注意事項
今回の作品は、機械学習を学ぶために作成した個人向けのアプリです。
十分に検証された内容ではありませんので、実際の業務や診療等では使用しないようにご留意下さい。
1.はじめに
最近機械学習やデータサイエンス等の領域にハマっており、産業や業務をハックするためにはどんな使い方をしたらいいか、というのを四六時中考えています。
手始めに、月並みなテーマではありますが、今まで人が診断していた医療画像を機械にやらせたらどうなるか、どれ程の精度が出せるのかを自分で試してみたくなり、脳のMRI画像から腫瘍があるかを判定するアプリを作成してみました。
↓作成したアプリはこちらです
https://tumor-detection-app.onrender.com/
↓コードは全てGithubで公開してます
https://github.com/buono/tumor-detection-app
2.開発環境
・MacBook Pro M1 Max
・macOS 13.2.1
・Google Colaborabory(GPU Tesla T4, 525.105.17, 15360 MiB)
・Python(Ver 3.11.3)
3.使用したライブラリ
・TensorFlow:2.12.0使用
Googleが開発した機械学習のためのライブラリ。
・OpenCV:4.8.0使用
Open Source Computer Vision Libraryの略で画像処理・画像解析に使用するライブラリ。
・Numpy:1.23.5使用
Pythonで数値計算を行うためのライブラリ。
・Flask:2.0.1
PythonでWebアプリケーションを作成するためのライブラリ。
DeployするバージョンをRequirements.txt内で指定できます。
※ちなみに、Google colaboratory上で各ライブラリのバージョンを確認する時は下記コマンドを使います。
例:Numpyのバージョン確認方法
print(np.__version__)
4.学習データの準備
Kaggleで公開されている脳のMRIの画像データセットを使用。
"Brain MRI Images for Brain Tumor Detection"
https://www.kaggle.com/datasets/navoneel/brain-mri-images-for-brain-tumor-detection
このZipファイルをあらかじめダウンロードしておき、解凍した上で作業ファイルと同じ階層に保存しておきます。
5.学習モデルの構築
次に、Google Colaboratory上でモデルを作成します。機械学習はこの作業が一番のハイライト。
下準備
まずはGoogle drive上のファイルをColaboratory上から使えるように、ドライブをマウントします。
from google.colab import drive #Googleドライブにマウントし、ファイルへアクセス
drive.mount('/content/drive')
次に関連ライブラリのインポートします。機械学習用のフレームワークはTensorFlowとPyTorchが二大巨頭で、今回はTensorFlowを使います。
それぞれのライブラリの使い方は別途説明します。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizer
パスと画像リストを取得します。
# ファイルパスの設定
path = '/content/drive/MyDrive/Colab Notebooks/BrainTumorDetection/brain_tumor_dataset/'
path_yes = path + 'yes/'
path_no = path + 'no/'
# 画像をリストで取得
list_yes = os.listdir(path_yes)
list_no = os.listdir(path_no)
データの加工
機械学習をしやすいように、画像のリサイズと並べ替え等をします。
#すべての画像ファイルを50 x 50の配列に変換
img_yes = []
img_no = []
for i in range(len(list_yes)):
img = cv2.imread(path_yes + list_yes[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b]
img = cv2.resize(img, (50,50))
img_yes.append(img)
for i in range(len(list_no)):
img = cv2.imread(path_no + list_no[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b]
img = cv2.resize(img, (50,50))
img_no.append(img)
#結合して並べ替え
X = np.array(img_yes + img_no)
y = np.array([0]*len(img_yes) + [1]*len(img_no))
#画像の順番をシャッフル(これやらないと精度がバタバタ増減する)
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#データを訓練データとテストデータに分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#To_categolizeで正解ラベルを作成する
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
モデルの構築
ここと次のセクションが一番機械学習っぽいところです。
今回は転移学習という学習方法を使います。
これは、ゼロからモデルを作り上げるのではなく、あらかじめ作られた学習済みモデルを利用し、それに追加する形でモデルを自分流にカスタマイズするものです(ファインチューニングとも言います)。
モデルをゼロから作るのは労力がものすごいかかるので、一般的にも良く使われています。IT業界でよく言う、「巨人の肩の上に乗る」ってやつですね。
転移学習の元となる学習済みモデルはたくさんの種類がありますが、その中でもスタンダードなVGG16というモデルを使いました。
これは、imagenetという、1400万枚のラベル付き画像を元に作られたいくつかの学習モデルのうちの一つです。
参考:https://paperswithcode.com/dataset/imagenet
# input_tensorの定義をして、vggのImageNetによる学習済みモデルを作成
input_tensor = Input(shape=(50,50,3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 特徴量抽出部分のモデルを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みを固定
for layer in model.layers[:19]:
layer.trainable = False
# 学習の前に、モデル構造を確認
model.summary()
転移学習では、元のモデルを完全にそのまま踏襲するか、それとも再学習するかという点も選ぶことができます。
ここでは、下記2行の箇所で、19層目まで、つまり出力層以外の全ての層を固定しているので完全踏襲しています。
(vgg16は出力層合わせて全20層から成っています)
for layer in model.layers[:19]:
layer.trainable = False
下記が作成したモデルの出力結果です。
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) [(None, 50, 50, 3)] 0
block1_conv1 (Conv2D) (None, 50, 50, 64) 1792
block1_conv2 (Conv2D) (None, 50, 50, 64) 36928
block1_pool (MaxPooling2D) (None, 25, 25, 64) 0
block2_conv1 (Conv2D) (None, 25, 25, 128) 73856
block2_conv2 (Conv2D) (None, 25, 25, 128) 147584
block2_pool (MaxPooling2D) (None, 12, 12, 128) 0
block3_conv1 (Conv2D) (None, 12, 12, 256) 295168
block3_conv2 (Conv2D) (None, 12, 12, 256) 590080
block3_conv3 (Conv2D) (None, 12, 12, 256) 590080
block3_pool (MaxPooling2D) (None, 6, 6, 256) 0
block4_conv1 (Conv2D) (None, 6, 6, 512) 1180160
block4_conv2 (Conv2D) (None, 6, 6, 512) 2359808
block4_conv3 (Conv2D) (None, 6, 6, 512) 2359808
block4_pool (MaxPooling2D) (None, 3, 3, 512) 0
block5_conv1 (Conv2D) (None, 3, 3, 512) 2359808
block5_conv2 (Conv2D) (None, 3, 3, 512) 2359808
block5_conv3 (Conv2D) (None, 3, 3, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
sequential_2 (Sequential) (None, 2) 131842
=================================================================
Total params: 14,846,530
Trainable params: 131,842
Non-trainable params: 14,714,688
_________________________________________________________________
モデルの内容が問題なければ、最後にcompileをしてモデルを完成させます。
(ここの処理の概念は分かり辛いですが、自分はモデルをテキストからバイナリファイルに変換するイメージを持ってます)
なお、見慣れない単語が並んでいますが、ここで重要なのは「どのように学習を進めていくか」を設定している点です。
今までのテスト勉強や受験勉強を思い出せば分かると思いますが、自分の進むべき道が分からないとどう勉強していいか分からないですよね。
それを設定しているのがここの行です。
専門的には損失関数や最適化関数と言い、どうやって、どれくらいのスピードで精度を上げていくかといったことをここでパラメータとして設定します。
(このように人が調整するパラメータを、ハイパーパラメータと呼んだりします)
このあたりは下記ページの解説が分かりやすいので、余力のある人は見てみて下さい。
https://qiita.com/omiita/items/1735c1d048fe5f611f80
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
6.モデルの学習と評価
それでは、作成したモデルに入力データと出力ラベルを割り当て、学習を進めます。
ここでいう学習とは、それぞれの重みとバイアスが最適になるように値を調整する事です。
model.fitを使って訓練データを与え、バッチサイズ、エポック数を設定することで学習を開始してくれます。
バッチサイズは学習データをいくつかのグループに分けた際の各グループのデータ数のことで、エポック数は何回学習を繰り返すか、ということです。
いずれも数を増やせばいいのか、というとそうでもなく、処理時間や過学習や目標精度などを考慮し、トライ&エラーで数を選びます。
ここではバッチサイズ100、エポック数10としました。
一度学習したモデルは保存しておくと後で使い回せて便利なので、良い結果が出たら保存しておきましょう。
また、このモデルは後ほどアプリ内でも使用します。
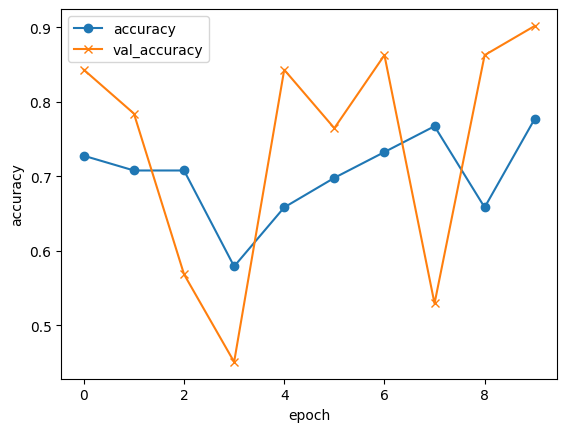
ここでは、model.evaluateでテストデータと比較した結果、0.80の精度(的中率80%)が出たのでまずまずの結果だと思います。
あと、後ほど学習履歴をグラフ化するためにmodel.fitでの学習履歴をhistory変数に入れておきます。
# モデルの学習
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=100, epochs=10)
# モデルの保存
model.save('model.h5')
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 学習履歴
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
Epoch 1/10
3/3 [==============================] - 1s 183ms/step - loss: 0.9733 - accuracy: 0.5050 - val_loss: 0.7885 - val_accuracy: 0.4902
Epoch 2/10
3/3 [==============================] - 0s 51ms/step - loss: 0.7247 - accuracy: 0.6535 - val_loss: 0.5099 - val_accuracy: 0.7647
Epoch 3/10
3/3 [==============================] - 0s 40ms/step - loss: 0.7159 - accuracy: 0.6733 - val_loss: 0.4659 - val_accuracy: 0.7059
Epoch 4/10
3/3 [==============================] - 0s 39ms/step - loss: 0.6419 - accuracy: 0.6980 - val_loss: 0.4445 - val_accuracy: 0.7843
Epoch 5/10
3/3 [==============================] - 0s 39ms/step - loss: 0.5718 - accuracy: 0.7277 - val_loss: 0.5888 - val_accuracy: 0.6471
Epoch 6/10
3/3 [==============================] - 0s 39ms/step - loss: 0.5320 - accuracy: 0.7822 - val_loss: 0.5024 - val_accuracy: 0.7647
Epoch 7/10
3/3 [==============================] - 0s 36ms/step - loss: 0.4001 - accuracy: 0.8416 - val_loss: 0.4658 - val_accuracy: 0.7843
Epoch 8/10
3/3 [==============================] - 0s 40ms/step - loss: 0.4554 - accuracy: 0.7822 - val_loss: 0.4991 - val_accuracy: 0.7451
Epoch 9/10
3/3 [==============================] - 0s 35ms/step - loss: 0.3293 - accuracy: 0.8515 - val_loss: 0.4004 - val_accuracy: 0.8235
Epoch 10/10
3/3 [==============================] - 0s 40ms/step - loss: 0.5255 - accuracy: 0.7376 - val_loss: 0.3861 - val_accuracy: 0.8039
2/2 [==============================] - 0s 15ms/step - loss: 0.3861 - accuracy: 0.8039
Test loss: 0.38611894845962524
Test accuracy: 0.8039215803146362
学習履歴
7.検証
これでモデルの作成は完了ですが、正しく画像を判定できているかも念のため確認しておきましょう。
# 画像を一枚受け取り、腫瘍の有無を判定して返す関数
def pred_tumor(img):
#50 x 50にリサイズ
resized_img = cv2.resize(img, (50,50))
#model.predictの結果が0であれば腫瘍あり、1であれば腫瘍なし
pred = np.argmax(model.predict(np.array([resized_img])))
if pred == 0:
return "yes"
elif pred == 1:
return "no"
# pred_tumor関数に画像を渡して腫瘍有無を予測
for i in range(10):
# pred_tumor関数に顔写真を渡して性別を予測
img = cv2.imread(path_no + list_no[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b]
plt.imshow(img)
plt.show()
print(pred_tumor(img))
print()
print()
以下は出力結果の一部です。
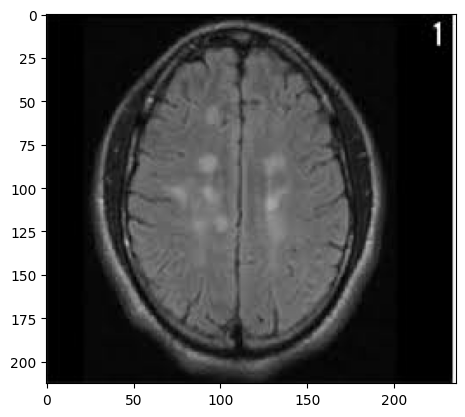
1/1 [==============================] - 0s 37ms/step
no
8.Renderへのデプロイ
最後の仕上げとして、作成したモデルを使ってWEBアプリを作成していきます。
モデルができたら、Google Colaboratoryの役目は終了です。
コードエディタを立ち上げ、以下ファイルを作成していきます。
.
├── README.md
├── detection.py
├── model.h5
├── requirements.txt
├── static
│ └── stylesheet.css
├── templates
│ └── index.html
└── uploads
今回は機械学習によるモデル作成の説明がメインなので、説明は割愛します。詳細は下記GitHubのコードをご覧ください。
https://github.com/buono/tumor-detection-app
下記が完成したサイトです。Renderを使用しています。ローカル環境と同じように、画像をアップすると概ね正しく腫瘍の有無を判定してくれている事が確認できました。
https://tumor-detection-app.onrender.com/
9.まとめ
考察
Kaggleで公開されている腫瘍の画像は数100枚しかなく、高い精度が出せないかと思いましたが80%程度の精度は出す事ができました。
ただし、学習履歴を見る限り、精度が右肩上がりになっていないので学習がうまくいっているとは完全に言えない状況です。
今後の展望としては、画像反転や回転、位置ずらしなどによる画像数の増加等でさらに精度アップが期待できると思います。
また、モデルの選定や損失関数・最適化関数の選定も十分にできたとは言えないので、そちらに関しても他のを選ぶことでもっと精度が良くなる可能性もあると思います。
コードは全て公開していますので、もし興味のある方はトライしてみてはいかがでしょうか。
所感
機械学習が産業・業務にどのように活かせるか?を確認したく、今回、このようなアプリを作成しました。
結果として、プロトタイプの完成度ながらも高い精度が出せたので、やはり機械学習のポテンシャルは高く、今後更に浸透していくのではないかと感じさせられました。
その意味で、今回の目的は十分に達成できました。
ただし一方で、精度を上げる事の難しさも分かり、今回のように人の命に関わるようなところで機械学習を使用する場合、やはり人の目も必要だという事を実感できました。
ということで、当面は人と機械が共存する未来が見えました。
改めてですが、今回の作品は、機械学習を学ぶために作成した個人向けのアプリです。
十分に検証された内容ではありませんので、実際の業務や診療等では使用しないようにご留意下さい。
それでは今回の検証は以上となります。