はじめに
以下の記事で紹介したように、EC2はAWS上にOS付きの仮想マシン(VM)を作成できるサービスであり、多種多様なサーバー用途に広く用いられています。
EC2の利点としては、オンプレサーバと比べて「環境構築、管理の手間が減らせること」、FargateやLambdaのようなサーバーレスサービスと比べて「自由度が高い」等が挙げられますが、自由度が高いゆえに自己流の活用法でも何とかなってしまい、
「適切に活用できているか自信がない…」

といった方も多いかと思います。
そのような方のために、以下の公式ベストプラクティスが準備されています。
が、上記のベストプラクティス、解説が非常に簡潔で具体例も少なく、初学者には実践が難しいと感じたため、本記事では備忘録も兼ねて具体例を交えて解説したいと思います。
ベストプラクティス一覧
公式ベストプラクティスは、以下の項目に分かれています。
それぞれ具体的な活用方法を解説します
セキュリティ関連
セキュリティに関連したベストプラクティスを解説します

IDフェデレーション、IAMユーザー、IAMロールによるアクセス管理
こちらはEC2というよりIAMのベストプラクティスに近く、EC2以外のサービスでも共通して意識すべき事項です。
EC2を始めとしたAWSサービスへのアクセス権限付与は、基本的にIAMから実行されます。
よってAWS内のセキュリティ確保のため、公式のIAMベストプラクティスを理解して実践することが推奨されます。
詳細は以下の記事の「IAMセキュリティのベストプラクティス」にまとめたので、こちらをご参照下さい
セキュリティグループに対して、最小権限となるルールを適用
こちらはEC2というよりVPCの機能における注意点となります。
セキュリティグループとは、VPC内のリソース (インスタンス)と外部との通信を制限する機能であり、オンプレネットワークにおけるファイアウォールに相当します。
前述のIAMがホスト(AWSサービス)上でのセキュリティの要であれば、セキュリティグループはネットワーク上でのセキュリティの要であり、適切に設定することで外部からの攻撃を遮断する事ができます。
具体的には、以下の内容を理解・実践する事が推奨されています
- デフォルトでは25番ポート(SMTP=メール転送での踏み台防止)以外全ての外向き通信を許可する
- セキュリティグループは「ホワイトリスト式」(拒否ルールを作成できない)と理解する
- セキュリティグループは「ステートフル」(最初の要求パケットの方向のみを考慮)と理解する
- セキュリティグループのフィルタリングは「外部側IPアドレス」「ポート番号」「プロトコル」に基づくことを把握して設定する
- ルールの追加と削除は随時行うことができ、関連付けられたインスタンスに自動的に適用される
- 複数のセキュリティグループをインスタンスに関連付けると、各セキュリティグループのルールが効率的に集約され適用される
詳細は以下の公式ドキュメントをご参照下さい
以下のVPCの記事もご参照頂ければと思います
定期的にインスタンスのOSやアプリケーションにパッチ処理、更新、および保護を適用
サーバーにはパッチや更新ファイルを適用しないと脆弱性が放置されてセキュリティ上危険ですが、これはEC2インスタンスでも同様です。
よってパッチや更新ファイルを定期的に適用する事が重要です。
例えばAmazon Linux OSのAMIを選択した場合、以下のようにsudo yum updateを実行してパッケージを一括更新します (更新にはインターネットへの外向き通信許可=VPCのパブリックサブネットが必要ですが、こちらのような裏技もあります)
また、EC2 Image builderを使用することで最新バージョンのパッケージがインストールされたAMIを自動で作成・展開できるため、こちらを利用して更新を自動化する事も有効です。
Amazon Inspectorでインスタンス上のソフトウェア脆弱性や意図しない公開の有無をスキャン
Amazon Inspectorとは、インスタンス内の脆弱性や外部からのアクセス可能性を自動スキャンするサービスです。
(EC2インスタンスだけでなく、ECR上のコンテナイメージもスキャン対象となります)
具体的には、以下の2項目を検査します (参考)
有料のサービスですがそれほど高くはないので、セキュリティリスクを抑えたい用途では積極的に利用して良いかと思います。
詳細は以下の記事が分かりやすいです
ストレージ関連
ストレージ (EBS, インスタンスストア)に関連したベストプラクティスを解説します

データの永続性、バックアップ、および復元に対するルートデバイスタイプの影響について理解する
EBSとインスタンスストアの差を理解して適切に使い分けるという事を表す項目です。
ざっくり言うと以下のように選択するのが適切かと思います
- EBS: 速度はそこそこだが、データの消失対策やコスト面に優れる。一般的にはこちらを選択
- インスタンスストア: 超高速だが、データの消失対策やコスト面で弱い。速度最優先の一時ストレージ向け
詳細は以下の記事の「ストレージ (EBS)」を参照下さい
オペレーティングシステム用およびデータ用として個別にEBSボリュームを使用
EC2インスタンスには、複数のEBSボリュームをアタッチする事ができます。
デフォルトではOS用に1個のEBSボリュームがアタッチされており、これがデータ用のボリュームも兼ねています。
一方でこのベストプラクティスではOS用とデータ用で別個のEBSボリュームをアタッチすることを推奨しています。
これにより、インスタンス終了後(OS用のルートボリュームはデフォルトで削除される)もデータ用のボリュームが保持され、他のインスタンスにアタッチする事で簡単に再利用できます。
インスタンス終了後もボリュームを保持する方法の詳細は、以下の公式ドキュメントを参照ください
インスタンスで一時データの格納に使用できるインスタンスストアを使用
インスタンスストアを使用する際は、データ消失リスクがある (冗長性がない&インスタンス停止時にデータが消える)ことを把握し、適切な用途 (一時ストレージ等)に使用する必要があります。
例えば、高速化等を目的としてインスタンスストアをデータベース用途で使用する場合、ユーザー側でレプリケーションファクターを設定して耐障害性を確保する事が推奨されています。
EBSボリュームとスナップショットを暗号化
セキュリティレベルを高めたい場合、インスタンスに紐づけられたボリュームであるEBSと、そのバックアップであるスナップショットを暗号化する事が推奨されます。
詳細は以下の記事の「EBSとスナップショットの暗号化」を参照下さい
リソース管理
インスタンス等のリソースを管理しやすくするためのベストプラクティスを解説します

AWS リソースを追跡および識別するために、インスタンスメタデータおよびリソースのカスタムタグを使用
こちらはEC2に限らず、多くのAWSサービスにおいて有用な運用法となります。
インスタンスを始めとしたEC2のリソース (あるいはEC2以外も含めた多くのAWSリソース)では、タグ付けによる分類が可能です。
タグ付けによりユーザーによるリソースの検索を効率化できるのみならず、請求書の分類(コスト配分タグ)やIAMによるアクセス制御(タグベース認可)をタグに基づき実施する事もできます。
最も馴染み深いタグは、インスタンスの名称を表すNameですが、それ以外にも「用途」、「所有者」、「環境」等を表すタグを追加する事で、インスタンス数が増えた際も効率的な管理を実現できます。
タグ付けの方法はコンソールやCLI、IaC (CloudFormation)等、使用するツールにより異なるため、以下の公式ドキュメントを参照下さい。
Amazon EC2 の現在の制限を表示
インスタンス等のリソース数には、リージョン毎に上限が設けられています。
これら上限は申請により引き上げる事ができますが、実際に引き上げが適用されるまでにはタイムラグが存在するため、現在のリソース数と上限値を逐次確認し、制限の引き上げが必要となる前に計画する事が推奨されています
詳細は以下の記事の「制限」を参照下さい
AWS Trusted AdvisorでAWS環境を検査
Trusted AdvisorはEC2に限らず、多くのAWSサービスにおいて有用な自動チェックツールです。
具体的には、「コスト最適化」「パフォーマンス」「セキュリティ」「耐障害性」「サービスの制限」という5種類の事項に関して、ベストプラクティスから外れた非効率・不安全な状態となっているリソースを簡単に検知できます。
ただし、多くの機能は有料のAWSサポートプランにおいて「ビジネス」以上のプランを選択しないと使用できない事にご注意ください。
全ての検知項目は、以下の公式ドキュメントを参照下さい
無料で使用できる機能として、例えば以下の「セキュリティ」に関する項目の検査を実施できます。
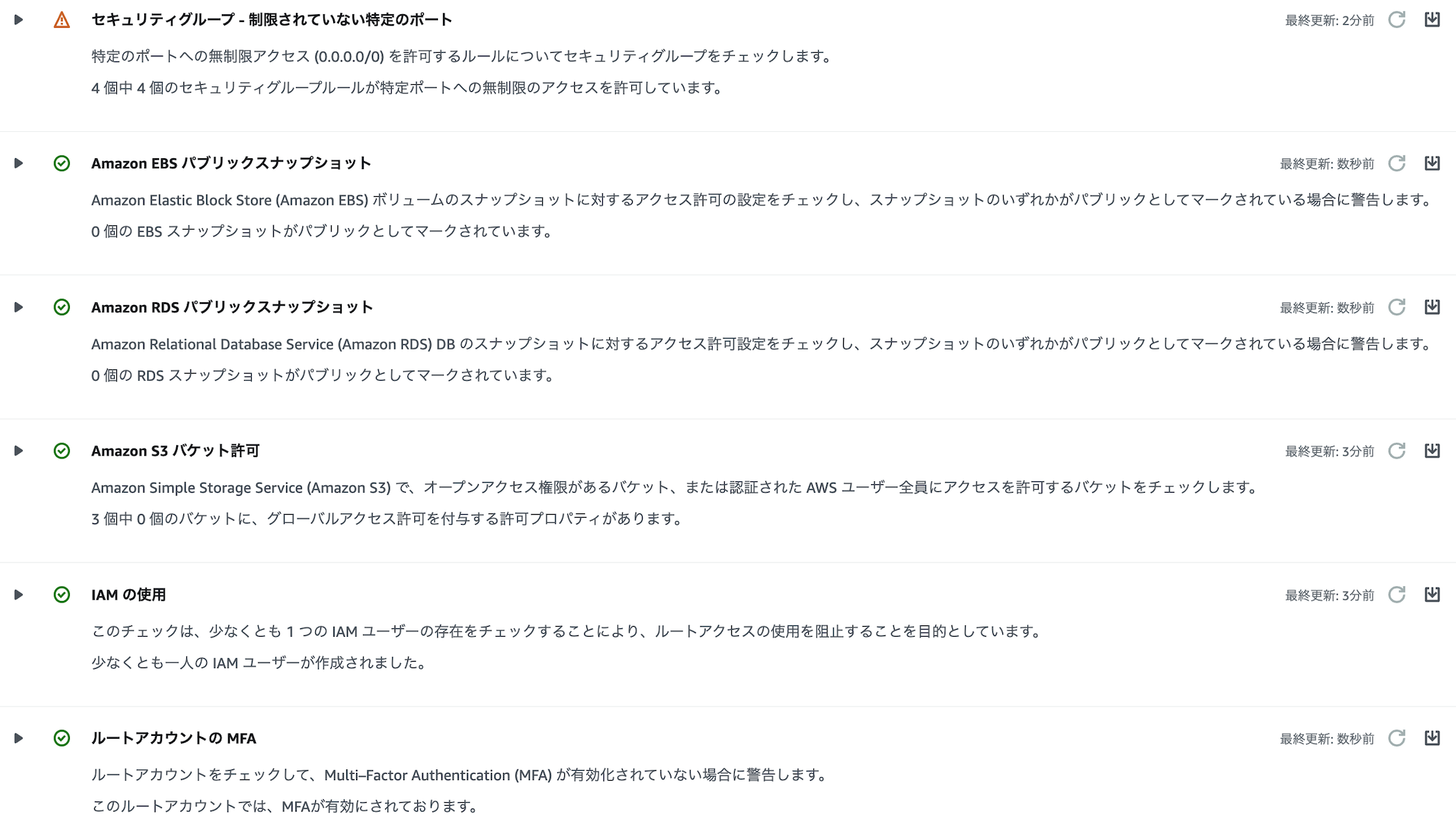
❗️マークが付いている項目が検査によりベストプラクティスに合致していないと判定されたリソースの検出を表しています。
(上例では、デフォルトのセキュリティグループでSSH用の22番ポートが無制限アクセスとなっているため、検知されているようです。このようにデフォルト設定であっても必ずしも安全とは言い切れないため、Trusted Advisorはより安全なクラウド運用を実現するために役立ちます)
バックアップと復旧
バックアップに関連したベストプラクティスを解説します

定期的にスナップショットを使用してEBSボリュームをバックアップし、インスタンスからAMIを作成
インスタンスやEBSをバックアップするにはスナップショットとAMIの2種類の方法があり、これらのバックアップを自動化するためにはライフサイクルマネージャーやAWS Backupと呼ばれる機能を使用すると便利です。
詳細は以下の記事の「EC2とバックアップ」を参照下さい
複数のアベイラビリティゾーンにアプリケーションの重要なコンポーネントをデプロイし、データを適切にレプリケート
こちらはEC2に限らず、多くのAWSサービス(特にEC2のようにデフォルトでは冗長化が弱いサービス)において意識する必要のある事項です。
EC2インスタンスは単一のAZに設置されて冗長化されておらず、ストレージとして使用されるEBSも単一AZ内の冗長化のみで、AZに障害が発生した際に単一障害点となってサービスが停止してしまいます。
よって、ELBやAuto Scaling等と組み合わせて複数AZへインスタンスを設置してトラフィックを分散させたり、スナップショット等で定期的にバックを取得(保存先のS3はデフォルトで複数AZにレプリケートされる)する事で、耐障害性を高める事が推奨されています。
詳細は以下のELBの記事を参照下さい
また、RDSやS3にデータを保持している場合は、併せてRDSのマルチAZ構成やS3のクロスリージョンレプリケーションを適用することで、システム全体としての冗長性を向上させられます。
インスタンスが再開したときに、動的なIPアドレスを処理するアプリケーションを設計
こちらの公式ドキュメントに記載されているように、インスタンスのデフォルトではインスタンスに動的なIPアドレスが自動で割り振られます
この動的なIPアドレスやAWS側がIPv4アドレスプールから自動選択するため、ユーザ側が事前に知る事はできません。よって、インスタンスの切り替えや再起動時にIPアドレスが変わる事を見越してアプリケーションを設計する必要があります。
具体的には、以下の3種類の方法 (特に前者2つ)が有効な対処法となります。
対処1: Elastic IP
上記への対処法として最もシンプルな方法はElastic IPを使用する事です。
Elastic IPはインスタンスに固定のグローバルIPアドレスを付与する機能であり、インスタンスの切り替えや再起動時に同じElastic IPを付与することで、IPアドレスの変化を防ぐ事ができます。
対処2: ELBとAuto Scaling
また複数インスタンスの使用を許容するのであれば、ELB単体、またはELBとAuto Scalingを組み合わせることで、IPアドレスの変化を意識する事なくインスタンスへのリクエストの自動配分を実現する事もできます。
対処3: ダイナミックDNS
Elastic IPを使用しなくとも、ダイナミックDNSを使用することで、より安価にIPアドレスの変化に対応する事ができます (以下のドキュメント参照)
ただしこちらのサイトの「DNSのTTL」で言及されているように、DNSはキャッシュ更新までにタイムラグがあるという特性上、新しいIPアドレスが反映されるまでに時間が掛かり(最大24時間程度)、古いIPアドレス(=終了したインスタンス)がリクエストを受信し続けるリスクがある事にご注意ください (基本的には公開サービスには向かない方法です)
イベントを管理し、対応
EC2を安定運用していくためには、異常発生時の検知や障害発生時の事後分析のために、インスタンスの各種情報をモニタリングする必要があります。
インスタンスのようなAWSのリソースのモニタリングにはCloudWatchを使用することが基本です。
モニタリング対象を何とするかはユースケースにより異なるため、目的に応じて計画的にモニタリング対象を定めることが求められますが、ベストプラクティスでは以下のメトリクスを最低限モニタリング対象に含めることが推奨されています。
| モニタリング対象の項目 | モニタリング対象の項目 | エージェント/CloudWatch Logs のモニタリング |
|---|---|---|
| CPU使用率 | CPUUtilization | |
| ネットワーク使用率 | NetworkIn NetworkOut |
|
| ディスクパフォーマンス | DiskReadOps DiskWriteOps |
|
| ディスクの読み書き | DiskReadBytes DiskWriteBytes |
|
| メモリの使用率、ディスクスワップの使用率、ディスクスペースの使用状況、ページファイルの使用状況、ログ収集 | CPUUtilization | 参考 |
最も簡単に閲覧するのであれば、以下のようにCloudWatchのトップページから「すべてのメトリクス」→「EC2」→「自動ダッシュボードを表示」と飛ぶと便利です
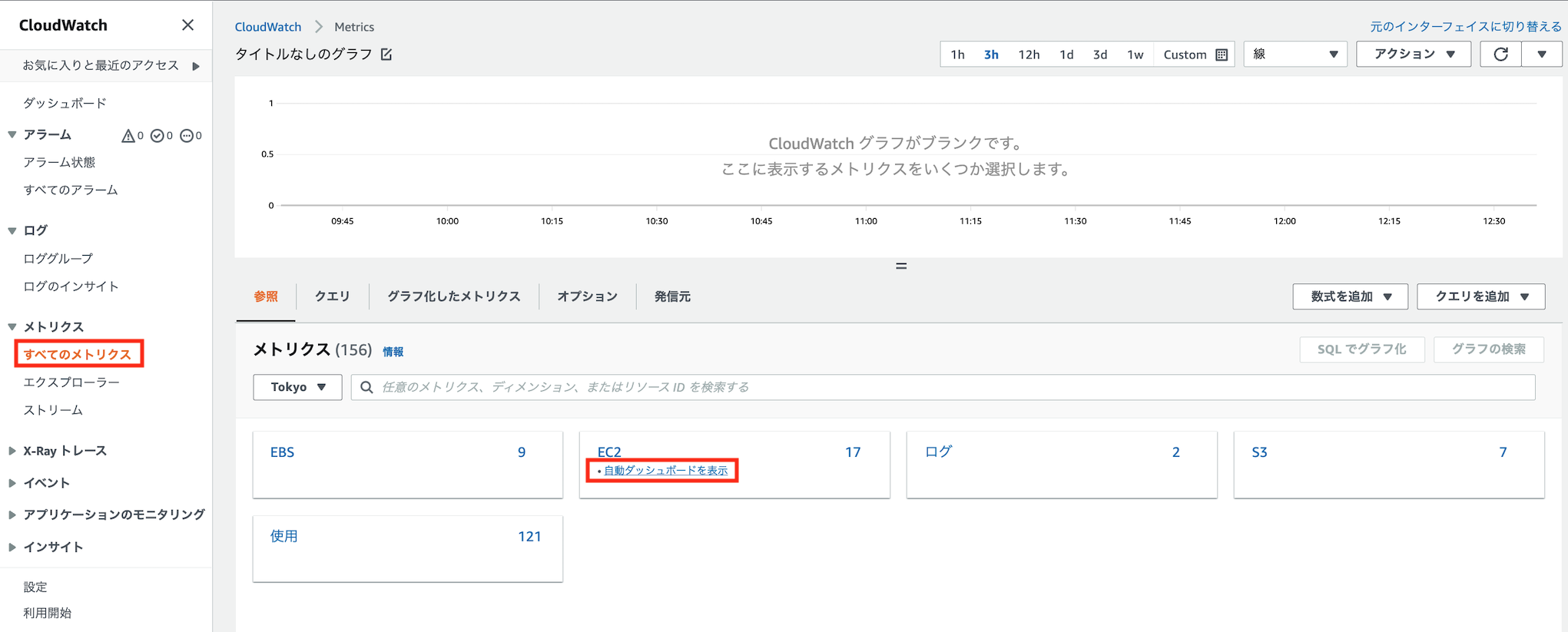
・ダッシュボードの表示内容
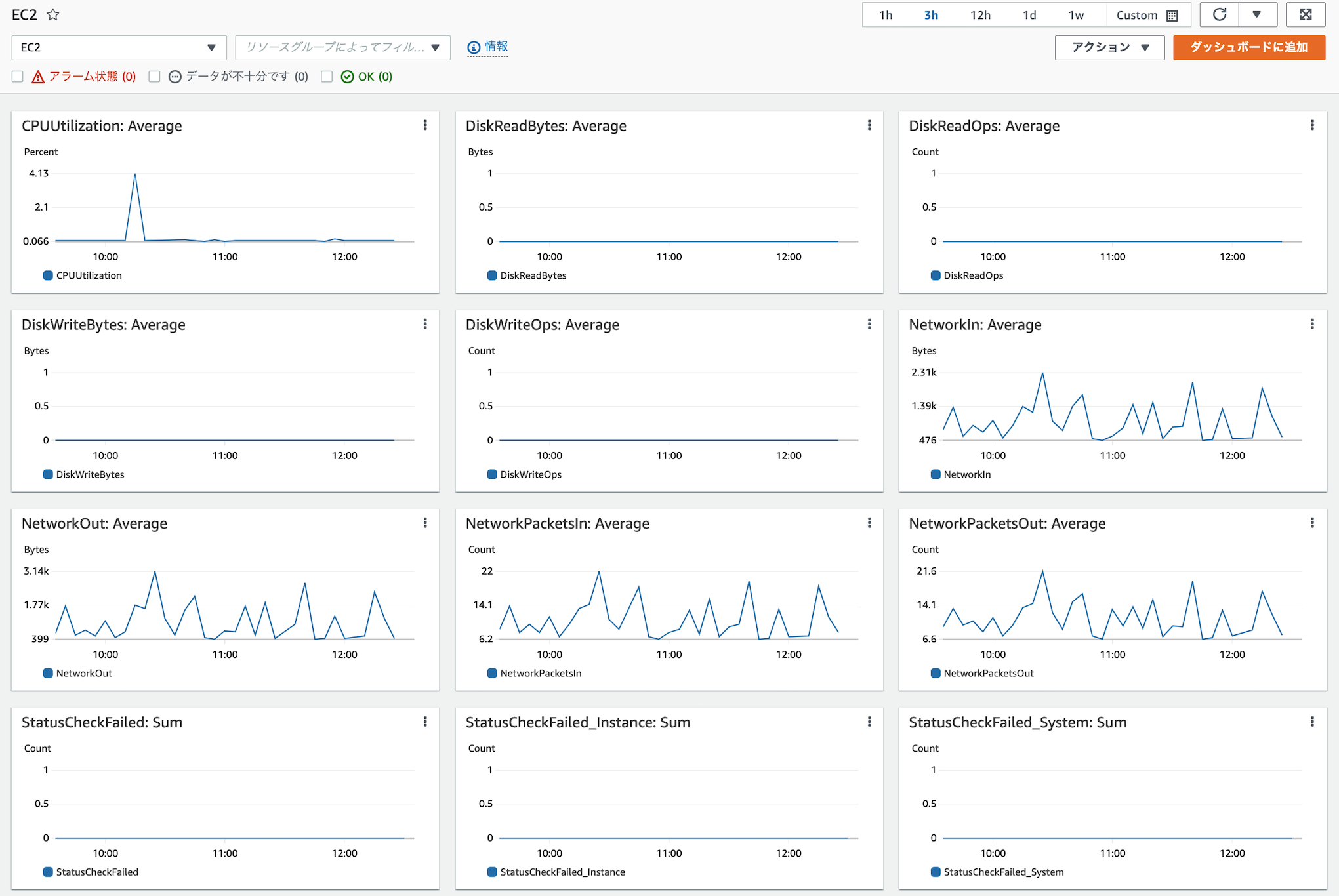
詳細は以下公式ドキュメントを参照下さい
フェイルオーバーを処理する準備が整っていることを確認
EC2におけるフェイルオーバーとは、あるインスタンスが障害で停止した際に、代わりのインスタンスに簡単に、あるいは自動的に切り替え、サービスの提供を維持する事を指します。
ベストプラクティスでは、以下の2種類の方法が紹介されていますが、ある程度スケールしたサービスであれば自動化された対処2がおすすめです。
対処1: ENIの付け替え
インスタンスがネットワークにアクセスするためには、ENI (Elastic Network Interface)を経由する必要があります。
逆に言うと、ENIにElastic IPで固定IPアドレスを付与すれば、ENIを他のインスタンスに付け替えるだけで簡単に同じIPアドレスを付与する事が出来ます。
なので、正規のインスタンスにElastic IPを付与したENIをアタッチした上で、予備のインスタンスを予め準備 (あるいはAMIやスナップショットの形で保持して新たにインスタンス立ち上げ)しておけば、障害発生時に手動でENIを付け替える事で簡単にフェイルオーバーを実現できます。
対処2: Auto Scalingを使用
Auto Scalingを使用すれば、CloudWatchまたはELBのヘルスチェック機能で障害発生を検知し、自動で新たなインスタンスを起動してフェイルオーバーできます。
インスタンスとEBSボリュームを復元するプロセスを定期的にテストして、データとサービスの正常な復元を確認
前述のように、ライフサイクルマネージャーやAWS Backupを使ってインスタンスのバックアップ(AMI + スナップショット)を取得する事ができます。
一方で、AMIとスナップショットからインスタンスを復元する方法やインスタンスタイプ等を把握しておかないと正しい復元が実現できないため、いざという時パニックとなる恐れがあります。
このような事態を防ぐため、定期的にバックアップからの復元訓練を実施し、復元後のインスタンスが想定通り動作することを確認しましょう。
(このあたりを「面倒臭い」と感じるのであれば、学習コストをかけてでも環境構築をより自動化できるFargateやECSのようなコンテナサービス、あるいはCloudFormationやTerraformのようなIaCサービスを使用する事をお勧めします)
ネットワーク関連
ネットワークに関連したベストプラクティスを解説します
アプリケーションのTTL値をIPv4とIPv6で255に設定
pingコマンド等で見たことのある方も多いかと思いますが、IPパケットにはTTLと呼ばれる仕組みが存在します。
TTLはルータを経由するたびに減少する数であり、0になるとパケットが強制的に廃棄され、リクエストが通らなくなります。
よって初期値 (TTL値)を経由するルータ数より大きく設定する必要があります。
本来はネットワーク界の「ハメ技」とも言えるルーティングループを防ぐための仕組みですが、クラウドのような経由ルータ数が多くなりがちな複雑なシステムでは、パケット破棄を防ぐために、アプリケーション側でTTL値を255のような大きな値に設定する事が推奨されます。
なお、TTLの詳細については以下の記事がわかりやすいです