はじめに
この猫の名前は、マロン、通称まーちゃんです。
アビシニアンの16歳の女の子です。
まーちゃんを電脳世界に解き放つことを目標に日々活動しています。

今回はその一歩として、まーちゃんに特化した画像処理機械学習モデルを作り、Webカメラで検知したら通れる物理的なゲートを作ろうと思います。
要はまーちゃん検出機です。
少し長いですがお付き合い頂けると嬉しいです。
実際に作ったものが以下になります。
この記事の対象者
本記事は以下のような人を対象としています。
- 画像処理の機械学習をやってみたい
- ブラウザとRaspberryPiで通信してモジュールを操作したい
- Rustで組み込みをやってみたい
本業はフロントエンドで、正直どの技術も門外漢でしたが何とか作れました。
自分と同じようにどれも触ったことがないっていう方でもGPTと相談しながら進めれば意外とできちゃうかと思いますので、この記事を読んでぜひチャレンジしてみてください。
動作環境・使用するツールや言語
以下の環境で開発を実施しました。
- macOS (MacBook Pro M3)
- LabelStudio
- Yolo v8
- Tensorflowjs
- Javascript
- Python3.11.9
- Rust 1.80
- Raspberry Pi 5
1.カスタム機械学習モデルを作る
最初にまーちゃんを検知するための独自の学習モデルを作成します。
画像のラベリング作業という根気がいる作業から始まります。
ここが最も重要と言っても過言ではないのでしっかりやりましょう。
1-1.LabelStudioで画像をラベリングする(教師データ)
LabelStudioというアノテーションツールを使用します。
アノテーションツールとは、画像やテキストなどの学習用データにラベルをつけるツールです。
画像で言えば、画像内の特定の物体を囲んだりしてラベル付けします。
大量のデータに対してラベル付けをすることでよりトレーニングの際の教師データとなり、高精度な学習モデルを作ることができるわけです。
早速やってみましょう。
まずは、LabelStudioをインストールしましょう。
インストール後、LabelStudioを起動します。
$ brew install humansignal/tap/label-studio
$ label-studio
起動するとログイン・新規登録の画面がローカルで表示されますので、新規登録します。
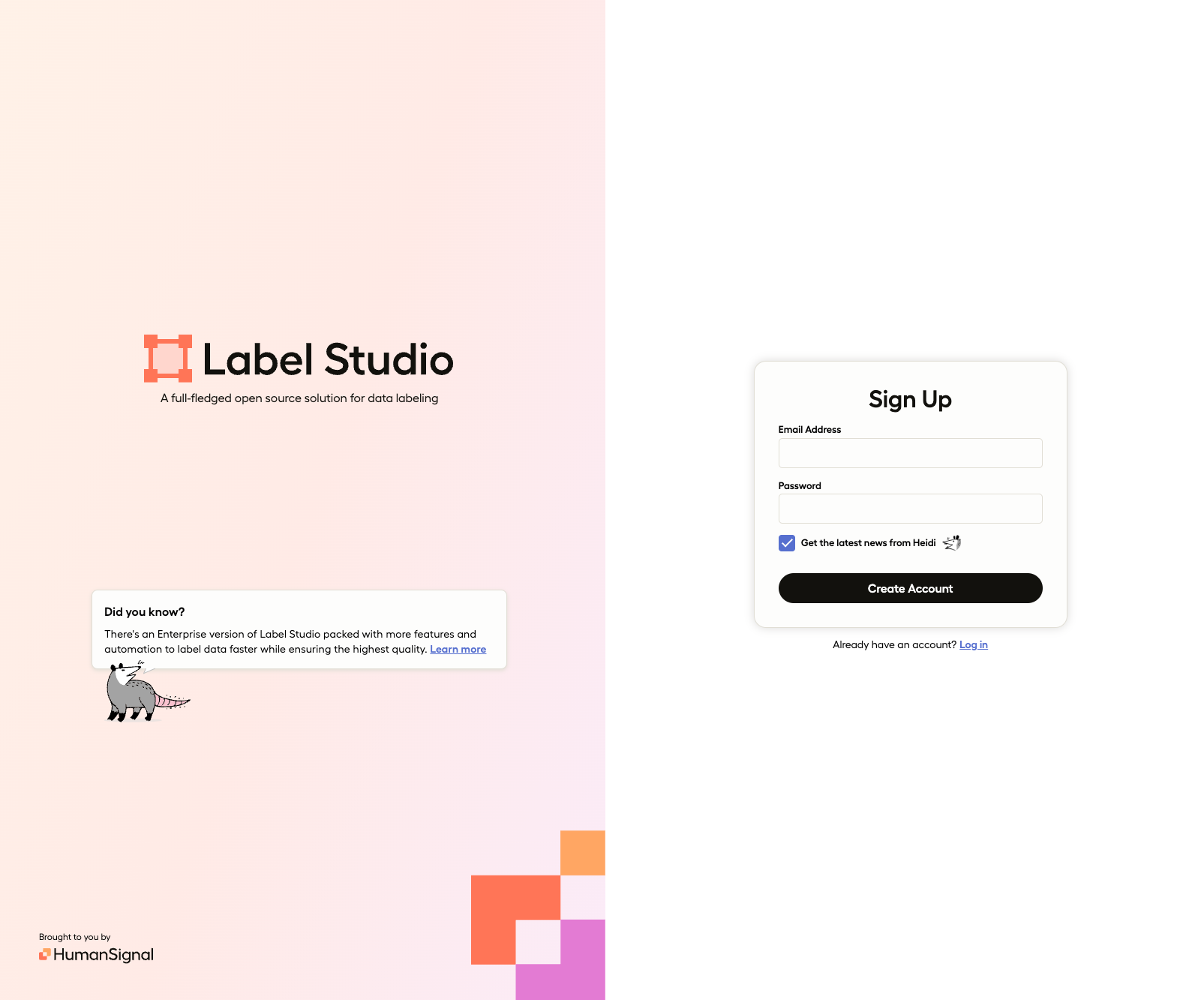
登録後、ログインすると以下のプロジェクト一覧画面が表示されます。
最初はプロジェクトが何もない状態ですので、右上の[Create]をクリックしてプロジェクトを作成します。
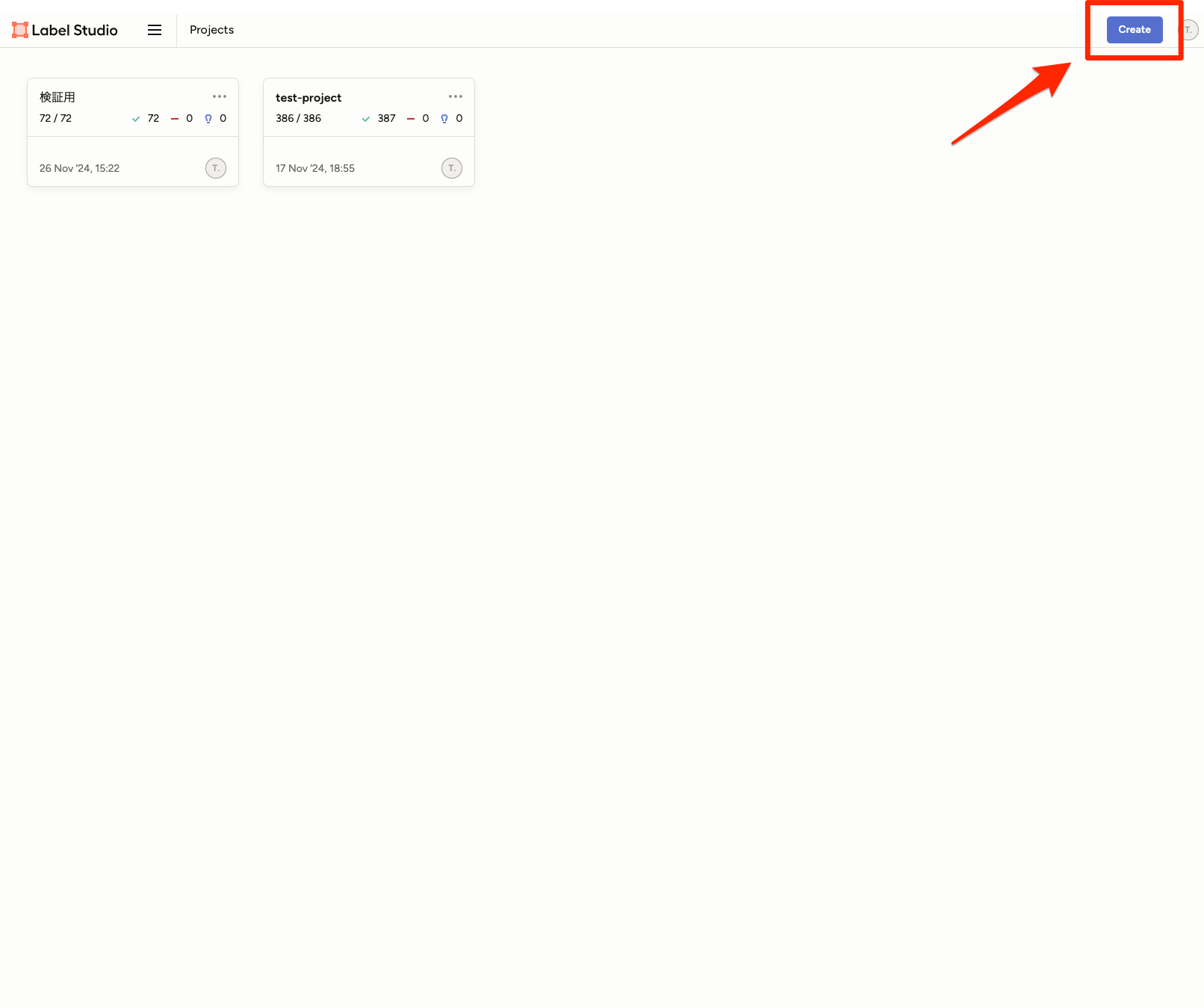
[Project Name]で、プロジェクト名を入力します。
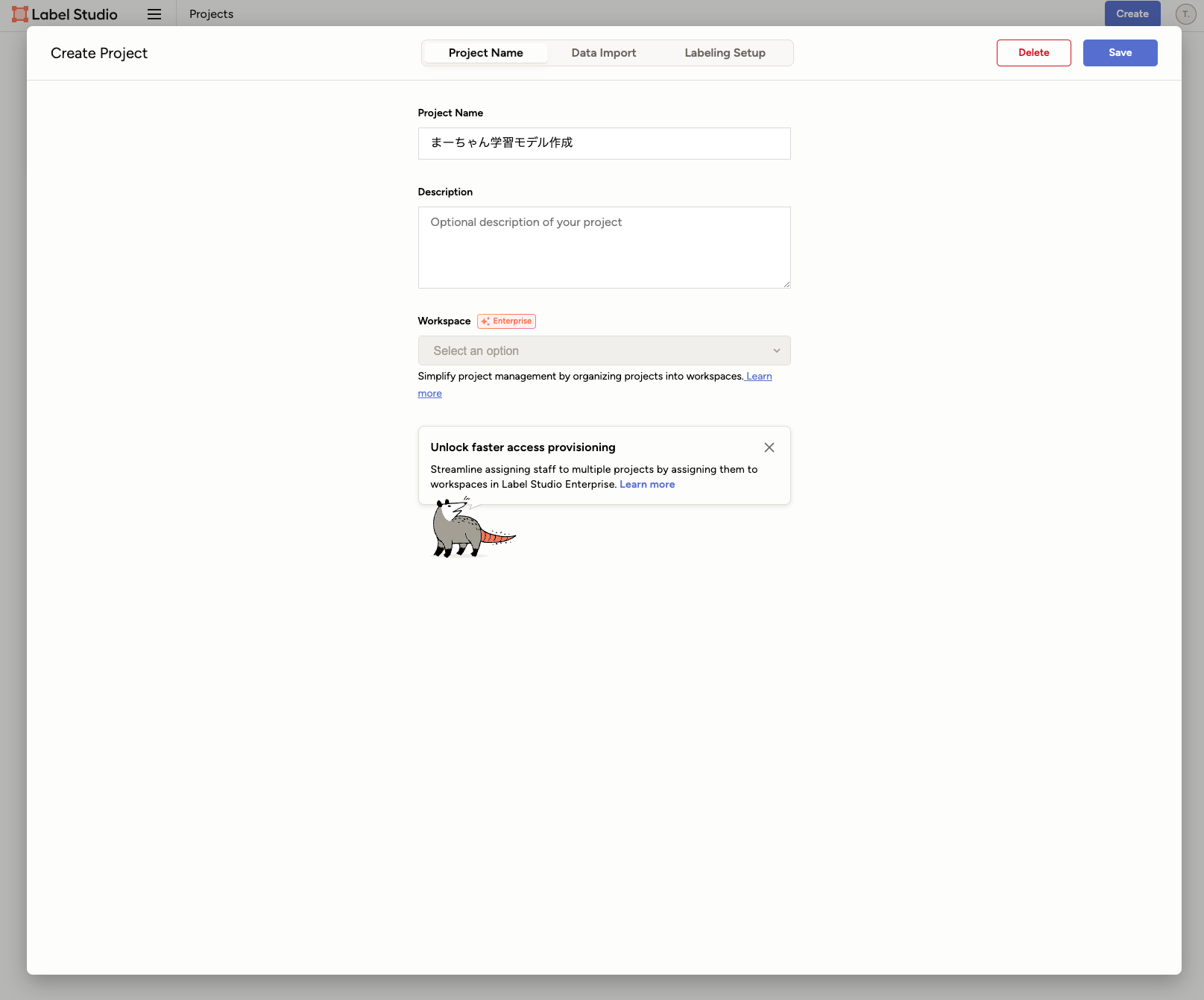
[Data Import]で、学習用の画像ファイルをimportします。
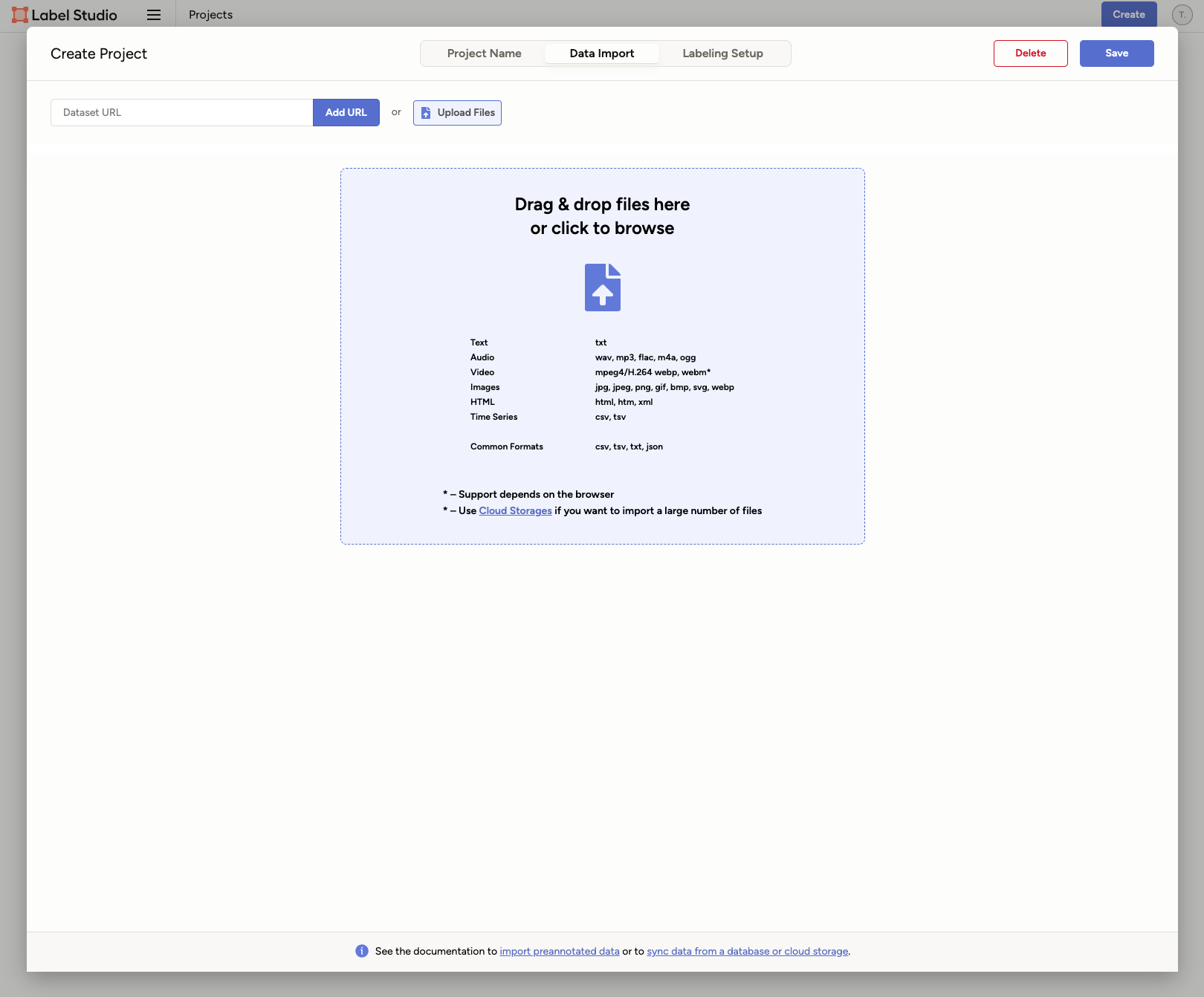
[Labeling Setup]でラベリングする種類を選択します。
今回は、対象をドラッグで囲う[Object Detection with Bounding Boxes]を選びます。
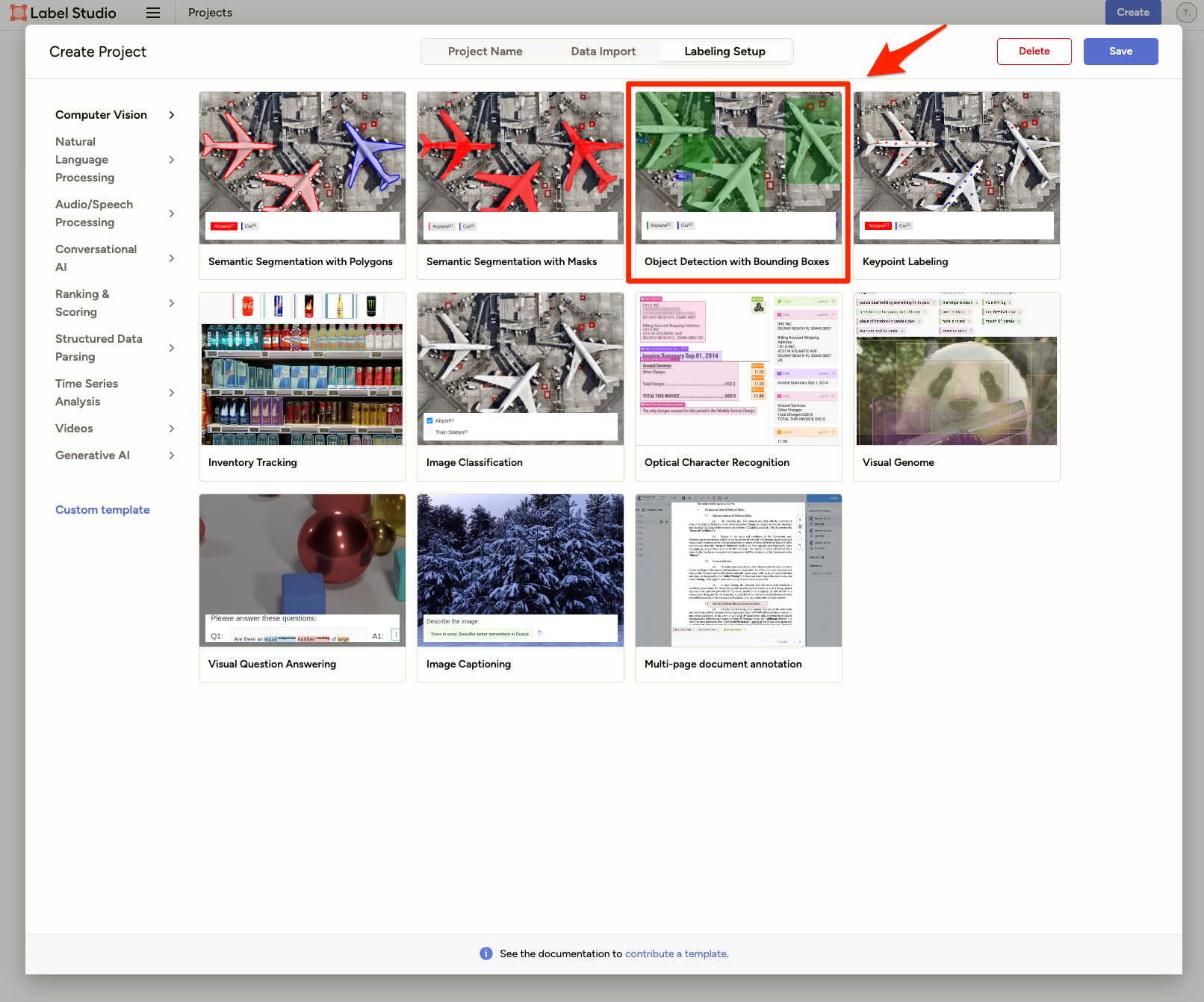
ラベルを作成します。ここでは、まーちゃんを表す「cat」というラベルを追加します。
デフォルトではplaneなど無関係なラベルがあるので、バツボタンで削除しておきます。
右上の[Save]ボタンを押してプロジェクトを作成します。

importした画像に対してラベリングしていきます。
以下の動画のように対象の画像を選択します。
画像下部にあるラベル[cat]をクリックし、画像内の検出対象である、まーちゃんをドラッグで囲います。
1枚の画像のラベリングが完了しました。
この作業をimportした画像全てに対して実施します。

なお、自分が実際にラベリングした画像の枚数は、387枚でした。
これでも足りないくらいで、精度を高めるにはもっと必要っぽいです。
ラベリングが完了したらExportします。
Export形式はいろいろあり、今回は[Yolo]を選択してExportします。

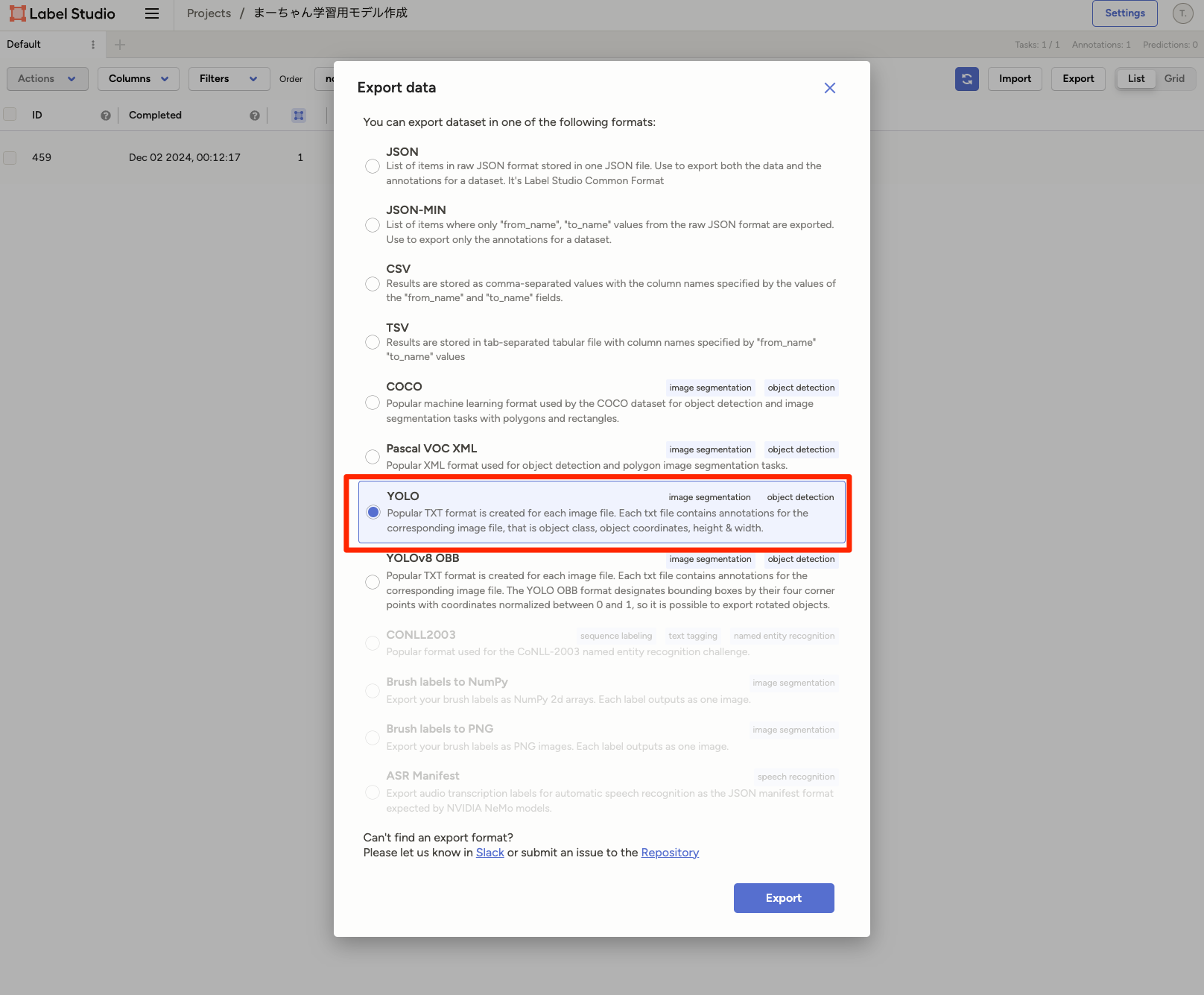
ExportするとZipファイルがダウンロードされ、解凍すると以下のデータが入っています。
ラベリングした画像と対応するラベルデータが含まれています。
$ tree -L 2
.
├── classes.txt
├── images
│ └── a335c376-7AEB89D6-7F3D-4ADF-8C14-422B7322EDBF.jpeg
├── labels
│ └── a335c376-7AEB89D6-7F3D-4ADF-8C14-422B7322EDBF.txt
└── notes.json
ここまでで教師データの準備が完了しました。
教師データの次は、評価データも用意します。
モデル作成のトレーニングで教師データから生成中のモデルをリアルタイムで評価して最適なモデルを作り上げるためです。
- 教師データ:モデルをトレーニングする
- 評価データ:教師データに対して性能を評価する
と言っても、教師データと同じ手順で作るだけなので、別なまーちゃんの画像群を用意してラベリングしてExportするだけです。
評価用の画像は、72枚でした。
評価用画像の目安としては教師データ合わせた総数の20~30%ぐらいがいいそうです(ちょっと足りなかったですが)。
1-2.Yoloでカスタムトレーニングする
作成した教師データと評価データを使ってモデルを作成します。
以下ディレクトリ構成で配置します。
教師データはtrain、評価データはvalidとします。
data.yamlも作成します。
data.yaml
yolo
├── train
│ ├── classes.txt
│ ├── images
│ ├── labels
│ ├── labels.cache
│ └── notes.json
└── valid
├── classes.txt
├── images
├── labels
├── labels.cache
└── notes.json
data.ymlの中身で以下です。
trainとvalidのパスの指定と使用するクラス(ラベル)名について記述します。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: path/to/train/images
val: path/to/valid/images
# number of classes
nc: 1
# class names
names: ["cat"]
次にYoloのトレーニング済みモデルをダウンロードします。
トレーニング済みのモデルに対してカスタムトレーニングするのが良いとのことです。
pipでダウンロードします。
pythonのバージョンは3.11.9です。
以下のコマンドで学習済みモデルをダウンロードできます。
$ yolo task=detect mode=predict model=yolov8n.pt \
source="https://ultralytics.com/images/bus.jpg"
$ ls
.rw-r--r-- t.endo staff 134 KB Mon Dec 2 09:23:54 2024 bus.jpg
.rw-r--r-- t.endo staff 6.2 MB Mon Dec 2 09:23:52 2024 yolov8n.pt
yolov8n.ptをプロジェクトのルート直下に配置して、以下のコマンドを実行します。
これでモデル生成が開始されます。
(ここから自動でやってくれるのですがとても長いです)
ちなみにコマンドのなかのepochs=300は、学習させる回数を表します。
全教師データに対して重み(パラメータ)を更新する作業を行って一巡位したら、それで1epochsになります。
ですので、今回の場合で言うと387枚全てに対して更新作業を行ってやっと1epochsになるので相当時間がかかります。
yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=300 imgsz=640

トレーニング中、ターミナル上で同時に評価結果も出力されます。
まだ開始したばかりで特に変化はないです。
【開始】

そして、これが最後のepochsが終わった時の結果になります。
Epochが238/300で終わっていますが、デフォルトの設定では一定回数以上、モデルの精度がこれ以上改善されないと自動的に終了するようになっていたため238で終了しました。
【終了】

トレーニングが終了すると、以下のディレクトリに生成されたモデルと評価結果が出力されています。
/Users/t.endo/.anyenv/envs/pyenv/runs/detect/train8
├── F1_curve.png
├── PR_curve.png
├── P_curve.png
├── R_curve.png
├── args.yaml
├── confusion_matrix.png
├── confusion_matrix_normalized.png
├── labels.jpg
├── labels_correlogram.jpg
├── results.csv
├── results.png
├── train_batch0.jpg
├── train_batch1.jpg
├── train_batch2.jpg
├── val_batch0_labels.jpg
├── val_batch0_pred.jpg
├── val_batch1_labels.jpg
├── val_batch1_pred.jpg
├── val_batch2_labels.jpg
├── val_batch2_pred.jpg
└── weights
├── best.pt // トレーニング中に得られた最良の重みファイル
└── last.pt
下は評価結果のresult.pngです。
特に着目すべきデータとしては画像右側の右肩上がりに上がっていっている4つになります。
良いモデルならできるだけ1に近づきます。
できたモデルとしては一旦これでよしとします。
- preceision: 精度
- recall: 再現率
- mAP50/mAP50-95:平均適合率

ちなみにトレーニングにかかった時間は、17時間もかかりました。
本来は画像処理などの機械学習はGPUなどを搭載しているPCで処理する必要があり、完全にCPUでトレーニングしていたのでここまで時間がかかってしまいました。
もし、PCも用意するのが手間であればGPUを搭載したクラウドサーバを使ってやるのが良いかと思います。
下のようなRunPodというサービスなどが良さそうです。
GPUを搭載していないPCだとトレーニングに何時間もかかるので、時間があるときに実施しましょう。
ちなみに後日、RunPodを使ってGPUでモデル生成したら、15分で終わりました。
圧倒的に速かったので、GPUでやった方がいいですね。
2.学習モデルとWebカメラでまーちゃんを検知する
学習モデルを生成できたので、このモデルをブラウザ上で使える形式に変換して実際にWebカメラで検知システムを作ります。
2-1.Pytorch形式からTesofflowjs形式に学習モデルを変換する
生成した以下の学習モデルをPytorch形式からTensoflowjs形式(json)に変換してブラウザ上で使えるようにします。
/Users/xxxx/.anyenv/envs/pyenv/runs/detect/train8/weights/best.pt
以下のpythonファイルを作成して実行します。
from ultralytics import YOLO
model = YOLO('/Users/xxxx/.anyenv/envs/pyenv/runs/detect/train8/weights/best.pt')
model.export(format='tfjs')
以下のディレクトリとファイルが生成されました。
model.jsonがTensorflowjsで扱える形式のモデルデータになります。
$ tree -L 2 /Users/t.endo/.anyenv/envs/pyenv/runs/detect/train8/weights/best_web_model
├── group1-shard1of3.bin
├── group1-shard2of3.bin
├── group1-shard3of3.bin
├── metadata.yaml
└── model.json
ちなみに変換する方法としては、pt => onnx => tfに変換する方法などもあるらしく、用途によって中間形式を変えられます。
ただ、変換過程で欠損が発生することもあるらしいので一発で済ませるのがいいと思います。
2-2.ブラウザ上でまーちゃんを検知する
変換したmodel.jsonを使ってブラウザ上でWebカメラを使ってリアルタイムにまーちゃんを検知するコードを書きます。
凝ったものは作らないので、htmlとjavascriptだけで作成します。
以下がコードになります。
TensorflowjsをCDNを使って呼び出し、Webカメラからの映像をモデルによる推論でまーちゃんを検知し、検知したら映像(画像)上に緑枠とどれぐらい一致しているかのパーセンテージとともにcanvas上に表示するといった内容のコードです。
<!DOCTYPE html>
<html>
<head>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script>
const labels = ["cat"];
async function detectObjects() {
const model = await tf.loadGraphModel("best_web_model/model.json");
const video = document.getElementById("video");
const stream = await navigator.mediaDevices.getUserMedia({
video: true,
audio: false,
});
video.srcObject = stream;
video.onloadeddata = async () => {
const canvas = document.getElementById("canvas");
const ctx = canvas.getContext("2d");
while (true) {
const videoFrame = tf.browser.fromPixels(video);
const resized = tf.image.resizeBilinear(videoFrame, [640, 640]);
const normalized = resized.div(255.0);
const batched = normalized.expandDims(0);
// 推論実行
const predictions = await model.predict(batched);
let output;
if (predictions.shape.length === 3) {
const transposed = tf.transpose(predictions, [0, 2, 1]);
const squeezed = transposed.squeeze([0]);
output = await squeezed.array();
tf.dispose([transposed, squeezed]);
} else {
output = await predictions.array();
}
const boxes = [];
const scores = [];
const classes = [];
for (let i = 0; i < output.length; i++) {
const [x, y, w, h, conf] = output[i];
const score = 1 / (1 + Math.exp(-conf));
if (score > 0.7) {
const x1 = (x - w / 2) * (canvas.width / 640);
const y1 = (y - h / 2) * (canvas.height / 640);
const x2 = (x + w / 2) * (canvas.width / 640);
const y2 = (y + h / 2) * (canvas.height / 640);
boxes.push([x1, y1, x2, y2]);
scores.push(score);
classes.push(0); // catクラスのインデックス
}
}
if (boxes.length > 0) {
const boxesTensor = tf.tensor2d(boxes);
const scoresTensor = tf.tensor1d(scores);
const nmsBoxes = await tf.image.nonMaxSuppressionAsync(
boxesTensor,
scoresTensor,
20,
0.7, // NMSのIoUしきい値を0.7に変更
0.7 // スコアしきい値も0.7に変更
);
const selectedBoxes = nmsBoxes.arraySync();
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
for (const boxIdx of selectedBoxes) {
const [x1, y1, x2, y2] = boxes[boxIdx];
const conf = scores[boxIdx];
const classId = classes[boxIdx];
const width = x2 - x1;
const height = y2 - y1;
ctx.strokeStyle = "#00ff00";
ctx.lineWidth = 2;
ctx.strokeRect(x1, y1, width, height);
ctx.font = "16px Arial";
ctx.fillStyle = "#00ff00";
ctx.fillText(
`${labels[classId]} ${Math.round(conf * 100)}%`,
x1,
y1 > 10 ? y1 - 5 : 10
);
}
tf.dispose([boxesTensor, scoresTensor, nmsBoxes]);
} else {
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
}
tf.dispose([videoFrame, resized, normalized, batched, predictions]);
await new Promise((resolve) => setTimeout(resolve, 100));
}
};
}
window.onload = detectObjects;
</script>
</head>
<body>
<video id="video" width="640" height="480" autoplay hidden></video>
<canvas id="canvas" width="640" height="480"></canvas>
</body>
</html>
このコードを使って実際に検知できるか試してみます。
今回、実物のまーちゃんがいないのでスマホ上の画像で検証します。
以下が実際に検知している時の画像です。
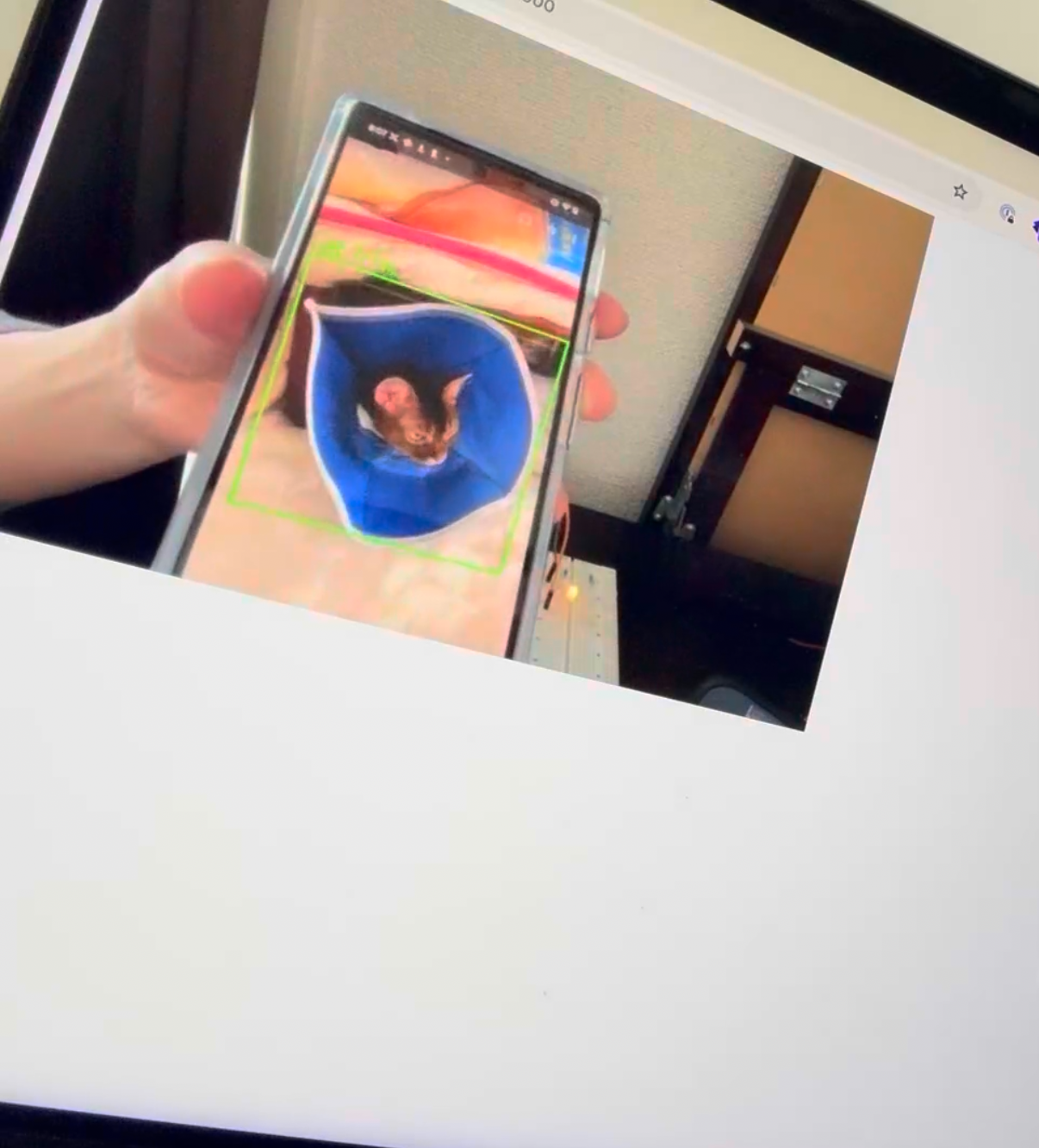
ある程度の距離まで近づけると検知しました。
他の物体と違うということができているので、個人的には成功です。
ただ、精度としては70%と低めで他のものでも時折誤認することがあるので、トレーニング段階で精度を高める必要がありそうです。
3.RaspberryPiとブラウザで通信する
ここからは、RaspberryPiを使っていきます。
ブラウザ上でまーちゃんを検知したらRaspberryPiと通信をするようにします。
3-1.Rustで待受サーバを実装
ブラウザとRaspberryPiの通信をするために、RaspberryPi側をサーバーとしてWebSocket通信できるようにします。
RaspberryPiのセットアップについては省略します。
今回、RaspberryPi上で使う言語は何にしようかなと考えたのですが、個人的にRustに興味があったので、組み込みもできるということでRustにしました。
早速、Rustをインストールするところから始めます。
任意の場所にディレクトリを作ってそこで実施してください。
無事インストールできたらRustのバージョンが表示されます。
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
$ rustc --version
rustc 1.82.0 (f6e511eec 2024-10-15)
Cargoでプロジェクトを作成します。
xxxx@raspberrypi:~/Workspace/rust/websocket-server $ cargo new websocket-server
tatsuya@raspberrypi:~/Workspace/rust/aa $ tree -L 2
.
├── Cargo.toml
└── src
└── main.rs
ブラウザからWebsocket通信を受け取れるようにします。
まずは、Cargo.tomlに必要なクレート(パッケージ)を記述します。
[package]
name = "websocket-server"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1", features = ["full"] } # 非同期するのに必要
tokio-tungstenite = "0.21" # WebSocketするのに必要
main.rsに以下のブラウザからの通信を待ち受けするコードを書きます。
use tokio::net::TcpListener;
use tokio::sync::broadcast;
use tokio_tungstenite::accept_async;
#[tokio::main]
async fn main() -> tokio::io::Result<()> {
let listener = TcpListener::bind("0.0.0.0:10005").await?;
println!("WebSocket server listening on ws://0.0.0.0:10005");
let (tx, _rx) = broadcast::channel::<String>(100);
while let Ok((stream, addr)) = listener.accept().await {
println!("New client connected: {}", addr);
let tx = tx.clone();
let _rx = tx.subscribe();
tokio::spawn(async move {
if let Ok(_ws_stream) = accept_async(stream).await {
println!("WebSocket handshake completed for {}", addr);
}
});
}
Ok(())
}
書き終わったら、プロジェクトルートにてビルドと実行を行います。
これでリッスン状態になります。
tatsuya@raspberrypi:~/Workspace/rust/websocket-server $ cargo build
tatsuya@raspberrypi:~/Workspace/rust/websocket-server $ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/websocket-server`
WebSocket server listening on ws://0.0.0.0:10005
3-2.ブラウザで検知したらWebSocket通信
メインのPCに戻り、index.htmlのまーちゃんを検知した時に入る処理にwebsocket通信を送信するコードを追加します。
検知したら連続で通信しないようにsetTimeoutで制限をかけています。
for (const boxIdx of selectedBoxes) {
// 省略
}
+ if (!window.isSending) {
+ window.ws = new WebSocket("ws://raspberrypi.local:10005/");
+ window.isSending = true;
+ setTimeout(() => {
+ window.isSending = false;
+ }, 5000); // 5秒間は再送信を防止
+ }
tf.dispose([boxesTensor, scoresTensor, nmsBoxes]);
} else {
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
}
これで準備は整ったので通信できるか確認します。
ブラウザでindex.htmlを表示してWebカメラを起動してまーちゃんを検知します。
(もし、RaspberryPi側でリッスン状態にしていなければ、cargo runを再度実行してください。)
すると、RaspberryPi側で以下が出力されるはずです。
ちゃんとWebSocket通信できていることが確認できました。
New client connected: xxxxxxxx
WebSocket handshake completed for xxxxxxxx
4.RustとRaspberryPiを使って開閉ゲートを作る
いよいよ佳境に差し掛かってきました。
RaspberryPi側にブラウザからの通信が来たらサーボモーターを動かすようにします。
4-1.サーボモーターを動作させる回路を組む
RaspberryPi5を使ってGPIOピンとサーボモーターを直接接続します。
本当は、ブレッドボード上で外部電源を使って回路を組んだほうがいいのですが、今回はこうします。
以下は実際に接続した画像です。

接続したGPIOピンと配線の色の対応は以下の通りです。
- ピン2:5V電源 => 赤
- ピン6:GND => 茶
- ピン12:GPIO18 => オレンジ

これで回路は完成です。
4-2.Rustでサーボモーターを動作させる
次にこのサーボモーターを動かすコードを書いていきます。
サーボモーターを動かすにはrppalというRustのクレートが必要なので、Cargo.tomlに追記します。
[package]
name = "websocket-server"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1", features = ["full"] }
tokio-tungstenite = "0.21"
rppal = "0.19.0" # RaspberryPi制御するためのクレート
続いて、モーターを動かすモジュールをsrc/utilsディレクトリを作ってそこにファイルを作成します。
motor.rsを作って以下のように記述します。
モーターを動かすコードですね。
90度回転して、2秒後に元の角度に戻ります。
use rppal::pwm::{Channel, Polarity, Pwm};
use std::{thread, time::Duration};
pub fn handle_motor() -> Result<(), Box<dyn std::error::Error>> {
let pwm = Pwm::with_frequency(Channel::Pwm0, 50.0, 0.0, Polarity::Normal, true)?;
// 開始位置(0度)
println!("サーボを0度に設定");
pwm.set_duty_cycle(0.025)?;
thread::sleep(Duration::from_secs(2));
// 90度位置
println!("サーボを90度に設定");
pwm.set_duty_cycle(0.075)?;
thread::sleep(Duration::from_secs(2));
// 終了時は0度に戻す
println!("サーボを0度に戻す");
pwm.set_duty_cycle(0.025)?;
thread::sleep(Duration::from_secs(1));
Ok(())
}
加えて、モジュールを呼び出せるように以下のファイルも作成します。
pub mod motor;
3-1で作成したmain.rsに"追加"コメントのコードを追記します。
これで先ほどのmotor.rsのメソッドを呼び出すことができ、通信を受けたらサーボモーターが回転するようになります。
use tokio::net::TcpListener;
use tokio::sync::broadcast;
use tokio_tungstenite::accept_async;
mod utils;
#[tokio::main]
async fn main() -> tokio::io::Result<()> {
let listener = TcpListener::bind("0.0.0.0:10005").await?;
println!("WebSocket server listening on ws://0.0.0.0:10005");
let (tx, _rx) = broadcast::channel::<String>(100);
while let Ok((stream, addr)) = listener.accept().await {
println!("New client connected: {}", addr);
let tx = tx.clone();
let _rx = tx.subscribe();
tokio::spawn(async move {
if let Ok(_ws_stream) = accept_async(stream).await {
println!("WebSocket handshake completed for {}", addr);
let _ = utils::motor::handle_motor();
}
});
}
Ok(())
}
4-3.動作確認
実際にブラウザで検知してからサーボモーターが動くか確認してみようと思います。
実際に作ったものが以下です。
ブラウザ側でまーちゃんをスマホ画像を使ってWebカメラに映します。
まーちゃんが検知されると画面上に緑枠と一致率が表示されています。
検知したらRaspberryPi側に通知がいき、お手製ゲートが開閉するようになりました。
これにてまーちゃん検出機の完成です。
参考資料
おわりに
今回は、画像処理系の機械学習とRaspberryPiを組み合わせたシステムを作って見ました。
機械学習はハードルが高そうに見えましたが、やってみると意外とそこまで難しいものではなかったですね。
RustでRaspberryPiを操作する試みも楽しかったです。
これからも、まーちゃんの布教と電脳世界へ解き放つ活動をやっていこうと思います。
ちなみにまーちゃんは僕が飼っている猫ではなく、知り合いの猫なんですけど、溺愛しています。
最後までお付き合い頂きありがとうございました!
