Pythonと地理データ
飛ぶ鳥を落とす勢いで利用が広がるPythonですが、地理データに関してもその傾向は同様です。
Pythonの主用途であるデータ分析と地理、一見関連が薄そうですが、
日本地図を作った伊能忠敬が偉人と言われるように、地理データは古来から重要な情報として活用され、現在では公的機関のサイトから良質のデータが無料で手に入るため、データ源として極めて有用です。

というわけで意気揚々と公的機関のサイトに乗り込み、ダウンロードしたファイルを解凍すると、多くの人は以下の困難にぶつかるかと思います。

「拡張子が・・・・わからん…」

こんな方のために、本記事では地理データの主要な形式であるShapefile(.shpファイル)をPythonで扱う方法を、実装例(GitHub)を交えて解説しようと思います。
本記事を読めばShapefileはひととおり扱えるというような、ポータルサイト的な記事を目指そうと思います。
また、Shapefile操作の代表的なライブラリのひとつであるGeoPandasに関しては、別記事でまとめています
Shapefileとは?
Shapefileとは、地理運用システム(GIS)のベクターデータを扱うためのファイル形式です。
GIS?ベクターデータ?って何やねん!と思われる方が多いかと思うので、解説します。
GISとベクターデータ
GISは、国土地理院のサイトでは以下のように定義されています。
地理情報システム(GIS:Geographic Information System)は、地理的位置を手がかりに、位置に関する情報を持ったデータ(空間データ)を総合的に管理・加工し、視覚的に表示し、高度な分析や迅速な判断を可能にする技術である。
少し難しい言葉が並んでいますが、ざっくり言うと
地理情報をグラフィカルに表示したり、分析に利用する仕組み
と解釈できそうです。
またGISが保持するデータは、ラスターデータとベクターデータに大別されます(wikipediaより)
| 名称 | 概要 | 利用法 | 代表的なファイル形式 |
|---|---|---|---|
| ラスターデータ | 地図を格子(メッシュ)状に分割し、メッシュごとに値を保持 | 背景の表示や、位置ごとの統計値の保持に利用される | GeoTiff |
| ベクターデータ | ポイント (点)、ライン (線)、ポリゴン (面)の3要素で表現したデータ | 地図上での位置関係を保持 | Shapefile, GeoJson |
ラスターデータは天気予報の雨雲レーダーをイメージすると理解しやすいかと思います(参考)。
ベクターデータの「ポイント、ライン、ポリゴン」はイメージを付けづらいかと思いますが、
下図のように解釈すると、理解しやすいかと思います
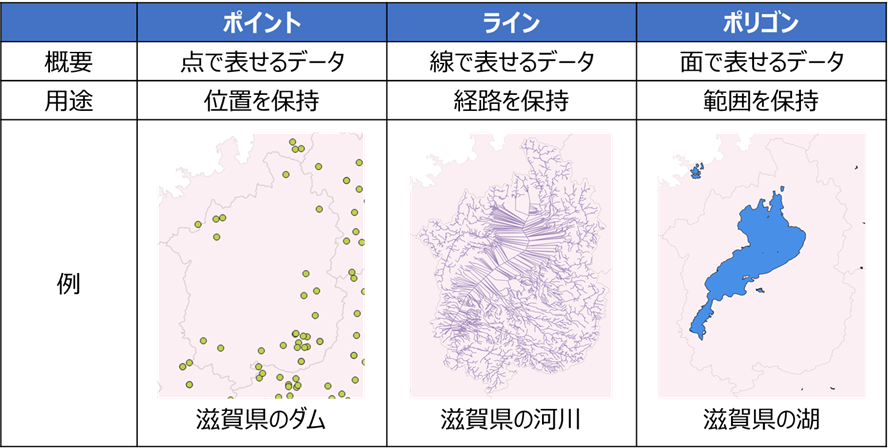
※この3種以外にもマルチライン等の形式がありますが、どれも基本的には上記3種の組合せで表現されます
本記事で紹介するShapefileは、ベクターデータの一種です。
なお、GoogleEarthで使われているKMLファイルなど、ラスターデータとベクターデータ両方を包括したファイル形式も存在します。
ベクターデータとShapefile
ベクターデータのファイル形式には、ShapefileとGeoJsonが良く使われています。
それぞれの特徴は以下となります。
| ファイル形式 | 拡張子 | 長所 |
|---|---|---|
| Shapefile | .shp | 公的機関等で実質的な標準形式となっており、手に入るデータ数が多い |
| GeoJSON | .json, .geojson | 通常のJSONと同様に処理可能。地図表示に対応したWebアプリが多い(Github等) |
ざっくり言うと、Shapefileはデータの入手性、GeoJSONはお手軽な表示にメリットがありそうです。
WikipediaにもShapefileはGIS業界の代表的な標準フォーマットとなっていると記載されているように、公的機関を始めとした多くのサイトから、多種多様なShapefileデータが提供されています。
Shapefileの構成
Shapefileは主に以下の4つのファイルからなります(参考)
| 拡張子 | 内容 |
|---|---|
| .shp | 図形の情報を格納する主なファイル |
| .shx | 図形のインデックス情報を格納するファイル |
| .dbf | 図形の属性情報を格納するテーブル |
| .prj | 図形の持つ座標系の定義情報を格納するファイル |
※.prjファイルはオプションなので、なくとも動作します(とはいえ、座標系は重要な情報なので作成しておいた方が無難です)
冒頭のスクリーンショットのようにこれらは別々のファイルで保持されますが、各種表示ソフトやライブラリでは一体となって読み込まれます
また、.shpに格納されたポリゴンやポイントなどの座標を表す「ジオメトリ」と、.dbfに格納された各種数値・文字列を表す「属性」が、シェープファイルの最も重要な構成要素となります。
Shapefile操作に使えるライブラリ
こちらの記事で詳しく解説されているように、PythonでのGIS関係は多くのライブラリが乱立しており、
「結局どれ使えばええねん!」
と初学者の心を折る要因の一つとなっています。
全体像を理解するためには、各ライブラリを下記4つの用途に合わせて分類することが有効です。
| 分類 | 解説 | 主なライブラリ | |
|---|---|---|---|
| 1 | 読込 | Shapefile(.shp)を読み込む | pyshp(shapefile), osgeo(GDAL), fiona, geopandas |
| 2 | 処理 | 座標変換、距離算出、面積算出等の処理を行う | osgeo(GDAL), pyproj, shapely, geopy, geopandas |
| 3 | 保存 | Shapefile(.shp)を書き出す | pyshp(shapefile形式), geojson(GeoJSON形式), osgeo(GDAL), fiona, geopandas |
| 4 | 可視化 | 地物情報をJupyter上で可視化する | folium, descartes, geopandas |
この後の実装パートでは、太字のライブラリでの実装法を紹介します
(geopandasは他のライブラリとの機能重複が多いことから、別記事で紹介します)
なお、具体的にどのライブラリを使うかは、
A. 後述のユースケースを参考に実装したい機能に合わせて使い分ける
B. Geopandasに統一する(別記事)
のいずれかがおすすめです
それぞれのライブラリの機能と特徴を下記します
1.読込
| ライブラリ名 | 主な機能 | 特徴 | 公式ドキュメント |
|---|---|---|---|
| pyshp(shapefile) | Shapefileの読込 | 実装がシンプルでわかりやすい。座標系読込など非対応機能もあり | pyshp |
| osgeo(GDAL) | 主要なGISファイル形式(ラスタデータ含む)の読込に対応 | 多機能だが学習コスト高め。一部の日本語が文字化け | GDAL Python API |
| fiona | Shapefileの読込 | データの読み書きをdict(JSON)チックに行える | Fiona User Manual |
| geopandas | Shapefile、GeoJSONの読込とPandas DataFrame形式での保持 | データの読み書き、処理、表示を1つのライブラリで行える | GeoPandas |
普段使う機能の大半はpyshpでの読込で対応できるので、まずはpyshpを使ってみるのが良いかと思います
2.処理
| ライブラリ名 | 主な機能 | 特徴 | 公式ドキュメント |
|---|---|---|---|
| osgeo(GDAL) | 多種多様な機能を提供 | 多機能だが学習コスト高め | GDAL Python API |
| pyproj | 座標変換、距離算出等 | 座標変換や投影系の処理がメイン | pyproj Documentation |
| shapely | ジオメトリの統計値算出 | ポリゴンの面積や重心、ラインの長さ等を算出可能 | Shapely |
| geopy | ジオコーディング、逆ジオコーディング | ジオコーディング(住所⇔緯度経度の相互変換) | GeoPy’s documentation |
| geopandas | shapely等のライブラリを包含しており、多くの機能を提供 | データの読み書き、処理、表示を1つのライブラリで行える | GeoPandas |
機能ごとに住み分けができているので、実現したい機能に合わせて選定してください
3.保存
| ライブラリ名 | 主な機能 | 特徴 | 公式ドキュメント |
|---|---|---|---|
| pyshp(shapefile) | Shapefile形式での保存 | 実装がシンプルでわかりやすい | pyshp |
| geojson | GeoJSON形式での保存 | GeoJSON形式なので保存ファイルをGitHubで表示可能 | geojson |
| osgeo(GDAL) | 主要なGISファイル形式(ラスタデータ含む)の保存に対応 | 多機能だが学習コスト高め(公式ドキュメントが長い…笑) | GDAL Python API |
| fiona | Shapefile形式での保存 | データの読み書きをdict(JSON)チックに行える | Fiona User Manual |
| geopandas | Shapefile、GeoJSON形式での保存 | データの読み書き、処理、表示を1つのライブラリで行える | GeoPandas |
読込とほぼ同じライブラリ構成ですが、GeoJSONで保存したい場面が結構あるので、この場合はgeojsonライブラリが便利です。
また、4.表示で使うfoliumライブラリにおいても、いったんGeoJSON形式に格納してから表示させると実装が楽になるので、geojsonライブラリが活躍します
4.表示
| ライブラリ名 | 主な機能 | 特徴 | 公式ドキュメント |
|---|---|---|---|
| folium | Jupyterで地図上にジオメトリ表示 | 地図(OpenStreetMap)上に表示してスクロール可能 | Folium documentation |
| descartes | Matplotlibと組み合わせて画像表示 | GeoJSON形式なので保存ファイルをGitHubで表示可能 | descartes |
| geopandas | Matplotlibと組み合わせて画像表示 | PandasのDataFrame.plotと似たAPI | GeoPandas |
地図上でスクロールできるfoliumの使い勝手が良いと感じました。
Webアプリ(GeoDjango)開発でも大いに活躍するライブラリとのことなので、覚えておいて損はないかと思います。
実装手順
実際にShapefileを読み込み、よく使う処理をユースケースとしてひととおり実装してみます。
使用コードはGitHubにもアップロードしております
また、同ユースケースのGeoPandasライブラリでの実装法も別記事で紹介しているので、こちらも必要に応じてご覧ください(GeoPandasは特にポリゴン関係の処理がカンタンなのでおすすめです)
ユースケース一覧
読込
| No | 内容 | 使用するライブラリ | 実装法リンク |
|---|---|---|---|
| 1 | Shapefileの読込 | pyshp | リンク |
| 2 | ジオメトリ情報と属性情報の取得 | pyshp | リンク |
処理
| No | 内容 | 使用するライブラリ | 実装法リンク |
|---|---|---|---|
| 1 | 座標変換 | osgeoまたはpyproj | リンク |
| 2 | ポイントデータへの変換 | shapely | リンク |
| 3 | ポイント間の距離測定 | osgeo+shapelyまたはpyproj | リンク |
| 4 | 最も近いポイントを探す | osgeo+scikit-learn | リンク |
| 5 | ラインデータへの変換 | shapely | リンク |
| 6 | ラインの長さ測定 | osgeo+shapely | リンク |
| 7 | ポリゴンデータへの変換 | shapely | リンク |
| 8 | ポリゴンの重心測定 | shapelyまたはosgeo+shapely | リンク |
| 9 | ポリゴンの面積測定 | osgeo+shapely | リンク |
| 10 | 名称・住所から緯度経度検索 (ジオコーディング) |
geopy | リンク |
| 11 | 緯度経度から住所検索 (逆ジオコーディング) |
geopy | リンク |
保存
| No | 内容 | 使用するライブラリ | 実装法リンク |
|---|---|---|---|
| 1 | ポイントのファイル出力 | pyshpまたはgeojson | リンク |
| 2 | ラインのファイル出力 | pyshpまたはgeojson | リンク |
| 3 | ポリゴンのファイル出力 | pyshpまたはgeojson | リンク |
表示
| No | 内容 | 使用するライブラリ | 実装法リンク |
|---|---|---|---|
| 1 | ポイントの表示 | geojson+folium | リンク |
| 2 | ラインの表示 | geojson+folium | リンク |
| 3 | ポリゴンの表示 | geojson+folium | リンク |
実装に入る前に
Pythonで読み込む前に、Shapefileの大まかな内容を可視化しておくと実装がはかどります。
可視化用ソフトとして、フリーのGISソフトであるQGISが便利なので、こちらを参考にインストールし、Shapefileを読み込んで色々と見てみましょう。
(背景となるGeotiffのラスタファイルはこちらの国土地理院のサイトからダウンロードできます)

また、多少動作が重いですが、Google Earth Proを使うと綺麗なグラフィック上でShapeファイルの可視化が実現できます(参考)
使用するデータ
以下のA~Dのデータを使用します。
(貼ってある画像はQGISで可視化しています)
後述のサンプルコードと同じフォルダに、解凍したフォルダを格納すれば、サンプルコードで読込可能となります。
A. ダムデータ(ポイント)

B. 滋賀県の河川データ(ライン)

※本データでは琵琶湖も河川として扱われているのでご注意ください
C. 湖沼データ(ポリゴン)

D. 釧路市の農場データ(ポリゴン)
※osgeoによる座標の自動取得のみ使用
必要ライブラリのインストール
pipでインストールする場合下記の操作でインストール可能です(condaでも基本は同じ)
GDAL周りでエラーが出やすいので、私の環境で発生したエラーと解決策を後述します
pyshp
pip install pyshp
geojson
pip install geojson
pyproj
pip install pyproj
shapely
pip install shapely
osgeo(GDAL)
pip install gdal
pip install osgeo
VisualStudio非使用時は高確率でエラーが出るので、トラブルシューティングを参考に解決してください
geopandas
pip install geopandas
こちらもエラーが出やすいので、トラブルシューティングを参考に解決してください
geopy
pip install geopy
folium
pip install folium
具体的な実装例
Shapefileの読込、処理、保存、表示に分けて、
各ユースケースの実装法を解説します
読込1:Shapefileの読込
Shapefileの読込には、pyshpライブラリ(import時は"shapefile"という名前で指定)を使用します
# 必要ライブラリの読込(読込以外で使用するライブラリも含みます)
import shapefile
from shapely.geometry import Point, LineString, Polygon
from osgeo import ogr, osr
import pyproj
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
# 入力ファイルのパス
DAM_PATH = './W01-14_GML/W01-14-g_Dam.shp' # 国交省ダムデータ(ポイント、https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-W01.html)
RIVER_PATH = './W05-09_25_GML/W05-09_25-g_Stream.shp' # 国交省滋賀県河川データ(ライン、https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-W05.html)
LAKE_PATH = './W09-05_GML/W09-05-g_Lake.shp' # 国交省湖沼データ(ポリゴン、https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-W09-v2_2.html)
FARM_PATH= './01206釧路市(2020公開)/01206釧路市(2020公開)_5.shp' # 農水省農場データ(ポリゴン、https://www.maff.go.jp/j/tokei/porigon/hudeporidl.html)
# shpファイル読込(pyshpライブラリ使用)
# ポイント(ダムデータ)
src_dam = shapefile.Reader(DAM_PATH, encoding='cp932') # Shapefile読込
shps_dam = src_dam.shapes() # シェープ(ジオメトリ情報)
recs_dam = src_dam.records() # レコード(属性情報)
print(f'number of shapes = {len(shps_dam)}') # シェープの数
print(f'number of records = {len(recs_dam)}') # レコードの数
# ライン(河川データ)
src_river = shapefile.Reader(RIVER_PATH, encoding='cp932') # Shapefile読込
shps_river = src_river.shapes() # ジオメトリ情報
recs_river = src_river.records() # 属性情報
# ポリゴン(湖沼データ)
src_lake = shapefile.Reader(LAKE_PATH, encoding='cp932') # Shapefile読込
shps_lake = src_lake.shapes() # ジオメトリ情報
recs_lake = src_lake.records() # 属性情報
# ポリゴン(農場データ)
src_farm = shapefile.Reader(FARM_PATH, encoding='cp932') # Shapefile読込
shps_farm = src_farm.shapes() # ジオメトリ情報
recs_farm = src_farm.records() # 属性情報
ファイルの読込自体はReaderクラスで実行できますが、実際に中のデータにアクセスするためには
ファイル内のジオメトリ一括取得:shapes()メソッド
ファイル内の属性情報一括取得:records()メソッド
を実行する必要があります。
上記コードではジオメトリと属性の数をprintしていますが、
number of shapes = 2749
number of records = 2749
のように、両者の数が一致していることが分かります。
読込2:ジオメトリ情報と属性情報を1レコードずつ取得
shapes()やrecords()メソッドで取得できるのは全てのジオメトリや属性のListなので、1個1個のデータにアクセスするためにはfor文を回す必要があります。
下のサンプルコードのように、zipメソッドを使うとジオメトリと属性に同時アクセスできて便利です
# ポイント
for shp, rec in zip(shps_dam, recs_dam):
print(f'ポイント位置{shp.points[0]}') # ジオメトリ情報
print(f'ダム名:{rec["W01_001"]}\n堤高:{rec["W01_007"]}m\n総貯水量:{rec["W01_010"]}千m3\n所在地:{rec["W01_013"]}') # 属性情報
# ライン
for shp, rec in zip(shps_river, recs_river):
print(f'ライン位置{shp.points}') # ジオメトリ情報
print(f'河川名:{rec["W05_004"]}') # 属性情報
# ポリゴン
for shp, rec in zip(shps_lake, recs_lake):
print(f'ポリゴン位置{shp.points}') # ジオメトリ情報
print(f'湖沼名:{rec["W09_001"]}\n最大水深:{rec["W09_003"]}千m3\n水面標高:{rec["W09_004"]}') # 属性情報
ポイント位置[140.8858935039343, 40.709771157873135]
ダム名:駒込
堤高:84.5m
総貯水量:7800千m3
所在地:青森県青森市大字駒込
:
:
ライン位置[(135.97779224, 35.01171447), (135.97677222, 35.01133174)]
河川名:金勝川
:
:
ポリゴン位置[(141.15680611, 42.98894445), (141.15678306, 42.98906278), (141.15671416, 42.98938362),
:
湖沼名:さっぽろ湖
最大水深:千m3
水面標高:
:
ジオメトリ情報と属性情報が取得できていることが分かります。
ジオメトリ情報は基本的にshp.pointsプロパティで取得することができますが、
属性情報はrec["W05_004"]のようにフィールド名を指定する必要があり、フィールド名をデータの入手元の仕様書から読み取るか、デバッグツール等で解析する必要があります。
また、ジオメトリと属性に同時アクセスする方法には、zipを使う以外にもiterShapeRecordsメソッドでイテレータを使う方法もあります。
処理1:座標変換
GISデータを扱う上で、最初にして最大の壁と言われているのが座標系の変換です。
地図上の座標は緯度経度で表現される事が多いですが、
面積や長さなどの統計値を求める際は、メートル単位の方が便利です。
このように、緯度経度の座標とメートル単位の座標を相互変換し、用途により使い分けることは、地理データを活用する上で必須のテクニックと言えます。
後述の各種処理でも前処理として座標変換が頻出するので、本節の内容は一読をお勧めします。
座標変換に必要な知識
座標変換を正しく活用するためには、各座標系の特徴を理解する必要があります。
実用上は下記3種類の座標が良く用いられます
| 名称 | 単位 | 特徴 |
|---|---|---|
| 緯度経度(地理座標系) | 緯度+経度 | 全世界を1座標系で表現可能。球面座標なので、長さや面積は歪んで不正確 |
| 平面直角座標 | メートル | 面積や長さを高精度に表現する平面座標。カバー範囲が狭いのが弱点 |
| UTM座標 | メートル | 精度とカバー範囲のバランスを取った平面座標 |
他にもGoogle Maps等のWebアプリでよく利用されるメルカトル図法(EPSG3857)等があります
緯度経度
普段最も目にすることの多い座標系で、全世界を1つの座標系で表現できることが特徴です。
球面上の座標なので、単純に面積や長さを求めようとすると歪みによる誤差が大きい事にご注意ください

※画像はWikipediaより
平面直角座標
日本全国を19に分け、平面上でメートル単位で表した座標です。
細かく分けた分だけ精度は高いが、日本全国のような広範囲を一括表現できないことが弱点です
面積を高精度に求める際などに便利な座標系と言えます

※画像は国土地理院HPより
UTM座標(ユニバーサル横メルカトル図法)
全世界(厳密には北半球と南半球それぞれ緯度80度以下)を経度6度で縦分割し、平面上でメートル単位で表した座標です。
精度とカバー範囲のバランスを取った座標系で、52N~54Nの3座標系でほぼ日本全国を表現できます。
もっと言うと53N系1つの座標だけで、精度低下を許容すれば日本全国をカバーできます。
広域や平面直角座標の境界付近で処理をしたいときに便利な、汎用性の広い座標系と言えそうです

※画像はWikipediaより
EPSGコード
EPSGコードとは、GISで使用される様々な要素に必要なパラメータに割り振られたIDです(参考)
各座標系を表現するIDとして使われる事が、最も主要な活用法です
前述の3種類の座標系は2000年に測定された「JGD2000」と2011年に測定された「JGD2011」、アメリカでよく使われる「WGS84」に大別され、それぞれ下記のようなEPSGコードが割り振られています
| 名称 | カバー地域 | JGD2000のEPSGコード | JGD2011のEPSGコード | WGS84のEPSGコード |
|---|---|---|---|---|
| 緯度経度 | 全世界 | EPSG4612 | EPSG6668 | EPSG4326 |
| UTM座標51N系 | 先島諸島 | EPSG3097 | EPSG6688 | EPSG32651 |
| UTM座標52N系 | 沖縄、九州 | EPSG3098 | EPSG6689 | EPSG32652 |
| UTM座標53N系 | 中四国、近畿、中部 | EPSG3099 | EPSG6690 | EPSG32653 |
| UTM座標54N系 | 関東、東北、北海道 | EPSG3100 | EPSG6691 | EPSG32654 |
| UTM座標55N系 | 北海道道東 | EPSG3101 | EPSG6692 | EPSG32655 |
| (UTM座標56N系) | (南鳥島) | EPSG3102 | EPSG6693 | EPSG32656 |
| 平面直角座標1系 | 長崎、奄美 | EPSG2443 | EPSG6669 | - |
| 平面直角座標2系 | 長崎以外の九州 | EPSG2444 | EPSG6670 | - |
| 平面直角座標3系 | 中国地方西部 | EPSG2445 | EPSG6671 | - |
| 平面直角座標4系 | 四国 | EPSG2446 | EPSG6672 | - |
| 平面直角座標5系 | 中国地方東部、兵庫 | EPSG2447 | EPSG6673 | - |
| 平面直角座標6系 | 兵庫以外の近畿、福井、三重 | EPSG2448 | EPSG6674 | - |
| 平面直角座標7系 | 愛知、岐阜、石川、富山 | EPSG2449 | EPSG6675 | - |
| 平面直角座標8系 | 甲信越、静岡 | EPSG2450 | EPSG6676 | - |
| 平面直角座標9系 | 関東、福島 | EPSG2451 | EPSG6677 | - |
| 平面直角座標10系 | 福島以外の東北 | EPSG2452 | EPSG6678 | - |
| 平面直角座標11系 | 北海道道南 | EPSG2453 | EPSG6679 | - |
| 平面直角座標12系 | 北海道道央、道北 | EPSG2454 | EPSG6680 | - |
| 平面直角座標13系 | 北海道道東 | EPSG2455 | EPSG6681 | - |
| 平面直角座標14系 | 小笠原諸島 | EPSG2456 | EPSG6682 | - |
| 平面直角座標15系 | 沖縄本島周辺 | EPSG2457 | EPSG6683 | - |
| 平面直角座標16系 | 先島諸島 | EPSG2458 | EPSG6684 | - |
| 平面直角座標17系 | 大東諸島 | EPSG2459 | EPSG6685 | - |
| (平面直角座標18系) | (沖ノ鳥島) | EPSG2460 | EPSG6686 | - |
| (平面直角座標19系) | (南鳥島) | EPSG2461 | EPSG6687 | - |
| ※無人地域はカッコ付けしています |
後述の実装においてもEPSGコードの知識は必須となるので、上の表を活用してください
特にJGD2000の緯度経度座標である「EPSG4612」とWGS84の緯度経度座標である「EPSG4326」は非常に良く使われるので、覚えておいて損はないかと思います
osgeoライブラリによる座標変換
座標変換をなるべく自動化したいのであれば、osgeoライブラリ(ogrクラスとosrクラス)が便利です。
ogrクラスが.prjファイルから変換前の座標系を自動で読み取り、osrクラスで座標変換を実行できます。
先述の釧路市の農場データで、平面直角座標から緯度経度への座標変換を実行してみます。
# shpファイルから座標系取得
shp = ogr.GetDriverByName('ESRI Shapefile').Open(FARM_PATH, 0)
src_srs = shp.GetLayer().GetSpatialRef()
src_srs_name = src_srs.GetName() if src_srs is not None else 'なし'
print(f'変換前の座標系{src_srs_name}')
# 変換後の座標系を指定
dst_srs = osr.SpatialReference()
dst_srs.ImportFromEPSG(4612) # EPSGコードを指定
print(f'変換後の座標系{dst_srs.GetName()}')
# 変換式を作成
trans = osr.CoordinateTransformation(src_srs, dst_srs)
shp.Destroy() # shapefileを閉じる
# 取得した座標系を基に座標変換(pyshpライブラリで読み込んだデータにosgeoライブラリで作成した変換式適用)
for shp in shps_farm:
print(f'変換前ポリゴン位置{shp.points}') # 位置情報(座標変換前)
# 座標変換を実行
points_transfer = list(map(lambda point: trans.TransformPoint(point[0], point[1])[:2], shp.points))
print(f'変換後ポリゴン位置{points_transfer}') # 位置情報(座標変換後)
使用しているosgeoライブラリのクラスとメソッドの内容は以下となります
| クラスorメソッド | 処理内容 |
|---|---|
| GetDriverByNameメソッド | 開くファイル種類を指定し、Openメソッドでファイルを開く |
| GetLayerメソッド | レイヤーを取得し、GetSpatialRefで座標系を取得(後述のosr.SpatialReferenceクラスで保持) |
| (・GetNamesメソッド) | (座標系の名称を取得 → 座標変換には使用していない) |
| osr.SpatialReferenceクラス | 座標系を保持 |
| ImportFromEPSGメソッド | EPSGコードから座標系を取得 |
| osr.CoordinateTransformationクラス | 座標変換式を保持 |
| TransformPointメソッド | 座標変換を実行 |
また、最後のshp.Destroy()は、読み込んだShapefileが開きぱなしとなりロックされることを防ぎます。
ポリゴンの座標を一括で変換しているため、変換実行部分はmapを使った少し複雑な実装となっていますが、変換自体は
trans.TransformPoint(point[0], point[1])
の部分が該当します。
変換前の座標系JGD2000 / Japan Plane Rectangular CS XIII
変換後の座標系JGD2000
変換前ポリゴン位置[(-12183.815876618528, -78293.83192835805), (-12182.6399506926, -78291.95044687657), (-12167.352913655564, -78288.65785428397), (-12166.412172914825, -78294.77266909879), (-12162.649209951862, -78303.94489132102), (-12180.75846921112, -78308.17822465434), (-12183.815876618528, -78293.83192835805)]
変換後ポリゴン位置[(43.29515003938805, 144.09984479201268), (43.295166995303745, 144.09985924258658), (43.29519688199948, 144.10004756895728), (43.29514185229627, 144.1000592980005), (43.295059345723665, 144.10010587596648), (43.29502094503654, 144.0998827895099), (43.29515003938805, 144.09984479201268)]
変換前がメートル単位の平面直角座標(13系)だったのに対し、変換後は緯度経度となっていることがわかいます。
なお、入力ファイルによっては座標系が設定されていない事もありますが、この場合srt_srsに対してもImportFromEPSGメソッドで手動座標系指定する必要があります。
pyprojライブラリによる座標変換
osgeoは座標系を自動取得できる分、実装が少し複雑となりますが、
pyprojライブラリを使えばよりシンプルに実装できます(ファイルからの座標系自動取得はできない)
# 変換前後の座標系指定(平面直角座標13系(EPSG2455) → 緯度経度(EPSG4612))
src_proj = 'EPSG:2455' # 変換前の座標系を指定
dst_proj = 'EPSG:4612' # 変換後の座標系を指定
transformer = pyproj.Transformer.from_crs(src_proj, dst_proj) # 変換式を作成
# 取得した座標系を基に座標変換(pyshpライブラリで読み込んだデータにosgeoライブラリで作成した変換式適用)
for shp in shps_farm:
print(f'変換前ポリゴン位置{shp.points}') # 位置情報(座標変換前)
# 座標変換を実行
points_transfer = list(map(lambda point: transformer.transform(point[0], point[1]), shp.points))
print(f'変換後ポリゴン位置{points_transfer}') # 位置情報(座標変換後)
座標の一括変換
for文で座標変換すると、所要時間も行数も増大してしまうので、全てのジオメトリを一括座標変換したいときは、リスト内包表記が便利です。
ポイント、ライン、ポリゴンそれぞれをosgeoライブラリで一括座標変換するサンプルコードを下記します(変換前の座標系は手動指定)
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標135度(EPSG3099) Osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# ポイント(ダムデータ、TransformPointの引数は緯度,経度の順番で指定)
dam_points_utm = [list(trans.TransformPoint(shp.points[0][1], shp.points[0][0])[:2]) for shp in shps_dam]
# ライン(河川データ)
river_lines_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_river]
# ポリゴン(湖沼データ)
lake_polys_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_lake]
上の例ではリスト内包表記とmapを組み合わせていますが、リスト内包表記を2重にしても良いかと思います。
処理2:ポイントデータへの変換
ポイントをpythonで扱う際は、shapelyライブラリのPointクラスに読み込むと便利な機能(後述の距離測定など)が使えます。
変換は、下記コードのようにPointクラスの引数にポイント座標のタプル(shp.points[0])を渡せばOKです
for shp in shps_dam:
points = Point(shp.points[0])
処理3:ポイントデータ間の距離測定
ポイント間での距離算出は、非常にポピュラーで需要が高い処理です。
平面座標系のときと緯度経度座標系のときで大きく方法が異なるので、ご注意ください
平面座標系のとき
メートル単位の平面座標系のときは、shapelyライブラリのPoint.distanceメソッドで距離が算出できます
point1 = Point(0, 0)
point2 = Point(1, 1)
dist = point1.distance(point2)
print(f'距離={dist}')
距離=1.4142135623730951
緯度経度座標系のとき
緯度経度座標で保持されたデータも、同様にPoint.distanceメソッドで距離が計算できます‥とはなりません
緯度経度は球面上での座標のため、平面を前提としたPoint.distanceメソッドでは大きなずれが生じます。
日本がある北緯35度付近では、緯度1度が110kmに対して経度1度が90kmと20%前後のずれがあるのに加え、位置関係が遠くなると球面による歪みの影響も大きくなります。
この歪みの影響を避けて距離を測定するためには、下記2種類の方法が使用できます。
1. UTM座標に変換してPoint.distanceメソッドで距離算出
2. pyproj.Geodメソッドを使用して距離算出
両者の違いを比較するため、こちらのデータを使用して、各ダムから都道府県庁までの距離を求めてみます
# 県庁所在地の座標を読込
df_prefecture = pd.read_csv('./prefecture_location.csv', encoding='cp932')
# 緯度経度の分秒を小数に変換
df_prefecture['longitude'] = df_prefecture['都道府県庁 経度'].apply(lambda x: float(x.split('°')[0])
+ float(x.split('°')[1].split("'")[0]) / 60
+ float(x.split("'")[1].split('"')[0]) / 3600)
df_prefecture['latitude'] = df_prefecture['都道府県庁 緯度'].apply(lambda x: float(x.split('°')[0])
+ float(x.split('°')[1].split("'")[0]) / 60
+ float(x.split("'")[1].split('"')[0]) / 3600)
# 県庁所在地の緯度経度をdict化
dict_pref_office = {row['都道府県']: (row['longitude'], row['latitude']) for i, row in df_prefecture.iterrows()}
距離算出法1:UTM座標に変換してPoint.distanceで距離算出
ひとつ目の方法は、Point.distanceメソッドで距離算出できるよう平面座標系に変換することです。
このとき、カバー範囲の狭い平面直角座標よりも、範囲の広いUTM座標に変換した方が便利です。
対象のポイントをカバーする座標系を使うのが理想ですが、日本の中心付近にある53系(EPSG3099)、または54系(EPSG3100)を利用すれば、全国どこでもそこそこの精度で距離が算出できます
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標54系(EPSG3100) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3100)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# ダムデータを1点ずつ走査
for shp, rec in zip(shps_dam, recs_dam):
# ダムの位置(UTM座標に変換)
dam_point = trans.TransformPoint(shp.points[0][1], shp.points[0][0])[:2]
# 都道府県名を所在地から正規表現で抜き出して位置変換
prefecture = re.match('..*?県|..*?府|東京都|北海道', rec['W01_013']).group()
pref_office_point = dict_pref_office[prefecture] # 県庁所在地の緯度経度
pref_office_point = trans.TransformPoint(pref_office_point[1], pref_office_point[0])[:2]
# ポイントデータとして格納(shapelyライブラリ使用)
dam_point = Point(dam_point)
pref_office_point = Point(pref_office_point)
# 距離を計算(shapelyライブラリ使用)
dist = dam_point.distance(pref_office_point)
print(f'{rec["W01_001"]}ダム {prefecture}庁まで{dist/1000}km')
駒込ダム 青森県庁まで17.71005113357471km
:
中城ダム 沖縄県庁まで14.50710866265267km
石垣ダム 沖縄県庁まで418.66715344646536km
距離算出法2:pyproj.Geodを使用して距離算出
pyproj.Geodメソッドを利用すると、座標変換なしで緯度経度から直接距離を求めることができます(参考)
方法1のようなカバー範囲の制約もないので、特別な理由がなければこちらの方法がオススメです。
# 距離測定用のGRS80楕円体
grs80 = pyproj.Geod(ellps='GRS80')
# ダムデータを1点ずつ走査
for shp, rec in zip(shps_dam, recs_dam):
# ダムの位置(緯度経度)
dam_point = shp.points[0]
# 都道府県名を所在地から正規表現で抜き出し
prefecture = re.match('..*?県|..*?府|東京都|北海道', rec['W01_013']).group()
pref_office_point = dict_pref_office[prefecture] # 県庁所在地の緯度経度
# 距離を計算(pyproj.Geod使用)
azimuth, bkw_azimuth, dist = grs80.inv(dam_point[0], dam_point[1], pref_office_point[0], pref_office_point[1])
print(f'{rec["W01_001"]}ダム {prefecture}庁まで{dist/1000}km')
駒込ダム 青森県庁まで17.717080913897718km
:
中城ダム 沖縄県庁まで14.200787571626435km
石垣ダム 沖縄県庁まで406.95145701089456km
2種類の算出法のうち、精度が高いのは緯度経度からの距離算出専用クラスであるpyproj.Geodです。
両者の距離の差は、青森県(UTM54座標系の範囲内)で18kmの距離で0.03%、沖縄県(UTM54座標系の範囲外)で14kmの距離で2%、400kmの距離で3%だと分かりました。
UTM座標系の範囲から外れるほど、また距離の絶対値が大きくなるほど誤差が大きくなることがわかります。
これらの条件を満たすときは、pyproj.Geodを使って距離算出した方が良いかと思います。
他にもGeopyを使う距離算出法もあります参考
距離を一括算出
「距離の最大値」のような統計値を計算したいとき、リスト内包表記で距離を一括算出すると便利です。
下の例では、pyplot.Geodで都道府県庁からの距離を一括算出し、最も遠いダムを求めています。
# 距離測定用のGRS80楕円体
grs80 = pyproj.Geod(ellps='GRS80')
# 都道府県名を所在地から正規表現で抜き出し
prefectures = [re.match('..*?県|..*?府|東京都|北海道', rec['W01_013']).group() for rec in recs_dam]
pref_office_points = [dict_pref_office[prefecture] for prefecture in prefectures] # 県庁所在地の緯度経度
# 距離を計算(pyproj.Geod使用)
dists = [grs80.inv(shp.points[0][0], shp.points[0][1], pref[0], pref[1])[2] for shp, pref in zip(shps_dam, pref_office_points)]
# 都道府県庁から最も遠いダムを表示
farthest_index = np.argmax(dists)
print(f'{prefectures[farthest_index]}庁から最も遠いダム={recs_dam[farthest_index]["W01_001"]}ダム 距離={dists[farthest_index]/1000}km')
東京都庁から最も遠いダム=乳房ダム 距離=1029.7692879063898km
都道府県庁から最も遠いダムは、なんと東京都にあるようです!
どこやねん!!
と思われた方のために調べたところ、絶海の孤島、小笠原諸島の母島にあるようです。

このように、最大値のような統計値をとる分析をしたい場合、一括処理が非常に便利です。
データ分析ではおなじみのテクニックですが、リスト内包表記やmap、apply、zip関数、ラムダ式などに慣れておくと、GISデータの活用においても有用かと思います。
処理4:最も近いポイントを探す
最も近い点を探す問題は「最近傍探索」と呼ばれており、様々なライブラリが存在します。
今回は機械学習でおなじみのScikit-LearnのNearestNeighborsクラスを利用します。
最近傍だけでなく「k番目に近い点」も探索できるのが便利です。
距離を算出するためには平面上の座標に変換する必要があるので、下のサンプルコードではUTM座標に事前変換しています
from sklearn.neighbors import NearestNeighbors
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標135度(EPSG3099) Osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# UTM座標に変換
dam_points_utm = [trans.TransformPoint(shp.points[0][1], shp.points[0][0])[:2] for shp in shps_dam]
# 全点の位置関係を学習
dam_points_array = np.array(dam_points_utm) # ndarray化
nn = NearestNeighbors(algorithm='ball_tree')
nn.fit(dam_points_array)
# ダムデータを1点ずつ走査
for shp, rec in zip(shps_dam, recs_dam):
# 最近傍点を探索
point_utm = trans.TransformPoint(shp.points[0][1], shp.points[0][0])[:2] # UTM座標に変換
point_utm = np.array([list(point_utm)]) # ndarrayに変換
dists, result = nn.kneighbors(point_utm, n_neighbors=3) # 近傍上位3点を探索
# 見付かった最近傍点(1番目は自身なので、2番目に近い点が最近傍点)を表示
rec_nearest = recs_dam[result[0][1]] # 最近傍点の属性データ取得
dist_nearest = dists[0][1]/1000 # 最近傍点までの距離(m単位なのでkm単位に変換ん)
print(f'{rec["W01_001"]}ダムから最も近いダム: {rec_nearest["W01_001"]}ダム 距離={dist_nearest}km')
駒込ダムから最も近いダム: 下湯ダム 距離=9.241586379700022km
:
Scikit-learn以外にも、shapelyを使う方法や各種最近傍探索ライブラリを使う方法があります。
いずれの方法も、座標系の変換は必須なので、前述の誤差の問題が発生します。
誤差を最小化するためには、対象の位置をカバーする座標系(UTM座標、平面直角座標)の選択が重要です
最も近いポイントを一括算出
NearestNeighborsクラスのkneighborsメソッドに全点の座標を渡せば、
各ポイントから最も近いポイントを一括算出できます。
下のサンプルコードでは、最も近いダムまでの距離が最大のダムを求めています
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標135度(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# UTM座標に変換
dam_points_utm = [trans.TransformPoint(shp.points[0][1], shp.points[0][0])[:2] for shp in shps_dam]
# 全点の位置関係を学習
dam_points_array = np.array(dam_points_utm) # ndarray化
nn = NearestNeighbors(algorithm='ball_tree')
nn.fit(dam_points_array)
# 最近傍点を一括探索
dists, results = nn.kneighbors(dam_points_array)
# 見付かった最近傍点(1番目は自身なので、2番目に近い点が最近傍点)と距離を保持
rec_nearest = [recs_dam[result] for result in results[:,1]] # 最近傍点の属性データ取得
dist_nearest = [dist/1000 for dist in dists[:,1]] # 最近傍点までの距離(m単位なのでkm単位に変換)
# 最も近いダムからの距離が最大のダムを表示
farthest_index = np.argmax(dist_nearest)
print(f'最近傍ダムからの距離が最大のダム={recs_dam[farthest_index]["W01_001"]}ダム\
最近傍ダム={rec_nearest[farthest_index]["W01_001"]}ダム\
距離={dist_nearest[farthest_index]}km')
最近傍ダムからの距離が最大のダム=新堤ダム 最近傍ダム=青野大師ダム 距離=203.02523976527996km
今回も
「どこやねん!!」
と思われた方のために調べたところ、東京都の八丈島にあるようです。
(最も近い青野大師ダムは静岡県)

処理5:ラインデータへの変換
ラインをpythonで扱う際は、shapelyライブラリのLineStringクラスに読み込むと便利な機能(後述のライン長さ測定等)が使えます。
変換は、下記コードのようにLineStringクラスの引数に座標のリスト(shp.points)を渡せばOKです
for shp, rec in zip(shps_river, recs_river):
line = LineString(shp.points)
処理6:ラインの長さ測定
ラインデータを扱う際には、ラインの長さを求めたい場面が多々発生します。
基本的にはLineStringクラスのlengthプロパティから長さを取得できますが、
緯度経度座標系のときは事前に座標変換が必要なので、ご注意ください。
変換先の座標は、UTM座標 or 平面直角座標から位置に合わせて選択してください
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標53N系(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# 河川データを1点ずつ走査
for shp, rec in zip(shps_river, recs_river):
# UTM座標に変換
river_utm = list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points))
# ラインデータに変換
line = LineString(river_utm)
# 長さを算出して表示
length = line.length
print(f'{rec["W05_004"]} 長さ={length}m')
金勝川 長さ=102.29698101602632m
:
長さを一括算出
上位ランキング等の統計値を求めたい際は、リスト内包表記で一括座標変換 → 一括長さ算出が便利です。
下の例では、滋賀県の河川長さランキングを求めています。
※河川が分割して登録されているので、河川名でグルーピングして長さの合計値算出しています
※琵琶湖と名称不明はランキング対象として不適なので、除外しています
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標53N系(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# UTM座標に一括変換
lines_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_river]
# ラインデータに変換し長さを一括算出(km単位にするため1000で割る)
length_list = [LineString(points).length/1000 for points in lines_utm]
# 河川名をリスト化
river_names = [rec['W05_004'] for rec in recs_river]
# 河川名の重複があるので、Pandas DataFrameに読み込んでグルーピング
df_river = pd.DataFrame(np.array([river_names, length_list]).T, columns=['name', 'length'])
df_river = df_river.astype({'length': float})
# 河川名グルーピングして長さ降順でソート
df_length = df_river.groupby('name').sum().sort_values('length', ascending=False)
# 名称不明と琵琶湖を除外
df_length = df_length[~df_length.index.isin(['名称不明', '琵琶湖'])]
print(df_length.head(5))
length
name
野洲川 67.495013
安曇川 55.069210
愛知川 53.348960
日野川 49.800100
高時川 47.912388
こちらのリンクの滋賀県の川の長さ上位5位と、要素自体は一致していそうです(3~5位の順位が異なりますが、Wikipediaでは愛知川48km、日野川46.7km、高時側41.4kmと出力結果の順位と一定しているので、集計方法により順位が変わっているのだと思います。また、今回使用した河川データは琵琶湖の仲までラインが引かれているので、実際の川の長さよりも長く算出されています)
処理7:ポリゴンデータへの変換
ポリゴンをpythonで扱う際は、shapelyライブラリのPolygonクラスに読み込むと便利な機能(後述の重心、面積測定等)が使えます。
変換方法に少し癖があるので、下記にご注意ください
※ポリゴンデータの注意点
ポイントやラインと異なり、pyshpで読み込んだshp.pointsをそのままPolygonクラスの引数に渡すと、穴部分が全て結合され、ポリゴンが正しく読み込まれません
for shp, rec in zip(shps_lake, recs_lake):
poly = Polygon([shp.points])
このとき、shp.pointsの中身は、
[外周の座標1, 外周の座標2,‥, 穴1の座標1, 穴1の座標2,‥, 穴2の座標1, 穴2の座標2,‥]
のように、外周と穴が結合した状態となっています。
これをそのままPolygonクラスに読み込むと、下図のように外周と穴(湖の場合「島」に相当)が結合した誤ったポリゴンが生成されてしまいます。

pyshpで読み込んだShapeクラスには、どのインデックス以降が穴の座標かを表すshp.partsプロパティが含まれているので、shp.partsのインデックスでshp.pointsを分割して
[[外周の座標1, 外周の座標2,‥],
[穴1の座標1, 穴1の座標2,‥],
[穴2の座標1, 穴2の座標2,‥]]
のようにリスト化してからPolygonクラスに読み込むことで、穴を正しく表現することができます。
for shp, rec in zip(shps_lake, recs_lake):
parts = [i for i in shp.parts] + [len(shp.points) - 1]
points_hole = [shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
poly = Polygon(points_hole[0], points_hole[1:])

処理8:ポリゴンの重心測定
ポリゴンデータの座標をどこか1つの代表点にまとめたいとき、重心算出が便利です。
基本的にはPolygonクラスのcentroid.coordsプロパティから重心を取得できます。
緯度経度座標の場合、精度を重視するのであれば事前に平面座標に変換する事が望ましいですが、
ライン長さとは異なり、緯度経度座標のままでもそこそこの精度で重心を求めることができます。
緯度経度座標のまま算出
緯度経度座標のまま重心を算出してみます
# 湖沼データを1点ずつ走査
for shp, rec in zip(shps_lake, recs_lake):
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(shp.points) - 1]
points_hole = [shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ポリゴンデータに変換
poly = Polygon(points_hole[0], points_hole[1:])
# 重心を算出
center = list(poly.centroid.coords)[0]
print(f'{rec["W09_001"]} 重心={center}')
さっぽろ湖 重心=(141.14867614403863, 43.00018728073415)
:
霞ヶ浦 重心=(140.37323343888406, 36.042847739825625)
:
琵琶湖 重心=(136.08878954009663, 35.28527410588072)
:
UTM座標に変換して算出
精度向上のため、UTM座標に変換して重心を算出してみます
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標53N系(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs) # 緯度経度→UTM座標への変換式
trans_reverse = osr.CoordinateTransformation(dst_srs, src_srs) # UTM座標→緯度経度への逆変換
# 湖沼データを1点ずつ走査
for shp, rec in zip(shps_lake, recs_lake):
# UTM座標に変換
lake_utm = list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points))
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(lake_utm) - 1]
points_hole = [lake_utm[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ポリゴンデータに変換
poly = Polygon(points_hole[0], points_hole[1:])
# 重心を算出
center_utm = list(poly.centroid.coords)[0]
# 緯度経度座標に戻す(TransformPointは緯度→経度の順で返すので、元の座標系に合わせ経度を先に反転させる)
center = tuple(trans_reverse.TransformPoint(center_utm[0], center_utm[1])[1::-1])
print(f'{rec["W09_001"]} 重心={center}')
さっぽろ湖 重心=(141.14867860778017, 43.00018596200766)
:
霞ヶ浦 重心=(140.37327735295187, 36.042836688005195)
:
琵琶湖 重心=(136.08860483036526, 35.28517147865989)
:
両算出法の差
目安として、琵琶湖(長径65km)で20m(長径比0.03%)、霞ヶ浦(長径28km)で4.1m(長径比0.02%)ほどのずれとなっています。
基本的にサイズが大きくなるほど球面の歪の影響によりずれが大きくなりますが、このずれを許容できる場合は、前述の緯度を使った算出法で問題ないかと思います。
重心位置の一括算出
位置関係をランク付けしたい際などには、リスト内包表記で重心位置を一括算出すると効率的です。
下の例では、緯度経度座標のまま重心位置を一括算出し、最も緯度が大きい(北にある)湖沼を求めています
# shp.partsに基づきポリゴン点を一括分割
parts_list = [[i for i in shp.parts] + [len(shp.points) - 1] for shp in shps_lake]
points_hole_list = [[shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)] for shp, parts in zip(shps_lake, parts_list)]
# 重心位置を一括計算
centers = [tuple(list(Polygon(points_hole[0], points_hole[1:]).centroid.coords)[0]) for points_hole in points_hole_list]
# 重心が最も北にある湖を表示
northest_index = np.argmax([center[1] for center in centers])
print(f'重心が最も北にある湖={recs_lake[northest_index]["W09_001"]} 北緯{centers[northest_index][1]}度')
重心が最も北にある湖=久種湖 北緯45.431622616632914度
処理9:ポリゴンの面積測定
ポリゴンデータの主用途の一つに、面積の算出があります
面積は基本的にPolygonクラスのareaプロパティから取得できますが、
緯度経度座標系のときは事前に座標変換が必要なので、ご注意ください。
変換先の座標は、UTM座標 or 平面直角座標から位置に合わせて選択してください
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標53N系(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs) # 緯度経度→UTM座標への変換式
# 湖沼データを1点ずつ走査
for shp, rec in zip(shps_lake, recs_lake):
# UTM座標に変換
lake_utm = list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points))
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(lake_utm) - 1]
points_hole = [lake_utm[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ポリゴンデータに変換
poly = Polygon(points_hole[0], points_hole[1:])
# 面積を算出(m2 → km2に単位変換)
area = poly.area/1000000
print(f'{rec["W09_001"]} 面積={area}km2')
さっぽろ湖 面積=1.7843064500985144km2
:
霞ヶ浦 面積=168.46126253416477km2
:
琵琶湖 面積=669.4501123974004km2
:
Wikipediaでは琵琶湖の面積は669.26km2なので、概ね正しく算出できていそうです
面積を一括算出
上位ランキング等の統計値を求めたい際は、一括座標変換 → 一括面積算出が便利です。
下の例では、面積最大の湖を求めています。
# 変換前後の座標系指定(緯度経度(EPSG4612) → UTM座標53N系(EPSG3099) osgeo.osrを使用)
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
# UTM座標に一括変換
polys_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_lake]
# shp.partsに基づきポリゴン点を一括分割
parts_list = [[i for i in shp.parts] + [len(shp.points) - 1] for shp in shps_lake]
points_hole_list = [[poly[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)] for poly, parts in zip(polys_utm, parts_list)]
# 面積を一括計算
areas = [Polygon(points_hole[0], points_hole[1:]).area/1000000 for points_hole in points_hole_list]
# 面積最大の湖を表示
biggest_index = np.argmax(areas)
print(f'面積最大の湖={recs_lake[biggest_index]["W09_001"]} 面積={areas[biggest_index]}km2')
面積最大の湖=琵琶湖 面積=669.4501123974004km2
処理10:名称・住所から緯度経度検索(ジオコーディング)
名称や住所から緯度経度を検索することを、「ジオコーディング」と呼びます。
ジオコーディングの代表的なライブラリとして、geopyが挙げられます。
geopyは、ジオコーディングを提供する外部サービスのAPIを叩いて結果を返すライブラリです。
この外部サービスのうちよく使われるものは、以下となります。
| 名称 | 概要 | 特徴 | geopyでの使用法リンク |
|---|---|---|---|
| Nominatim | オープンソースの地図 OpenStreetMapが提供するAPI | フリーかつ登録不要 | リンク |
| GoogleV3 | Googleが提供するAPI | Google Maps APIへの登録が必要 | リンク |
| Bing | Bingが提供するAPI | リンク |
geopyの注意点として、APIを叩いているのでリクエスト数に上限(サービスごとに異なる)があることです。
Nominatimの場合、1秒当たり1回が上限として定められています。
そのため、一度に大量のジオコーディングを実行しないように注意してください
下のサンプルコードでは、堤高150m以上のダムの緯度経度をNominatimジオコーディングで検索し、Shapefileの座標と比較しています
from geopy.geocoders import Nominatim
# 堤高150m以上のダムに絞る(リクエスト数を減らすため)
over150m_indices = [i for i, rec in enumerate(recs_dam) if rec['W01_007'] > 150]
over150m_shps = [shp for i, shp in enumerate(shps_dam) if i in over150m_indices]
over150m_recs = [rec for i, rec in enumerate(recs_dam) if i in over150m_indices]
# Nominatimを指定
geolocator = Nominatim(user_agent='test')
# ダムを走査
for shp, rec in zip(over150m_shps, over150m_recs):
# ジオコーディング
name = f'{rec["W01_001"]}ダム' # ダム名で検索
location = geolocator.geocode(name) # ジオコーディング実行
# 検索結果が得られたときのみ表示
if location is not None:
print(f'{rec["W01_001"]}ダム Nominatim座標={location.latitude, location.longitude} Shapefile座標={shp.points[0][1], shp.points[0][0]}')
奈良俣ダム Nominatim座標=(36.881349099999994, 139.07862956264304) Shapefile座標=(36.88255707077635, 139.07974492849385)
宮ヶ瀬ダム Nominatim座標=(35.5418887, 139.24958498703745) Shapefile座標=(35.54238903998771, 139.24936339562964)
浦山ダム Nominatim座標=(35.9536136, 139.05290375860193) Shapefile座標=(35.95398639039371, 139.0518627456571)
奥只見ダム Nominatim座標=(37.154355249999995, 139.24989095274884) Shapefile座標=(37.153983262000054, 139.24976516900006)
黒部ダム Nominatim座標=(36.5666941, 137.66363857226673) Shapefile座標=(36.56647116200003, 137.66208790500002)
手取川ダム Nominatim座標=(36.264979049999994, 136.6449363862047) Shapefile座標=(36.265276726000025, 136.64386447700008)
奈川渡ダム Nominatim座標=(36.13263465, 137.72041830713633) Shapefile座標=(36.13266115400006, 137.71839754300004)
高瀬ダム Nominatim座標=(35.5418887, 139.24958498703745) Shapefile座標=(36.473813094000036, 137.69002646700005)
徳山ダム Nominatim座標=(35.66599185, 136.5013996895242) Shapefile座標=(35.66363873700004, 136.50202871600004)
温井ダム Nominatim座標=(34.634732, 132.302024) Shapefile座標=(34.63431705000001, 132.29948245)
Shapefileの座標とほぼ等しい位置となっており、正しくジオコーディングできていることが分かります
Nominatimクラスで外部サービス(Nominatim)を指定し、geocodeメソッドでジオコーディングを実行しています。
なお、Nominatimクラスの引数「user_agent」は、リクエスト数(検索の回数)が少ないときは"test"のような適当な名前で構いませんが、リクエスト数が多い時は有効なメールアドレスを使用して下さいと、Nominatim公式wikiに記載されています。
処理11:緯度経度から住所を取得(逆ジオコーディング)
ジオコーディングとは逆に、緯度経度から住所を取得する方法を「逆ジオコーディング」と呼びます。
逆ジオコーディングも、ジオコーディング同様にgeopyライブラリで実現可能です。
geocodeメソッドの代わりにreverseメソッドを使用します。
from geopy.geocoders import Nominatim
# 堤高150m以上のダムに絞る
over150m_indices = [i for i, rec in enumerate(recs_dam) if rec['W01_007'] > 150]
over150m_shps = [shp for i, shp in enumerate(shps_dam) if i in over150m_indices]
over150m_recs = [rec for i, rec in enumerate(recs_dam) if i in over150m_indices]
# Nominatimを指定
geolocator = Nominatim(user_agent='test')
# ダムを走査
for shp, rec in zip(over150m_shps, over150m_recs):
# 逆ジオコーディング
point_str = f'{shp.points[0][1]}, {shp.points[0][0]}' # "緯度, 経度"を指定
location = geolocator.reverse(point_str) # 逆ジオコーディング実行
print(f'{rec["W01_001"]}ダム {location.address}')
奈良俣ダム みなかみ町, 利根郡, 群馬県, 379-1721, 日本
宮ヶ瀬ダム ダム下 山麓駅, 玉すだれの滝トンネル, 半原, 緑区, 愛川町, 愛甲郡, 神奈川県, 243-0306, 日本
浦山ダム 秩父市, 埼玉県, 日本
奥只見ダム 魚沼市, 南会津郡, 新潟県, 日本
黒部ダム 黒部ダム, かんぱ谷橋, 立山町, 中新川郡, 富山県, 日本
手取川ダム 白山市, 石川県, 920-2336, 日本
奈川渡ダム 国道158号, 松本市, 長野県, 日本
高瀬ダム 大町市, 長野県, 日本
徳山ダム 国道417号, 揖斐川町, 揖斐郡, 岐阜県, 日本
佐久間(再)ダム 飯田富山佐久間線, 天竜区, 浜松市, 北設楽郡, 静岡県, 日本
佐久間(元)ダム 飯田富山佐久間線, 天竜区, 浜松市, 北設楽郡, 静岡県, 日本
温井ダム 安芸太田町, 山県郡, 広島県, 日本
保存1:ポイントのファイル出力
Shapefile形式での保存(pyshpライブラリ使用)と、GeoJSON形式での保存(geojsonライブラリ使用)の2種類を紹介します。
サンプルとして、堤高100m以上のダムに絞ったデータを出力します
Shapefile形式での出力
Shapefile形式での出力には、pyshpライブラリを使用します
# 出力用のデータ(堤高100m以上のダム)作成
# 堤高100m以上のインデックス取得
over100m_indices = [i for i, rec in enumerate(recs_dam) if rec['W01_007'] > 100]
# 堤高100m以上のジオメトリと属性取得
over100m_shps = [shp for i, shp in enumerate(shps_dam) if i in over100m_indices]
over100m_recs = [rec for i, rec in enumerate(recs_dam) if i in over100m_indices]
# Shapefileを出力
outpath = './dams_over100m/dams_over100m.shp'
with shapefile.Writer(outpath, encoding='cp932') as w:
# 属性のフィールドを定義(名前、型、サイズ、精度を入力)
w.field('ダム名', 'C', 50, 0)
w.field('堤高', 'F', 12, 6)
w.field('総貯水量', 'F', 12, 6)
# ジオメトリと属性値を行ごとに追加
for shp, rec in zip(over100m_shps, over100m_recs):
# ジオメトリ(ポイント)を追加
w.point(shp.points[0][0], shp.points[0][1])
# 属性値を追加
attr = (f'{rec["W01_001"]}ダム', rec['W01_007'], rec['W01_010'])
w.record(*attr)
# プロジェクションファイル作成 (EPSG:4612)
with open('./dams_over100m/dams_over100m.prj', 'w') as prj:
epsg = 'GEOGCS["JGD2000",DATUM["Japanese_Geodetic_Datum_2000",SPHEROID["GRS 1980",6378137,298.257222101]],TOWGS84[0,0,0,0,0,0,0],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
prj.write(epsg)
Shapefile本体の出力の手順は下記となります
・shapefile.Writerで出力用クラスを開く
・w.fieldで属性のフィールドを定義(型の指定方法は後述)
↓ここから下はforで1レコードごとに処理
・w.pointでポイントのジオメトリを追加
・w.recordで属性値を追加(*でタプルを渡すと便利です)
指定できるフィールドの型には、以下があります
| 指定文字 | 説明 | よく使われるサイズ |
|---|---|---|
| F | 実数(pythonのfloatに相当) | 12 |
| N | 整数(pythonのintに相当) | 8 |
| D | 日付(pythonのdateに相当) | 8 |
| C | 文字列(pythonのstrに相当) | 50 |
また、w.recordで日付型の属性値を渡す際は、下記3種類(pythonのdate型、年月日の数字をリスト渡し、'yyyymmdd')の方法が使用できます
from datetime import date
w.record(date(1898,1,30))
w.record([1998,1,30])
w.record('19980130')
末尾のプロジェクションファイル(.proj)出力は、"epsg ="以降の文字列(WKTと呼びます)を出力したい座標系に合わせて変える必要があります。
よく使う座標系でのWKT指定例を下記します。
epsg = 'GEOGCS["JGD2000",DATUM["Japanese_Geodetic_Datum_2000",SPHEROID["GRS 1980",6378137,298.257222101]],TOWGS84[0,0,0,0,0,0,0],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
epsg = 'GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
その他の座標系も、こちらのサイトの"Well Known Text (WKT)"と書いてある枠内のテキストを.projファイル内に書き込めば基本的にOKです
参考までに、出力したShapefileをQGISで可視化してみます。

入力ファイルと比べ、堤高100m以上に絞った分だけダムの数が減っており、正しく出力できていそうです
GeoJSON形式での出力
GeoJSON形式での出力には、geojsonライブラリを使用します
import json
import geojson
# 出力用のデータ(堤高100m以上のダム)作成
# 堤高100m以上のインデックス取得
over100m_indices = [i for i, rec in enumerate(recs_dam) if rec['W01_007'] > 100]
# 堤高100m以上のジオメトリと属性取得
over100m_shps = [shp for i, shp in enumerate(shps_dam) if i in over100m_indices]
over100m_recs = [rec for i, rec in enumerate(recs_dam) if i in over100m_indices]
# GeoJSONを出力
outpath = './dams_over100m.geojson'
with open(outpath, 'w', encoding='cp932') as w:
feature_list = [] # Featureのリスト
# ジオメトリと属性値を行ごとに追加
for i, (shp, rec) in enumerate(zip(over100m_shps, over100m_recs)): # enumerateでIDを付けた方があとで検索しやすい
# ジオメトリ(ポイント)を作成
point = geojson.Point((shp.points[0][0], shp.points[0][1]))
# 属性値を作成
attr = {'ダム名': f'{rec["W01_001"]}ダム',
'堤高': float(rec['W01_007']),
'総貯水量': float(rec['W01_010'])
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=point, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# geojsonファイルに書き出し
w.write(json.dumps(feature_collection, indent=2))
Shapefileのときとデータの格納方法が異なり、GeoJSONでは
Point → Feature → FeatureCollection
というクラスの階層構造で格納を実施します。
具体的には、下記手順で実装します
・openクラスで出力用geojsonファイルを開く
・空のリスト(Featureクラス格納用)を準備
↓ここから下はforで1レコードごとに処理
・Pointクラスにジオメトリ(ポイント)を格納
・Pointクラスと属性とIDをまとめてFeatureクラスに格納
・Featureクラスをリストに格納
↓ここから下は
・FeatureクラスのリストをFeatureCollectionクラスに変換
・json.dumpsでJSONに変換し、geojsonファイルに書き出し
出力ファイルは以下のGitHubリポジトリにもアップロードしました
(GeoJSONはGitHubで表示できるのが素晴らしいですね!)
保存2:ラインのファイル出力
Shapefile形式での保存と、GeoJSON形式での保存の2種類を紹介します。
サンプルとして、長さ上位5位までの河川データを出力します
Shapefile形式での出力
ジオメトリ追加メソッドがw.lineとなること以外は、
ポイントデータ出力のときと、基本的に同様です。
# 出力用のデータ(上位5位の河川に絞る)作成
# 名称不明と琵琶湖以外のインデックス取得
river_top5_indices = [i for i, rec in enumerate(recs_river) if rec['W05_004'] in ['野洲川', '安曇川', '愛知川', '日野川', '高時川']]
# 名称不明と琵琶湖以外のジオメトリと属性取得
river_top5_shps = [shp for i, shp in enumerate(shps_river) if i in river_top5_indices]
river_top5_recs = [rec for i, rec in enumerate(recs_river) if i in river_top5_indices]
# Shapefileを出力
outpath = './river_top5/river_top5.shp'
with shapefile.Writer(outpath, encoding='cp932') as w:
# 属性のフィールドを定義(名前、型、サイズ、精度を入力)
w.field('河川名', 'C', 50, 0)
w.field('河川コード', 'C', 50, 0)
# ジオメトリと属性値を行ごとに追加
for shp, rec in zip(river_top5_shps, river_top5_recs):
# ジオメトリ(ライン)を追加
w.line([shp.points])
# 属性値を追加
attr = (rec['W05_004'], rec['W05_002'])
w.record(*attr)
# プロジェクションファイル作成 (EPSG:4612)
with open('./river_top5/river_top5.prj', 'w') as prj:
epsg = 'GEOGCS["JGD2000",DATUM["Japanese_Geodetic_Datum_2000",SPHEROID["GRS 1980",6378137,298.257222101]],TOWGS84[0,0,0,0,0,0,0],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
prj.write(epsg)
出力したShapefileをQGISで可視化すると、以下のようになります

前述の上位5河川が出力されていることが分かります
GeoJSON形式での出力
こちらもジオメトリ格納クラスがLineStringとなること以外は、
ポイントデータ出力のときと一緒です。
import json
import geojson
# 出力用のデータ(上位5位の河川に絞る)作成
# 名称不明と琵琶湖以外のインデックス取得
river_top5_indices = [i for i, rec in enumerate(recs_river) if rec['W05_004'] in ['野洲川', '安曇川', '愛知川', '日野川', '高時川']]
# 名称不明と琵琶湖以外のジオメトリと属性取得
river_top5_shps = [shp for i, shp in enumerate(shps_river) if i in river_top5_indices]
river_top5_recs = [rec for i, rec in enumerate(recs_river) if i in river_top5_indices]
# GeoJSONを出力
outpath = './river_top5.geojson'
with open(outpath, 'w', encoding='cp932') as w:
feature_list = [] # Featureのリスト
# ジオメトリと属性値を行ごとに追加
for i, (shp, rec) in enumerate(zip(river_top5_shps, river_top5_recs)): # enumerateでIDを付けた方があとで検索しやすい
# ジオメトリ(ポイント)を作成
line = geojson.LineString(shp.points)
# 属性値を作成
attr = {'河川名': rec['W05_004'],
'河川コード': rec['W05_002']
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=line, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# geojsonファイルに書き出し
w.write(json.dumps(feature_collection, indent=2))
出力したファイルは以下のGitHubリポジトリにアップロードしております
保存3:ポリゴンのファイル出力
Shapefile形式での保存と、GeoJSON形式での保存の2種類を紹介します。
サンプルとして、面積100km2以上の湖沼データを出力します
Shapefile形式での出力
ポリゴンデータの場合は少し注意が必要で、
shapelyライブラリのPolygonクラスへの格納時と同様に、穴のデータを外形データと分けてリスト化する必要があります
(コードが長いですが、前半は出力用のデータを作成するためのフィルタ処理で、実際の出力に関わる部分は「# Shapefileを出力」以降です)
# 出力用のデータ(面積100km2以上の湖沼)作成
# UTM座標変換
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
polys_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_lake]
# shp.partsに基づきポリゴン点を一括分割
parts_list = [[i for i in shp.parts] + [len(shp.points) - 1] for shp in shps_lake]
points_hole_list = [[poly[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)] for poly, parts in zip(polys_utm, parts_list)]
# 面積100km2以上のインデックス取得
areas = [Polygon(points_hole[0], points_hole[1:]).area/1000000 for points_hole in points_hole_list]
lake_over100km2_indices = [i for i, area in enumerate(areas) if area > 100]
areas_over100km2 = [area for i, area in enumerate(areas) if i in lake_over100km2_indices]
# 面積100km2以上のジオメトリと属性取得
lake_over100km2_shps = [shp for i, shp in enumerate(shps_lake) if i in lake_over100km2_indices]
lake_over100km2_recs = [rec for i, rec in enumerate(recs_lake) if i in lake_over100km2_indices]
# Shapefileを出力
outpath = './lake_over100km2/lake_over100km2.shp'
with shapefile.Writer(outpath, encoding='cp932') as w:
# 属性のフィールドを定義(名前、型、サイズ、精度を入力)
w.field('湖沼名', 'C', 50, 0)
w.field('最大水深', 'F', 12, 6)
w.field('面積', 'F', 12, 6)
# ジオメトリと属性値を行ごとに追加
for shp, rec, area in zip(lake_over100km2_shps, lake_over100km2_recs, areas_over100km2):
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(shp.points) - 1]
points_hole = [shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ジオメトリ(ポリゴン)を追加
w.poly(points_hole)
# 属性値を追加
attr = (rec['W09_001'], rec['W09_003'], area)
w.record(*attr)
# プロジェクションファイル作成 (EPSG:4612)
with open('./lake_over100km2/lake_over100km2.prj', 'w') as prj:
epsg = 'GEOGCS["JGD2000",DATUM["Japanese_Geodetic_Datum_2000",SPHEROID["GRS 1980",6378137,298.257222101]],TOWGS84[0,0,0,0,0,0,0],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
prj.write(epsg)
出力したShapefileをQGISで可視化すると、以下のようになります

面積100km2以上の琵琶湖、霞ヶ浦、サロマ湖、猪苗代湖が出力されていることが分かります
GeoJSON形式での出力
Shapefileのときと同様に、穴を分割する必要があるので注意してください
import json
import geojson
# 出力用のデータ(面積100km2以上の湖沼)作成
# UTM座標変換
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
polys_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_lake]
# shp.partsに基づきポリゴン点を一括分割
parts_list = [[i for i in shp.parts] + [len(shp.points) - 1] for shp in shps_lake]
points_hole_list = [[poly[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)] for poly, parts in zip(polys_utm, parts_list)]
# 面積100km2以上のインデックス取得
areas = [Polygon(points_hole[0], points_hole[1:]).area/1000000 for points_hole in points_hole_list]
lake_over100km2_indices = [i for i, area in enumerate(areas) if area > 100]
areas_over100km2 = [area for i, area in enumerate(areas) if i in lake_over100km2_indices]
# 面積100km2以上のジオメトリと属性取得
lake_over100km2_shps = [shp for i, shp in enumerate(shps_lake) if i in lake_over100km2_indices]
lake_over100km2_recs = [rec for i, rec in enumerate(recs_lake) if i in lake_over100km2_indices]
# GeoJSONを出力
outpath = './lake_over100km2.geojson'
with open(outpath, 'w', encoding='cp932') as w:
feature_list = [] # Featureのリスト
# ジオメトリと属性値を行ごとに追加
for i, (shp, rec, area) in enumerate(zip(lake_over100km2_shps, lake_over100km2_recs, areas_over100km2)): # enumerateでIDを付けた方があとで検索しやすい
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(shp.points) - 1]
points_hole = [shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ジオメトリ(ポイント)を作成
poly = geojson.Polygon(points_hole)
# 属性値を作成
attr = {'湖沼名': rec['W09_001'],
'最大水深': float(rec['W09_003']),
'面積': area
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=poly, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# geojsonファイルに書き出し
w.write(json.dumps(feature_collection, indent=2))
出力したファイルは以下のGitHubリポジトリにアップロードしております
表示1:ポイントの表示
GISデータをPythonで簡易的に表示したいとき、Jupyterを利用するのが便利です。
Jupyterでmatplotlibと組み合わせて画像として表示する方法(descrates、geopandas)と、オープンソースの地図上に表示する方法(folium)がありますが、個人的には地図上でスクロールできる後者がおすすめです。
foliumでは、オープンソースの地図であるOpenStreetMap上に、ジオメトリを表示します。
下記サンプルでは、堤高100m以上のダムをfoliumで表示しています。
import folium
import geojson
# 表示用のデータ(堤高100m以上のダム)作成
over100m_indices = [i for i, rec in enumerate(recs_dam) if rec['W01_007'] > 100]
over100m_shps = [shp for i, shp in enumerate(shps_dam) if i in over100m_indices]
over100m_recs = [rec for i, rec in enumerate(recs_dam) if i in over100m_indices]
# 表示用のGeoJSONファイルを作成(出力1と同じ)
feature_list = [] # Featureのリスト
for i, (shp, rec) in enumerate(zip(over100m_shps, over100m_recs)): # enumerateでIDを付けた方があとで検索しやすい
# ジオメトリ(ポイント)を作成
point = geojson.Point((shp.points[0][0], shp.points[0][1]))
# 属性値を作成
attr = {'ダム名': f'{rec["W01_001"]}ダム',
'堤高': float(rec['W01_007']),
'総貯水量': float(rec['W01_010'])
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=point, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# ベースとなる地図を作成
folium_map = folium.Map(location=[35, 135], # デフォルトの表示緯度経度
zoom_start=6) # デフォルトの表示倍率
# GeoJSONファイルを地図に追加
folium.GeoJson(feature_collection,
popup=folium.GeoJsonPopup(fields=['ダム名', '堤高']), # クリック時に表示されるポップアップ
).add_to(folium_map)
# 地図を表示
folium_map

手順としては、
- 出力したいGeoJSONファイルを作成(出力1のときと同様の方法)
- 表示のベースとなる地図をfolium.Mapクラスで作成
- 1のジオメトリをfolium.GeoJsonクラスで読み込み、add_toメソッドで2の地図に追加
- folium_mapで地図を表示
となります。
また、folium.GeoJsonクラスの便利な機能として、マウスカーソルを合わせたときの表示(上の図の「早明浦ダム」が該当)を、引数で設定することができます
クリック時の表示項目:popup=folium.GeoJsonPopup(fields=フィールド名のリスト)
マウスカーソル通過時の表示項目:tooltip=folium.GeoJsonTooltip(fields=フィールド名のリスト)
また、マーカーの色を変えたいときには、geojson.FeatureCollectionから一括作成したGeoJSONではうまくいかないようです。1レコードごとにfolium.Markerでポイントを追加する必要があります(参考)
表示2:ラインの表示
ポイントデータのときとほぼ同様の手順です。
下のサンプルでは、滋賀県の長さ上位5河川を表示しています
# 表示用のデータ(上位5位の河川)作成
river_top5_indices = [i for i, rec in enumerate(recs_river) if rec['W05_004'] in ['野洲川', '安曇川', '愛知川', '日野川', '高時川']]
river_top5_shps = [shp for i, shp in enumerate(shps_river) if i in river_top5_indices]
river_top5_recs = [rec for i, rec in enumerate(recs_river) if i in river_top5_indices]
# 表示用のGeoJSONファイルを作成(出力2と同じ)
feature_list = [] # Featureのリスト
# ジオメトリと属性値を行ごとに追加
for i, (shp, rec) in enumerate(zip(river_top5_shps, river_top5_recs)): # enumerateでIDを付けた方があとで検索しやすい
# ジオメトリ(ポイント)を作成
line = geojson.LineString(shp.points)
# 属性値を作成
attr = {'河川名': rec['W05_004'],
'河川コード': rec['W05_002']
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=line, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# ベースとなる地図を作成
folium_map = folium.Map(location=[35.3, 136.1],
zoom_start=9)
# GeoJSONファイルを地図に追加
folium.GeoJson(feature_collection,
popup=folium.GeoJsonPopup(fields=['河川名', '河川コード']), # クリック時に表示されるポップアップ
style_function=lambda feature: {
'color': 'blue', # 線の色
'weight': 3, # 線の太さ
'lineOpacity': 0.2, # 線の不透明度
},
).add_to(folium_map)
# 地図を表示
folium_map

線の色や太さを変える際には、folium.GeoJsonクラスのstyle_function引数を指定します。
後述のポリゴンの例のように、属性値で色や太さを変えることも可能です
表示3:ポリゴンの表示
基本的にはラインデータのときとほぼ同様の手順です。
ポリゴンデータの保存時と同様に、穴のデータを外形データと分けてリスト化する必要があります
(コードが長いですが、前半は出力用のデータを作成するためのフィルタ処理で、実際の表示に関わる部分は「# 表示用のGeoJSONファイルを作成」以降です)
import folium
import branca.colormap as cm # カラーマップ用のライブラリ
import geojson
# 出力用のデータ(面積50km2以上の湖沼)作成
# UTM座標変換
src_srs, dst_srs = osr.SpatialReference(), osr.SpatialReference()
src_srs.ImportFromEPSG(4612)
dst_srs.ImportFromEPSG(3099)
trans = osr.CoordinateTransformation(src_srs, dst_srs)
polys_utm = [list(map(lambda point: trans.TransformPoint(point[1], point[0])[:2], shp.points)) for shp in shps_lake]
# shp.partsに基づきポリゴン点を一括分割
parts_list = [[i for i in shp.parts] + [len(shp.points) - 1] for shp in shps_lake]
points_hole_list = [[poly[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)] for poly, parts in zip(polys_utm, parts_list)]
# 面積50km2以上のインデックス取得
areas = [Polygon(points_hole[0], points_hole[1:]).area/1000000 for points_hole in points_hole_list]
lake_over50km2_indices = [i for i, area in enumerate(areas) if area > 50]
areas_over50km2 = [area for i, area in enumerate(areas) if i in lake_over50km2_indices]
# 面積50km2以上のジオメトリと属性取得
lake_over50km2_shps = [shp for i, shp in enumerate(shps_lake) if i in lake_over50km2_indices]
lake_over50km2_recs = [rec for i, rec in enumerate(recs_lake) if i in lake_over50km2_indices]
# 表示用のGeoJSONファイルを作成(出力3と同じ)
feature_list = [] # Featureのリスト
for i, (shp, rec, area) in enumerate(zip(lake_over50km2_shps, lake_over50km2_recs, areas_over50km2)): # enumerateでIDを付けた方があとで検索しやすい
# shp.partsに基づきポリゴン点を分割(穴を定義)
parts = [i for i in shp.parts] + [len(shp.points) - 1]
points_hole = [shp.points[parts[i]:parts[i + 1]] for i in range(len(parts) - 1)]
# ジオメトリ(ポイント)を作成
poly = geojson.Polygon(points_hole)
# 属性値を作成
attr = {'湖沼名': rec['W09_001'],
'最大水深': float(rec['W09_003']),
'面積': area
}
# Feature(ジオメトリと属性をまとめたもの)を作成してリストに追加
feature = geojson.Feature(geometry=poly, id=i, properties=attr)
feature_list.append(feature)
# FeatureのリストをFeatureCollectionに変換
feature_collection = geojson.FeatureCollection(feature_list,
crs={'type': 'name', # 座標系を指定
'properties': {'name': 'urn:ogc:def:crs:EPSG::4612'}
})
# ベースとなる地図を作成
folium_map = folium.Map(location=[43, 143], # 初期表示位置
zoom_start=7) # 初期表示倍率
# 塗りつぶし用のカラーマップを作成
colorscale = cm.linear.YlGnBu_09.scale(0, 300)
# GeoJSONファイルを地図に追加
folium.GeoJson(feature_collection,
popup=folium.GeoJsonPopup(fields=['湖沼名', '面積', '最大水深']), # クリック時に表示されるポップアップ
style_function=lambda feature: {
'fillColor': colorscale(feature['properties']['最大水深']), # 塗りつぶし色(lambdaで属性値に基づいて色分け可能)
'color': 'gray', # 外枠線の色
'weight': 1, # 外枠線の太さ
'fillOpacity': 0.8, # 塗りつぶしの不透明度
'lineOpacity': 0.6, # 外枠線の不透明度
},
).add_to(folium_map)
# 地図を表示
folium_map

塗りつぶしや線の色を変える際には、folium.GeoJsonクラスのstyle_function引数を指定します。
lambda式でfeatureの内部の値にアクセスすることで、属性値で色や太さを変えることも可能です。
上の例では、属性 "最大水深" で、塗りつぶし色(fillColor)を変えており、
塗りつぶし用のカラーマップは、brancaという別ライブラリ(作者がfoliumと同じ)で指定する必要があります(指定できる色の参考)
以上で、実装例の解説は全てとなります。
ライブラリ関係のトラブルシューティング
GDAL (osgeo)ライブラリのインストール時にエラーが出やすいので、それぞれ解説します。
pip install gdal時にERROR: Command errored out with exit status 1:が発生
gdalをインストールした際に、上記のようなエラーメッセージが出ることがあります。
上記メッセージだけだと原因が複数種類考えられるので、さらに下に書いてあるエラーメッセージによって対処を分けます
"error: Microsoft Visual C++ 14.0 or greater is required."と出た時
ERROR: Command errored out with exit status 1:
:
中略
:
error: Microsoft Visual C++ 14.0 or greater is required.
このエラーはWindowsでC++ファイルをビルドするツールがシステムに含まれていない事に起因します。
解決策
こちらを参考に、Build Tools for Visual Studio 2019の「C++によるデスクトップ開発」をインストールしてください(数分~数10分掛かります)
"Could not find gdal-config. Make sure you have installed the GDAL native library and development headers."と出たとき
Linux (Debian系)で上記エラーが出たときは、以下コマンドでGdalのネイティブライブラリをインストールしてください (参考)
sudo apt update
sudo apt install gdal-bin
sudo apt install libgdal-dev
sudo apt install python3-gdal
sudo apt install python3-geopandas
"fatal error C1083: include ファイルを開けません"と出た時
以下のようなメッセージが出たとき
ERROR: Command errored out with exit status 1:
:
中略
:
extensions/gdalconst_wrap.c(3018): fatal error C1083: include ファイルを開けません。'gdal.h':No such file or directory
extensions/gdal_array_wrap.cpp(3144): fatal error C1083: include ファイルを開けません。'gdal.h':No such file or directory
extensions/gnm_wrap.cpp(3135): fatal error C1083: include ファイルを開けません。'gdal.h':No such file or directory
extensions/ogr_wrap.cpp(3153): fatal error C1083: include ファイルを開けません。'gdal.h':No such file or directory
extensions/osr_wrap.cpp(3198): fatal error C1083: include ファイルを開けません。'cpl_string.h':No such file or directory
extensions/gdal_wrap.cpp(3191): fatal error C1083: include ファイルを開けません。'cpl_port.h':No such file or directory
このエラーは、恐らくPyPIのリポジトリとGDALのバージョンが上手く紐づいていない事に起因します(参考)
解決策
手動でダウンロードしたGDALをインストールします。
下記サイトから環境に合わせてインストールしたいバージョンのGDALをダウンロードします。
(例:Intel/AMD 64CPU、Python3.9でGDAL3.3.0をインストールしたい場合、"GDAL‑3.3.0‑cp39‑cp39‑win_amd64.whl"を選択)
https://www.lfd.uci.edu/~gohlke/pythonlibs/#gdal
ダウンロードしたファイルのあるフォルダにPowerShell等で入り、下記コマンドでインストールします
pip install .\GDAL‑3.3.0‑cp39‑cp39‑win_amd64.whl
pip install geopandas時にERROR: Command errored out with exit status 1:が発生
Geopandasインストール時に以下のようなメッセージが出ることがあります
ERROR: Command errored out with exit status 1:
:
中略
:
fiona/_transform.cpp(606): fatal error C1083: include ファイルを開けません。'cpl_conv.h':No such file or directory
このエラーは、恐らくPyPIのリポジトリと、geopandasの必須ライブラリであるFionaのバージョンが上手く紐づいていない事に起因します(参考)
解決策
GDALのときと同様に、手動でダウンロードしたFionaをインストールします。
下記サイトから環境に合わせてインストールしたいバージョンのFionaをダウンロードします。
(例:Intel/AMD 64CPU、Python3.9でFiona1.8.20をインストールしたい場合、"Fiona‑1.8.20‑cp39‑cp39‑win_amd64.whl"を選択)
https://www.lfd.uci.edu/~gohlke/pythonlibs/#fiona
ダウンロードしたファイルのあるフォルダにPowerShell等で入り、下記コマンドでインストールします
pip install .\Fiona-1.8.20-cp39-cp39-win_amd64.whl
この後、pip install geopandasとすればエラーが消えるはずです
shapelyやGeoPandas利用時に"GEOSGeom_createLinearRing_r returned a NULL pointer"と出たとき
インストール時のエラーではありませんが、shapelyやGeoPandasをosgeoと併用すると、実行時に下記エラーが発生する事があります(fionaとの併用でも発生例あり)
from osgeo import ogr, osr
from shapely.geometry import Polygon
P = Polygon([(0, 0), (0, 1), (1, 1), (1, 0)])
解決策
こちらに記載されているように、importの順番を逆にすると正常に動作します
from shapely.geometry import Polygon
from osgeo import ogr, osr
P = Polygon([(0, 0), (0, 1), (1, 1), (1, 0)])
エラーメッセージから原因が推測できないので、なかなか凶悪なエラーです‥
pyshp等でshpファイル読込時に"'shift_jis' codec can't decode byte 0xfa in position 0: illegal multibyte sequence"が発生
src = shapefile.Reader(DAM_PATH, encoding='SHIFT-JIS')
recs = src.records() # ここで上記エラーが発生
Windows拡張文字がファイル内に含まれることに由来するエラーです(参考)
解決策
エンコード指定を'cp932'に変更します
src = shapefile.Reader(DAM_PATH, encoding='SHIFT-JIS')
recs = src.records() # ここで上記エラーが発生