する事ができます。
また、ブラウザからAPIでデータを直接取得するSPA構成とする事でサーバーサイド処理を有効化できたり、CloudFrontと組み合わせて配信を高速化したりと、利便性を向上させる機能を数多く備えており、これらとサーバーレスサービス等を併せて活用する事で低コストかつ高速な動的サイトの構築まで実現できてしまいます。
詳細は実装法も交えて別記事で紹介したいと思います。
その他のS3関連機能
| 名称 | 概要 |
|---|---|
| S3 Inventory | バケット内のオブジェクト一覧を定期的に出力する |
| オブジェクトLambdaアクセスポイント | S3 Object Lambda(S3へのリクエスト時にLambdaで動的な処理を加える)を使用するためのアクセス経路を作成する |
| バッチオペレーション | 大量のオブジェクトに対して特定の処理 (Lambda等)を一括実行 |
| イベント通知 | S3バケットへのイベント(オブジェクト作成、削除等)発生時に、Lambda、SNS、SQSいずれかによる処理を自動実行 |
| Transfer Acceleration | インターネットからS3へのデータアップロード時に、最寄りのAWSの拠点を経由することで転送速度を高速化 |
| AWS Storage Gateway | オンプレ側のストレージ機能(外付けSSD、NAS、テープストレージ等)をクラウド側のストレージ(S3、EBS等)で置き換え、併用するためのサービス |
S3 Inventory
バケット内のオブジェクト一覧を定期的に出力してくれる機能です。
具体的な使用手順は、以下の記事が分かりやすいです。
なお、ここで出力されるmanifest.jsonは、後述のバッチオペレーションでも使用する事ができます。
オブジェクトLambdaアクセスポイント
GETリクエストでS3からデータを取得する場合、通常は格納されていたデータをそのまま(静的に)返します。
これに対し、S3 Object Lambdaと呼ばれる機能を使用する事で、データを動的に処理した上で返す事ができます。
このS3 Object Lambdaを使用するためには、S3とLambdaとのアクセスを疎通 (参考)させるためにオブジェクトLambdaアクセスポイントが必要となり、本画面でこのアクセスポイントを作成する事ができます。
公式リリースでは、S3 Object Lambdaのユースケースとして以下が例示されています(1つ目のユースケースは前述のデータレイク機能と近いと言えます)
- 行のフィルタリング
- 画像の動的なサイズ変更
- 機密データの編集
具体的な使用法は以下の記事が参考になります
バッチオペレーション
バッチオペレーションとは、大量のオブジェクトに対して特定の処理を一括実行できる機能です。
データコピーのようなシンプルな処理から、Lambdaを利用した自由度の高い処理まで様々な処理を実現でき、オブジェクト一括暗号化等、公式に利用が推奨されているユースケースも存在します。
バッチオペレーションの実行単位をジョブと呼び、以下の内容を指定することで処理を定める事ができます
- マニフェスト:処理対象のオブジェクトを指定
- オペレーション:処理内容を指定
- 追加のオプション:必要なロール等を指定
・マニフェスト
マニフェストとは、処理対象のオブジェクトを指定するためのファイルです。
以下の3形式で指定する事ができます
| 名称 | 概要 |
|---|---|
| S3インベントリレポート(manifest.json) | JSON形式で対象オブジェクトを指定 |
| CSV | CSV形式で対象オブジェクトを指定 |
| レプリケーション | コンソールで対象オブジェクトを指定(レプリケーション処理のみ対応) |
それぞれ解説します
S3インベントリレポート(manifest.json)
JSON形式で対象オブジェクトを指定します。
manifest.jsonを1から自分で作成するのは大変なので、前述のS3 Inventoryを使用すると便利です。
以下の記事が参考になります
CSV
CSV形式で対象オブジェクトを指定します。
以下のように、バケット名とオブジェクトのキーを列に持ったシンプルな記述で指定が可能です
(オプションでバージョンIDの列も追加可能ですが、この場合「マニフェストにはバージョン ID が含まれています」をチェックしてください)
バケット名1,オブジェクト1のキー
バケット名1,オブジェクト2のキー
:
バケット名2,オブジェクト○○のキー
:
レプリケーション
処理内容(オペレーション)がレプリケーションの時のみ、コンソール画面から対象オブジェクトを指定する事もできます。
バケットを選択した上で、指定日付でフィルタリングした作成日範囲のオブジェクトが処理対象となります
・オペレーション
マニフェストで指定したオブジェクトに対して実行する処理を選択します。
実際の選択画面は以下のようになっており、コピーやLambda、ACLの置き換え等が選択できます。
(最後の「レプリケート」はマニフェストでレプリケーションを指定した時のみ指定可能です)

・追加のオプション
追加のオプションでは完了レポートの出力やタグなども指定する事ができますが、何より重要なのがIAMロールの付与です。
オペレーションで指定した処理が実行できるポリシーを作成(または既存のポリシーから選択)し、これをIAMロールに付与してください。ここが間違っているとバッチ処理が実行できません。
IAMロールとポリシーについては以下の記事をご参照ください (むやみな管理者権限の付与は厳禁です)
このポリシー作成は結構テクが必要ですが、
「作成したポリシーを付与したユーザーでオペレーションの処理と同等の操作を実行できるか」
を都度確認すれば、正しいポリシーを効率よく作成できるかと思います。
イベント通知
S3バケットに対してイベント(オブジェクトの作成、削除、ライフサイクルルール移行等)が発生した際に、Lambda(汎用的なサーバーレス処理)、SNS(Eメール等)、SQS(他アプリへのメッセージ送信)いずれかによる処理を自動実行する事ができます。
(プレフィックス、サフィックスで対象フォルダやオブジェクトを限定できます)
具体的な使用法は、以下の記事が参考になります
Transfer Acceleration
Transfer Accelerationとは、インターネットからS3へのデータアップロード時に、最寄りのAWSの拠点 (CloudFrontのエッジロケーション)を経由することで転送速度を高速化する機能です。
詳細は以下QAで簡潔にまとめられています。
AWS Storage Gateway
オンプレ側のストレージ機能をクラウド側のストレージ(S3、EBS等)で置き換える(あるいは併用する)ためのサービスです。クラウドストレージをあたかもオンプレのストレージであるかのように扱えるため、社内システムにおけるファイルサーバやバックアップ、アプリケーションサーバのストレージを、最小限の改造でS3等のクラウドストレージに置き換える事ができます。
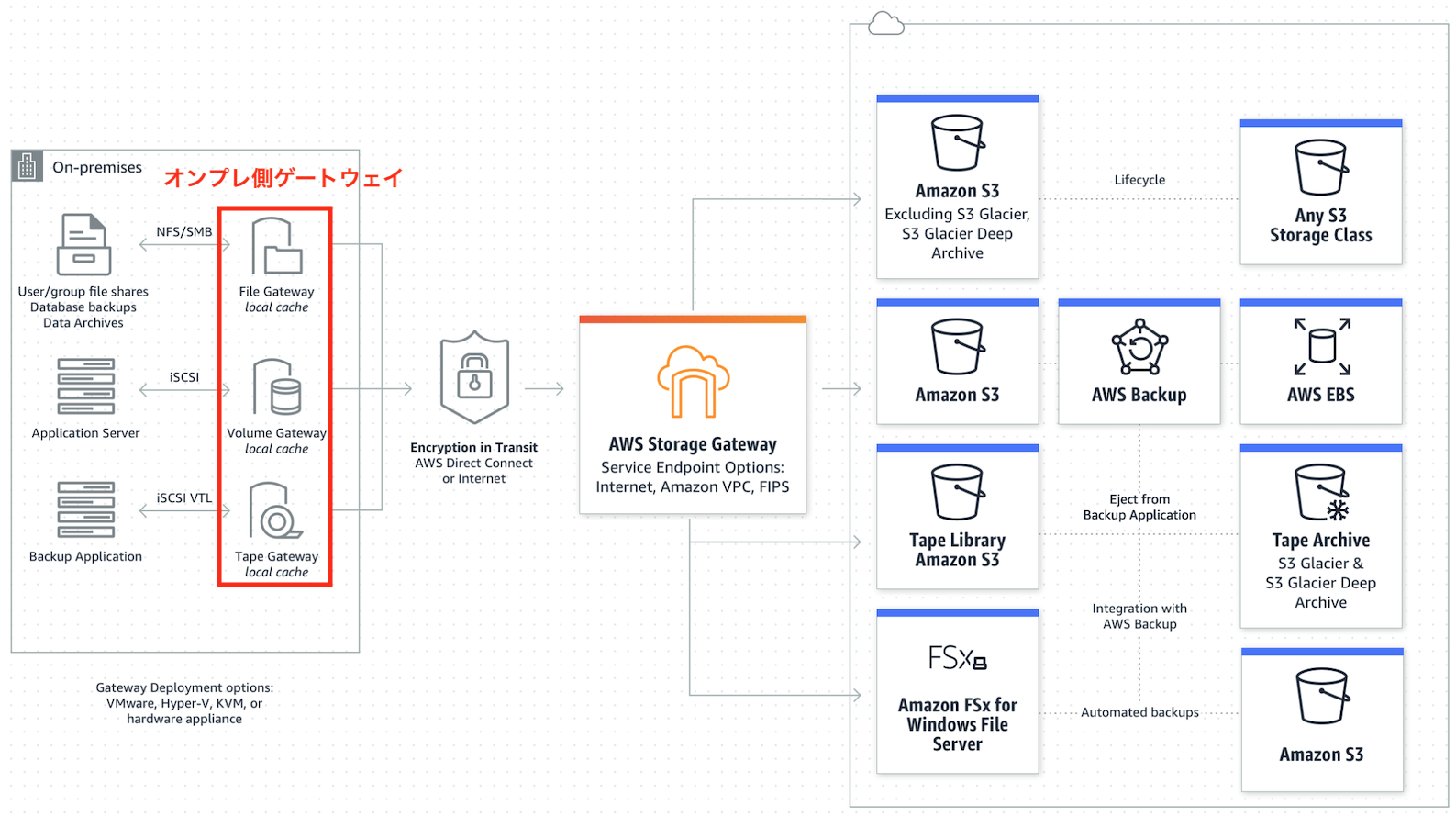
用途に応じてオンプレ側のゲートウェイの種類を以下から選択します
| ゲートウェイ名 | オンプレ側の接続プロトコル | 主な想定用途 |
|---|---|---|
| ファイルゲートウェイ | NFS, SMB | ファイルサーバ |
| ボリュームゲートウェイ | iSCSI | アプリケーションサーバのストレージ |
| テープゲートウェイ | iSCSI VTL | バックアップ |
それぞれ解説します
・ファイルゲートウェイ
ファイルサーバのプロトコルとしてよく利用されるNFS、SMBを用い、オンプレサーバからS3上にファイルを保存する事ができます(S3のオブジェクトとして保存される)。これによりS3をネットワーク上のファイルサーバ、すなわちNASのように使う事ができます。
S3を用いることでオンプレのNASと比べ、容量が無制限になる事や維持管理の手間を低減できる事がメリットとしてあげられます。
ファイルゲートウェイには「S3 ファイルゲートウェイ」「FSx ファイルゲートウェイ」がありますが、クラウド側のストレージにS3を用いる場合は前者を、Windowsのファイルシステム(Amazon FSx for Windows)を用いる場合は後者を使用します。
またS3のようなクラウドストレージへのアクセスはインターネットを経由するため、原理上どうしても速度が落ちて(レイテンシが長くなって)しまいますが、オンプレ側のファイルゲートウェイにキャッシュを設けてよく使うデータを格納しておく事で、この速度低下を防ぐ事ができます。
・ボリュームゲートウェイ
テープストレージによるバックアップで一般的に用いられるiSCSI VTLを用いて、仮想的なテープストレージをS3上に構築する事ができます。長期バックアップ用途を想定しており、オンプレミスアプリケーションを書き直す事なくストレージをS3に置き換えられる事がメリットして挙げられます。
ファイルゲートウェイと同様に、キャッシュを用いる事でよく使うデータのアクセス速度を向上させる事もできます。
・テープゲートウェイ
iSCSIプロトコルを用いて、オンプレ側からファイルをS3上のオブジェクトとして保存する事ができます。主にアプリケーションサーバのストレージとしての用途を想定しており、既存のバックアップワークフローを変更することなく、バックアップ用のテープストレージをS3に置き換えられる事がメリットしてあげられます。
ファイルゲートウェイと同様に、キャッシュを用いる事でよく使うデータのアクセス速度を向上させる事もできます。
S3とコスト
S3はEC2やFargateのようなコンピューティングサービスと比べると低料金で利用できる場合が多いですが、それでも大量のデータを保持するとそれなりのコストが掛かります。
具体的には、以下のリソース・操作にコストがかかります
- ストレージ
- リクエストとデータ取り出し
- データ転送 (外向き通信のみ。内向き通信は無料)
- 管理と分析 (ストレージクラス分析等)
- レプリケーション
- S3 Object Lambda
上記コストはストレージクラスごとに異なるため、以下に重要項目を抜粋して記載します。
ざっくり把握しておくと良いでしょう。
| 名称 | 東京リージョンでのストレージ料金(2022/7) | 最低利用期間 | データ取り出し | GETリクエスト(1000リクエストあたり) | POSTリクエスト(1000リクエストあたり) |
|---|---|---|---|---|---|
| S3 標準 | 0.023-0.025USD/GB月 | なし | 無料 | 0.00037USD | 0.0047USD |
| S3 標準IA | 0.0138USD/GB月 | 30日 | 0.01USD/GB | 0.001USD | 0.01USD |
| S3 Intelligent-Tiering | 0.002-0.025USD/GB月(階層により変化) | 30日 | 無料(アーカイブアクセス迅速取出以外) | 0.00037USD | 0.0047USD |
| S3 1ゾーンIA | 0.011USD/GB月 | 30日 | 0.01USD/GB | 0.001USD | 0.01USD |
| S3 Glacier Instant Retrieval | 0.005USD/GB月 | 90日 | 0.03USD/GB | 0.01USD | 0.02USD |
| S3 Glacier Flexible Retrieval | 0.0045USD/GB月 | 90日 | 0.011-0.033USD/GB | 0.0037USD | 0.03426USD |
| S3 Glacier Deep Archive | 0.002USD/GB月 | 180日 | 0.005-0.022USD/GB | 0.0037USD | 0.065USD |
上表以外にも、PUT等のHTTPリクエストや無料枠100GBを超えるインターネットへのデータ転送、レプリケーション等にも料金がかかります。詳細は以下の公式ドキュメントを参照ください
コスト削減のためには、適切なストレージクラスを選択したり、前述のIntelligent-Tieringやライフサイクルルールの活用が有効です。
コスト削減施策を検討する上で現状のコスト分析が重要となるため、以下で解説します。
コスト削減に利用できる分析機能
適切なライフサイクルールやストレージクラスの設定を判断するには、以下のストレージクラス分析、Storage Lensによる分析が便利です。
ストレージクラス分析
バケット内のオブジェクトへのアクセス頻度を分析し、適切なライフサイクルルールやストレージクラス選択の参考にする事ができます。
アクセス頻度が対象という特性上、特にライフサイクルルールにおけるS3 標準から下位のバケットへの移行タイミングを判断する上で便利な機能です
(例: アクセス頻度が減ってくるタイミングをS3 標準からS3 標準IAへの移行タイミングとする)
詳細は以下の記事を参照ください
Storage Lens
Storage Lensは、リージョン、ストレージクラス、バケット、およびプレフィックス別に、格納されたデータに対する各種統計情報をダッシュボードで可視化できる機能です。
例えば、デフォルトで準備されているダッシュボードでは、下図のように合計容量、オブジェクト数等が表示されます。

格納されたデータのサマリーを効率よく確認できるよう、自作のダッシュボードを作成すると便利でしょう
詳細は以下の記事が参考になります。
リクエスタ支払い
リクエスト関係の料金 (上記GET、POSTなど)は、通常はバケットを保有するアカウントに請求されます。
これに対し、リクエストを実行したアカウントに請求する仕組みを、リクエスト支払いと呼びます。
リクエスタ支払いは後述のバケット設定画面から設定する事ができます。
S3コンソール画面の見方
AWSコンソールにログインしてS3のサービスに入ると、以下のような画面が表示されます。

S3の操作は基本的に上図の「左側のタブ」(ナビゲーションペイン)から行うため、各項目について解説します。
バケット
バケットの一覧が表示されています。

S3の機能の多くは、このバケットの設定画面から指定することで実現できるため、詳細を解説します。
バケットの設定画面は、以下の6つのタブからなります

・タブ一覧
| タブ名 | サブ項目 |
|---|---|
| オブジェクト | オブジェクト |
| プロパティ | バケットの概要 バケットのバージョニング タグ デフォルトの暗号化 Intelligent-Tiering Archive設定 サーバーアクセスのログ記録 AWS CloudTrail データイベント イベント通知 Transfer Acceleration オブジェクトロック リクエスタ支払い 静的ウェブサイトホスティング |
| アクセス許可 | アクセス許可の概要 ブロックパブリックアクセス バケットポリシー オブジェクト所有者 ACL CORS |
| メトリクス | バケットメトリクス ストレージクラス分析 レプリケーションメトリクス |
| 管理 | ライフサイクルルール レプリケーションルール インベントリ設定 |
| アクセスポイント | アクセスポイント |
タブ毎に内容を解説します
「オブジェクト」タブ
バケット直下のオブジェクト、フォルダを一覧表示します。
フォルダ名をクリックすると、フォルダ内のオブジェクト、フォルダが再帰的に表示されます。

「プロパティ」タブ
バケットに関する各種設定を変更できます。
セキュリティ、メトリクス、ライフサイクル系以外の機能はここから設定可能です (以下一覧)
| サブ項目名 | 概要 |
|---|---|
| バケットの概要 | バケットのリージョン、ARN、作成日を表示 |
| バケットのバージョニング | バケットのバージョニングの有効無効を設定 |
| タグ | バケットにタグ付けして整理し、追跡や監視等に使用 |
| デフォルトの暗号化 | データの暗号化をデフォルトで適用するかを設定 |
| Intelligent-Tiering Archive設定 | S3 Intelligent-Tieringストレージクラスのオプション階層設定 |
| サーバーアクセスのログ記録 | S3サーバーログの有効無効を設定 |
| AWS CloudTrail データイベント | CloudTrailによるログ記録の作成と管理を実施 |
| イベント通知 | バケット内のイベント発生をトリガーとしたLambda,SNS,SQSによる自動処理実行を設定 |
| Transfer Acceleration | Transfer Accelerationによるバケットへのデータアップロード高速化有無を設定 |
| オブジェクトロック | オブジェクトロックの有無を確認 |
| リクエスタ支払い | リクエスタ支払いの有効無効を設定 |
| 静的ウェブサイトホスティング | 静的ウェブサイトホスティングの有効無効を設定 |
それぞれ解説します
・バケットの概要
バケットのリージョン、ARN、作成日を表示します

・バケットのバージョニング
前述のバケットのバージョニングの有効無効を設定します。

MFA Deleteはコンソールからは設定できず、CLIからの設定が必要です (参考)
・タグ
バケットにタグ付けして整理することで、ストレージコストやその他の基準追跡に利用できます。
・デフォルトの暗号化
データの暗号化をデフォルトで適用するかを設定できます。

設定可能な項目は以下となります。
- 指定できるのはSSE-S3およびSSE-KMSのみ (SSE-Cおよびクライアント側の暗号化は指定不可)
- SSE-KMSを指定した場合、AWS管理キー、カスタマーマネージドキーから鍵を選択可
- SSE-KMSを指定した場合、 S3バケットキーを指定可 (上図の「バケットキー」が相当)
暗号化を有効にした場合、新たにアップロードされたオブジェクトに指定した暗号化が適用されますが、有効化前から存在するオブジェクトには暗号化が適用されません (このような暗号化されないオブジェクトは、バッチオペレーションによる暗号化が便利です)
・Intelligent-Tiering Archive設定
S3 Intelligent-Tieringストレージクラスにおいてオプション指定となっている「アーカイブアクセス階層」「ディープアーカイブアクセス階層」の有効無効を設定できます。

有効とした場合、以下の項目を設定する事ができます
- プレフィックスによる対象フォルダの限定
- タグによる対象オブジェクトの限定
- 対象階層に移行するまでの日数
・サーバーアクセスのログ記録
アクセスログの記録のうち、S3サーバーログの有効無効を指定する

・AWS CloudTrailデータイベント
アクセスログの記録のうち、CloudTrailによるログ記録の作成と管理を実施します。
「CloudTrailで設定する」をクリックするとCloudTrailのコンソール画面に飛ぶので、「証跡の作成」をクリックして保存先のバケットやKMSエイリアスを指定したのち、
以下の「ログイベントの選択」から
- イベントタイプ:データイベント
- データイベントタイプ:S3
を選択する事で、CloudTrailによるログ記録を実現できます

・イベント通知
前述のイベント通知を作成・一覧表示・変更します。
・Transfer Acceleration
前述のTransfer Accelerationの有効無効を設定できます。
・オブジェクトロック
オブジェクトロックの有無を確認できます
オブジェクトロックの有無指定はバケット作成時のみ設定できるため、本項目では確認のみ可能です。
・リクエスタ支払い
前述のリクエスタ支払いの有効無効を設定できます。
・静的ウェブサイトホスティング
静的ウェブサイトホスティングの有効無効を設定できます。
「アクセス許可」タブ
以下のセキュリティ関係の設定を行います。
| サブ項目名 | 概要 |
|---|---|
| アクセス許可の概要 | バケットが外部に公開されているかを表示 |
| ブロックパブリックアクセス | ブロックパブリックアクセスの有効無効を設定 |
| バケットポリシー | バケットポリシーを作成・変更 |
| オブジェクト所有者 | ACLの有効無効を設定。有効の場合はオブジェクトの所有者を選択 |
| アクセスコントロールリスト (ACL) | ACLによるアクセス制御を設定 |
| Cross-Origin Resource Sharing (CORS) | CORS設定を作成・変更する |
・アクセス許可の概要
バケットが外部に公開されているかを表示します。
以下の3パターンの表示でバケットの公開状況を確認する事ができます(各状態の違いはこちらの記事を参照下さい)
・ブロックパブリックアクセスが設定されている場合(バケットは一般公開されない)

・ブロックパブリックアクセスが設定されていないが、ポリシーやACLでパブリックアクセスが無効化されている場合(バケットは一般公開されない)

・ブロックパブリックアクセスが設定されておらず、ポリシーやACLでもパブリックアクセスが有効化されている場合(バケットは一般公開されている)

・ブロックパブリックアクセス
ブロックパブリックアクセスの有効無効を設定します
・バケットポリシー
バケットポリシーを作成・変更します
・オブジェクト所有者
ACLの有効無効を設定します。

ACL有効を指定した場合、オブジェクトの所有者を以下のどちらにするか選択できます。
- 希望するバケット所有者: バケットの所有者がオブジェクト所有者となる
- オブジェクトライター: オブジェクトをアップロードしたAWSアカウントがオブジェクト所有者となる
・アクセスコントロールリスト (ACL)
ACLによる各AWSアカウントへのアクセス権付与を変更します
・Cross-Origin Resource Sharing (CORS)
前述のCORS (Cross-Origin Resource Sharing)設定を作成・変更します
「メトリクス」タブ
バケット内の状況を簡単に可視化、分析することができます(詳細に分析したい場合は後述のStorage Lensを使用してください)
・バケットメトリクス
バケット内のデータ量やオブジェクト数を、ストレージクラス毎にダッシュボード表示します
・ストレージクラス分析
前述のストレージクラス分析を作成・変更します
バケット内のオブジェクトへのアクセス頻度を分析し、適切なストレージクラス選択の参考にする事ができます。
詳細は以下の記事を参照ください
・レプリケーションメトリクス
レプリケーションルール作成時に「レプリケーションメトリクスと通知」をチェックした場合、レプリケーションの進捗状況をモニタリングする事ができます。
「管理」タブ
各種ルールの管理を行えます
・ライフサイクルルール
ライフサイクルルールを作成・変更します
・レプリケーションルール
クロスリージョンレプリケーションを実行するルールを、作成・変更します
・インベントリ設定
前述のS3 Inventoryを作成・一覧表示・変更します。
「アクセスポイント」タブ
S3アクセスポイントを作成・変更します。
基本的には後述するナビゲーションペインの「アクセスポイント」と同内容の設定が行えますが、該当バケットに紐づけられたアクセスポイントのみに表示がフィルタリングされています。
アクセスポイント
S3アクセスポイントの作成、一覧表示、設定を行います。
オブジェクトLambdaアクセスポイント
前述のオブジェクトLambdaアクセスポイントを作成・一覧表示・変更します。
マルチリージョンアクセスポイント
マルチリージョンアクセスポイントの作成、一覧表示、設定を行います。
バッチオペレーション
前述のバッチオペレーションを作成・一覧表示・変更します。
S3のアクセスアナライザー
S3のアクセスアナライザーにより、セキュリティリスクの高いバケットを検知できます。
IAM Access Analyzer for S3と表示される事もあるようです。
このアカウントのブロックパブリックアクセス設定
ブロックパブリックアクセスを許可するかを、アカウント一括で設定できます。
通常のブロックパブリックアクセスと同様、以下のようにACLとポリシー(バケットポリシーまたはアクセスポイント)に分けてブロックの有無を指定する事ができます

パブリックアクセスはダブルチェック(ブロックパブリックアクセス+ポリシーまたはACLによるアクセス制御)に加え、本項目でアカウント全体でのパブリックアクセスを禁止する事もできるため、実質的にはトリプルチェック体制と言えます。
Storage Lens
ダッシュボード
前述のStorage Lensによる格納データの統計情報可視化ダッシュボードを作成、編集、閲覧できます。
AWS Organitazionsの設定
Storage Lensを使用し、AWS Organitazions使用時に複数のアカウントのS3の状況を一括で確認することができます
注目機能
新機能追加時にこちらで通知がされます
S3のAWS Marketplace
サードパーティのS3関係ツールを購入する事ができます
S3の操作方法
S3に実際にアクセスし、バケットやオブジェクトの操作、ファイルのアップロード等を実施する方法を解説します。
本記事ではS3を操作する方法としてよく利用される、以下の3種類の方法を解説します(他にもREST APIでのアクセス等が可能ですが、本記事では割愛します)
| 名称 | S3の操作方法 |
|---|---|
| コンソール | AWSのコンソール(WebUI)上から操作する |
| CLI | Powershellやbash等のシェルから操作する |
| Python SDK (Boto3) | Pythonのスクリプトから操作する(他のプログラミング言語のSDKも存在しますが、本記事では割愛します) |
順を追って説明します
AWSの登録とIAMユーザ作成
まずはS3使用の準備としてAWSへの登録とIAMユーザの作成を行います。
AWSへの登録自体はこちらを参照ください。
次にS3の操作権限を持ったIdentity and Access Management (IAM)ユーザを作成します。
ルートユーザでログインして、コンソールからIAM → ユーザーと進み、「ユーザを追加」をクリックします

好きなユーザ名とパスワードを入力し、アクセスキー(プログラムやCLI)とパスワード(GUIコンソール)によるアクセスを有効にします
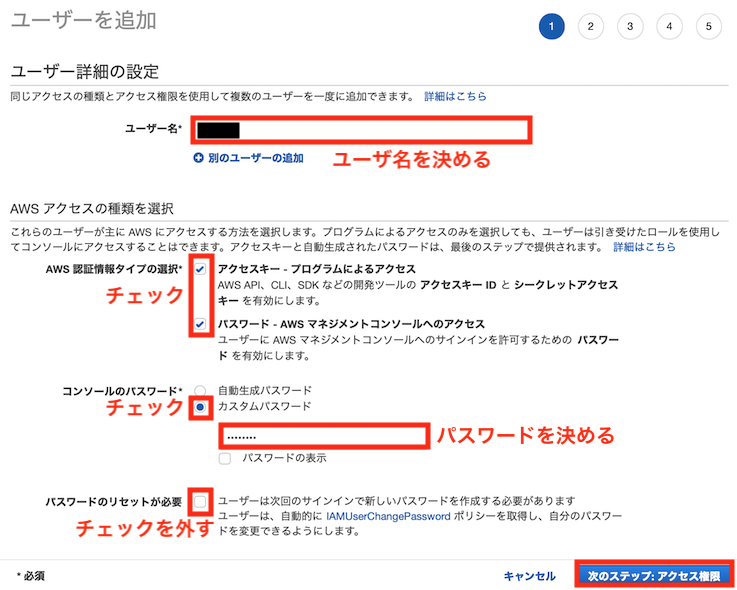
S3にアクセスするためのポリシーを設定します(下の例ではS3以外もアクセスできるよう管理者権限であるAdministratorAccessを付与していますが、IAMベストプラクティスの最小権限の原則に則るのであれば、S3のフルアクセス権限であるAmazonS3FullAccessを設定した方が良いかと思います)

タグを設定し(未記入でもOK)、「ユーザの作成」をクリックします。
ユーザ作成後に出てくる以下のアクセスキーIDとシークレットアクセスキーをメモしてください
(メモを忘れたら後で再作成が必要です)

以降は、以下の操作方法に応じてリンク先の操作方法を参照ください
コンソール
コンソール (AWSマネジメントコンソール)とは、ブラウザ上からでGUIでAWSの各種サービスを操作できるWebアプリで、AWSの操作法として最も一般的に使用されます。
以下、コンソールによるS3の操作法を解説します。
バケットの作成
先ほど作成したユーザでAWSコンソールにサインインし、画面上の検索BOXから「S3」と検索し、S3のコンソールに移動します
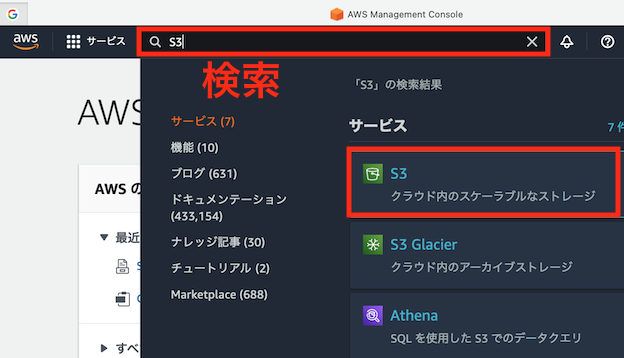
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、「バケットの作成」をクリックします

以下のように、作成するバケットの各種設定を選択し、「」


各種設定をそれぞれ解説します
・一般的な設定
バケット名、リージョンを選択します。
なお、バケット名は世界中で一意である必要があるのでご注意ください
また、「既存のバケットから設定をコピー」をクリックすると、他バケットの設定をコピーして移行の設定入力を簡略化することができます
・オブジェクト所有者
ACLの有効無効を設定し、有効を指定した場合はオブジェクトの所有者をバケット所有者とオブジェクト投稿者のどちらにするかを選択できます。
詳細は「バケットの設定」におけるオブジェクト所有者と同じなので、こちらをご参照ください
・ブロックパブリックアクセス
前述のブロックパブリックアクセスの有効無効を設定します。
「バケットの設定」におけるブロックパブリックアクセスと同じです
・バケットのバージョニング
前述のバケットのバージョニングの有効無効を設定します。
詳細は「バケットの設定」におけるバケットのバージョニングと同じなので、こちらをご参照ください
・タグ
バケットにタグ付けして整理することで、ストレージコストやその他の基準追跡に利用できます。
・デフォルトの暗号化
データの暗号化をデフォルトで適用するかを設定できます。
詳細は「バケットの設定」におけるデフォルトの暗号化と同じなので、こちらをご参照ください
・詳細設定
オブジェクトロックが設定できます。
バケットの削除
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、削除したいバケットを選択したのち「削除」をクリックします

バケット内にオブジェクトが存在する場合、そのままでは削除できないので「空のバケット設定」をクリックする

「完全に削除」と入力し、「空にする」をクリックしてバケット内のオブジェクトを全削除

再びバケットの削除画面に戻り、バケット名を入力して「バケットを削除」をクリックします

バケットの設定
バケットの各種設定を変更したい場合、前述のバケットの設定を参照ください。
フォルダの作成
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、フォルダを追加したいバケットをクリックしてバケットの設定画面に入ります
「フォルダの作成」をクリックします

作成したフォルダ名とデフォルトの暗号化方法を指定し、「フォルダの作成」をクリックします

オブジェクトの追加 (アップロード)
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、フォルダを追加したいバケットをクリックしてバケットの設定画面に入ります
「アップロード」をクリックします

「ファイルを追加」をクリックするとダイアログが開くのでアップロードしたいファイルを選択し、「プロパティ」からストレージクラスや暗号化方法を選択したのち (無選択ならバケットのデフォルト設定が適用される)、「アップロード」をクリックします

オブジェクトの取得 (ダウンロード)
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、操作したいバケットをクリックしてバケットの設定画面に入ります
ダウンロードしたいオブジェクトを選択して「ダウンロード」をクリックします

オブジェクトの削除
ナビゲーションペイン (左側のタブ)の「バケット」を選択し、操作したいバケットをクリックしてバケットの設定画面に入ります
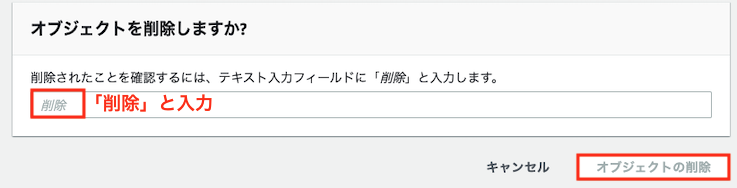
削除したいオブジェクトを選択し、「削除」をクリックします

「削除」と入力し、「オブジェクトの削除」をクリックする
CLI
CLI (AWS コマンドラインインターフェイス)とは、CUIでAWSの各種サービスを操作できるツールです。
GUIで操作するコンソールと比べ、熟練者によるスピーディーな操作や、処理の自動化に優れた方法と言えます。
CLIでS3を操作する場合、以下の2通りの方法が存在します
- 高レベル(s3)コマンド: 簡単なコマンドで処理を実現できる
- APIレベル(s3 api)コマンド: より長いコマンドで詳細な処理を実現できる
本記事では、高レベルコマンドによるS3の操作法を解説します (参考)
本記事で紹介しないAPIレベルコマンドについては、以下の公式ドキュメントを参照してください
CLIのインストール
・CLIアプリのインストール
CLIを利用するためには、使用するPCへのCLIアプリのインストールが必要です。
以下のページを参考に、OSに応じたインストール法を選択してください
※なお、以下の方法いずれかで、インストール不要でCLIを利用することができます
- コンソールからCloudShellを起動
- Amazon Linux AMIを選択したEC2インスタンスを利用(最初からCLIがインストールされている)
・ アクセスキーの入手
※本操作は、IAMユーザ作成時にアクセスキーを作成・取得済であれば不要です。忘れた場合は以下の方法で再作成してください(古いキーの情報は残しておくと危険なので削除してください)
※CLIをローカルPCではなくEC2やFargate等のAWS内リソースから利用する場合、本節で紹介するアクセスキーではなくロールを使用する事がセキュリティ上望ましいです。こちらを参照下さい。
先ほど作成したIAMユーザでコンソールにログインし、IAM → ユーザ → 先ほど作成したユーザ → 「認証情報」タブに移動し、「アクセスキーの作成」をクリックします。

アクセスキーを作成して出てきたアクセスキーIDとシークレットアクセスキーをメモします
・AWS CLIのインストールとアクセスキーの登録
AWSをコマンドラインから操作するためのAWS CLIを、クライアントPCに以下を参考にインストールしてください
インストールが完了したら、ターミナル(Windowsの場合Powershell)から以下のコマンドを打ち
aws configure
以下のように入力します
AWS Access Key ID [None]: [アクセスキーID]
AWS Secret Access Key [None]: [先ほどメモしたシークレットアクセスキー]
Default region name [None]: ap-northeast-1
Default output format [None]: [空欄でOK]
「~/.aws/credentials」と「~/.aws/config」に入力したクレデンシャル情報(アクセスキーやリージョン)が生成していれば成功です。
CLIコマンド一覧(S3 高レベルコマンド)
| 操作 | コマンド |
|---|---|
| バケット一覧表示 | aws s3 ls |
| バケットの作成 | aws s3 mb s3://バケット名 |
| バケットの削除 | aws s3 rb s3://バケット名 |
| バケットの設定 | リンク先参照 |
| オブジェクトの一覧表示 | aws s3 ls s3://バケット名 |
| オブジェクトのアップロード | aws s3 cp [ローカルファイルのパス] s3://バケット名 |
| オブジェクトのダウンロード | aws s3 cp s3://バケット名/オブジェクトのキー [ローカルフォルダのパス] |
| オブジェクトの削除 | aws s3 rm s3://バケット名/オブジェクトのキー |
| オブジェクトのコピー | aws s3 cp s3://コピー元バケット名/コピー元オブジェクトのキー s3://コピー先バケット名/コピー先フォルダ名/ |
| オブジェクトの移動 | aws s3 mv s3://移動元バケット名/移動元オブジェクトのキー s3://移動先バケット名/移動先フォルダ名/ |
| バケットの同期 | aws s3 sync s3://同期元バケット名 s3://同期先バケット名 |
それぞれのコマンドを簡単に解説します
※以降の操作は先ほど作成したユーザー (アクセスキーと紐づいたユーザー)に適切なポリシーが設定されていないと実行できません。エラーが出る場合、まずこちらを参考にポリシーの設定を再確認してください
バケット一覧表示
以下コマンドでアカウント内のバケットを一覧表示できます
aws s3 ls
バケットの作成
以下コマンドでバケットを作成できます
aws s3 mb s3://バケット名
バケットの削除
以下コマンドでバケットを削除できます
aws s3 rb s3://バケット名
バケットの設定
バケットの設定にはAPIレベルコマンドが必要となるため、以下の公式コマンドリファレンスを参照してください
オブジェクトの一覧表示
以下コマンドでバケット内のオブジェクトを一覧表示できます
aws s3 ls s3://バケット名
以下コマンドでフォルダ内のオブジェクトを一覧表示できます
aws s3 ls s3://バケット名/フォルダ名/
オブジェクトの追加 (アップロード)
cpコマンドは、オブジェクトの移動に使用します。
以下コマンドでローカルからS3バケットにオブジェクトをアップロードできます。
aws s3 cp [アップロードしたいローカルファイルのパス] s3://バケット名
以下コマンドでフォルダ内にアップロードすることもできます (最後の/を忘れないよう注意、存在しないフォルダ名ならフォルダが自動作成される)
aws s3 cp [アップロードしたいローカルファイルのパス] s3://バケット名/フォルダ名/
オブジェクトの取得 (ダウンロード)
以下コマンドでS3バケットからローカルにオブジェクトをダウンロードできます。
aws s3 cp s3://バケット名/オブジェクトのキー [ダウンロード先のローカルフォルダのパス]
オブジェクトの削除
以下コマンドでオブジェクトを削除できます
aws s3 rm s3://バケット名/オブジェクトのキー
--recursiveオプションを付加することで、バケット内またはフォルダ内全てのオブジェクトを
aws s3 rm s3://バケット名 --recursive
aws s3 rm s3://バケット名/フォルダ名 --recursive
オブジェクトのコピー
以下コマンドでバケット同士でオブジェクトをコピーできます (コピー先のフォルダ名が存在しなければフォルダが自動作成される)
aws s3 cp s3://コピー元バケット名/コピー元オブジェクトのキー s3://コピー先バケット名/コピー先フォルダ名/
以下コマンドでバケット内のオブジェクトを丸ごとコピーできます
aws s3 cp s3://コピー元バケット名 s3://コピー先バケット名 --recursive
以下コマンドでフォルダ内のオブジェクトを丸ごとコピーできます
aws s3 cp s3://コピー元バケット名/コピー元フォルダ名 s3://コピー先バケット名/コピー先フォルダ名/ --recursive
オブジェクトの移動
以下コマンドでバケット同士でオブジェクトを移動できます (移動先のフォルダ名が存在しなければフォルダが自動作成される)
aws s3 mv s3://移動元バケット名/移動元オブジェクトのキー s3://移動先バケット名/移動先フォルダ名/
以下コマンドでバケット内のオブジェクトを丸ごと移動できます
aws s3 mv s3://移動元バケット名 s3://移動先バケット名 --recursive
以下コマンドでフォルダを丸ごと移動できます
aws s3 mv s3://移動元バケット名/移動元フォルダ名 s3://移動先バケット名/移動先フォルダ名/ --recursive
バケットの同期
syncコマンドで、バケット同士やローカルとバケットを同期し、同一オブジェクトを保持する事ができます。
なお、ここでいう「同期」はコンソールからのレプリケーションとは異なるので、以下の記事をご参照ください。基本的には「同期」は最初の1回のみ実施され、レプリケーションは定期的に実行されるようです
以下コマンドでローカルフォルダとバケットを同期することができます
(通常削除処理は同期されませんが、--deleteオプションを付けることで削除も同期されるようになります)
aws s3 sync [同期元ローカルフォルダのパス] s3://バケット名
以下コマンドでバケット内の特定のフォルダのみを同期対象とする事ができます
aws s3 sync [同期元ローカルフォルダのパス] s3://バケット名/フォルダ名
以下コマンドでバケット同士を同期することができます
aws s3 sync s3://同期元バケット名 s3://同期先バケット名
以下コマンドでバケット内の特定のフォルダのみを同期する事ができます
aws s3 sync s3://同期元バケット名/フォルダ名 s3://同期先バケット名/フォルダ名
Python SDK (Boto3)
Boto3とは、PythonからAWSのリソースを操作するためのライブラリ (SDK)です。
S3に限らず、「PythonからAWSをいじりたい!」という場合はこのBoto3を使用するのが一般的です。
Boto3のインストール
・AWS CLIのインストールとアクセスキーの登録
Boto3をインストールするためには、AWS CLIのインストールとアクセスキーの登録がまず必要となります。
本記事のCLIのインストール、アクセスキーの入手、AWS CLIのインストールとアクセスキーの登録を参考に、インストールを進めてください
・Boto3のインストール
ローカルPC上で以下コマンドでboto3をインストールします
・pipの場合
pip install boto3
・condaの場合
conda install boto3
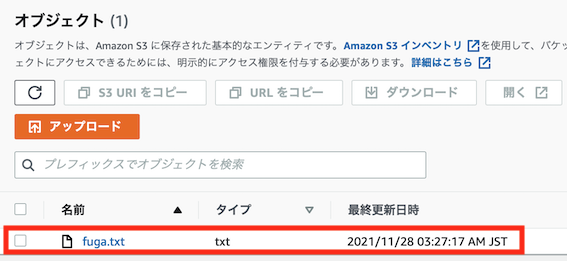
・Boto3によるPythonからS3へのアップロード動作確認
ローカルPC上で以下のようなコードを動作させ、S3へデータがアップロードできるか確認します
import boto3
import os
# アップロード用のテキストファイル作成
text = "rooms, zipcode, median_price, school_rating, transport"
text_path = 'fuga.txt'
with open(text_path, "w") as f:
f.write(text)
# S3にアップロード
s3 = boto3.resource('s3')
bucket = s3.Bucket('[S3のバケット名]')
bucket.upload_file(text_path, text_path)
os.remove(text_path)
該当S3バケットにファイルがアップロードされていれば成功です
Boto3の基本的な使い方
クライアントAPIとリソースAPI
Boto3では、AWS内のリソースを操作するためのスクリプト記述方法としてクライアントAPIとリソースAPIの2種類が準備されています。公式ドキュメントにはその違いは以下のように記載されています。
Boto3 には、2 つの異なるレベルの API があります。クライアント(「低レベル」)API では、下層の HTTP API 操作との 1 対 1 のマッピングが提供されます。 リソース API では、明示的なネットワーク呼び出しが表示されず、属性にアクセスしアクションを実行するためのリソースオブジェクトとコレクションが提供されます。(例:
上記説明だけでは分かりづらいですが、以下の記事の解説も読むと理解が進むかと思います。
端的に言うと、以下のように解釈できそうです。
- クライアントAPI: REST APIに準じた(=前述のCLIと似た)操作が可能
- リソースAPI: AWSリソース(S3バケット等)をオブジェクト指向のインスタンスとして操作できる
筆者(私)の解釈が入りますが、それぞれのメリットとデメリットは以下のように位置付けられそうです(一般論としてのREST APIとオブジェクト指向のメリット/デメリットに基づいています)
| 概要 | メリット | デメリット | |
|---|---|---|---|
| クライアントAPI | AWSリソースをREST APIとに準じた方法で操作できる | 各操作を独立して行えるため、前に実行した操作の影響を受けづらい | 操作毎にリソースを逐次指定しないといけないため、コードが冗長になりがち |
| リソースAPI | AWSリソースをオブジェクト指向のインスタンスとして操作する | 一度インスタンス化したリソースはメソッドで操作できるため、コードをシンプルにできる | 前に実行した操作の影響を受けやすい |
どちらを選択するかですが、正直個人の趣向レベルの話(公式でもどちらかを推奨しているわけではない)となりそうです。
あえて言うのであれば、オブジェクト指向言語と位置付けられる事の多いPythonらしいコードを書くのであれば、リソースAPIの方が相性は良さそうです。
クライアントAPIの基本的な使い方
リソースAPIの基本的な使い方
リソースAPIでは、基本的に以下のような階層構造を基に、上位側から順にインスタンスを作成していきます(オブジェクトへは、S3クラスから直接作成も、バケットインスタンスから作成する事もできます)
先ほどの動作確認で使用したコードもリソースAPIを使用しているので、こちらを例に解説します。
import boto3
# サービス(S3)を表すインスタンス作成
s3 = boto3.resource('s3')
# バケットインスタンス作成
bucket = s3.Bucket('[S3のバケット名]')
# オブジェクトをアップロードするメソッド(バケットインスタンスのメソッド)
bucket.upload_file(text_path, text_path)
上記のように、
- boto3クラスに含まれる
boto3.resource()メソッドでサービス(今回のケースではS3)を表すインスタンスを作成 - そのサービス内のリソースを表すインスタンス(今回のケースでは
Bucket)を作成
の順でリソース操作用のインスタンスを作成し、そのメソッドを呼び出す(今回のケースではupload_file())
boto3によるS3の操作法一覧
上記のように、クライアントAPIではboto3.client()、クライアントAPIではboto3.resource()メソッドを呼び出すことで、S3の操作用クラスを作成する事ができます。
※以降の操作は先ほど作成したユーザー (アクセスキーと紐づいたユーザー)に適切なポリシーが設定されていないと実行できません。エラーが出る場合、まずこちらを参考にポリシーの設定を再確認してください
| 操作 | クライエントAPIでの操作法 | リソースAPIでの操作法 |
|---|---|---|
| バケット一覧表示 | list_buckets() |
- |
| バケットの作成 | create_buckets() |
Bucket.create() |
| バケットの削除 | delete_bucket() |
Bucket.delete() |
| オブジェクトの一覧表示 | list_objects() |
Bucket.objects |
| オブジェクトのアップロード | upload_file() |
Bucket.upload_file() |
| オブジェクトのダウンロード | download_file() |
Bucket.download_file() |
| オブジェクトの削除 | delete_object() |
Bucket.delete_objects() |
| オブジェクトのコピー | copy_object() |
Bucket.copy() |
| オブジェクトの移動 |
copy_object() + delete_object()
|
Bucket.copy() + Bucket.delete_objects()
|
それぞれのコマンドを簡単に解説します
※以降の操作は先ほど作成したユーザー (アクセスキーと紐づいたユーザー)に適切なポリシーが設定されていないと実行できません。エラーが出る場合まずポリシーの設定を再確認してください
バケット一覧表示
クライエントAPI
以下のように、list_buckets()メソッドでアカウント内のバケットを一覧表示できます
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
s3client.list_buckets() # バケット一覧表示
リソースAPI
私が調べた限りでは、リソースAPIでアカウント内のバケットを一覧表示できるメソッドは見つかりませんでした。クライエントAPIを使用してください。
バケットの作成
クライエントAPI
以下のように、create_buckets()メソッドでバケットを作成できます(対応リージョンに限りがあるので、以下APIリファレンスを参照ください)
mport boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# バケット作成
s3client.s3.create_bucket(Bucket='[S3のバケット名]',
CreateBucketConfiguration={'LocationConstraint': 'ap-northeast-1'})
Bucket引数でバケット名を、CreateBucketConfiguration引数でリージョンを指定できます。その他の引数は上記APIリファレンスを参照ください。
リソースAPI
以下のように、Bucketクラス内のcreate()メソッドでバケットを作成できます(対応リージョンに限りがあるので、以下APIリファレンスを参照ください)
mport boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('[S3のバケット名]') # バケットインスタンス作成
# バケット作成
bucket.create(
CreateBucketConfiguration={'LocationConstraint': 'ap-northeast-1'})
CreateBucketConfiguration引数でリージョンを指定できます。その他の引数は上記APIリファレンスを参照ください。
バケットの削除
クライエントAPI
以下のように、delete_bucket()メソッドでバケットを削除できます
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# バケット削除
s3client.delete_bucket(Bucket='[S3のバケット名]')
リソースAPI
以下のように、Bucketクラス内のdelete()メソッドでバケットを削除できます
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('[S3のバケット名]') # バケットインスタンス作成
# バケット削除
bucket.delete()
オブジェクトの一覧表示
クライエントAPI
以下のように、list_objects()メソッドでバケット内のオブジェクト一覧を取得する事ができます
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# オブジェクトの一覧表示
response = s3client.list_objects(Bucket='[S3のバケット名]')
得られる出力(上記スクリプトのresponse)は以下のようになります。'Contents'にキーやストレージクラス等のオブジェクト内容が格納されています。
{
'Contents': [
{
'ETag': '"70ee1738b6b21e2c8a43f3a5ab0eee71"',
'Key': 'example1.jpg',
'LastModified': datetime(2014, 11, 21, 19, 40, 5, 4, 325, 0),
'Owner': {
'DisplayName': 'myname',
'ID': '12345example25102679df27bb0ae12b3f85be6f290b936c4393484be31bebcc',
},
'Size': 11,
'StorageClass': 'STANDARD',
},
{
'ETag': '"9c8af9a76df052144598c115ef33e511"',
'Key': 'example2.jpg',
'LastModified': datetime(2013, 11, 15, 1, 10, 49, 4, 319, 0),
'Owner': {
'DisplayName': 'myname',
'ID': '12345example25102679df27bb0ae12b3f85be6f290b936c4393484be31bebcc',
},
'Size': 713193,
'StorageClass': 'STANDARD',
},
],
'NextMarker': 'eyJNYXJrZXIiOiBudWxsLCAiYm90b190cnVuY2F0ZV9hbW91bnQiOiAyfQ==',
'ResponseMetadata': {
'...': '...',
},
}
以下のようにfilter()メソッドを間に加える事で、フォルダ名等でフィルタを掛けてオブジェクト一覧を取得する事もできます。
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# オブジェクトの一覧表示
response = s3client.list_objects(Bucket='[S3のバケット名]', Prefix='[フォルダ名]/')
リソースAPI
以下のように、Bucketクラス内のobjectsコレクションからバケット内のオブジェクト一覧を取得できます。
以下のようにall()メソッドを後ろに続けることで、イテレーションとしてfor文で内容を取得できます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('[S3のバケット名]') # バケットインスタンス作成
# オブジェクトの一覧表示
for object in bucket.objects.all():
print(object.key) # オブジェクトのキーを表示
print(object.strage_class) # オブジェクトのストレージクラスを表示
以下のようにfilter()メソッドを間に加える事で、フォルダ名等でフィルタを掛けてオブジェクト一覧を取得する事もできます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('[S3のバケット名]') # バケットインスタンス作成
# オブジェクトの一覧表示
for object in bucket.objects.filter(Prefix='[フォルダ名]/').all():
print(object.key) # オブジェクトのキーを表示
print(object.storage_class) # オブジェクトのストレージクラスを表示
オブジェクトの追加 (アップロード)
クライエントAPI
以下のように、upload_file()メソッドでファイルをオブジェクトとしてS3にアップロードできます
import boto3
import os
# アップロード用のテキストファイル作成
text = "rooms, zipcode, median_price, school_rating, transport"
text_path = 'fuga.txt' # アップロード元のファイル名
with open(text_path, "w") as f:
f.write(text)
s3client = boto3.client('s3') # S3操作用インスタンス作成
# ファイルをオブジェクトとしてアップロード
s3client.upload_file(
Filename=text_path,
Bucket='バケット名',
Key='オブジェクト名')
os.remove(text_path) # 不要なファイルを削除
オブジェクト名にはhoge.txtのように保存したいキー名を指定します
以下のようにフォルダ(プレフィックス)名を指定することで、フォルダ内にアップロードする事もできます。
s3client.upload_file(
Filename=text_path,
Bucket='バケット名',
Key='フォルダ/オブジェクト名')
リソースAPI
以下のように、Bucketクラス内のupload_file()メソッドでバケットを削除できます
import boto3
import os
# アップロード用のテキストファイル作成
text = "rooms, zipcode, median_price, school_rating, transport"
text_path = 'fuga.txt' # アップロード元のファイル名
with open(text_path, "w") as f:
f.write(text)
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('バケット名') # バケットインスタンス作成
# ファイルをオブジェクトとしてアップロード
bucket.upload_file(
Filename=text_path,
Key='オブジェクト名')
os.remove(text_path) # 不要なファイルを削除
オブジェクト名にはhoge.txtのように保存したいキー名を指定します
以下のようにフォルダ(プレフィックス)名を指定することで、フォルダ内にアップロードする事もできます。
bucket.upload_file(
Filename=text_path,
Key='フォルダ名/オブジェクト名')
オブジェクトの取得 (ダウンロード)
クライエントAPI
以下のように、download_file()メソッドでファイルをオブジェクトとしてS3バケットにアップロードできます
import boto3
text_path = 'fuga.txt' # ダウンロード先のファイル名
s3client = boto3.client('s3') # S3操作用インスタンス作成
# ファイルをオブジェクトとしてアップロード
s3client.download_file(
Filename=text_path,
Bucket='バケット名',
Key='オブジェクト名')
オブジェクト名にはhoge.txtのようなダウンロード対象のオブジェクトのキー名を指定します
アップロード時と同様にKey='フォルダ名/オブジェクト名'とすることで、フォルダ(プレフィックス)指定してダウンロードする事もできます。
リソースAPI
以下のように、Bucketクラス内のdownload_file()メソッドでファイルをオブジェクトとしてS3バケットにアップロードできます
import boto3
text_path = 'fuga.txt' # ダウンロード先のファイル名
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('バケット名') # バケットインスタンス作成
# オブジェクトをファイルとしてダウンロード
bucket.download_file(
Filename=text_path,
Key='オブジェクト名')
オブジェクト名にはhoge.txtのようなダウンロード対象のオブジェクトのキー名を指定します
アップロード時と同様にKey='フォルダ名/オブジェクト名'とすることで、フォルダ(プレフィックス)指定してダウンロードする事もできます。
オブジェクトの削除
クライエントAPI
以下のように、delete_object()メソッドでオブジェクトを削除できます
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# オブジェクトをファイルとしてダウンロード
s3client.delete_object(
Bucket='バケット名',
Key='オブジェクト名')
オブジェクト名にはhoge.txtのようなダウンロード対象のオブジェクトのキー名を指定します
アップロード時と同様にKey='フォルダ名/オブジェクト名'とすることで、フォルダ(プレフィックス)指定してダウンロードする事もできます。
リソースAPI
以下のように、Bucketクラス内のdelete_objects()メソッドでオブジェクトを削除できます
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('バケット名') # バケットインスタンス作成
# オブジェクトを削除
bucket.delete_objects(
Delete={
'Objects': [{
'Key': 'オブジェクト名'
}]
})
クライエントAPIのdelete_object()メソッドでは単一のオブジェクトを指定していましたが、こちらのdelete_objects()メソッドでは複数のオブジェクトをリスト指定(もちろん1個だけの指定も可能です)することにご注意ください。
バケット内の全てのオブジェクトを削除したい場合
バケット内の全てのオブジェクトを削除したい場合、先ほどのオブジェクトの一覧表示で登場したobjectsコレクション(Objectクラスのdelete()メソッド)を用いて一括削除する事ができます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
bucket = s3resource.Bucket('バケット名') # バケットインスタンス作成
# バケット内の全オブジェクトの削除
for object in bucket.objects.all():
object.delete()
上記のように、イテレーションで簡単に複数のオブジェクトを操作できることも、リソースAPIのメリットの一つと言えそうです。
他にも先ほどのfilter()メソッドを間に加える事で、フォルダ内のオブジェクトを丸ごと削除できます
for object in bucket.objects.filter(Prefix='[フォルダ名]/').all():
object.delete()
オブジェクトのコピー
クライエントAPI
以下のように、copy_object()メソッドでオブジェクトをあるS3バケットから他のバケットにコピーできます。
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
# コピー元のバケットとオブジェクト(キー)を指定
object_key = 'オブジェクト名'
copy_source = {
'Bucket': 'コピー元のバケット名',
'Key': object_key
}
# オブジェクトを別バケットにコピー
s3client.copy_object(
CopySource=copy_source,
Bucket='コピー先のバケット名',
Key=object_key)
なお、copy_object()メソッドと似た機能を持つcopy()メソッドも存在します。前者は5GB以上のオブジェクトはコピーできないのに対し、後者はコピーできるという違いがあるようです(参考)
リソースAPI
以下のように、Bucketクラス内のcopy()メソッドでオブジェクトをあるS3バケットから他のバケットにコピーできます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
target_bucket = s3resource.Bucket('コピー先のバケット名') # コピー先のバケットインスタンス作成
# コピー元のバケットとオブジェクト(キー)を指定
object_key = 'オブジェクト名'
copy_source = {
'Bucket': 'コピー元のバケット名',
'Key': object_key
}
# オブジェクトを別バケットにコピー
target_bucket.copy(
CopySource=copy_source,
Key=object_key)
バケット内の全てのオブジェクトをコピーしたい場合
バケット内の全てのオブジェクトをコピーしたい場合、先ほどのオブジェクトの一覧表示で登場したobjectsコレクションとBucket.copy()メソッドを組み合わせて、一括コピーする事ができます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
source_bucket_name = 'コピー元のバケット名' # コピー元のバケット名
source_bucket = s3resource.Bucket(source_bucket_name) # コピー元のバケットインスタンス作成
target_bucket = s3resource.Bucket('コピー先のバケット名') # コピー先のバケットインスタンス作成
# コピー元バケット内の全てのオブジェクトを走査
for object in source_bucket.objects.all():
# コピー元のバケットとオブジェクト(キー)を指定
copy_source = {
'Bucket': source_bucket_name,
'Key': object.key
}
# オブジェクトを別バケットにコピー
target_bucket.copy(
CopySource=copy_source,
Key=object.key)
他にも先ほどのfilter()メソッドを間に加える事で、特定のフォルダ(プレフィックス)内のオブジェクトを全てコピーする事もできます
オブジェクトの移動
クライエントAPI
オブジェクトを移動するメソッドは存在しませんが、オブジェクトをコピーするcopy_object()メソッドとオブジェクトを削除するdelete_object()を組み合わせれば、オブジェクトを別バケットに移動できます。
import boto3
s3client = boto3.client('s3') # S3操作用インスタンス作成
source_bucket_name = '移動元のバケット名' # 移動元のバケット名
# 移動元のバケットとオブジェクト(キー)を指定
object_key = 'オブジェクト名'
copy_source = {
'Bucket': source_bucket_name,
'Key': object_key
}
# オブジェクトを別バケットにコピー
s3client.copy_object(
CopySource=copy_source,
Bucket='移動先のバケット名',
Key=object_key)
# オブジェクトを移動元バケットから削除
s3client.delete_object(
Bucket=source_bucket_name,
Key=object_key)
リソースAPI
オブジェクトを移動するメソッドは存在しませんが、オブジェクトをコピーするBucket.copy()メソッドとオブジェクトを削除するBucket.delete_objects()を組み合わせれば、オブジェクトを別バケットに移動できます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
source_bucket_name = '移動元のバケット名' # 移動元のバケット名
source_bucket = s3resource.Bucket(source_bucket_name) # 移動元のバケットインスタンス作成
target_bucket = s3resource.Bucket('移動先のバケット名') # 移動先のバケットインスタンス作成
# 移動元のバケットとオブジェクト(キー)を指定
object_key = 'オブジェクト名'
copy_source = {
'Bucket': source_bucket_name,
'Key': object_key
}
# オブジェクトを別バケットにコピー
target_bucket.copy(
CopySource=copy_source,
Key=object_key)
# オブジェクトを移動元バケットから削除
source_bucket.delete_objects(
Delete={
'Objects': [{
'Key': object_key
}]
})
バケット内の全てのオブジェクトを移動したい場合
バケット内の全てのオブジェクトを移動したい場合、先ほどのオブジェクトの一覧表示で登場したobjectsコレクションとBucket.copy()メソッド、Object.deleteメソッドを組み合わせて、一括移動する事ができます。
import boto3
s3resource = boto3.resource('s3') # S3操作用インスタンス作成
source_bucket_name = '移動元のバケット名' # 移動元のバケット名
source_bucket = s3resource.Bucket(source_bucket_name) # 移動元のバケットインスタンス作成
target_bucket = s3resource.Bucket('移動先のバケット名') # 移動先のバケットインスタンス作成
# 移動元バケット内の全てのオブジェクトを走査
for object in source_bucket.objects.all():
# 移動元のバケットとオブジェクト(キー)を指定
copy_source = {
'Bucket': source_bucket_name,
'Key': object.key
}
# オブジェクトを別バケットにコピー
target_bucket.copy(
CopySource=copy_source,
Key=object.key)
# オブジェクトを移動元バケットから削除
object.delete()
他にも先ほどのfilter()メソッドを間に加える事で、特定のフォルダ(プレフィックス)内のオブジェクトを全てコピーする事もできます
参考記事